
We advance state-of-the-art #AI techniques paving the path for innovative products at @Salesforce. Focus areas: #AIAgents, #EnterpriseAI, #EGI, and #TrustedAI.
Joined September 2014
- Tweets 1,959
- Following 423
- Followers 19,742
- Likes 1,656
893 Photos and videos









Pinned Tweet

11 Sep 2025
Looking for the cutting-edge of AI research? Follow Salesforce AI Research to see how we're transforming enterprise technology through advanced innovations. From world models to agentic systems, discover the future of AI before it hits the market.
37
434
2,444,223
Model cards are nutrition labels for AI. Now they include environmental impact. 🌱
@Salesforce is adding standardized energy carbon metrics to its AI model cards: sforce.co/4umu8qm
Salesforce AI Research worked with the Impact team to embed these estimates into the standard model evaluation workflow, so a model's footprint is measured alongside its performance. They cover energy use and emissions across pre-training, post-training, and inference, using the AI Energy Score methodology.
The Environmental Impact section is live now in the model cards for First Name Match, Account Match, and TextEval. Browse them on the Salesforce Trust site: sforce.co/4eaIwMu
#ResponsibleAI #Sustainability #FutureOfAI
1
3
418
Salesforce AI Research retweeted

Jun 4
Excited to be at #CVPR2026 this week and to present my internship work with @SFResearch: Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding
In this work, we study how multimodal agents can actively reason over long videos by iteratively seeking the most relevant evidence, rather than passively processing all video content at once.
If you’re attending CVPR, feel free to stop by our poster!
📍 #245, Findings Posters, ExHall A
📅 Sunday, June 7
🕢 7:30 – 9:00 AM
Project page: activevideoperception.github…
Looking forward to connecting at CVPR!
#CVPR2026 #ComputerVision #MultimodalAI #VideoUnderstanding #AIAgents

1
5
14
1,117
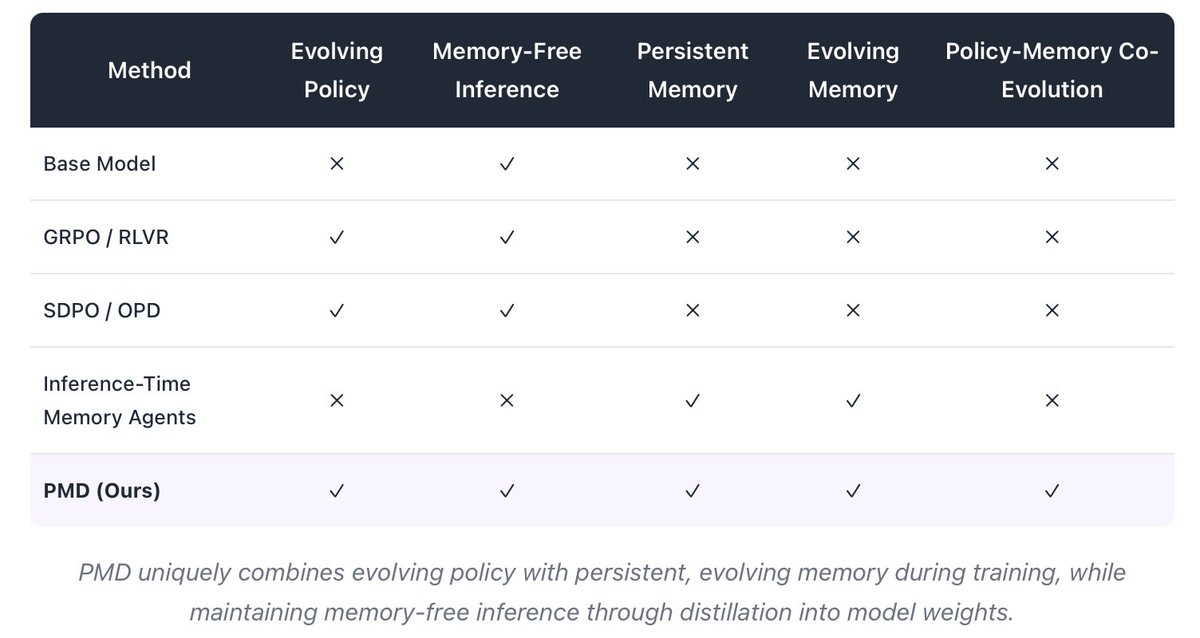
(1/8) Can Language Models Remember What They Learn? LLMs learn from feedback. But most post-training is amnesiac: rollout → reward → update → forget.
What if you keep the signal?
Procedural Memory Distillation (PMD): learning from experience, not just feedback. 🧵
1
1
15
1,601
(7/8) PMD doesn't give models a permanent notebook. It lets them use one while learning, absorb the useful lessons into their weights, and move on. Every training step contains signals about what works and what fails. Most methods throw it away.
📄 Paper: sforce.co/4dXlVTE
1
203
(8/8) Authors:: Ye Liu @YeLiu918, Srijan Bansal @SrijanBansal1, Bo Pang @bo_pang0, Yang Li, Zeyu Leo Liu @ZEYULIU10, Yifei Ming @ming5_alvin, Zixuan Ke @KeZixuan, Shafiq Joty @JotyShafiq, and Semih Yavuz @semih__yavuz.
📝 Blog: sforce.co/4dAjQOu
1
268
The 6th Multimodal Algorithmic Reasoning Workshop at #CVPR2026 is Thursday (6/4) morning 🗓️ sforce.co/4ueOT7j
Bringing together researchers across academia and industry to explore advances in multimodal reasoning, foundation models, agentic reasoning, and the future of intelligent reasoning systems.
Keynote speakers:
🔹 Juan Carlos Niebles @jcniebles, Salesforce AI Research
🔹 Jiayuan Mao — U. of Pennsylvania
🔹 Melanie Mitchell — Santa Fe Institute
🔹 Jialong Wu — Tsinghua University
Room 601, Colorado Convention Center | 8:55 AM – 12:30 PM MDT
Thanks to Honglu Zhou @zhou_honglu (Research Scientist at @SFResearch) and sponsors @merl_news and @ElorianAI
1
5
909
Can Language Models Remember What They Learn? Introducing Procedural Memory Distillation (PMD): sforce.co/4dAjQOu
PMD turns model attempts into reusable training memory, conditions a self-teacher on it, and distills the guidance into the student's weights.
3
21
3,269
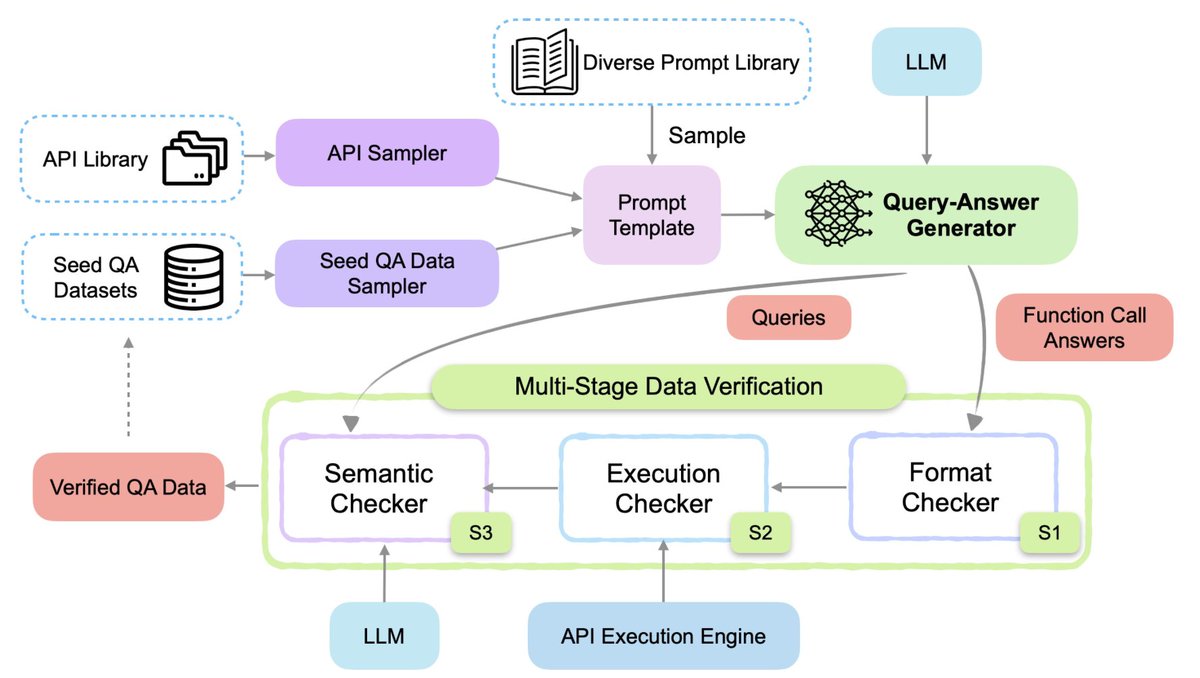
Accepted to #ICML2026: MFCL-Audio — a benchmark for voice agents that have to call tools.
Real speech is messy. Accents, background noise, mumbling, and "wait, what did I say?" moments all break tool calls. MFCL-Audio measures how badly, across 6.2K tasks.
Authors: Huanzhi Mao, Aditya Ghai, Imra Dawoodani, Tony Ginart, Shishir G. Patil, John Emmons, Joseph E. Gonzalez
#FutureOfAI #EnterpriseAI #VoiceAgents
1
8
1,104
📣 Counterparty Modeling is Not Strategy: The Limits of LLM Negotiators sforce.co/3RTTU7Q
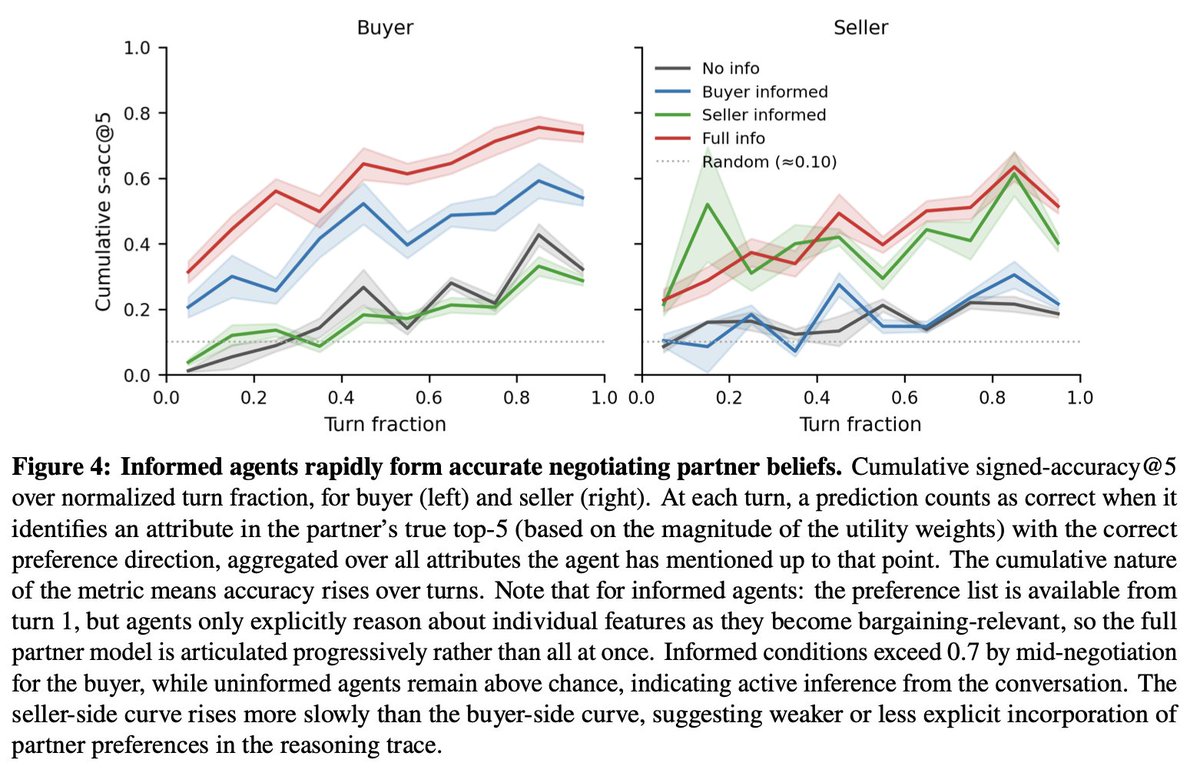
New research finds LLM agents can model a negotiating partner's preferences accurately, but don't reliably turn that knowledge into strategic bargaining.
➡️ Asymmetric information backfires: giving sellers the buyer's preferences raised buyer utility while seller utility fell
➡️ Agents accurately read the room early on, but fail to convert this social understanding into reciprocal, multi-turn exchange
➡️ Final deals are driven by opening price anchors rather than latent utility structure
➡️ Forcing explicit give/ask trade plans doesn't close the gap, proving that a model's ability to reason about a variable doesn't mean it can execute it in interaction.
The problem isn't that models fail to read the room; they form accurate early beliefs about the opponent. The breakdown is downstream: they fail to convert social understanding into multi-turn strategic execution. Showing a capability in a reasoning trace does not mean the model can deploy it in sequential interaction.
Authors: Romain Cosentino @Rom_Cosentino, Sarath Shekkizhar @shekkizh, Adam Earle, Silvio Savarese @silviocinguetta
#FutureOfAI #EnterpriseAI #AgenticAI

2
7
877
1/5 RLVR trains LLMs with pass/fail rewards — but every near-miss rollout is wasted.
What if models could actually *learn* from their mistakes?
New paper: "Learning from Language Feedback via Variational Policy Distillation"
Read: sforce.co/4uv2f0k 🧵👇
2
10
62
14,423
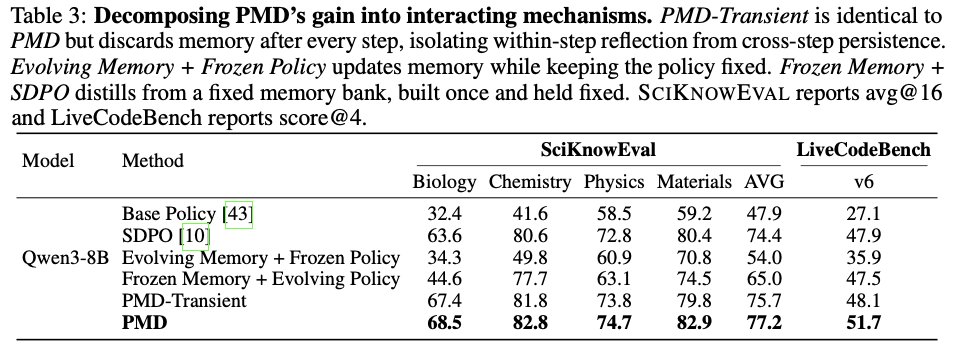
4/5 Tested on 3 model families (Qwen3-4B/8B, Llama-3.1-8B) across code generation (LiveCodeBench) and scientific reasoning (SciKnowEval):
✅ Consistent gains over GRPO and self-distillation baselines
✅ Stable training where prior methods collapse
✅ Best gains on domains with rich error signals (code, science)
1
3
485
5/5 Binary rewards leave information on the table. Teaching models to interpret why they failed, not just that they failed, unlocks a complementary learning signal.
Paper: sforce.co/4uv2f0k
Authors: Yang Li @YangL95, Erik Nijkamp @erik_nijkamp, Semih Yavuz, @semih__yavuz, Shafiq Joty @JotyShafiq
3
463