
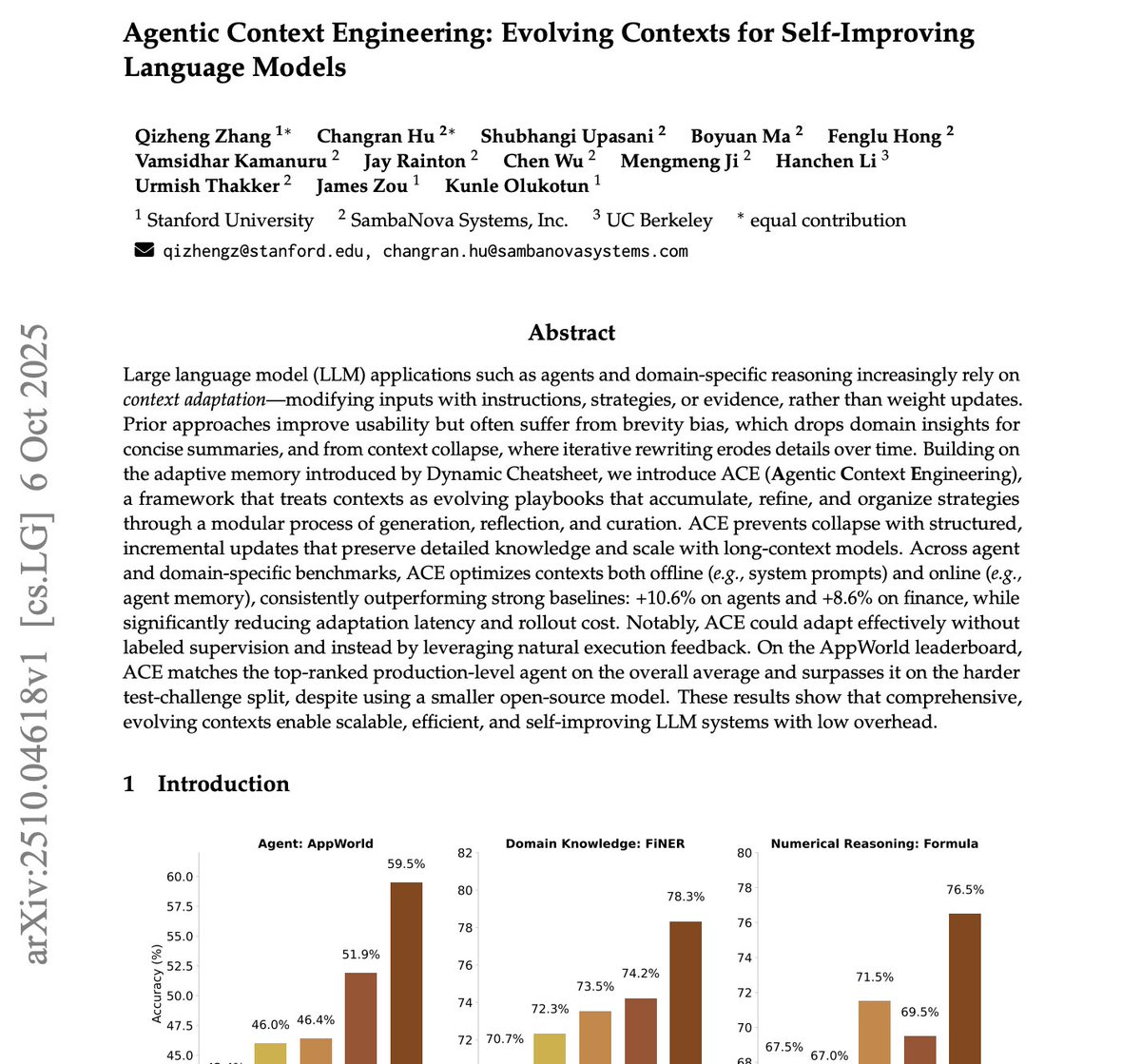
Co-founder & CEO @SambaNovaAI
Joined January 2019
- Tweets 382
- Following 129
- Followers 1,466
- Likes 112
16 Photos and videos















Rodrigo Liang retweeted

Jun 9
Same prompt. Same model. Two stacks.
At #Computex, we demonstrated disaggregated inference live: GPUs handling prefill, SambaNova RDUs handling decode, and CPUs orchestrating agent execution.
The result? Up to 2X the speed of B200-only configurations 🦾
1
3
17
1,105
Rodrigo Liang retweeted

Jun 9
Co-founder @sarahookr on stage at @brainstormtech with @SambaNovaAI CEO @RodrigoLiang and @FortuneMagazine's @jeremyakahn.
The discussion: Chips not built for inference and models that don’t learn continuously.
Two CEOs, two sides of the same problem. A new era of intelligence is here.

1
9
38
2,380

Jun 10
Here is what happens inside Sambanova RDU.
Jun 9

What actually happens during AI inference?
This video breaks down how RDUs, memory architecture, and multi-level parallelism work together to generate thousands of tokens in parallel across racks.
Built for scalable, real-world AI inference 🦾
Learn more: sambanova.ai/products/rdu-ai…
8
223
Rodrigo Liang retweeted
Jun 8
"VC2 is the largest commercial deployment of SambaNova technology in our history, and we're proud to partner with the industry's strongest leaders." - @LipBuTan1
Excited to see @vectorcorecomp launch live w/ our RDUs powering decode alongside GPUs & CPUs.
itbrief.co.uk/story/vista-la…

1
7
38
2,028
Rodrigo Liang retweeted
Jun 2
At @LipBuTan1's #COMPUTEX2026 keynote today, @RodrigoLiang stepped onstage with @RFS_Vista to power up the world's first disaggregated inference cloud, VectorCore Compute (VC2), launched by @Vista_Equity and Cambium Capital.
Three chips ran disaggregated inference, live from the VC2 datacenter in LA:
➡️ NVIDIA B200 GPUs — prefill, high-compute burst
➡️ SambaNova RDUs — decode, high-throughput, low-latency token generation at scale
➡️ Intel® Xeon® 6 CPUs — tool execution, end-to-end orchestration
“GPUs are powerful. RDUs are fast. CPUs orchestrate. But disaggregate all three — and you get speed, performance, and economics no single chip can touch. That's the unlock.” – @RodrigoLiang

10
41
1,838
Rodrigo Liang retweeted
Jun 2
The future of inference is disaggregated.
At #COMPUTEX2026, Vector Core Compute unveiled the world's first fully disaggregated inference cloud powered by Intel Xeon and SambaNova RDUs—designed for the scale, speed, and economics modern AI demands.
Excited to help bring this vision to life with @Vista_Equity and Cambium Capital.

Vector Core Compute, a new enterprise inference cloud formed by @Vista_Equity and Cambium Capital, unveil fully disaggregated inference running on Intel Xeon processors and @SambaNovaAI RDUs
@RFS_Vista at Computex
ms.spr.ly/6016vbWHp

2
11
40
2,100
Rodrigo Liang retweeted
May 20
Following Cerebras’ IPO, @RodrigoLiang joined @Bloomberg with @mattmiller1973 and @daniburgz
to explain why inference could become the biggest business in tech.
Watch here: bloomberg.com/news/videos/20…

1
2
9
461
Rodrigo Liang retweeted
May 15
The next AI war won’t be about training models.
It’ll be about:
➡️ Inference costs
➡️ Compute shortages
➡️ Scaling AI profitably
Following Cerebras’ IPO, @RodrigoLiang joined @Bloomberg with @mattmiller1973 and @daniburgz to explain why inference could become the biggest business in tech.
Enterprise AI demand is exploding. The infra race is just getting started.
Watch here ⤵️
bloomberg.com/news/videos/20…
2
44
79
222,013
Rodrigo Liang retweeted
May 15
UK sovereign AI is becoming reality.
Together with Argyll , we’ve launched a sovereign AI inference cloud built on SambaNova’s full-stack AI platform — designed for performance, efficiency, and control without the trade-offs of traditional infrastructure.
As AI adoption scales, sovereignty can’t just be a label. It has to be demonstrated through infrastructure ownership, operational control, energy efficiency, and where intelligence is deployed.
This deployment delivers:
⚡ High-performance AI inference
🌍 Renewable-powered infrastructure
🔋 ~10kW rack density with air-cooled systems
🏗️ Disaggregated architecture across UK data centers
🧠 SambaNova RDUs for efficient large-scale AI
This is what the next generation of AI infrastructure looks like.
Read more via DatacenterDynamics ⤵️
lnkd.in/eAqaBqtr


3
5
35
294,307
May 15
Cerebras IPO signals that the market has clearly moved to inference. That’s where costs stack up, where systems break. Where scale either works… or doesn’t.
AI won’t be decided by who trains the biggest model. But who can make inference economics actually work at global scale.
1
1
9
157
Rodrigo Liang retweeted
May 5
Thank you @ArtificialAnlys for verifying our speeds, as always 🦾
@MiniMax_ai M2.7 is running the FASTEST on SambaCloud. Try it now: cloud.sambanova.ai

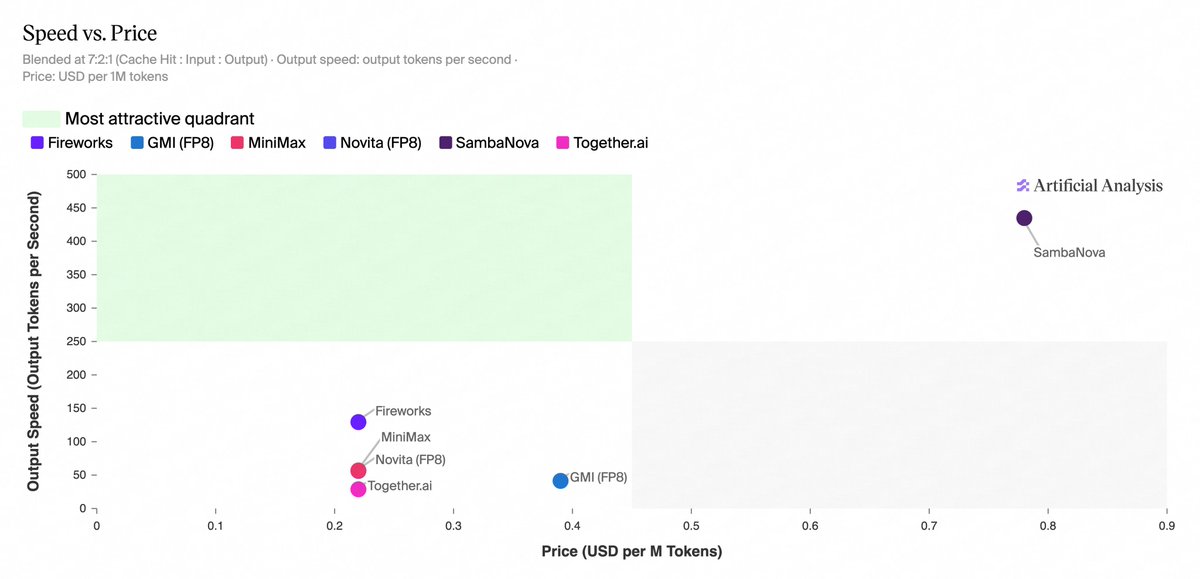
MiniMax-M2.7 is now available across six inference providers on Artificial Analysis, with significant differentiation in speed and price
@SambaNovaAI leads on speed at 435 output tokens/s, >3x faster than any other provider. @FireworksAI_HQ, @novita_labs, @togethercompute, and @GMI_cloud have all matched @MiniMax_AI's first-party API pricing, while SambaNova is 2x higher.
Key takeaways:
➤ Fireworks and SambaNova are on the Pareto frontier for Speed vs. Price. At 127 output tokens/s and ~$0.22 per 1M tokens blended, Fireworks is ~2.2x faster than MiniMax's first-party API at the same blended price, whereas SambaNova delivers 435 output tokens/s but at ~2-3.5x the blended price of the other providers (depending on cache usage)
➤ SambaNova is the fastest provider at 435 output tokens/s, ~3.4x the next fastest provider (Fireworks at 127 output tokens/s). The remaining providers run substantially slower: MiniMax’s first-party API at 57 output tokens/s, Novita at 54, GMI at 41, and Together AI at 29
➤ Cache discounts vary across providers. Fireworks, MiniMax, Novita, and Together AI offer 80% cache hit discounts, while GMI and SambaNova do not offer a discount. For cache-heavy workloads, this can materially increase the relative pricing for GMI and SambaNova
➤ Optimal provider choice depends on workload. SambaNova may be more suited to latency-sensitive deployments, albeit at a higher cost, while Fireworks may be more suitable for high-volume workloads that are not as latency-sensitive
1
5
14
2,193
Rodrigo Liang retweeted
May 5
MiniMax M2.7 is now running FASTEST on SambaCloud 🚀
Built for coding, OpenClaw, and self-evolving agent workflows.
Available today across Enterprise & Dev tiers.
Try it now: sambanova.ai/blog/build-self…
6
5
49
349,318



Rodrigo Liang retweeted
Mar 24
📣 ICYMI: Devs, SambaCloud delivers MiniMax 2.5 at the fastest speed (400 t/s)—verified by @ArtificialAnlys.
Try it now: cloud.sambanova.ai/dashboard…
Take a look at those benchmarks 👇
1
4
499
Rodrigo Liang retweeted
Feb 26
🦞 @openclaw is powerful, but running agentic workflows on big, slow models kills the magic.
The fix? Smaller, specialized models our ultra-fast AI infra. Speed = intelligence. 🚀
Check out the blog ⬇️
sambanova.ai/blog/the-opencl…
5
11
734
Rodrigo Liang retweeted
Feb 25
When the @NYSE celebrates you 🥹
Humbled & thrilled to see our name take flight above the trading floor! A legendary tribute to our $350M Series E & collab with @Intel.
NYSE team: Thank you for making this milestone magic.
sambanova.ai/press/sambanova…



1
5
15
1,657
Rodrigo Liang retweeted

Feb 24
A defining inflection point for the infrastructure powering the next AI era.
Congratulations to @SambaNovaAI on raising $350M and unveiling the fastest chip purpose-built for Agentic AI, in collaboration with @intel.
This is not just a funding round. It’s a market signal that the industry is moving decisively from pilots to production. With the launch of SN50, SambaNova is redefining what production-grade AI infrastructure looks like: scalable, high-performance systems engineered to power fleets of AI agents across entire data centers.
As Co-Founder and CEO, @RodrigoLiang puts it:
“AI is no longer a contest to build the biggest model. With the SN50 and our deep collaboration with Intel, the real race is about who can light up entire data centers with AI agents that answer instantly, never stall, and do it at a cost that turns AI from an experiment into the most profitable engine in the cloud.”
SambaNova continues to demonstrate what it means to build at the foundation layer, where silicon, performance, efficiency and real-world deployment converge.
We are honoured to have such visionaries within the RAISE Summit ecosystem.
The next era of AI won’t be trained. It will be operationalized.
👇 sambanova.ai/press/sambanova…
1
3
269
Rodrigo Liang retweeted

Feb 24
The future of AI inference data centers will be heterogenous as AI agents and workloads become more diverse and complex. We are working on a multi-year collaboration for @intel #Xeon and @SambaNovaAI RDU based AI compute racks to meet this growing need. newsroom.intel.com/data-cent…
1
10
47
5,497
Feb 24
SN50 is here.
✅5X faster than competitive chips.
✅3X lower cost than GPUs.
✅Built for the agentic era, inference at true cloud scale.
We’re also announcing a multi-year collaboration w/ @intel to unlock the next wave of AI infra.
bit.ly/3P0ua8k
4
17
65
12,313
Rodrigo Liang retweeted
4 Dec 2025
What if we measured intelligence?
New research from @Stanford introduces Intelligence per Joule, a metric that actually reflects value, not just speed 🚀
And our SN40L RDU delivers 4X better energy efficiency by computing smarter, not harder.
Read more: sambanova.ai/blog/best-intel…

2
7
2,237