
Full-stack TypeScript. Building AI tools @ SimplicityLabs.io
Joined March 2009
- Tweets 4,902
- Following 919
- Followers 420
- Likes 7,886
625 Photos and videos









Pinned Tweet

11 Nov 2019
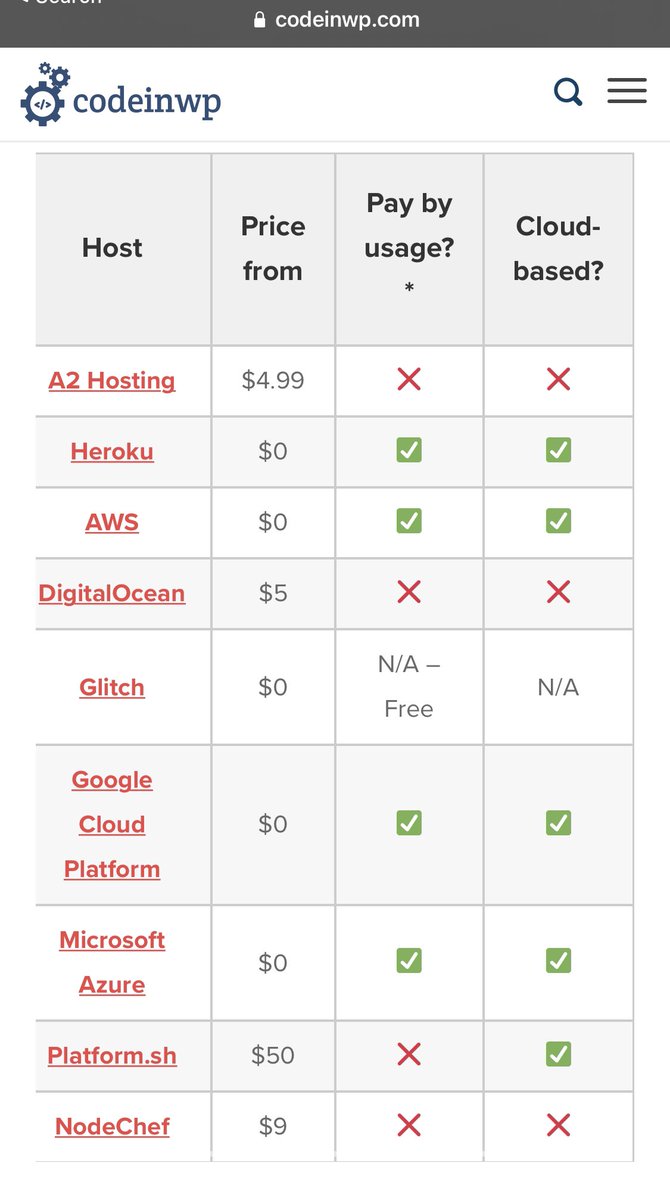
JS is the most versatile programming language out there.
With JS you can build:
- Frontend (Angular/React/Vue)
- Backend (Node/Nest)
- Database (Mongo)
- Mobile (Ionic/ReactNative/NativeScript)
There is so much cross over that you can excel quickly in many areas.
9
Jun 10
The live show was sick @wesbos / @stolinski 🫶
Thanks for coming to Amsterdam so I only had to get the ferry across the river 🤟
Dutch phrases I love:
🥜 Helaas pindakaas (unfortunately peanut butter == tough shit)
🍌 Gaan met de banaan (go with the banana == let’s go 🤟!!)


1
1
67

Cloudflare has acquired Vite / VoidZero
Void is vite's fullstack Intertia-like framework.
This gives Cloudflare control over the entire stack. They have all the primitives from frontend/backend framework, linting, testing, formatting, JS runtime, db, kv, inference, blob storage, access, etc...
smart move. A tidy package they can hand to an LLM to make a site.

80
137
2,105
223,916
👾Ro-NaN👾 retweeted

May 22
I am absolutely more productive using agents. I don't know the factor but it's large. However much of that productivity is spent tuning the agents and hardening the product. I'm guessing 30%-40%.
Some might consider that a waste; but I don't. The software I'm creating nowadays is vastly more robust than I'd ever been able to create manually.
I don't mean that the code is better. I mean the surrounding tests are vastly better. I have a higher degree of confidence than I ever had manually -- even when I used very disciplined TDD and Acceptance testing.
And then there's the ability to quickly reorganize the modules and the architecture while keeping those robust tests running. That is a tremendous boon.
119
188
2,225
302,662
👾Ro-NaN👾 retweeted

May 14
/grill-me is my most popular skill ever.
I get 5-10 messages a day about how it’s changed people’s workflows for the better
But… I’ve stopped using it for code. Here’s the improved version:
94
178
3,155
276,824
May 12
Super excited for Megathon in my own neighbourhood of Oostenburg, Amsterdam 📍
500 builders from Europe coming together to share ideas, build, and ship.
From business & design to developers & founders, everyone’s welcome.
Bring your own idea or join a team.
June 19 - 21 🇳🇱
2
7
104
👾Ro-NaN👾 retweeted

Apr 30
This is the the quote I've been citing a lot recently.
Feb 4

you can outsource your thinking
but you cannot outsource your understanding
851
4,389
46,843
2,600,522
👾Ro-NaN👾 retweeted
May 11
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status/2046982…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.

1,040
2,018
19,289
3,838,950

Proud to be Announcing MEGATHON: the biggest hackathon Europe has ever seen. Can't wait to be your host at this one!
June 19–21 · Amsterdam 🇳🇱
500 builders
Europe's most ambitious builders, designers, and founders competing in a tournament to build the greatest AI products.
🎟️ Sign-up link in comments.
As part of the organizing team, I'm giving away free tickets! drop a comment telling me what you want to build. The most innovative idea wins.
So let me know: what are you gonna build?!
brought to you by:
@MolliePayments
@tageuamsterdam
AMS Tech Week
Tulip
AI AM and more

4
3
17
900

Every app I vibe code has the tech stack below
Easy for beginners and free to start
If you've never built an app before, just paste this list into Codex or Claude Code and you'll be good to go:
Web framework: NextJS
Hosting: Vercel
Database: Convex
Auth: Clerk
Payments: Stripe
Styling: Tailwind
AI: logic- OpenAI, creativity- Claude, cheap tasks- Gemini Flash 3
Emails: Resend
Design apps with: GPT image gen 2 Claude Design
AI I use to build it all: Codex desktop app w/ GPT 5.5
Any questions let me know!
152
104
1,723
107,596
👾Ro-NaN👾 retweeted
Apr 20
Morning Bathrobe Rant: AI out-codes you; deal with it.
245
479
4,875
659,080
👾Ro-NaN👾 retweeted

Apr 18
Claude Design is insane.
❤️🔥Just recorded a 18-min tutorial on how to build animated, award-winning websites with Claude Design Opus 4.7!
338
2,136
25,610
3,267,270
Apr 19
RT @use_bruno: Postman removed free team collaboration.
Bruno collections live in Git.
No seat limits. No BS.
Migrate in minutes.

429

In Claude Code, the new /ultrareview command runs a dedicated review session that reads through your changes and flags what a careful reviewer would catch.
We've also extended auto mode to Max users, so longer tasks run with fewer interruptions.
65
117
3,067
698,657
👾Ro-NaN👾 retweeted

Apr 16
Opus 4.7 is in Claude Code today. It's more agentic, more precise, and a lot better at long-running work. It carries context across sessions and handles ambiguity much better.

Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
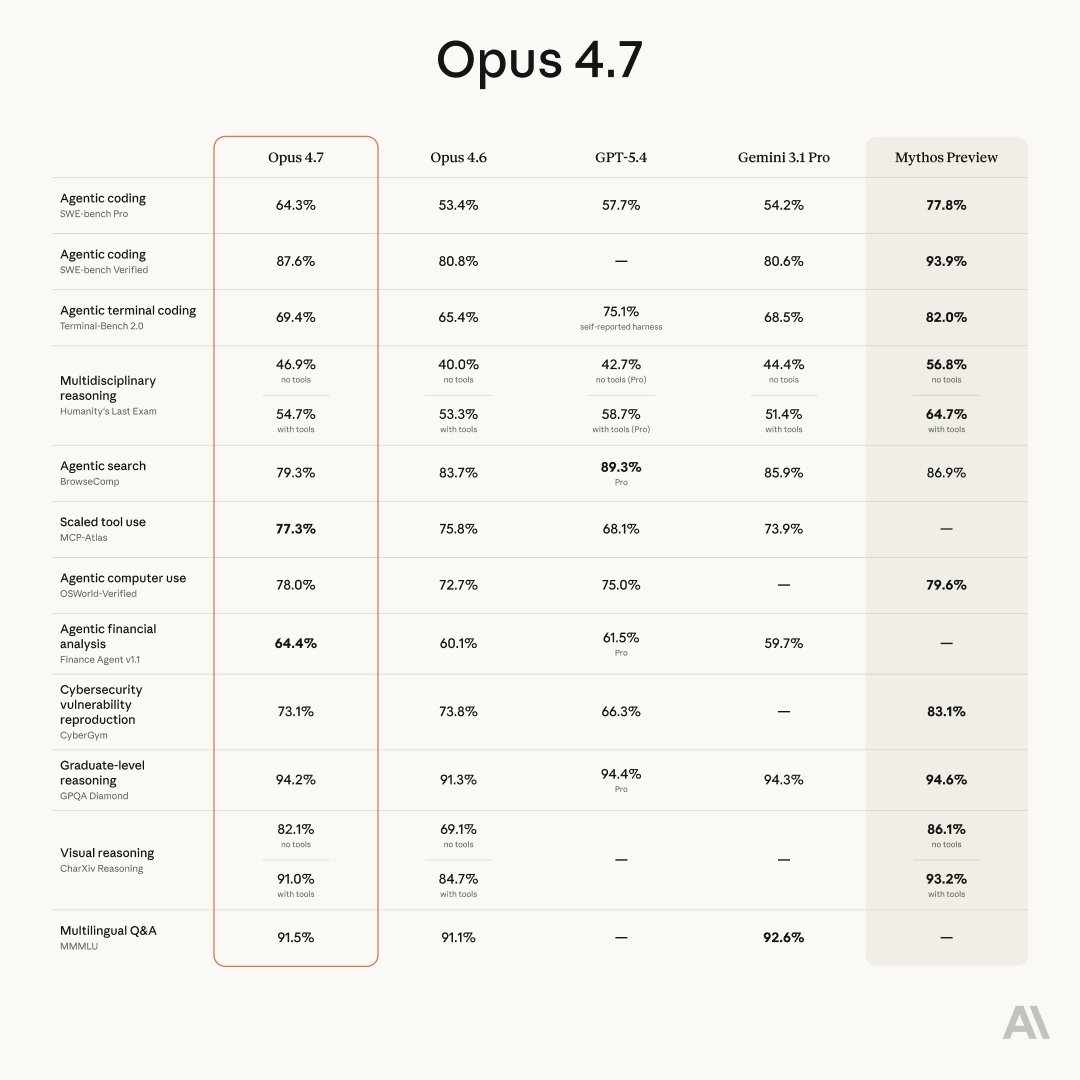
ALT Claude Opus 4.7 Benchmarks
373
181
3,043
235,591
👾Ro-NaN👾 retweeted
Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,120
2,827
26,776
7,145,366
👾Ro-NaN👾 retweeted
Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,888
7,238
59,801
21,366,651
👾Ro-NaN👾 retweeted
Mar 7
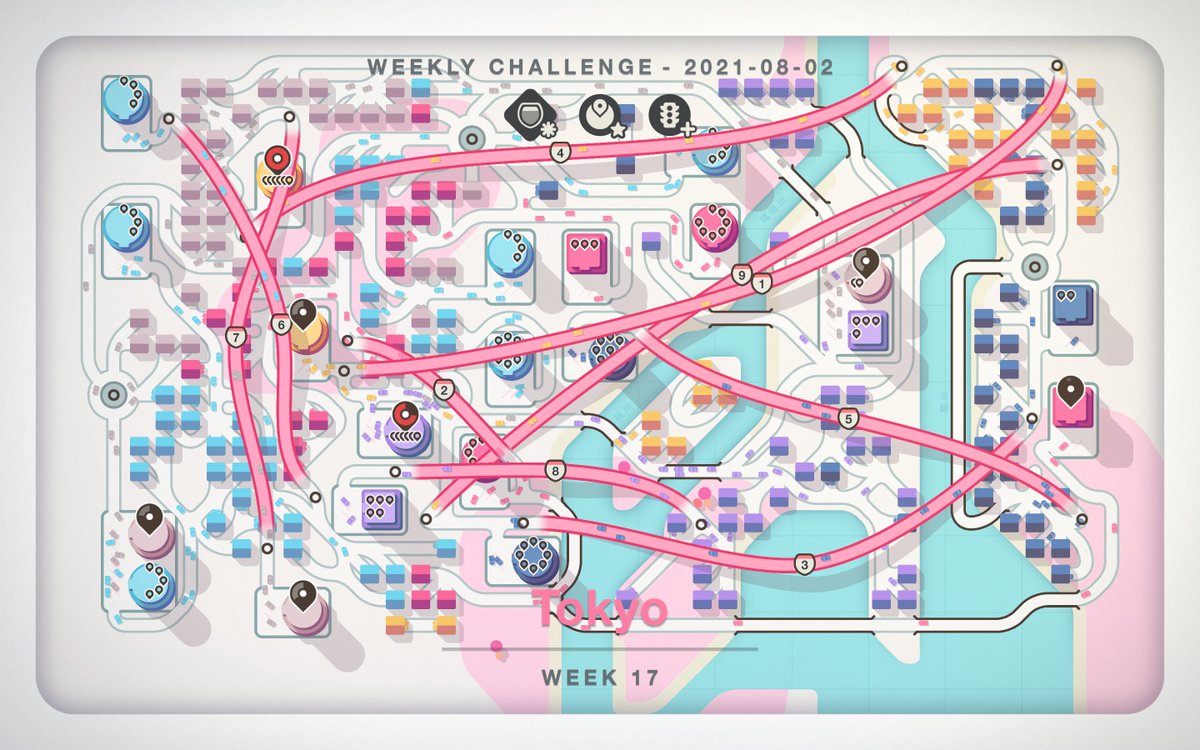
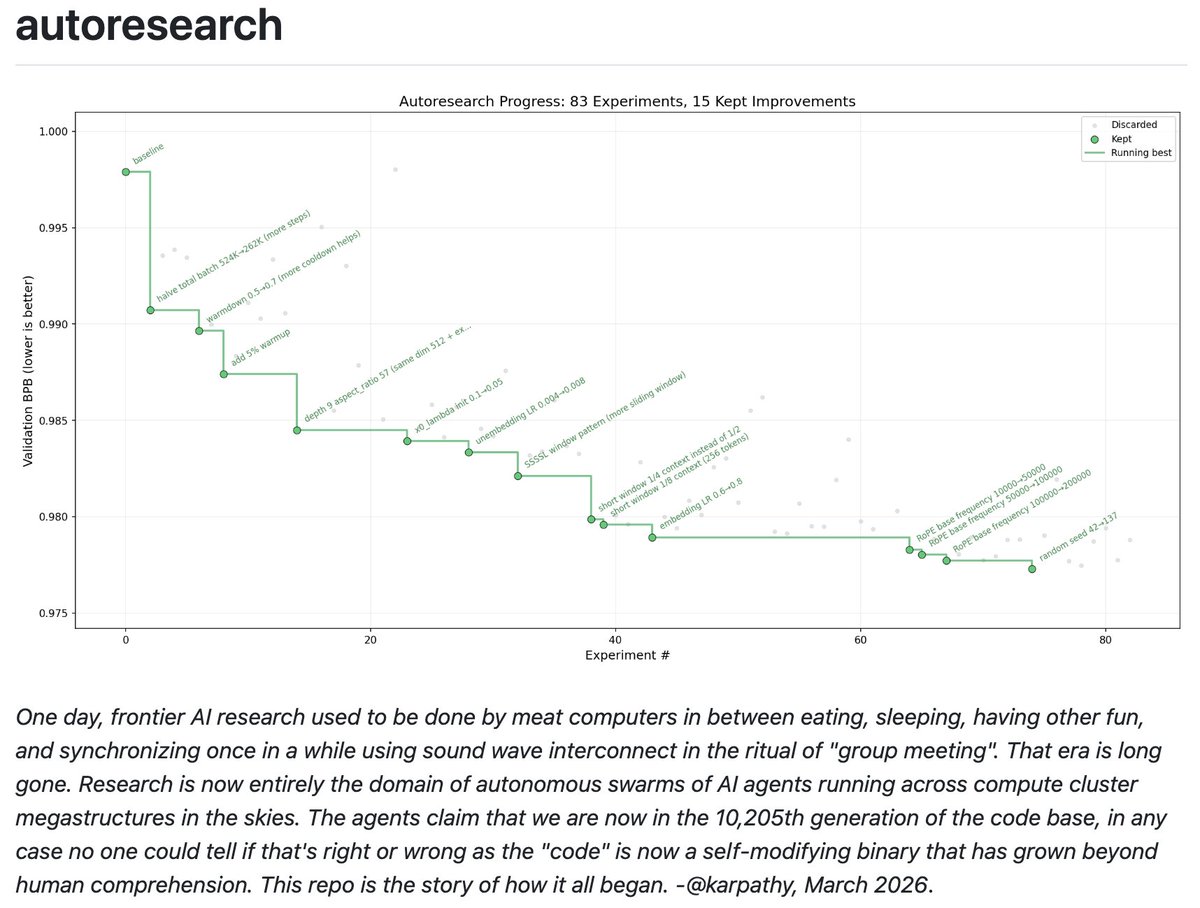
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autorese…
Part code, part sci-fi, and a pinch of psychosis :)
1,054
3,627
28,331
11,077,606