
gemini multimodal understanding, product @ deepmind. views are my own.
Joined April 2020
- Tweets 90
- Following 208
- Followers 1,374
- Likes 603
10 Photos and videos









Pinned Tweet

18 Nov 2025
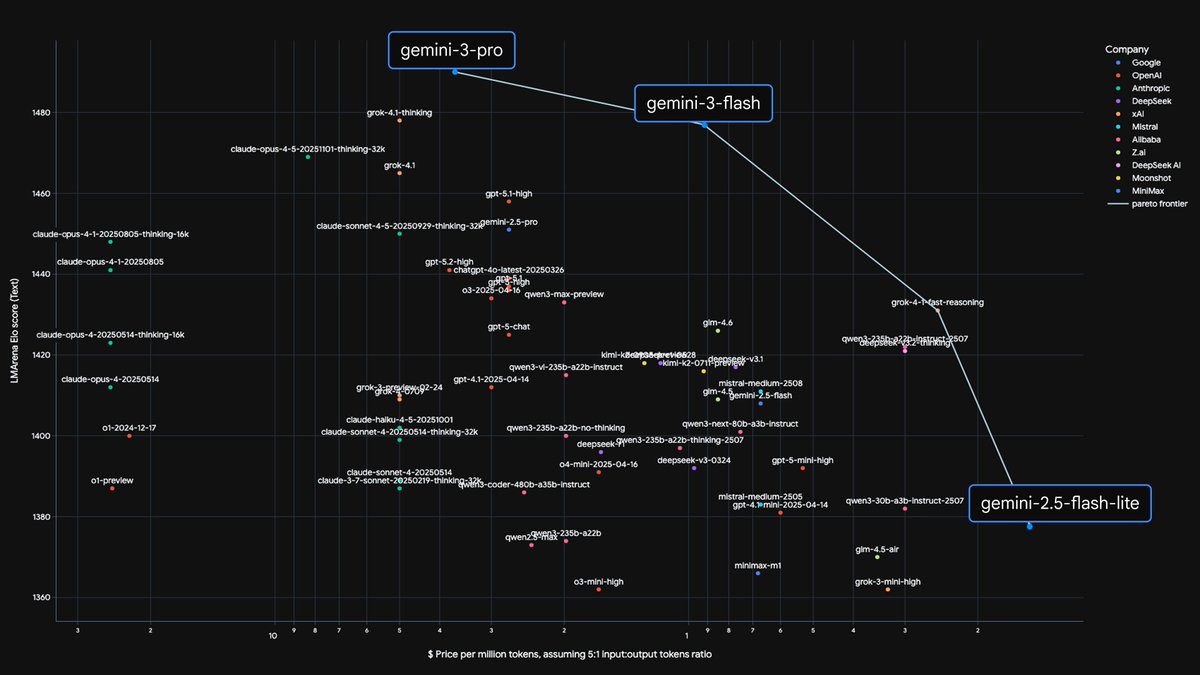
🚀 We just launched Gemini 3 Pro — the strongest multimodal understanding model ever built.
I lead product for Gemini’s multimodal vision capabilities, and I want to share more about the massive wins we are seeing across document, screen, spatial, and video understanding. 🧵
8
5
45
9,483
Rohan Doshi retweeted

May 22
Gemini 3.5 Flash outperforms 3.1 Pro on many vision use cases (like the below Roboflow eval) while being ~6x faster on average 🤯 Gemini multimodal understanding for the win.

126
50
1,019
63,907
May 21
gemini 3.5 flash is the engine that powers agents across all google products. would love to hear what y'all think
May 21

Gemini 3.5 Flash ranks #1 on the APEX-Agents-AA benchmark, outperforming much larger models a whole size above it.

1
6
688
Apr 25
Had fun speaking at Cloud Next 2026 as a panelist for "How DeepMind Makes Modeling Decisions" ✨ DM me if you want to keep chatting about the future of frontier models and multimodal agents 🤖
1
200
Apr 14
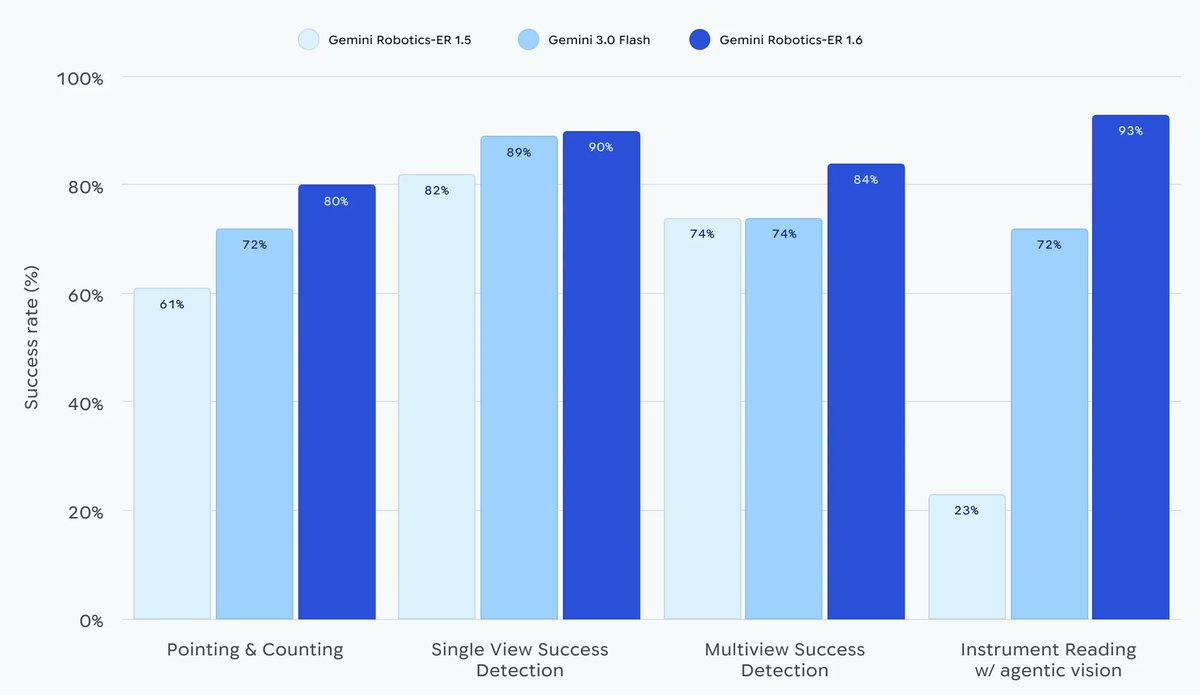
Gemini's agentic vision really shines in our latest SOTA robotics model for things like reading instruments, estimating proportions, and counting 🤖
Apr 14
Introducing Gemini Robotics ER 1.6, our new SOTA robotics model 🤖 which excels at visual and spacial reasoning, now available via the Gemini API!
2
9
1,237

filesystem code sandbox combo eats another modality.
remember when o3 destroyed at geoguessr?
gemini agentic vision will find location on any street photo you take faster than Liam Neeson can get back his daughter

Jan 29

Agentic Vision is rolling out now in the Gemini app when you select “Thinking” from the model drop-down.
Learn more about Agentic Vision in Gemini 3 Flash: goo.gle/45zo5FH
21
12
155
23,888
Feb 10
An awesome deep dive on how to leverage Gemini 3 Agentic Vision today

Gemini 3 Flash now uses an agentic "think-act-observe" loop to solve complex visual tasks 🤖
@GoogleDeepMind engineer @ptruiz_dev demonstrates how the model runs Python code automatically to zoom and inspect items, annotate images, and re-visualize data into charts.
2
1
49
3,275
Feb 9
Back at Harvard Business School last week speaking on frontier AI agents 🤖
As a ’23 alum, it was energizing to be back - this time teaching from the other side of the classroom
My AI agent workshop was completely packed, with 100 students - signal on how much Harvard is leaning into AI
The students’ agency, raw IQ, and curiosity left me wildly optimistic about the next wave of AI builders 🚀
Grateful to Profs. Jeffrey Bussgang & Allison Mnookin and the Launching Tech Ventures team for the invite 🙏🏼


2
15
1,287
Jan 28
what are y'all building with Gemini Agentic Vision??
Jan 27

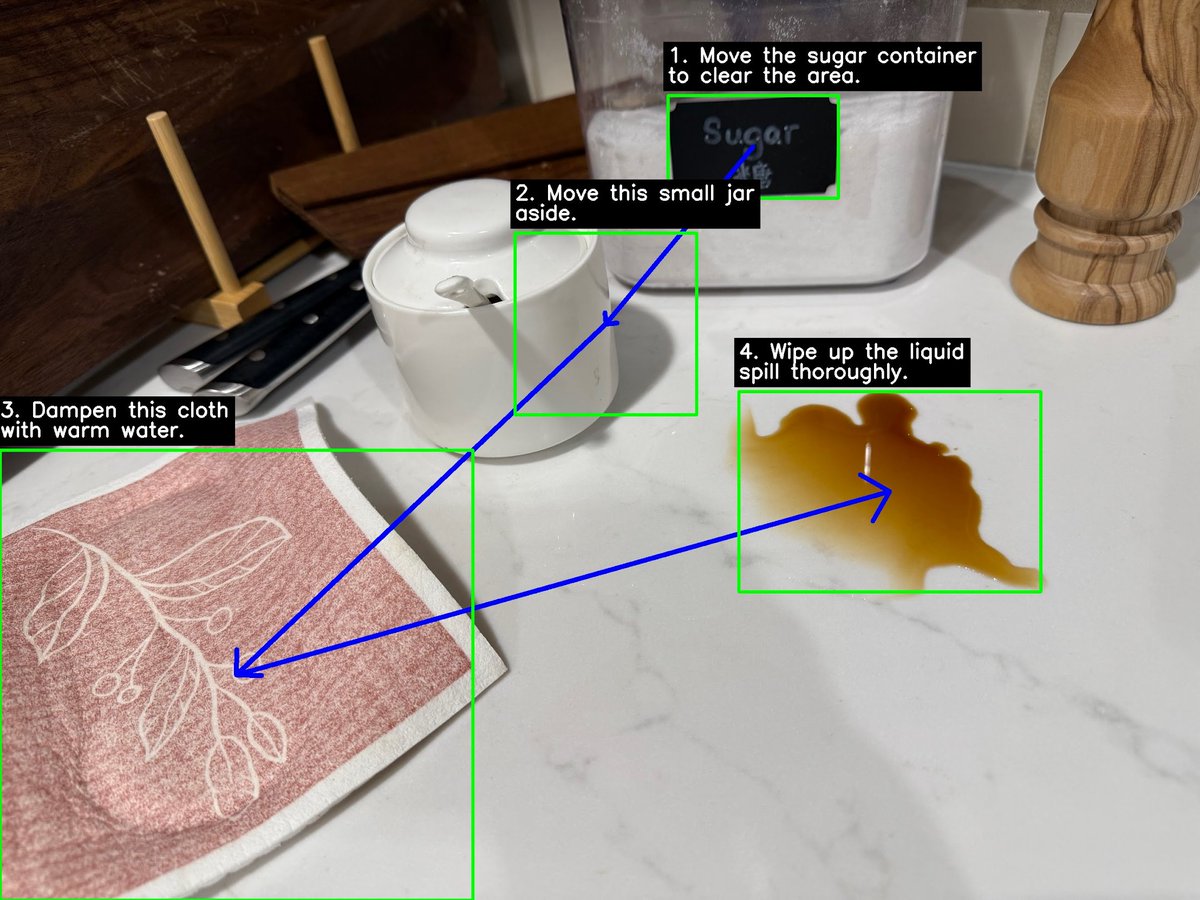
Introducing Agentic Vision with Gemini 3! 👀🔥
Gemini can now write and execute code to zoom, annotate, inspect, and plot directly with vision input, all while leveraging it's advanced reasoning capabilities
5
3
33
5,493
Jan 27
🚀 Excited to officially launch 👁Agentic Vision via Gemini 3 Flash. Gemini can run code execution on image uploads to zoom, analyze, and annotate:
🔍 Zoom: 5-10% quality win across vision benchmarks
🧮 Analyze: do image math with code (e.g. calculate the tip for a receipt)
✏️ Annotate: Draw arrows or bounding boxes to answer questions
Try via the Gemini API (AI Studio / Vertex) or via the Gemini App (rolling out to Thinking mode today).
Learn more→ goo.gle/4bsKdFv
Demo:
goo.gle/3Z05KxK
cc: @IoanaBica95 @anastasija56572 @jalayrac @bcaine @eisenjulian @weichengkuo @phillip_lippe @xf1280 @tulseedoshi @BiboXu @OfficialLoganK
Try 👁 Agentic Vision with Gemini 3 Flash in @GoogleAIStudio or Vertex AI. This new capability enables the model to effectively use code and reasoning to improve performance for common vision tasks.
See Agentic Vision in action: goo.gle/3Z05KxK
8
27
232
29,418

Gemini 3 Flash is insane at OCR.
It parses this extremely hard to read handwritten letter by Richard Feynman perfectly. It can do ~300 of these for $1.
What's crazy is Feynman addresses General Donald J. Kutyna as "Katyna" which Gemini gets. There is no "Meeting Katyna", the first part of the letter, in all of Google search!

64
159
1,677
177,765
18 Dec 2025
⚡️ Gemini 3 Flash just got a major new capability: code execution for images.
Gemini can decide when to write code to zoom, count, and annotate—unlocking the next phase of Agentic Vision. 🤖
Wildly fun to PM this 0→1. Stay tuned to hear more 👀

🚀Excited to share that #Gemini 3 Flash can do code execution on images to zoom, count, and annotate visual inputs!
The model can choose when to write code to:
🔍 Zoom & Inspect: Detect when details are too small and zoom-in.
🧮 Compute Visually: Run multi-step calculations using code (e.g., summing line items on a receipt).
✏️ Annotate: Draw arrows or bounding boxes to answer questions or show relationships between objects.
5
10
99
8,907
17 Dec 2025
One of my fav parts of being a Gemini model PM - you get to work with billion-user Google products like AI Mode. The future of multimodal search is bright⚡️
17 Dec 2025

1/2 Gemini 3 Flash is here ⚡⚡⚡ Starting today, we’re rolling it out globally in Search as the default model in AI Mode (google.com/ai).
3 Flash brings the sophisticated reasoning capabilities of Gemini 3 to Search, without compromising speed. This means AI Mode better interprets your toughest, multi-layered questions – considering each of your constraints or requirements – and provides a visually digestible response with helpful links to explore further.
2
2
20
1,248
17 Dec 2025
🚀🚀🚀 Gemini 3 Flash is live⚡️⚡️⚡️
🧠 Gemini 3 Pro-level intelligence, but 📉 4x Cheaper and 🏎️ 3x Faster. We pushed the Pareto frontier, unlocking a new generation of multimodal agents.
🤯 We’re already seeing @figma accelerate rapid prototyping, @Harveyaisol master complex legal reasoning, and @Bridgewater unlock investment insights from massive unstructured datasets.
🤖Try now at gemini.google.com or start building at aistudio.google.com. Read more at lnkd.in/gsPv542a
👏🏼Huge shoutout to the team! @jalayrac @RSoricut @bcaine @xf1280 @IoanaBica95 @MarioLucic_ @BiboXu @tulseedoshi @OfficialLoganK @joshwoodward @demishassabis
1
15
120
5,306
7 Dec 2025
gemini 3 is our bet that the future of AGI is multimodal
I unpack the thinking behind the evals @demishassabis just shared here → goo.gle/3Mt3UlT
7 Dec 2025

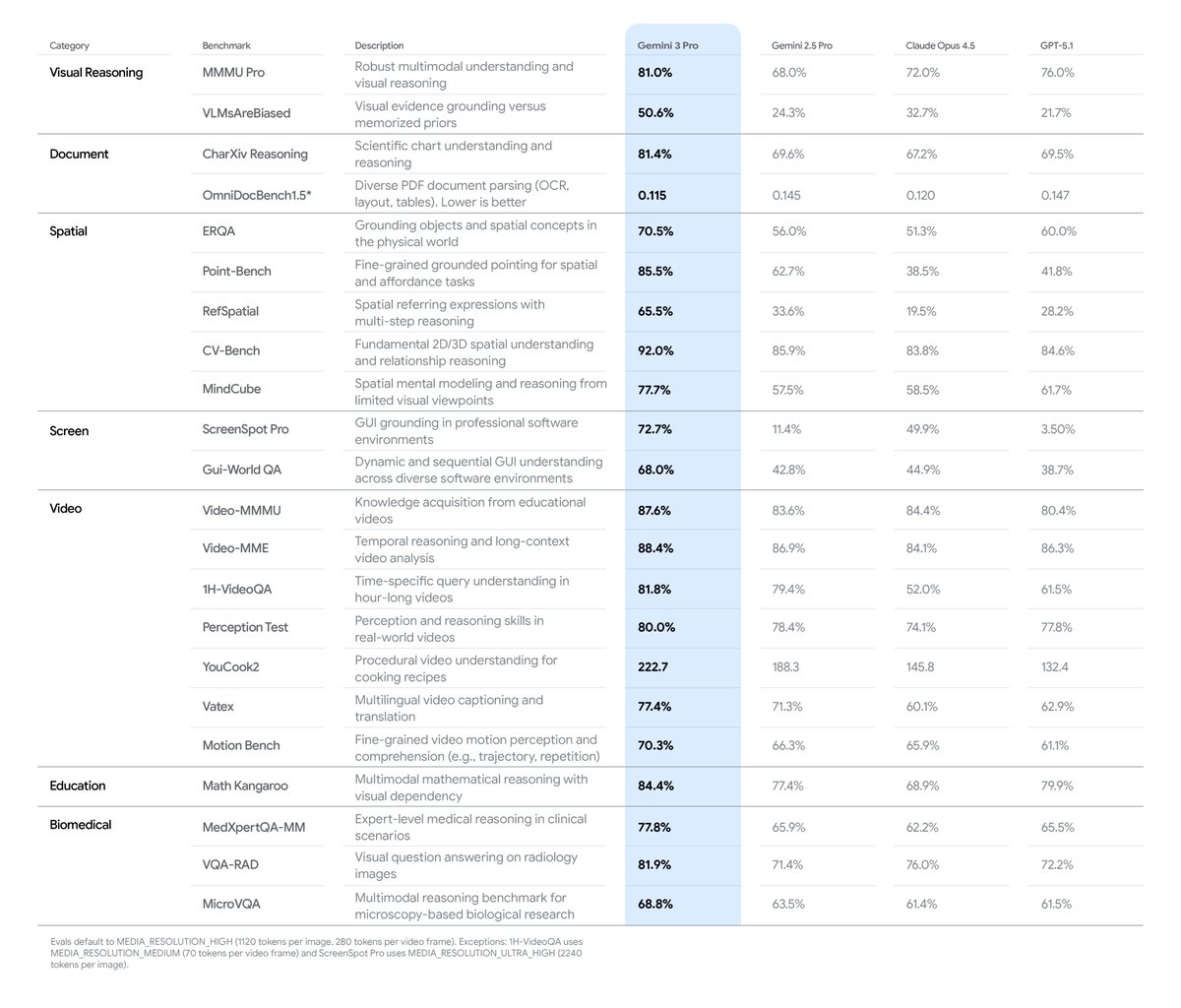
Gemini has always had exceptionally strong multimodal capabilities. Gemini 3 Pro is an incredible vision AI model and is SOTA across all main vision & multimodal benchmarks. It’s great for document, screen, image, video & spatial understanding tasks - try now in the @GeminiApp!
11
16
254
50,466
Rohan Doshi retweeted
5 Dec 2025
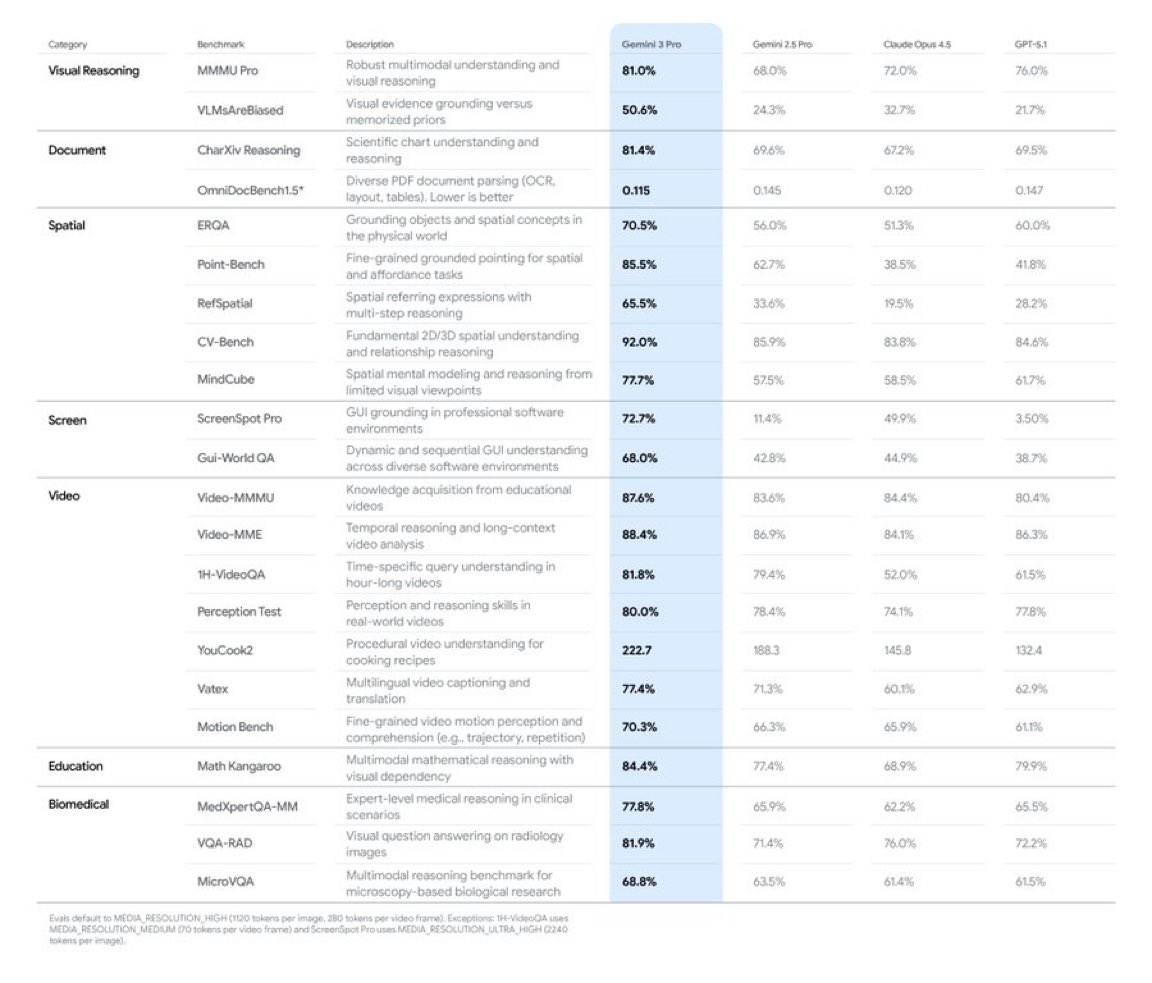
Gemini 3 Pro continues to be SOTA on most multi-modal benchmarks and use cases!
98
67
1,224
80,864

One aspect of our Gemini 3 Pro model to look at is how it performs in multimodal capabilities. We've worked on making it perform really well across a variety of multimodal use cases, like understanding of documents, videos, spatial characteristics, biomedical data, and computer sceens, and being able to reason about visual information.
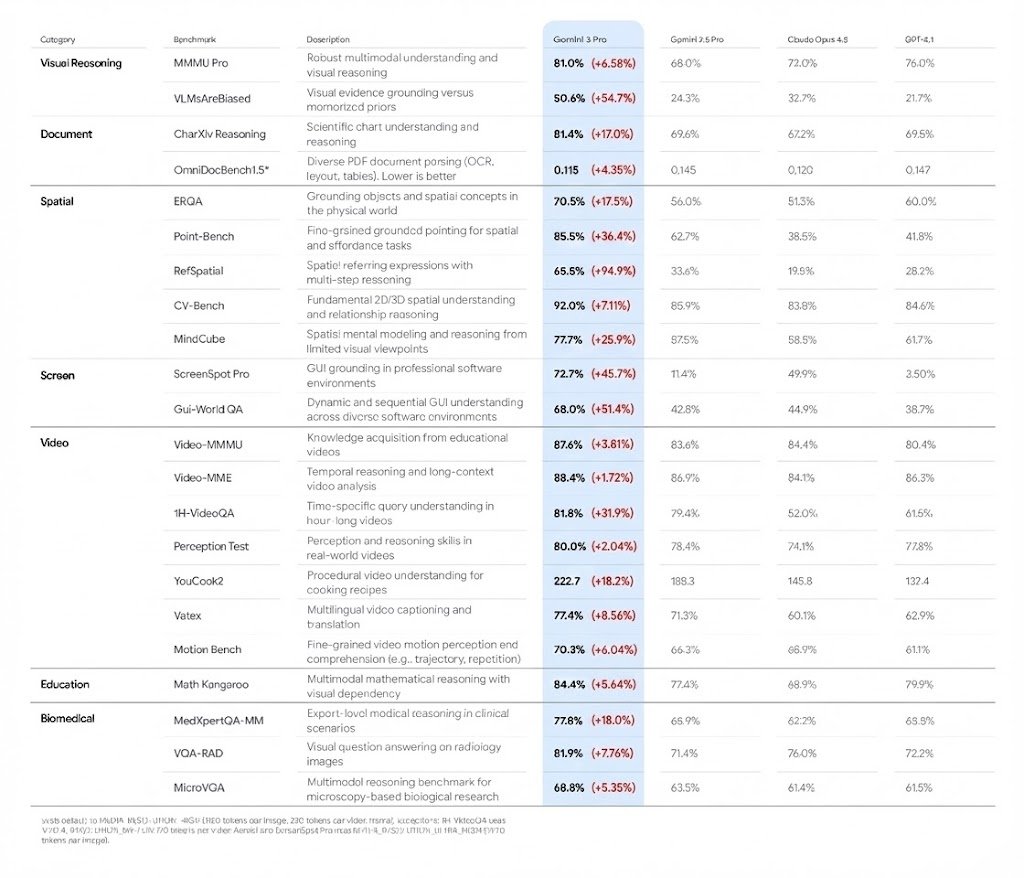
To test it out, I gave the original image from the blog post below, and asked it:
Please make a version of this figure with the Gemini Pro column annotated with the relative improvement versus the best result from the other three columns in red
(This in itself is a pretty difficult visual reasoning task! It did pretty well at doing this accurately on some spot checking, and those relative accuracy improvements are quite large across some of the benchmarks!)
Read more below or in the blog post at:
blog.google/technology/devel…
5 Dec 2025
Gemini 3 Pro is the frontier of multimodal AI, delivering SOTA performance across document, screen, spatial, and video understanding.
Read our deep dive on how we’ve pushed our core capabilities to power hero use cases across:
Docs: "derender" complex docs into structured code (HTML/LaTeX)
Screen: build robust computer agents that automate complex tasks
Spatial: generate collision-free trajectories for robotics & XR
Video: analyze sports footage using high-FPS processing with "thinking" mode
See how these capabilities are transforming workflows in education, biomedical, and law/finance → goo.gle/3Mt3UlT

45
73
836
117,657