
RunAnywhere: The default way of running on-device AI at scale. Backed by @ycombinator
Joined July 2025
- Tweets 241
- Following 8
- Followers 1,343
- Likes 706
10 Photos and videos






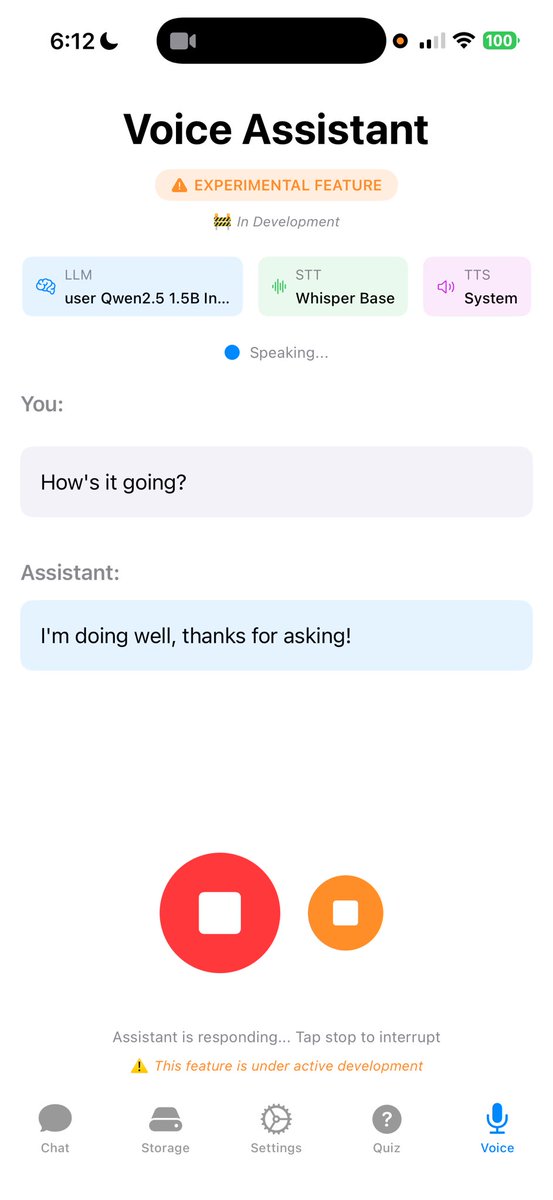
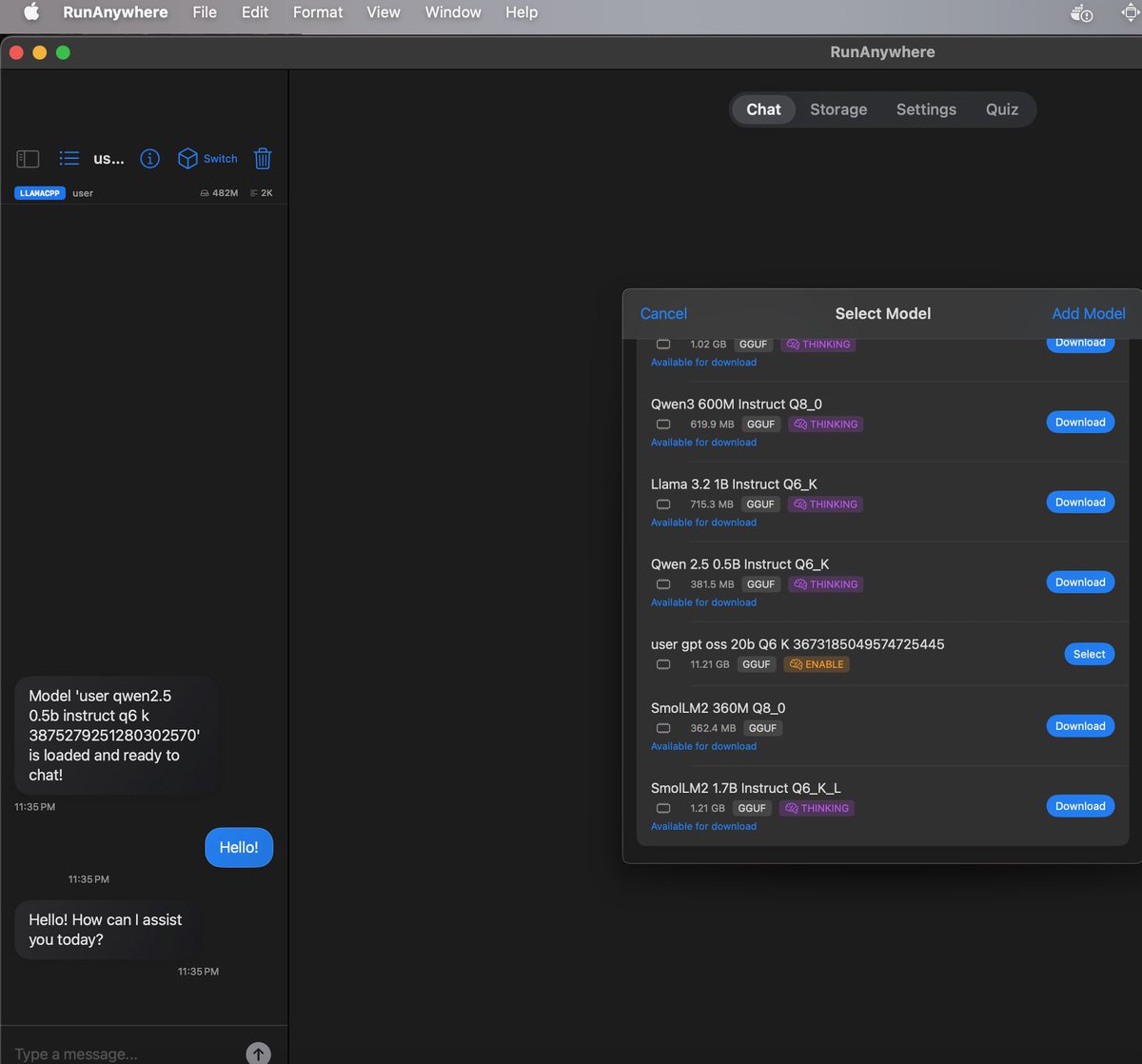


Pinned Tweet

7 Nov 2025
3
2
29
10,964
RunAnywhere (YC W26) retweeted

Jun 12
1
2
7
152
RunAnywhere (YC W26) retweeted

Jun 11
The most important AI document published this year wasn't written by OpenAI, Google, Anthropic, or Meta.
It was written by the Pope.
And its biggest warning isn't that AI becomes too powerful.
It's that AI infrastructure becomes too concentrated.
"Technology takes on the characteristics of those who devise, finance, regulate, and use it."
When a handful of companies own the models, the compute, and the distribution, they don't just shape technology.
They shape who gets to use it, on what terms, and for how long.
For enterprises, governments, hospitals, and law firms, that's not philosophy.
It's a procurement decision.
The biggest AI risk may not be the model you choose.
It may be who controls it.
That's why we're building @RunAnywhereAI: inference on hardware you control, with data that stays in your environment and no third party between you and the output.
Dependency isn't inevitable.
It's a design choice.

3
5
106
RunAnywhere (YC W26) retweeted
Jun 10
You're probably overpaying for AI.
Not because you chose the wrong provider.
Because you're comparing the wrong things.
Most people compare self-hosted inference to pay-per-token APIs and call it a fair fight.
It isn't.
On-prem loses:
• Low-volume APIs (<~$2K/month): serverless wins
• Burst-only workloads: cloud elasticity wins
• Early-stage experiments: start in the cloud
On-prem wins:
• Dedicated deployments for compliance
• Self-hosted inference with sustained utilization
• Privacy-sensitive workloads where cloud isn't practical
• High-volume inference above ~50% utilization
The biggest mistake is benchmarking low-volume cloud pricing against infrastructure built for sustained demand.
The right answer depends on your workload.
At @RunAnywhereAI, we'll tell you honestly which category you're in. If the math doesn't work, we'll say so.
#RunAnywhere #onprem #edgeai #inference

3
6
128
RunAnywhere (YC W26) retweeted
Jun 9
Jensen Huang just described the architecture of the next decade of AI.
Not a new model. Not a benchmark. Not a breakthrough in reasoning.
Architecture.
Watch the clip.
The core idea is simple:
- As AI evolves from chatbots into agents, context becomes everything. And context lives in your data.
- Inside hospitals. Inside factories. Inside banks. Inside governments.
The result is almost inevitable:
- The intelligence moves to the data.
- Not the data to the intelligence.
That's why local AI, private AI, sovereign AI, and on-prem AI are all gaining momentum at the same time.
They're not separate movements.
They're the natural consequence of deploying AI into the real world.
At @RunAnywhereAI, this is exactly what we build.
Inference that runs inside customer environments, on infrastructure they control, with intelligence that stays where the context already exists.
The AI industry spent the last few years obsessing over models.
The next few years will be about where those models run.
#AIInfrastructure #SovereignAI #LocalAI #EnterpriseAI #RunAnywhere
1
5
9
272
RunAnywhere (YC W26) retweeted
Jun 4
3
7
628
RunAnywhere (YC W26) retweeted
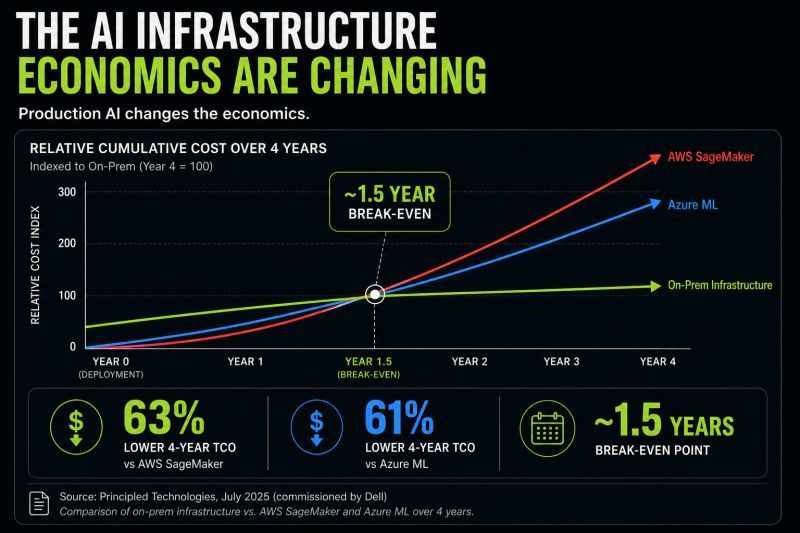
Honeywell's CTO said something publicly last week every enterprise AI budget owner should read.
They're increasingly pushing AI workloads beyond the public cloud and into a hybrid architecture. The reason is simple:
At production scale, inference economics start to matter.
And the numbers are starting to reflect that shift:
• 63% lower 4-year TCO vs AWS SageMaker
• 61% lower 4-year TCO vs Azure ML
• ~1.5 year break-even point
The break-even threshold for on-prem AI keeps falling.
What used to require extremely high utilization is now becoming viable for a much broader range of enterprise workloads.
These aren't frugal edge cases.
They're Fortune 500 companies running sustained, high-volume AI workloads where every token, request, and workflow compounds into recurring spend.
They ran the math and made an infrastructure decision.
At @RunAnywhereAI, we're building the inference infrastructure for when that math tips.
Proprietary inference engines running inside your own environment. No cloud bill scaling with every request.
If you're spending $10K per month on inference APIs, run the numbers.
The calculation has changed.
3
5
211
RunAnywhere (YC W26) retweeted
May 29
2
3
156
RunAnywhere (YC W26) retweeted
May 27
“The future of AI is going to be local models running on extraordinary desktop hardware.” - @Jason
This line from the recent @theallinpod hit hard.
For years AI meant sending everything to the cloud, paying per request, and hoping for the best on latency and privacy.
That era is ending.
@Apple Silicon, AI PCs, and high-memory desktops are shifting the game. Local inference brings lower latency, zero marginal cost, real privacy, and actual user control.
At @RunAnywhereAI, we're building exactly for this future: AI apps that run close to the user, understand private context, and work across devices without shipping your data to a third-party cloud.
The next wave won't just be won by the biggest models. It will be won by the models that run where the user is.
What workloads do you think go local first?
#localai #inference #runanywhere #edgeai
1
4
14
3,937
RunAnywhere (YC W26) retweeted
May 25
Microsoft just canceled internal Claude Code licenses because the bills got out of control.
Months ago, it was the hero tool. Thousands of employees using it. Teams told to build faster, ship faster, prototype faster.
Then the invoice showed up.
Usage exploded. Tokens exploded. Bills exploded. Finance noticed. Licenses started disappearing.
This isn't a Claude problem. It's the next 24 months of every AI rollout.
Everyone wants agents. Everyone wants AI in every workflow. Nobody is asking the actual question:
What happens when every employee uses AI all day, every day?
Cloud AI is cheap when usage is low. Agentic AI breaks that math. The more your deployment succeeds, the less you can predict next month's bill.
You're not paying for a model anymore. You're paying for every token, every request, every loop, every retry, every agent talking to another agent.
And you're handing the most critical part of your stack to a vendor whose pricing, limits, and policies you don't control.
The future is AI everywhere. That doesn't have to mean AI in someone else's cloud.
This is why we're building @RunAnywhere.
Run inference on your own hardware. Keep sensitive data in-house. Kill the unpredictable usage bill. Own the infrastructure instead of renting it back from a hyperscaler.
AI shouldn't grow into a line item that scales faster than your revenue.

1
2
5
334
RunAnywhere (YC W26) retweeted
May 21
1
2
4
190
RunAnywhere (YC W26) retweeted

10. @ShubhamMal72313 from RunAnywhereAI is building natively optimised inference and infrastructure for SLMs, and will be at the Delhi meetup.

2
6
565
RunAnywhere (YC W26) retweeted
May 15
1
2
7
373
RunAnywhere (YC W26) retweeted

May 13
just tried this out and it one-shotted* this video: "before the agent does anything"
*i generated the narrative using chatgpt and used that as a prompt. featuring: @e2b @runanywhereai @composio @mem0ai @firecrawl @browser_use @agentmail @covenantlabsai
some thoughts:
- i clearly tried to stick too much into 30 seconds, they talk very fast and lost some content which breaks logic
- character consistency is strong, i uploaded a single screenshot from my prior video as reference
- voice consistency was not automatic. you notice unicorn switch from female to male voice part way through
- the agent gives you an editor with generated scenes broken up but i don't see a way to regenerate a single section in the UI (which would be nice)
- it is definitely a much better experience to have the agent stitch videos together than doing it yourself (i was using canva). was trying @flymy_ai's media agent api for it this weekend which also works well and with other models

Meet Runway Agent. Your new AI creative partner that helps you ideate and execute fully finished, sound designed and edited videos. All with just a simple conversation. From ads to shorts to content for social, Runway Agent makes it easy to make more of what you need.
Get started on web at the link below.
7
6
28
7,170
RunAnywhere (YC W26) retweeted
May 11
”Localmaxxing, pushing more inference to local models, is an inevitable response to tokenmaxxing.“
May 11

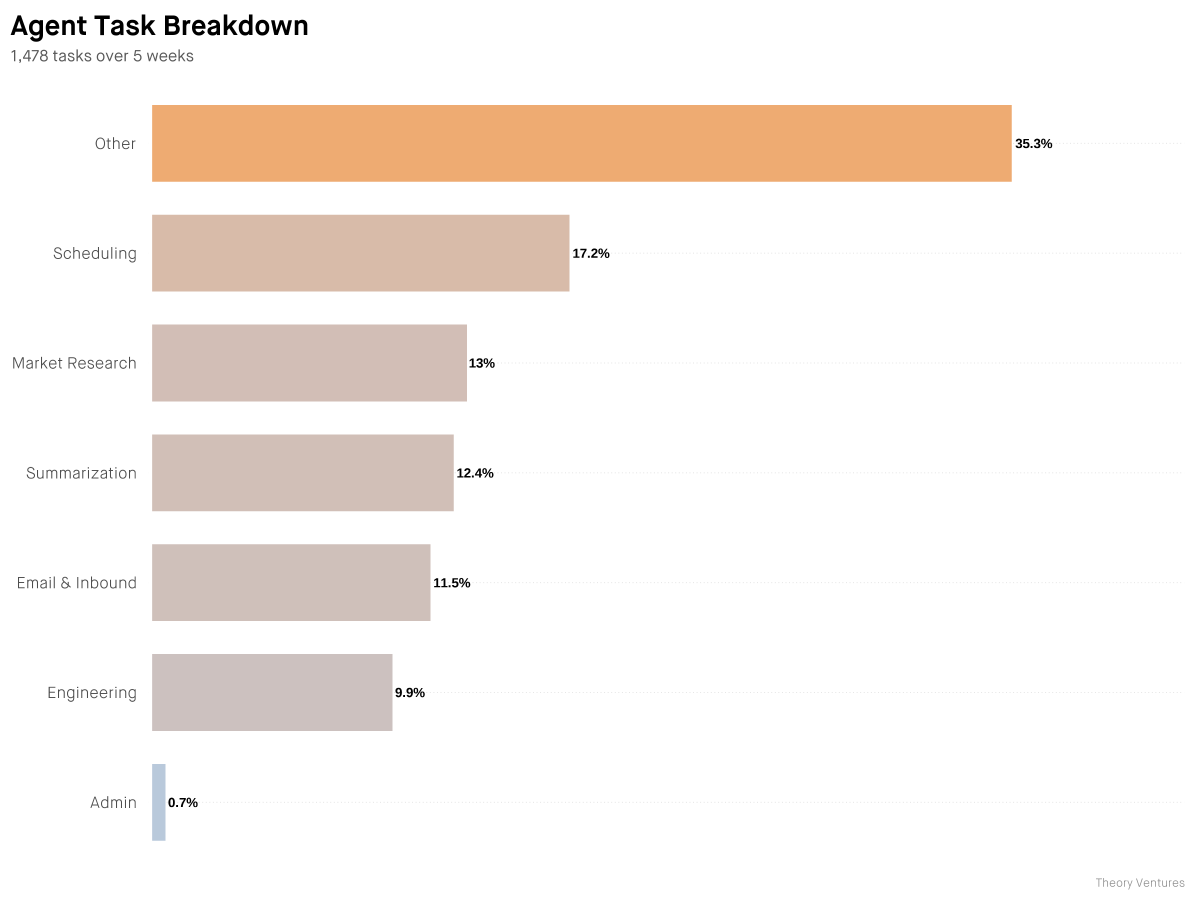
Localmaxxing : pushing more inference to local models.
Over five weeks, I tested how much of my daily work can run on a local 35B model instead of cloud frontier models. The answer : half.
Many reasons to use local models : privacy, cost, asset depreciation.
But the only one that really matters is latency.
I ran a head-to-head benchmark. Qwen 3.6 35B-A3B-4bit on my MacBook Pro M5 vs Claude Opus 4.5 via API.
Result : 2.1x faster locally. Mean 2.8s vs 5.8s.
The local model isn't smarter. Opus scores ~20% higher on reasoning benchmarks. Local models lag frontier by 3-4 months, and for complex tasks, that gap matters.
But for routine agent tasks, it rarely does.
If half the work runs 2x faster on my laptop, I'll take that trade every time.
My little computer is about to earn its keep.
tomtunguz.com/localmaxxing/
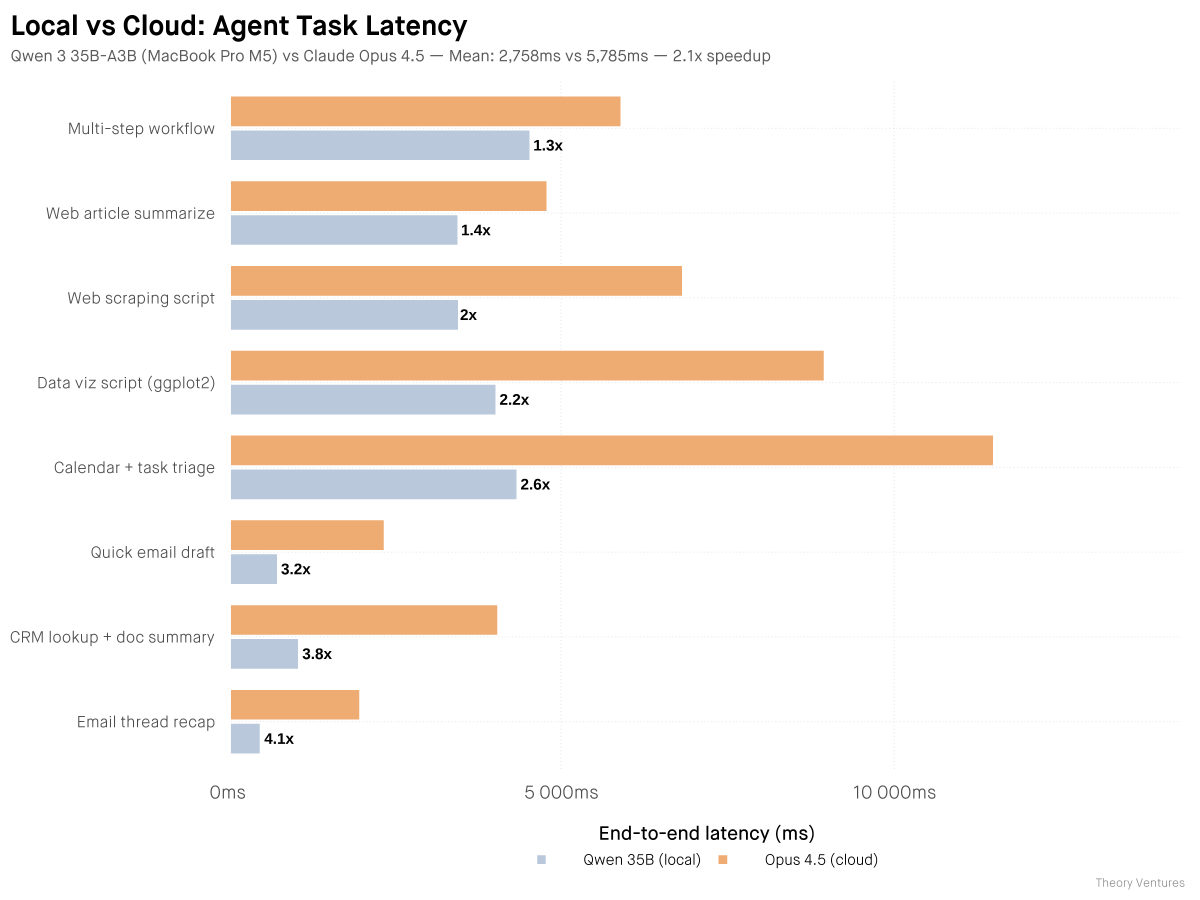
1
3
436
RunAnywhere (YC W26) retweeted
May 10
1
4
11
507
RunAnywhere (YC W26) retweeted
May 8
1
2
5
297
RunAnywhere (YC W26) retweeted
May 1
1
2
9
412
RunAnywhere (YC W26) retweeted
Apr 23
Thanks @NotebookLM, Notebooklm pod dropping soon as part of the newsletter :)


1
6
1,157
RunAnywhere (YC W26) retweeted
Apr 23
1
3
25
5,530