
Jun 8
What if a video’s meaning is not in what it shows, but in what it implies?
Excited to share VidMsg 🎥🧠 — a new benchmark for implicit message understanding in short, internet-native videos.
Project: iyttor.github.io/VidMsg/
#MultimodalAI #VideoUnderstanding #AIResearch
1
4

Jun 4
Excited to be at #CVPR2026 this week and to present my internship work with @SFResearch: Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding
In this work, we study how multimodal agents can actively reason over long videos by iteratively seeking the most relevant evidence, rather than passively processing all video content at once.
If you’re attending CVPR, feel free to stop by our poster!
📍 #245, Findings Posters, ExHall A
📅 Sunday, June 7
🕢 7:30 – 9:00 AM
Project page: activevideoperception.github…
Looking forward to connecting at CVPR!
#CVPR2026 #ComputerVision #MultimodalAI #VideoUnderstanding #AIAgents

1
5
14
1,117

May 21
From omni-modal understanding and synchronized audio-video reasoning, to GUI operation and sophisticated multi-step workflows, the model is designed for production AI systems that need to understand, reason, and execute reliably at scale.
This includes:
→ long-video understanding
→ interactive applications
→ Coding Agents
→ GUI automation
→ customer operations
→ knowledge workflows
The key difference is efficiency.
These capabilities are available in a lightweight omni-modal model designed for better performance per unit of compute.
Production AI needs more than benchmark strength.
It needs benchmark strength that can scale.
The latest Dola Seed 2.0 Mini is also now available. It supports omnimodal understanding, with reduced reasoning overhead and higher token efficiency than the previous version.
Try Dola Seed on BytePlus ModelArk for free now:tinyurl.com/49skedvv
Or book a free consultation: byteplus.com/en/contact-us
#AI #Developers #AIAgents #VideoUnderstanding #ImageUnderstanding #AudioAI #Coding #GUIAutomation #DolaSeed
2
2
5
1,125

🚨 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗔𝗜 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗔𝗹𝗲𝗿𝘁! 🚨
How can AI truly understand lengthy medical videos when crucial evidence is sparse, subtle, and hidden among hours of redundant footage?
@HKUST presents 𝗠𝗲𝗱𝗛𝗼𝗿𝗶𝘇𝗼𝗻, an innovative benchmark for long-context medical video understanding in the wild.
By Bodong Du, Bowen Liu, Yang Yu, Xinpeng Ding, ZhihengWu, ShuningWang, Shuo Nie, Naiming Liu, @CQFHK, @yqsong and @xiaomeng_hkust
Now you can watch and listen to the latest Medical AI papers daily on our YouTube and Spotify channels!
YouTube: youtu.be/vYwZyVIFxB0
Spotify: open.spotify.com/show/4edRuS…
Here's why it's exciting: 👇🧵 1/n
#MedicalAI #Healthcare #LongContextAI #VideoUnderstanding
[1/9]

1
1
4
218

Apr 15
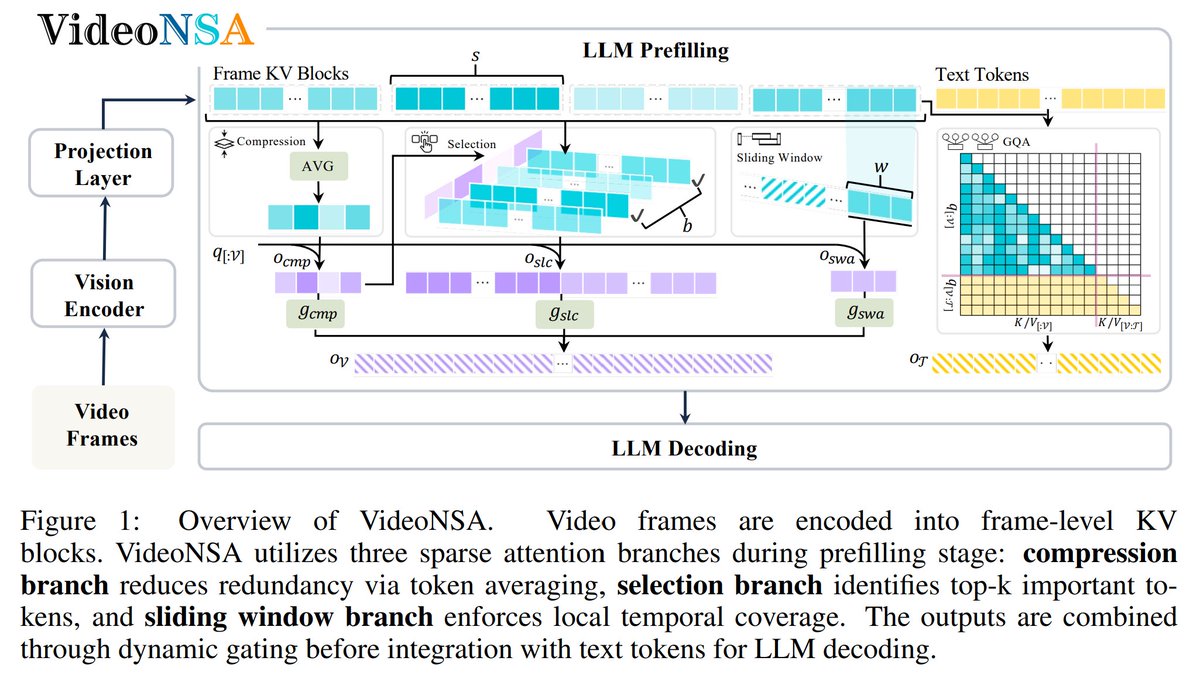
🚀 Excited to share our work on Sparse Attention for Multimodal LLMs, which is accepted to ICLR 2026 @iclr_conf
🤝 We collaborated with UCSD @UCSDJacobs , Princeton University @Princeton , New York University @nyuniversity , and Lambda
@LambdaAPI.
📄 “VideoNSA: Native Sparse Attention Scales Video Understanding”
🔗 Paper: arxiv.org/pdf/2510.02295
⚙️ page: enxinsong.com/VideoNSA-web/
👉Long-video understanding remains a key bottleneck for multimodal LLMs.
We propose VideoNSA, a learnable, hardware-aware sparse attention framework for video:
• 🎥 Dense attention for text native sparse attention for video
• 🧠 Learns task-adaptive sparsity instead of compressing tokens
• ⚙️ Scales reliably to 128K context length
Key insights:
• 📐 Optimal global–local attention allocation under fixed compute
• 🔄 Task-dependent sparsity patterns emerge
• 🌊 Dynamic “attention sinks” learned automatically
Results:
• 🔥 Strong gains on long-video understanding, temporal reasoning, and spatial benchmarks vs. token compression & training-free sparse methods
Takeaway:
✨Don’t compress tokens. Instead, learn where to attend. Sparse attention is the key to scaling vision-Language models.
👏 Huge shoutout to our collaborators: @EnxinSong @wenhaocha1 @shushengyang @EthanArmand2 @shan_xiaojun @HaiyangXu3110 @jianwen_xie @mlpcucsd and Zhuowen Tu.
#ICLR2026 #MultimodalLLM #VideoUnderstanding #SparseAttention #LongContext #ComputerVision #VideoNSA
1
13
51
4,274
Apr 10
AI that talks → AI that works. 🧠⚡️
Dola-Seed 2.0 Pro is here—our flagship execution engine designed for the next generation of autonomous agents. From reasoning over pixels to navigating software and deploying code, it moves enterprise AI from Analysis to Action.
Stop chatting. Start doing. 🛠️
Read the full article here: x.com/BytePlusGlobal/status/…
#BytePlus #DolaSeed #EnterpriseAI #AIAgents #ModelArk #ImageUnderstanding #VideoUnderstanding

1
1
11
1,537
Mar 26
The next phase of enterprise AI isn’t just generation; it’s understanding execution. The "Autonomous Enterprise" starts today. 🚀
Dola Seed 2.0 Pro is built for that shift: multimodal, agent-ready, and designed for production-scale deployment.
The API is now live on BytePlus, with access via ModelArk and partner platforms.
Ready to scale your intelligence?
🔗 Try it now → tinyurl.com/45nmm2c8
📅 Book a free consultation session → byteplus.com/en/contact-us
(6/6)
#BytePlus #DolaSeed #EnterpriseAI #AIAgents #ImageUnderstanding #VideoUnderstanding #ReasoningModel #ModelArk #OpenClaw

1
4
929
Mar 25
Introducing Dola Seed 2.0 Pro, referred to below as Seed 2.0 Pro
We have launched Seed 2.0 Pro, our most capable model in the Dola Seed 2.0 series, engineered to power the next generation of autonomous AI agents.
Enterprise AI is moving beyond models that simply analyze text or images.
What businesses increasingly need are agents that can understand, reason, use tools, and execute tasks across complex workflows.
That is exactly what Seed 2.0 Pro is built for.
Seed 2.0 Pro combines strong reasoning with advanced image understanding and video understanding, giving enterprise agents the ability not only to interpret information, but also to take action.
It is designed for high-value, multi-step enterprise workflows, with strong performance in:
- tool calling
- workflow execution across enterprise systems
- agentic task completion
- browser and computer use
This makes Seed 2.0 Pro a powerful engine for a wide range of agent scenarios, from daily office automation and deep web research to in-depth report drafting, financial analysis, content moderation, physical inspection, and video creation workflows.
It is also highly optimized for @openclaw and ReAct architectures, helping enterprises build agents that can navigate digital interfaces, enter information, and complete tasks with high reliability.
In short, Seed 2.0 Pro is not just built to generate insights. It is built to serve as the brain and execution engine for enterprise AI agents.
And it brings these capabilities at a highly attractive price point, making advanced agent deployment more practical for enterprise teams.
Try Seed 2.0 Pro for free: tinyurl.com/45nmm2c8
Or book a free consultation: byteplus.com/en/contact-us
#BytePlus #DolaSeed #EnterpriseAI #AIAgents #ImageUnderstanding #VideoUnderstanding #ReasoningModel #ModelArk #openclaw
37
49
384
95,934

Our paper is Oral at @wacv_official THIS WEEK! 🎉🚀🔥
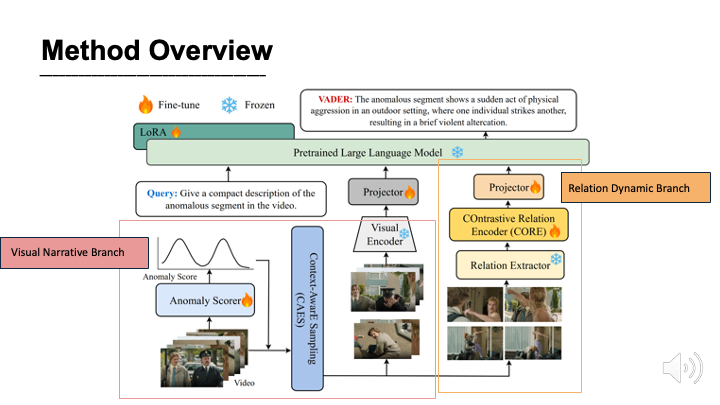
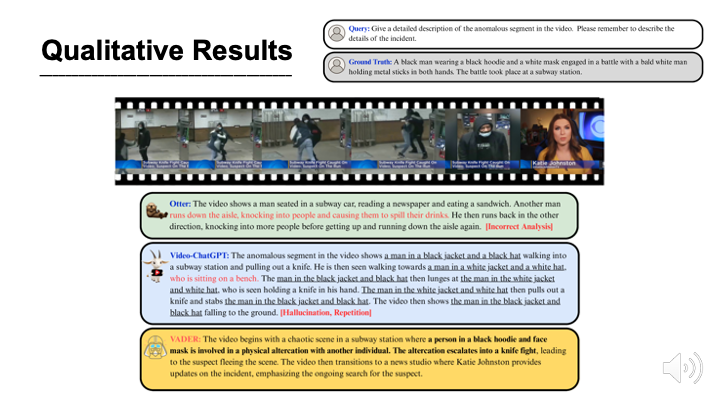
VADER: Towards Causal Video Anomaly Understanding with Relation-Aware Large Language Models
Tired of detectors just shouting "🚨anomaly!" with zero insight? 😩
VADER levels up BIG:
✅ Describes exactly what happened
✅ Explains the causal why 🤔
✅Reasons step-by-step on object dynamics & interactions like a video detective 🕵️✨
Powered by:
🌟CAES — smart keyframe sampling to catch the full causal story 📸
🌟CORE — contrastive encoder for evolving relations, temporal links & volatility ⚡
SOTA on HIVAU-70k & HAWK benchmarks 📈
🌐Project page: vader-vau.github.io/
See us live at WACV!
🗣️ Oral (Session 8B – Video Rec & Understanding II): Tue Mar 10, 13:30–14:30, AZ Ballroom 7
🖼️ Poster (Session 6): Tue Mar 10, 15:45–17:30, Tucson Ballroom
See you in Tucson! 🌵
#ComputerVision #AnomalyDetection #VideoUnderstanding #MultimodalAI #LLM #CausalAI #WACV2026

1
4
55
3,604

Feb 14
Happy Valentine’s weekend, CT ❤️🍿
If you’re already watching Netflix with your person (or your whole household), you might as well make it count.
@RumiLabs_io lets you earn points in the background while you stream, just install once and press play.
One Netflix account can be used by multiple people (as long as Netflix allows it).
Each person should have their own Rumi account and yes, multiple people in the same household can each run Rumi individually.
Auto mode isn’t just “free farming” either it requires a capable device and does meaningful indexing work for the extension.
So whether it’s date night, family binge night, or solo comfort watch season…
why not earn while you stream?
Start here → rumi.io
Also don't forget to join the discord channel not to miss out on any close news and also you can ask questions there
Enjoy the love, the shows, and the rewards this weekend 💕✨
#Rumi #WatchAndEarn #AI #VideoUnderstanding #ValentinesDay

1
3
40
Feb 13
Happy building season ✨
What I respect about @RumiLabs_io’s benchmark is this: it’s not about tuning for one flashy model.
It’s about measuring the real lift from their Video Intelligence framework.
The two big deltas?
• Offline preprocessing across 11 dimensions
• A hierarchical Story Base with explicit temporal links
Baseline: Gemini 2.5 Pro. Full episode in one context window. No internet. Then blind judging (GPT-4o Gemini 2.5 Pro) scoring correctness, completeness, reasoning, and relevance... multiple runs, answer swaps, no system labels.
Just one question: which system truly understands the story?
That’s how you test long-range narrative intelligence properly.
#Rumi #AI #VideoUnderstanding #LLM #Benchmarking 🚀

1
3
60

30 Dec 2025
🚀Project Number 1 - Giselle 🔥
'Visual AI agent workflow builder for teams'
by @Giselles_AI
#aiagents #ai #automation #opensource #multimodal #videounderstanding #codingagents #businessintelligence #Giselle
2
4
6
471
30 Dec 2025
🎨🚀AI Agents & Workflow Automation : Visual Builders, Research Bots, Multimodal Intelligence🚀🎨
"This video explores innovative AI agent projects that boost automation, reasoning, and real-world workflows across research, coding, planning, and analytics. From Giselle’s visual workflow agents to Dropstone’s self-learning AI IDE and Molmo 2’s multimodal understanding and more! ' 💻✨ 🔥
#aiagents #ai #automation #opensource #multimodal #videounderstanding #codingagents #businessintelligence

1
2
154

8 Dec 2025
Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding 🎬🔍
Paper: bit.ly/48X4PDY
Project: bit.ly/44WLwbo
Instead of passively captioning all frames, AVP agents actively decide what, when, and where to observe—treating videos as interactive environments to explore.
The framework runs iterative plan-observe-reflect cycles with MLLM agents:
→ Planner decides what/where/how to observe
→ Observer extracts timestamped evidence
→ Reflector evaluates sufficiency and guides next steps 🔄
Results across 5 benchmarks 📊:
→ 5.7% accuracy improvement vs. best agentic method
→ 18.4% of inference time
→ 12.4% of input tokens
Authors: Ziyang Wang @ZiyangW00, Honglu Zhou @zhou_honglu, Shijie Wang @ShijieWang20, Junnan Li @LiJunnan0409, Caiming Xiong @CaimingXiong, Silvio Savarese @silviocinguetta, Mohit Bansal @mohitban47, Michael S. Ryoo @ryoo_michael, Juan Carlos Niebles @jcniebles
#FutureOfAI #EnterpriseAI #VideoUnderstanding #AgenticAI



6
17
1,507

🚀 Announcing the 1st HITSZ-TMG VideoVista Video Understanding & Reasoning Competition!
We’ve teamed up with Huawei Cloud to launch this exciting challenge.
🎯 Evaluate and advance multimodal AI in:
✅ Perception & Recognition
✅ Cognitive & Reasoning Skills
✅ Cross-modal Fusion
✅ Cross-cultural & Temporal Understanding
✅ Scientific & Professional Knowledge
📅 Key Dates:
Register by Jan 10, 2026
Submit Benchmark A: Nov 17, 2025 – Jan 17, 2026
Submit Benchmark B: Jan 18 – Jan 31, 2026
👥 Open to individuals, universities, research institutes, and companies worldwide. Teams of 1–5 welcome!
📌 Learn more & register now:
github.com/HITsz-TMG/VideoVi…
#VideoVista #AICompetition #MultimodalAI #HuaweiCloud #HITSZ #VideoUnderstanding #AIResearch
4
243

3 Nov 2025
🎬 ICCV'25 just wrapped and we're rolling into EMNLP'25! Our paper "MovieCORE: Cognitive Reasoning in Movies" was accepted as an Oral presentation 🚀
#EMNLP2025 #NLP #ComputerVision #VideoUnderstanding #VisionLanguageModels #AI #MachineLearning #DeepLearning #VLM #LLM
1
1
7
512

27 Oct 2025
(1/3) Streaming Video Understanding: For continuous dialogue and interpret real-world scenes, the model addresses this demand by enabling fine-grained, real-time understanding of streaming video. See demo that the model accurately identifies objects and interactions, providing immediate insights and explanations to support users. #LLM #VideoUnderstanding
1
1
5
540

18 Oct 2025
📄 Paper: arxiv.org/pdf/2505.08561
💻 Code: github.com/rayush7/rl_videom…
Huge thanks to collaborators and co-authors Kyle Min @tkrishnna @FeiyanH Alan Smeaton @oconnorn @insight_centre
#ComputerVision #VideoModeling #ReinforcementLearning #MaskedModeling #VideoUnderstanding
3/3

1
139

13 Oct 2025
Counting down one week to #ICCV2025! I will be attending in-person to present our two papers (Hawaii local time):
🔹 Tuesday, Oct 21 | 11:45am - 1:45pm | Exhibit Hall I #360 — RANKCLIP: Ranking-Consistent Language-Image Pretraining
🔹 Thursday, Oct 23 | 11:15am - 1:15pm | Exhibit Hall I #2032 — Beyond Training: Dynamic Token Merging for Zero-Shot Video Understanding
Excited to connect and exchange ideas with everyone in Honolulu!
#ComputerVision #AIResearch #MultimodalLearning #VideoUnderstanding
12
2,106

7 Oct 2025
📢VideoRAG: Redefining Long-Context Video Comprehension
In this week’s deep dive, we explore another interesting approach for performing RAG on videos. VideoRAG, a groundbreaking framework that brings RAG to the world of extremely long videos. Unlike traditional LVLMs that struggle with temporal limits, VideoRAG enables LLMs to perform retrieval and reasoning across a collection of videos spanning over 134 hours - without any fine-tuning or context truncation.
By combining Graph-Based Textual Knowledge Grounding and Multi-Modal Context Encoding, VideoRAG builds a scalable, training-free retrieval pipeline that connects text, speech, and visuals into a unified reasoning framework - redefining how long-video comprehension is done.
🔎What’s Covered?
☑️ Understanding the Dual-Channel Architecture of VideoRAG
☑️ Building Cross-Video Knowledge Graphs for Semantic Reasoning
☑️ Performing RAG over 134 Hours of Video Data
☑️ Exploring the LongerVideos Benchmark (Lecture, Documentary, and Entertainment)
☑️ Comparing VideoRAG with NaiveRAG, GraphRAG, and LVLM Baselines
☑️ Key Insights from Ablation Studies and Case Analyses
This blog post covers everything - from VideoRAG’s architecture and retrieval workflow to its empirical results on the 134-hour LongerVideos benchmark, showing how it achieves deep, cross-modal understanding in multi-video contexts.
🔗 Read More: learnopencv.com/videorag-lon…
#VideoRAG #RetrievalAugmentedGeneration #RAG #VideoUnderstanding #MultimodalAI #LLM #AIResearch #GraphRAG #DeepLearning #VisionLanguageModels #LongContextAI #VLMs
1
1
5
310