
Joined September 2012
- Tweets 39,117
- Following 1,023
- Followers 2,990
- Likes 64,755
2,205 Photos and videos








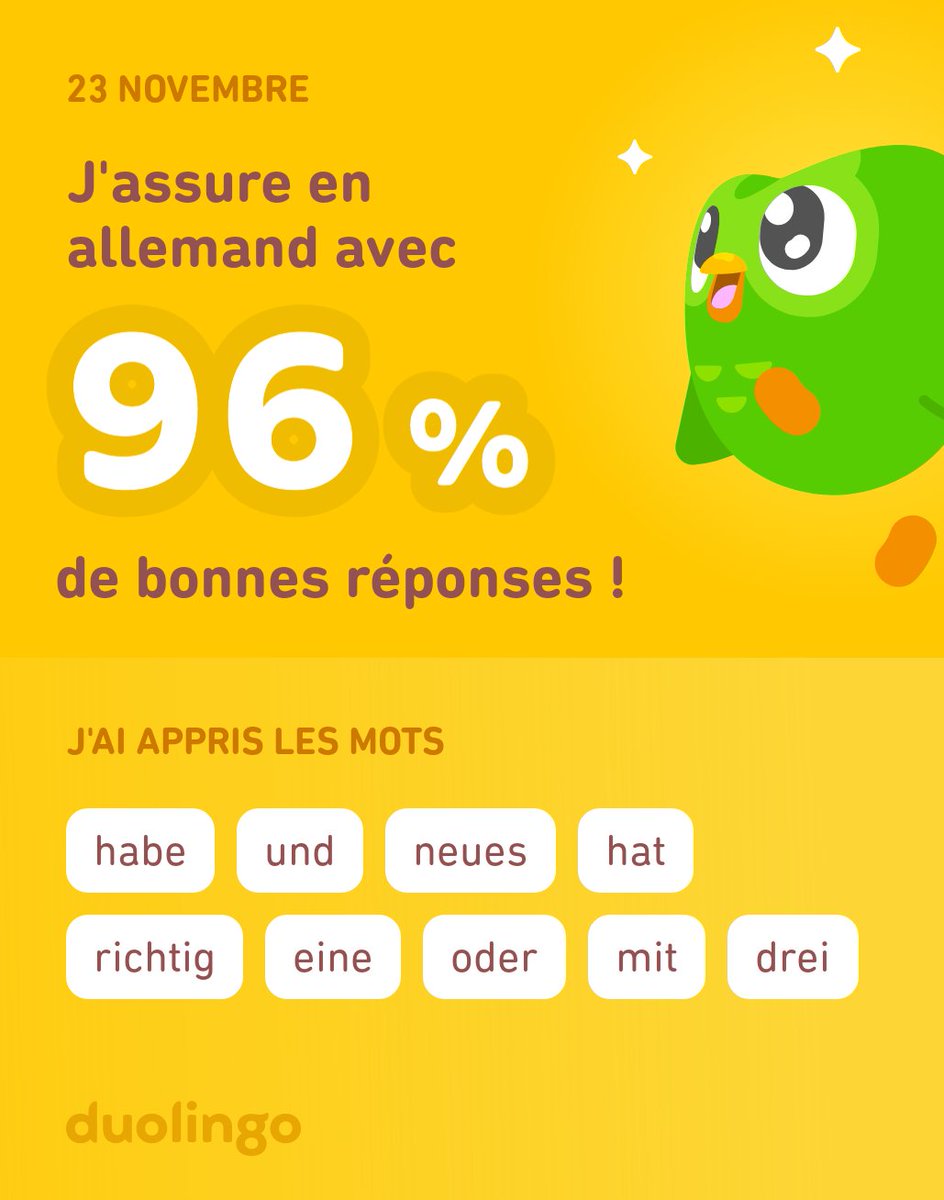





Pinned Tweet

17 Oct 2023
Partout où l'Etat ne peut ou ne veut ; tant que faire se peut, faire sans l'Etat !
2
11
25
6,754
Mon nouveau Post : L'effondrement actuel des naissances serait-il surtout une 'correction démographique' ?
Le filtre s'est déplacé : hier la mortalité infantile (biologique), aujourd'hui le coût de la vie (économique), limitent les naissances
open.substack.com/pub/renaud…
1
16
Ayi - 🍸 Molotov - Dossavi. retweeted

Jun 11
What can men expect from women without being shamed ??
20
120
1,284
19,696
Ayi - 🍸 Molotov - Dossavi. retweeted

Hayek calls Milton Friedman “still a Keynesian”
24
70
486
38,390
Ayi - 🍸 Molotov - Dossavi. retweeted
Jun 3
I have barely seen women quote statistics properly
28
99
1,506
21,232
Ayi - 🍸 Molotov - Dossavi. retweeted

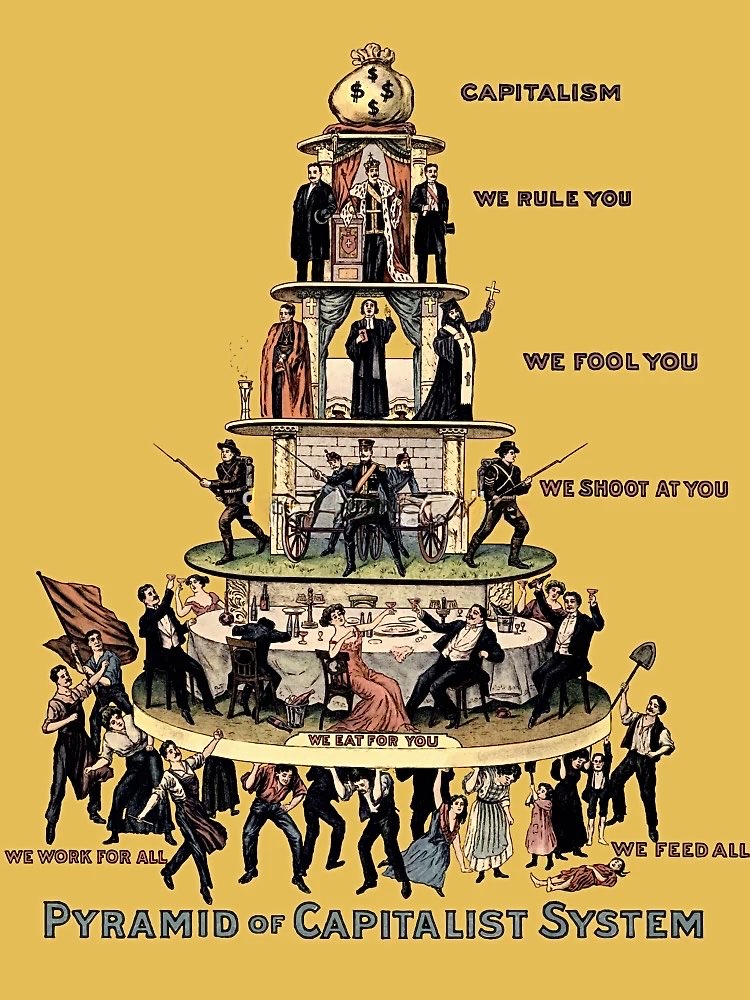
We desperately need class consciousness in the U.S.
Class consciousness is not telling people to vote for the blue or red ruling class parties.
It is educating people that both parties serve the billionaire class, which is why workers need to build our own power to fight back.

Your pyramid is a lie:
Here is the Capitalist Pyramid published in 1911 by the Industrial Workers of the World.
It illustrates how the working class props up capitalist society.
A century of propaganda has conditioned Americans to love the capitalist system that enslaves them and hate the socialist system that liberates us all.
771
2,795
13,224
673,641
Ayi - 🍸 Molotov - Dossavi. retweeted

Jun 3
Adam Aleksic, a Harvard-trained linguist, on why a single boring word reveals how AI is quietly reshaping human speech:
Aleksic says you can see something strange happening to human language in one small, unremarkable word: delve.
He explains that since ChatGPT came out, the numbers around this word have gone wild:
"Usage of the word 'delve' has spiked a 1,000% since before 2022."
So why does ChatGPT love "delve" so much? According to Adam, the answer is baked into how the model was trained:
"There is a bias in the reinforcement learning process... when the words get trained into the model."
@etymology_nerd lays out two reasons.
The first is about the people doing that training work:
"The reinforcement workers are in Nigeria and Kenya, where they do actually say 'delve' at higher rates — but still not that high."
The second is about the kind of vocabulary the model gravitates toward.
Adam notes that "delve" is a Latin word, and that ChatGPT carries a Latin-based bias, leaning toward dramatic-sounding words rather than the basic connective ones like "the" and "but."
His explanation for why:
"Because these models are trained to sound like they know what they're talking about, they're going to use more of the romance language stuff."
So ChatGPT keeps producing "delve." But here's the part Adam flags as genuinely unsettling:
The influence doesn't stay inside the machine. There's now evidence that, in just the past few years, humans have started using "delve" more often in their own spontaneous, spoken conversation.
As the interviewer Chris Williamson summed it up: "So the creature that programmed the AI is being programmed by the AI."
Adam's reply captures the entire phenomenon in five words:
"Its reality is influencing our reality."
33
40
443
21,794
Ayi - 🍸 Molotov - Dossavi. retweeted

Countries that can’t stand each other… and yeah, don’t skip the ending 😅
84
679
6,650
34,634
Ayi - 🍸 Molotov - Dossavi. retweeted

Jun 3
La Gen-Z et sa liberté de penser.
22
291
1,191
10,726
Fast 🧠
Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
9
Ayi - 🍸 Molotov - Dossavi. retweeted

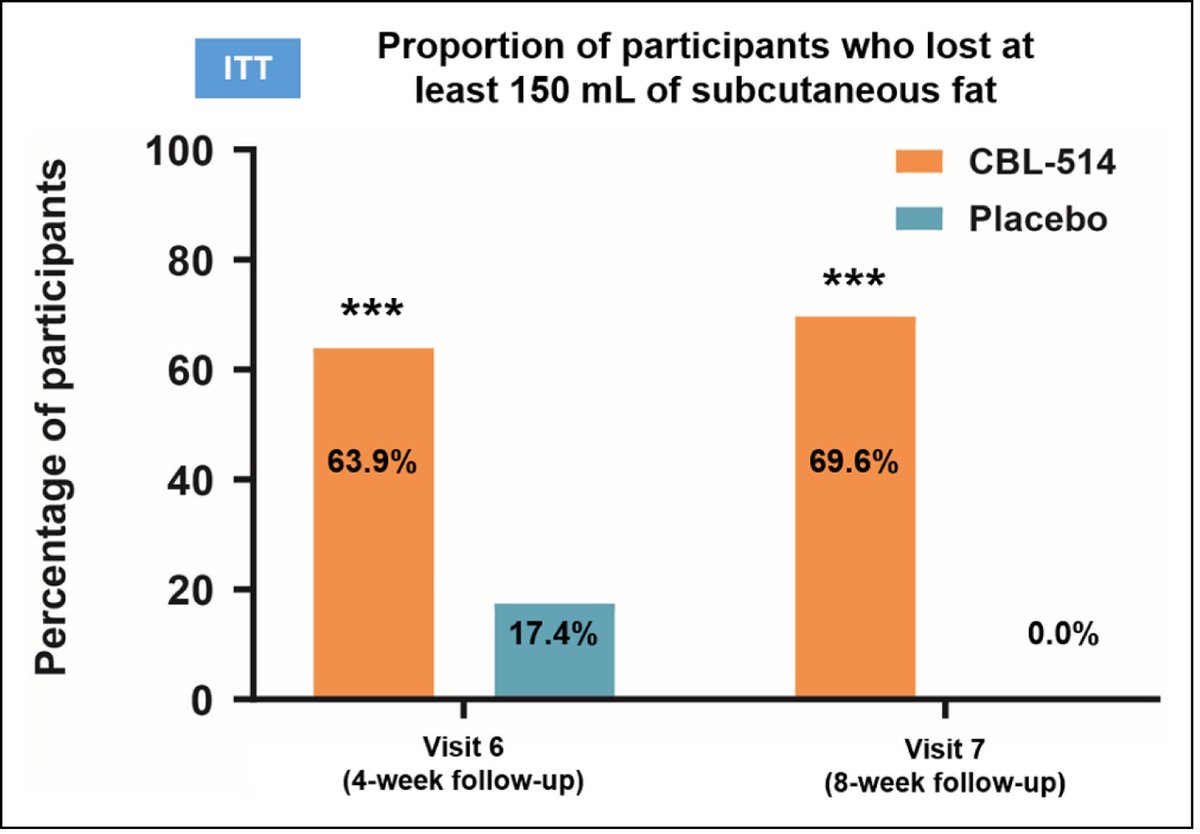
24 Jul 2025
What comes after GLP-1RAs make everyone skinny?
What comes after myostatin inhibitors make everyone buff?
One new candidate is:
Safe, cheap, and easily-administered injections that locally remove fat. A new drug that just passed through phase 2 seems to do just that🧵
114
170
2,516
608,484
Ayi - 🍸 Molotov - Dossavi. retweeted

Jun 4
"LLMs resemble a kind of left-hemisphere-style knowledge. It is sophistry. It is clever, but there is no necessary tie to reality...like chatting with a really charming psychopath..you probably want to check what he is saying against some reliable sources" wkeithcampbell.substack.com/…

8
11
72
58,185
Ayi - 🍸 Molotov - Dossavi. retweeted

May 30
Modern toplumun olanakları zekânın üzerindeki evrimsel baskıyı ortadan kaldırdı. Yani, bir kişinin zekâ seviyesi ile üreme başarısı arasında bir ilişki yok.


22
90
1,017
86,119
Le poète Toussaint Cossy Guenou, ou la beauté obsédante des mots et des nuages.
Nouvelle note de lecture, sur un auteur togolais méconnu... et légendaire !
open.substack.com/pub/renaud…
3
125
Ayi - 🍸 Molotov - Dossavi. retweeted

"I call it theory-induced blindness: once you have accepted a theory and used it as a tool in your thinking, it is extraordinarily difficult to notice its flaws."
-Daniel Kahneman (1934-2024)
stevestewartwilliams.com/p/o…
7
45
196
9,401
Ayi - 🍸 Molotov - Dossavi. retweeted

OPEN ACCESS: France in Cameroon (1945-1971), more than 1000 pages, now in English, led by historian Karine RAMONDY, download it here vie-publique.fr/files/rappor…

19
333
668
39,051
Ayi - 🍸 Molotov - Dossavi. retweeted

Apr 6
Jean-Frédéric Gerbeau (directeur général délégué à la science, Inria) décrit les "progrès spectaculaires" de l'IA en mathématiques : "j'ai des collègues à l'Inria qui me disent que certaines démonstrations qui leur aurait pris des semaines se font aujourd'hui en quelques heures".

📜 Le programme de cette audition publique :
➡️ Introduction par Raja Chatila, membre du Conseil scientifique de l’Office, professeur émérite
➡️ Progrès récents et pistes de développement de l’IA
• Patrick Pérez, directeur général de Kyutai
• Jean Ponce, professeur au Département d'informatique de l'ENS PSL et au Courant Institute de New York University, directeur associé pour la recherche de l'IA du Cluster PR[AI]RIE et président de la startup ENHANCE LAB
• Jean-Frédéric Gerbeau, directeur général délégué à la science, INRIA
• Laurent Simon, professeur des universités, titulaire de la chaire de la Fondation Bordeaux Université sur l’IA Digne de Confiance et membre du collège Représentation et Raisonnement de l’Association française pour l’intelligence artificielle
➡️ La diffusion des innovations dans les usages de l’IA
•Alexis Bacot, directeur de projets IA, Direction générale des entreprises
•Selma Souihel, adjointe au directeur du programme IA d’INRIA
•Françoise Soulié, administratrice et membre du bureau du Hub France IA
•Erwan de la Porte du Theil, président fondateur de l’Association nationale de l’intelligence artificielle
•Arthur Grimonpont, responsable du plaidoyer, Centre pour la sécurité de l’IA
➡️ Carte blanche à Daniel Andler, membre du Conseil scientifique de l’Office, professeur émérite
#DirectAN
8
76
216
33,113
Ayi - 🍸 Molotov - Dossavi. retweeted

Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,120
2,827
26,778
7,145,067
RT @robkhenderson: Under Pol Pot’s regime, the communists would blindfold people, line them up, and tell them to march forward. The militar…
1,500
Ayi - 🍸 Molotov - Dossavi. retweeted
Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,888
7,238
59,797
21,365,787
Ayi - 🍸 Molotov - Dossavi. retweeted

Apr 3
🇲🇿 Près de 700 millions de dollars : c’est l'estimation de la dette que le gouvernement mozambicain a entièrement remboursé au FMI. Voici ce que l’on sait.
#Mozambique
7
258
922
37,173