
ZK Engineering at @0xMiden. Previously @Toposware, @0xPolygon. Building Plonky3 recursion. Maintainer of Plonky3. Opinions are my own.
Joined December 2015
- Tweets 643
- Following 144
- Followers 532
- Likes 3,147
11 Photos and videos





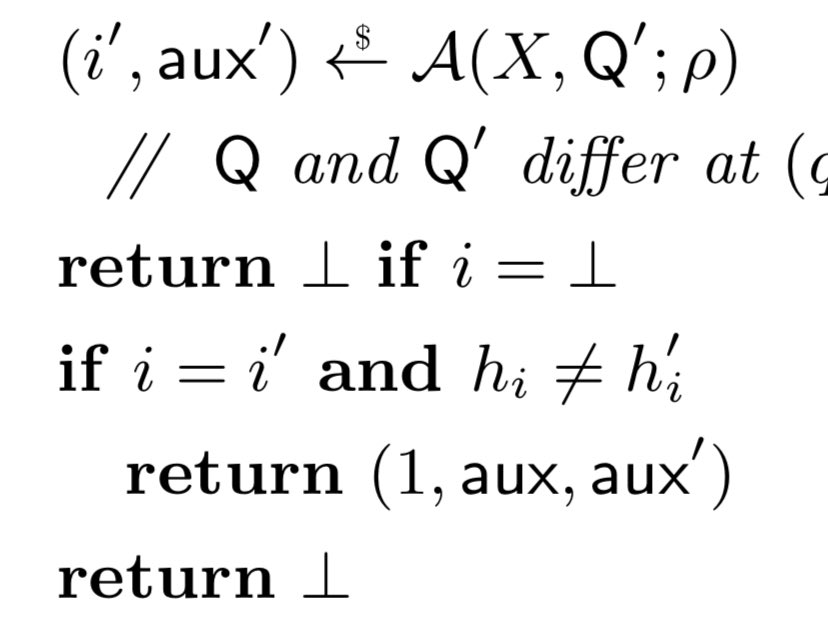
Pinned Tweet

Jun 11
🔥 WHIR has landed in Plonky3 🔥
We just released v0.6.0, and with it we open the door to the world of multilinear PCS! 🚀
We've also shipped a ton of cool new features and performance improvements.
👀 Spoiler alert: Circle STARK is now *really* fast.
github.com/Plonky3/Plonky3
1
7
42
4,496
Two days ago, we announced Plonky3 v0.6.0 and hinted at cool improvements for Circle STARK.
The reality? We just made Circle STARK over M31 *𝑓𝑙𝑦* in Plonky3 ⚡
No new hardware, just math and engineering giving us 2.3x faster prover at higher security! 🚀
Jun 11

🔥 WHIR has landed in Plonky3 🔥
We just released v0.6.0, and with it we open the door to the world of multilinear PCS! 🚀
We've also shipped a ton of cool new features and performance improvements.
👀 Spoiler alert: Circle STARK is now *really* fast.
github.com/Plonky3/Plonky3
1
2
21
1,153
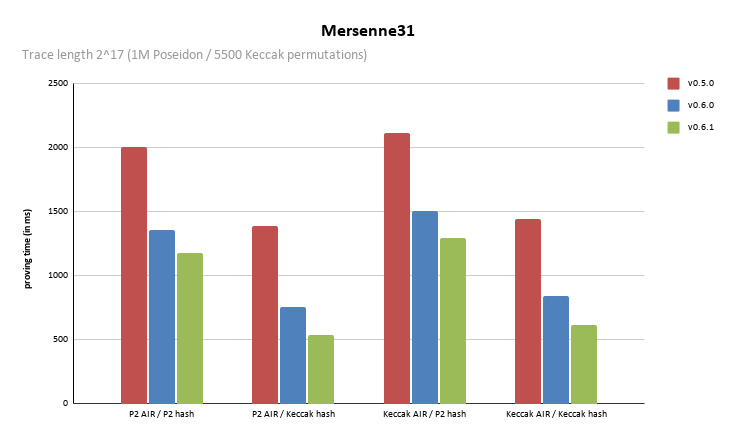
Below are benchmarks across the latest versions of Plonky3, showcasing the Circle STARK prover performances over the Poseidon2 and Keccak-f AIRs, obtained on an M4 pro.
The transition from v0.6.0 to v0.6.1 yielded 13-29% improvements while also gaining 20 extra bits of security!
1
4
142
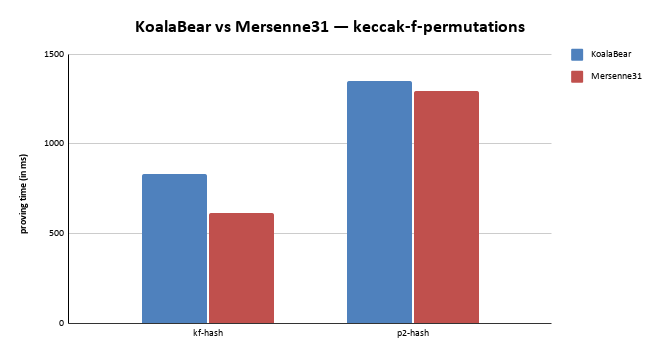
With our latest release, Circle STARK over M31 is now FASTER than Uni-STARK over Koala-Bear when proving Keccak-f permutations ⚡
(while Koala-Bear prover also got 12-15% faster across those releases!)
To the moon 🚀
2
1
3
218
Jun 11
The zero-knowledge variant of WHIR is also part of the new Plonky3 release, come play with it!

We’re currently working on bringing the zero-knowledge version of WHIR to Plonky3 — Zero-Knowledge IOPPs for Constrained Interleaved Codes.
Feedback, reviews, and improvement suggestions are very welcome 👇
github.com/Plonky3/Plonky3/p…
5
221
Robin Salen retweeted

Mar 31
Google’s latest Shor resource estimate: secp256k1 ECDLP (and ECDSA over that curve) may be breakable with <500K physical qubits under specific assumptions. They proved the resource estimate for a key subroutine with a ZKP rather than publishing the attack circuits. (Yes, really - a ZKP to support the claim without disclosing the attack. Interesting times.)
I’ve written about Q-day timing before. The idea was that law & business cycles alone justified working on quantum resistance without trying to predict Q-day.
But you also don’t need to predict the date if the cryptographic primitive your proof system depends on isn’t the one Shor is breaking. Miden’s proof system is STARK-based - hash functions, not elliptic curves.
26 Nov 2025

There's much talk about Q-day, the future date when quantum computers become powerful enough to break some of today’s public-key cryptography—specifically RSA & elliptic-curve schemes.
We do have good quantum-resistant cryptography, but when should we invest the work needed to switch?
3
8
27
3,297

Using Groth16 to prove the existence of a quantum advantage in elliptic curves is the only post-quantum secure use of Groth16 :)
Mar 31

This is wild. Google Research demonstrates a ~20x more efficient implementation of Shor's algorithm that could break ECDSA keys within minutes with ~500K physical qubits.
Google is now are more confident on a 2029 post-quantum transition. We are no longer looking at mid 2030s, we could have quantum computers of this scale by the end of the decade.
They believe this result is so severe that they are not publishing the actual circuits. They instead published a ZKP proving that they know of the quantum circuit with these properties. This is very atypical, showing Google thinks this is serious shit.
All blockchains need a transition plan ASAP. Post-quantum is no longer a drill.

5
14
104
8,527
Mar 27
Such a great work! 🔥
I’m excited to see what else we can pull from autoresearch to push ZK forward. Super promising direction!
Mar 26

I implemented zk-autoresearch, based on Karpathy's autoresearch loop, on a production ZK prover, Plonky3.
Soundness review by a Plonky3 engineer is pending before I treat these as final. The methodology finding is already clear, preliminary results below.
Target: Plonky3's NTT implementation — the inner loop of proof generation, already heavily optimized by expert ZK engineers. If the approach doesn't work here, it doesn't work anywhere.
Hardware: Hetzner CCX33, AMD EPYC, AVX512, 8 cores.
Model: I used Claude Sonnet 4.6 deliberately, Opus would have marginal gains at significantly higher cost per iteration. For a loop running potentially 100s of times in future experiments, that tradeoff matters.
74 iterations. Fully autonomous by design, but in this first experiment 2 adjustments were made to the setup (at iterations 5 & 10) to nudge the agents to be more decisive.
- Raised MAX_TOKENS from 8192 to 20000, and added "you must always make a change" as the agent kept hitting the token limit. This unlocked improvements at iterations 6 and 9.
- Added near-miss display in the history prompt, showing reverted experiments within 1.5% as combination candidates. This set up iteration 21, where the agent revisited a failed idea that now worked because the surrounding code changed.
Iteration constraints:
- Each iteration ran correctness tests to prevent faulty proofs. Note: during the run these were compile-level checks; post-run correctness was confirmed via full end-to-end ZK proof generation and verification with Radix2DitParallel on BabyBear (10 tests, all passing).
- Agents were structurally prevented from touching FRI or other soundness-critical components — only dft/src/ and baby-bear/src/ were writable.
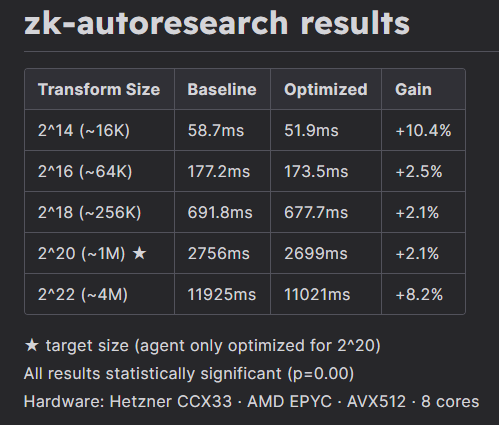
3% faster at the target size (2^20) during the experiment. Post-experiment benchmarks across 2^14 to 2^22 showed the optimizations generalized better than expected, particularly at the extremes (see image). The agent only optimized for 2^20.
The known issues (short history window causing agent amnesia, wasted tokens on repo exploration, correctness test targeting wrong package) meant the last improvement was found at iteration 21. Round 2 with these fixed should yield a more consistent staircase pattern over 100 iterations.
All gains came from the agent finding redundant work in the hot butterfly loop: precomputing products, hoisting broadcasts, skipping multiplications by 1. Pure implementation-level work, no algorithmic changes.
6 improvements in 74 iterations. 57 regressions. The full experiment log with every diff, benchmark result, and agent reasoning is auditable.
The agent that found these improvements is not a ZK expert. It reasoned about Rust and Montgomery arithmetic from first principles and found real optimizations in code already written by expert engineers.
ZK has been underexplored for agentic optimization because people worry about agents breaking proof soundness. The concern is real but misapplied here, all 6 changes are mathematically equivalent transformations, verified by end-to-end proof generation and verification. (Soundness review by a Plonky3 engineer is pending)
Round 2 is being prepared with the known issues from Round 1 fixed. Full findings and code will be open sourced after it completes.
If you are ZK team and want to run this, feel free to DM me.
Inspired by @karpathy autoresearch pattern. First known application to a production ZK prover.
1
3
253
Robin Salen retweeted

Mar 19
Quick announcement: After long and heavy suffering :) the S-two white paper is finally out:
eprint.iacr.org/2026/532
Although nothing new in regard to the basic principles (a circle STARK, etc.) the white paper yet contains several details of broader interest:
- A formal description of the flat AIR circuit model (used by several contemporary zkVMs)
- A thorough soundness analysis of multi-table proofs: If one does not use "lifted" FRI, taming the soundness error turns out to be more sophisticated as expected. We introduce the notion of "cross-domain correlated agreement", and show that multi-table FRI satisfies this property.
- A discussion of adjusted conjectures, which takes into account the recent boost of proximity gaps counter examples. We believe that it is plausible to hope for acceptable list- and line-decodability properties up to the information-theoretic barrier, the Elias bound.
Thanks for all the help from the StarkWare team, and in particular to Dmitry Krachun for the many helpful discussions around his counter example.
6
38
159
9,253
Mar 19
I am super thrilled to share that I am joining the @0xMiden team today!
I've been following their work for a while, and it's an honor to be part of their amazing engineering workforce.
To the moon! ✨
1
33
1,764
Robin Salen retweeted

Mar 16
We are starting to upstream WHIR implementation to Plonky3!
Multilinear primitives have been merged!
Feel free to reach out / open issues / PRs if you want to help or to improve the implementation!
github.com/Plonky3/Plonky3/p…
2
8
48
1,720
Mar 10
🚀 New Plonky3 release just dropped.
This is probably our most impactful and ambitious release so far:
- MUCH faster lookups
- High-arity folding
- N-ary Merkle trees Merkle caps
- Major Poseidon2 optimizations
- Poseidon1 support
- And many more…
Let’s break it down 👇
4
31
133
8,528
Mar 10
This release also includes many other improvements across the AIR API, FRI, matrix ops, and prover internals.
Huge thanks to everyone contributing to Plonky3 ❤️
1
11
380
Mar 10
Come check the release and build on Plonky3! 👇
github.com/Plonky3/Plonky3
For builders needing support in migrating their codebase to v0.5.0, we have a Plonky3 telegram channel: t.me/plonky3
1
15
365