
Joined February 2023
- Tweets 649
- Following 251
- Followers 116
- Likes 4,909
28 Photos and videos

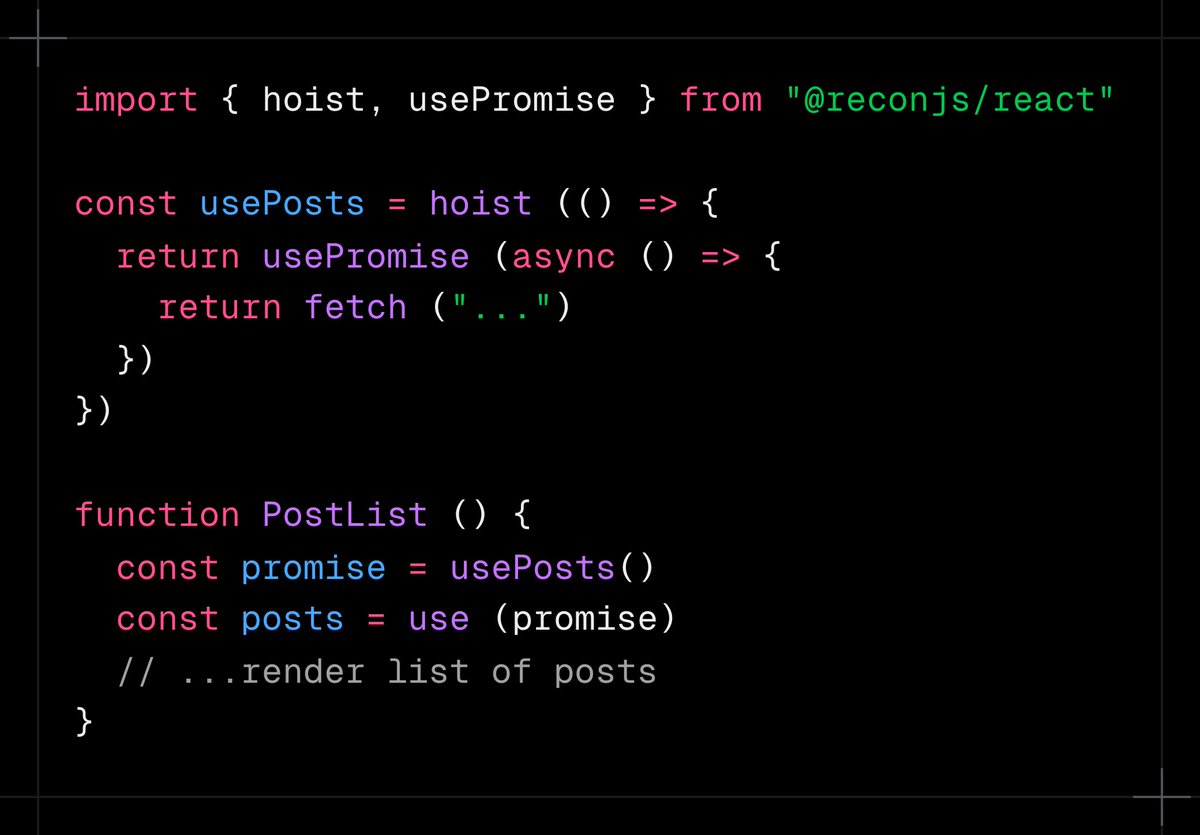
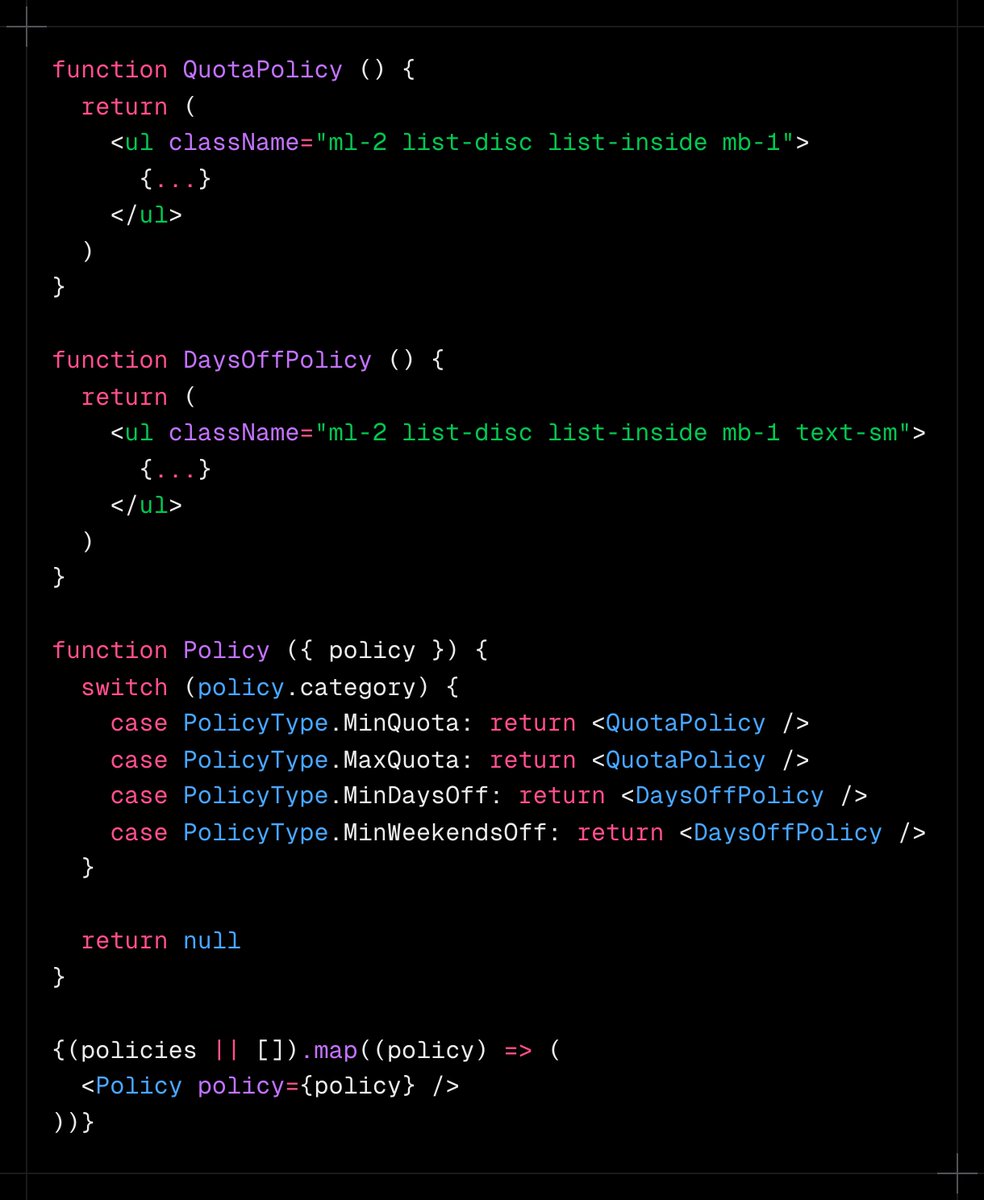

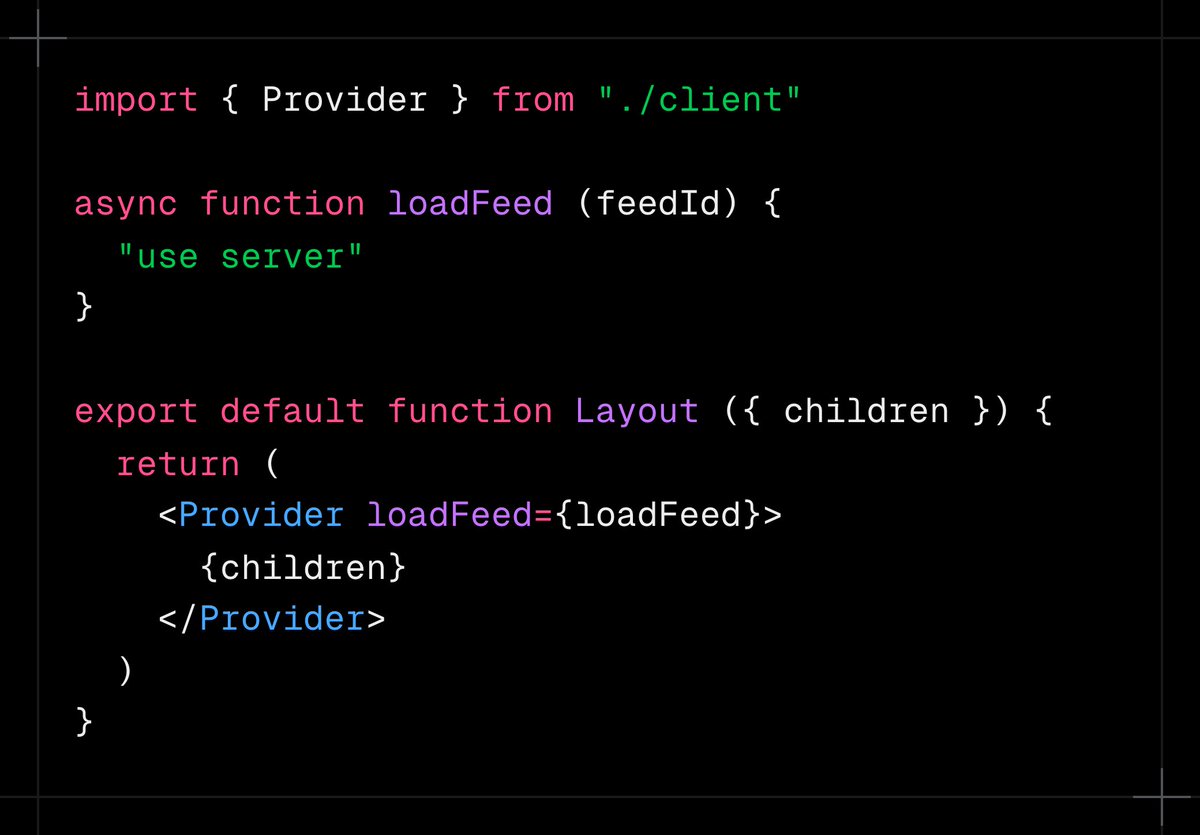









Jun 13
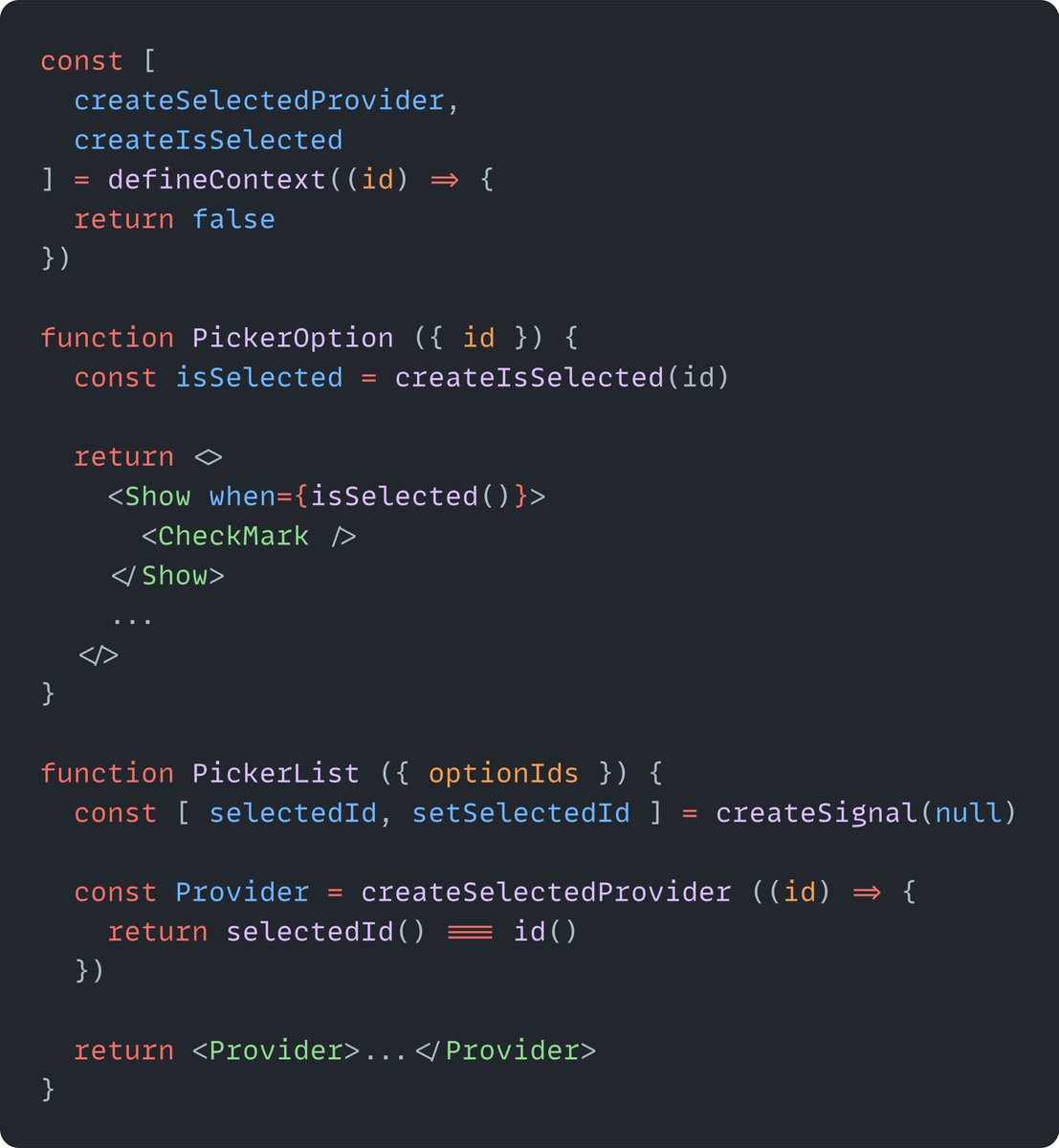
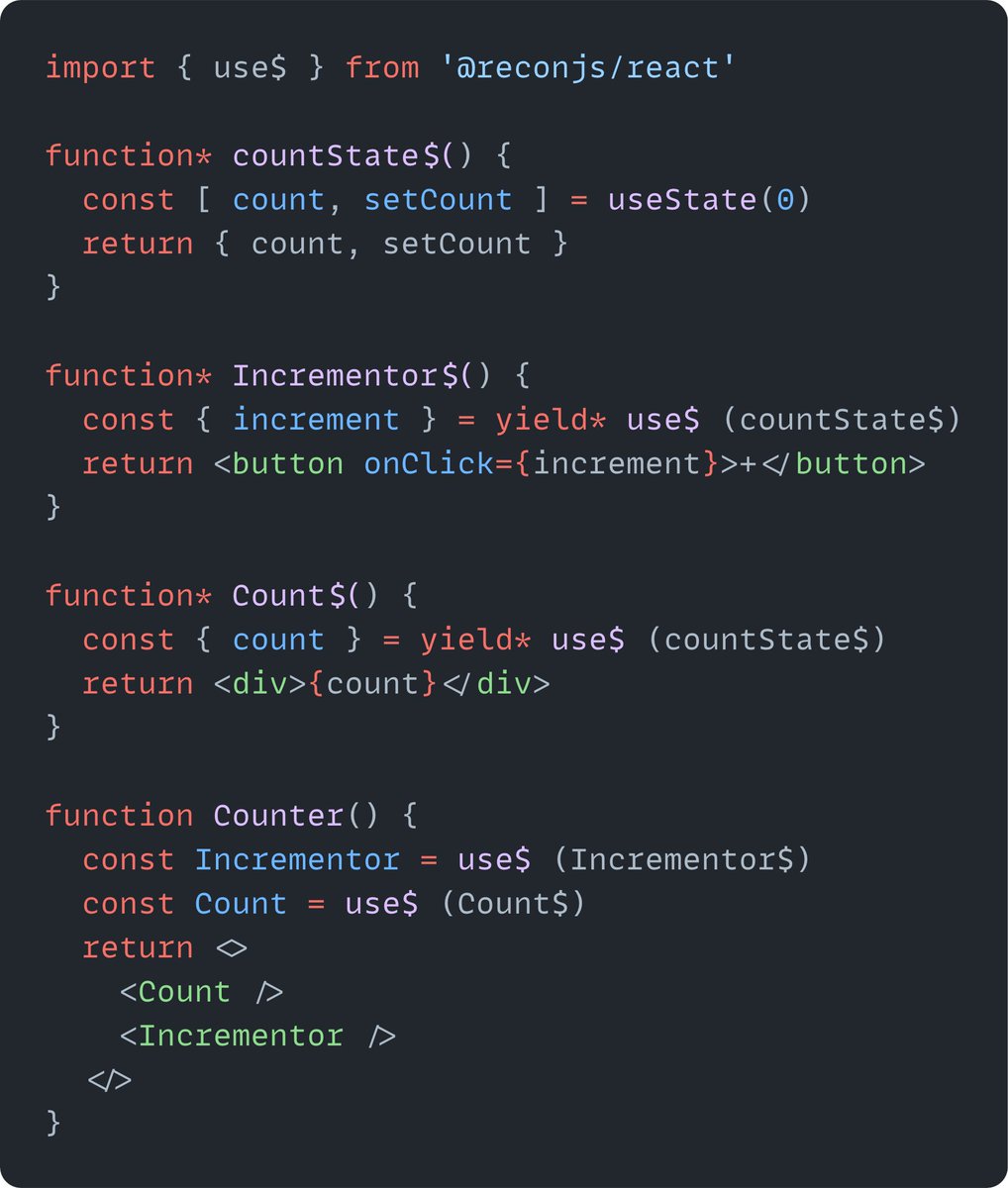
I’m so glad I spent yesterday using Fable instead of cleaning my house
1
23
Jun 13
I’m scared Opus is going to write over Fable’s memories and mess up this very complex project
12
Jun 10
I think LLMs are getting too much post-training and it’s stifling their creativity.
They understand a strategy that involves deviating from norms but will keep using the norms.
This probably improves benchmarks but most work usually involves deviance in one way or another.
27
Reed Harmeyer retweeted
Jun 3
The friction was the system. What’s the system now?
1
1
148
Jun 3
When a good session is getting close to compaction I feel something
39
Jun 1
Me from 9 years ago is so pumped right now! I actually have a few projects I can try this out on

1
109
Jun 1
Models be pissing me off when they make some shit up and then treat it like it’s the 11th commandment.
No Claude you didn’t need to setup a new DB for this, that was just an idea that YOU threw out earlier
48
Reed Harmeyer retweeted

May 27
Model-Harness-Task fit!
it’s clear that RL post-training produces a model-harness fit via tool shapes and prompting as models are trained with the harness in the loop. Mentioned this in a previous LangChain blog, Cursor also has good content on this
But there’s probably less talk on the importance experimentation of Harness-Task fit. Practically this includes choices like domain specific prompting (ex: verification coding tasks) or omission of confusing context that doesn’t apply to the current task
Claude Code’s harness has TONS of instructions because they’re forced to serve a very general persona of user who could ask for…anything basically. But there’s a large benefit of using a laser focused set of context and tools relevant to the narrow task at hand without all the other junk
This is the Harness-Task fit
Every component of a harness exists to elicit some behavior from the model. If these components are tuned to the task, then the model benefits. If they’re a mix of noise and good content, the model may be fine but it may get confused
This is why the best vertical AI teams in the world build very bespoke harnesses and evals for their agents
Task-Harness fit helps you rock at the exact thing your customers care about and is why builders can outperform natively post-trained harnesses
May 27

Question for harness heads: how is it possible that another harness helps a model more than the one it was RL’d against on a top-priority capability?
Not a dunk, I just find this really really surprising !!
7
9
83
9,565
May 23
I don’t see why we would expect this to result in good data.
This workforce was selected for being developers who could put up with corporate politics for a paycheck.
There is no reason to think they’d be effective or willing data labelers given these circumstances.
1
48
May 22
You’ve heard about Harness Engineering but have you heard about Harness Engineer Experience Engineering?
24
Reed Harmeyer retweeted

May 22
It is becoming less taboo for VCs to back direct competitors
I propose a defensive pact amongst founders:
"If a Major Investor hedges by investing in my direct competitor, I will hedge by starting a second company"
Comment/retweet to cosign :)
13
4
103
36,941
May 19
Flags seem insufficient for AI features, what are y’all using for A/B testing?
1
31
May 18
Remember when Steve Jobs gave his commencement speech at Stanford and told all the journalism grads that they’re entering a dying industry? Me neither.
May 17

This is incredible. Artificial intelligence getting booed out of the stadium in any commencement speech it’s mentioned. Maybe telling college students AI was taking their jobs wasn’t the best strategy. Must watch —>
54
Reed Harmeyer retweeted
May 17
build v1 of agent
ship it (dogfooding counts)
⭐️ collect tracing data ⭐️
⭐️⭐️ point agentic compute at data ⭐️⭐️
understand failures at scale
generate evals
edit agent to pass evals
🔁
10
4
102
7,065
Reed Harmeyer retweeted

May 15
The essential engineering cheatsheet of 2026:
agent → while loop
subagent → nested while loop
agent harness → the rest of the code
cloud agent → all the above, on EC2
31
82
984
36,413
May 15
Solution Architect
May 14

Question on my mind right now: What role is least impacted by AI (so far)?
37
May 15
I feel like if Claude thinks you’re wrong then you’re probably just wrong.
We are all somewhat wrong most of the time.
May 14

Opus is not very nice in a concrete way. When it disagrees with the user, it is almost impossible to get it to change its mind or reconsider. It almost always defaults to a disagreement loop where it blames the user for trying to override its opinion or gaslight it
2
293
May 15
Alternatively, maybe Claude is just really sensitive to the way ideas are articulated.
I find that Claude is good for pushing me on ideas but even when I’ve been wrong I’ve been able to make my case well enough to win it over.
But maybe it just likes how I talk
96
May 14
VCs don’t even think of themselves as idea evaluators.
90% of the ones I’ve met have a rule against making that kind of a judgment call.
May 12

If you talk to 100 seed funds and they won’t invest in your company you’re actually wrong.
Was reminded of this conversation I had with @eoghan.
22
Reed Harmeyer retweeted

May 14
Apparently an unpopular opinion, but I don't think Anthropic owes anyone heavily subsidized tokens for their third party app.
May 14

I can't help but feel personally burned by the Claude Code changes announced today.
We put so much work into wrapping the (atrocious) Claude Agent SDK in T3 Code. It was the ONLY path they supported, so we made it work. It was hell.
Now our users are getting their rate limits cut by 40x, despite us doing everything right.
I listened to the Claude Code team. I had my issues with their direction, but I trusted them and took them at their word.
I will never make that mistake again.
Until we see significant change, it is safe to assume any statement from an Anthropic employee is a lie on a timer.
The rug will be pulled, no matter how many promises are made beforehand.
152
54
2,269
282,934