
A passionate Software Developer and an open-source enthusiast.
- Tweets 408
- Following 182
- Followers 38
- Likes 1,992

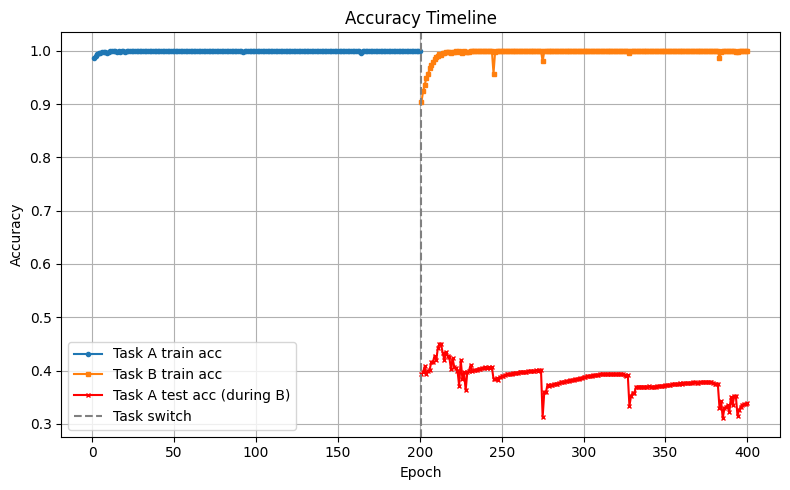


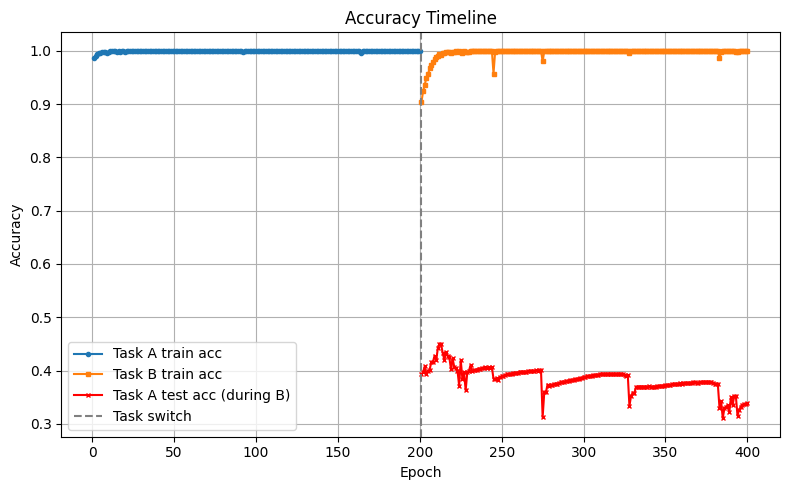


ALT Drop in accuracy on MNIST digits dataset after re-training the convolutional neutral network model on Fashion MNIST dataset
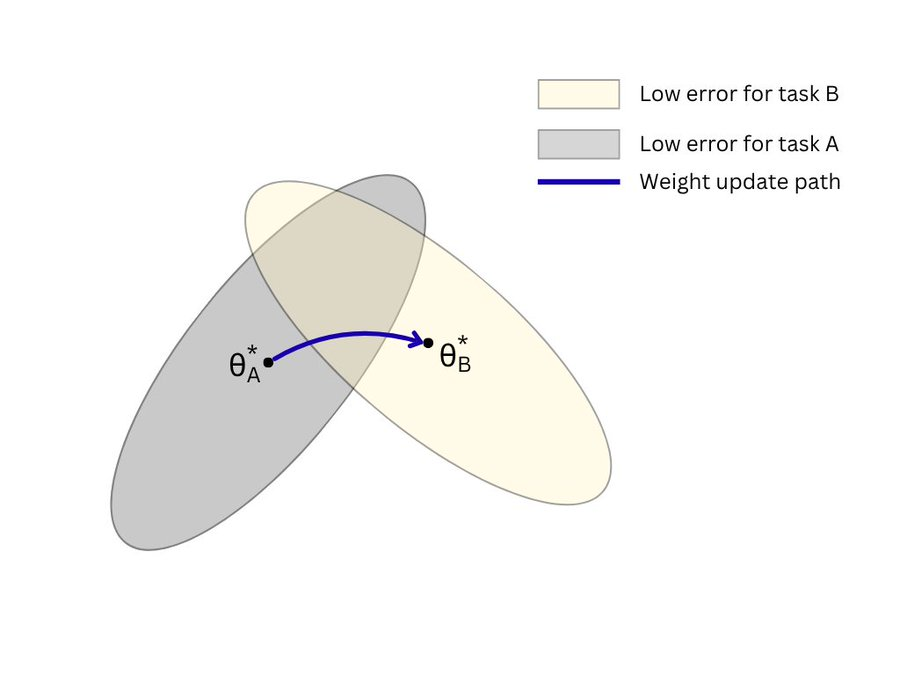
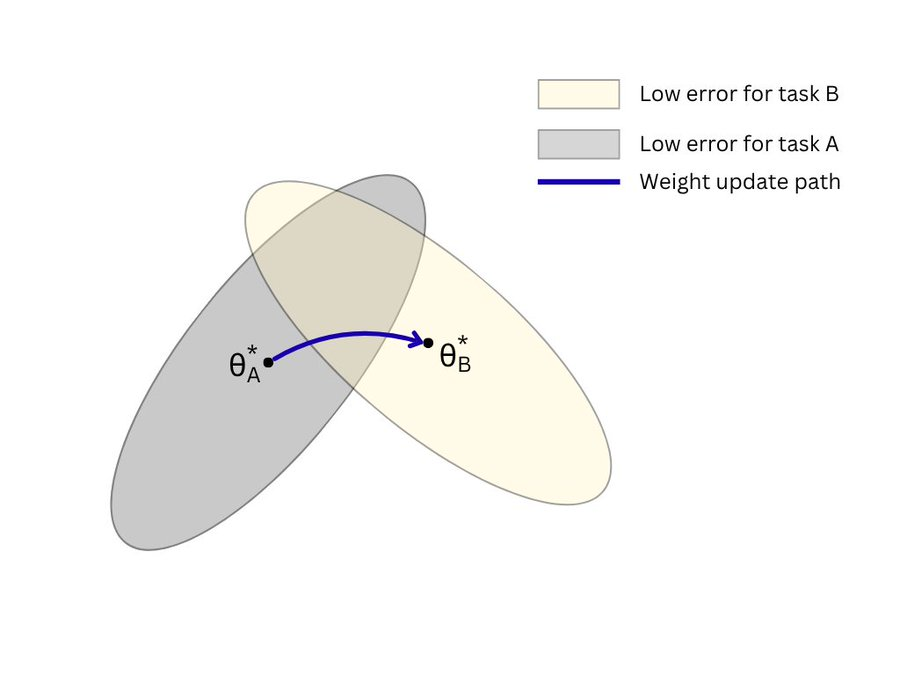
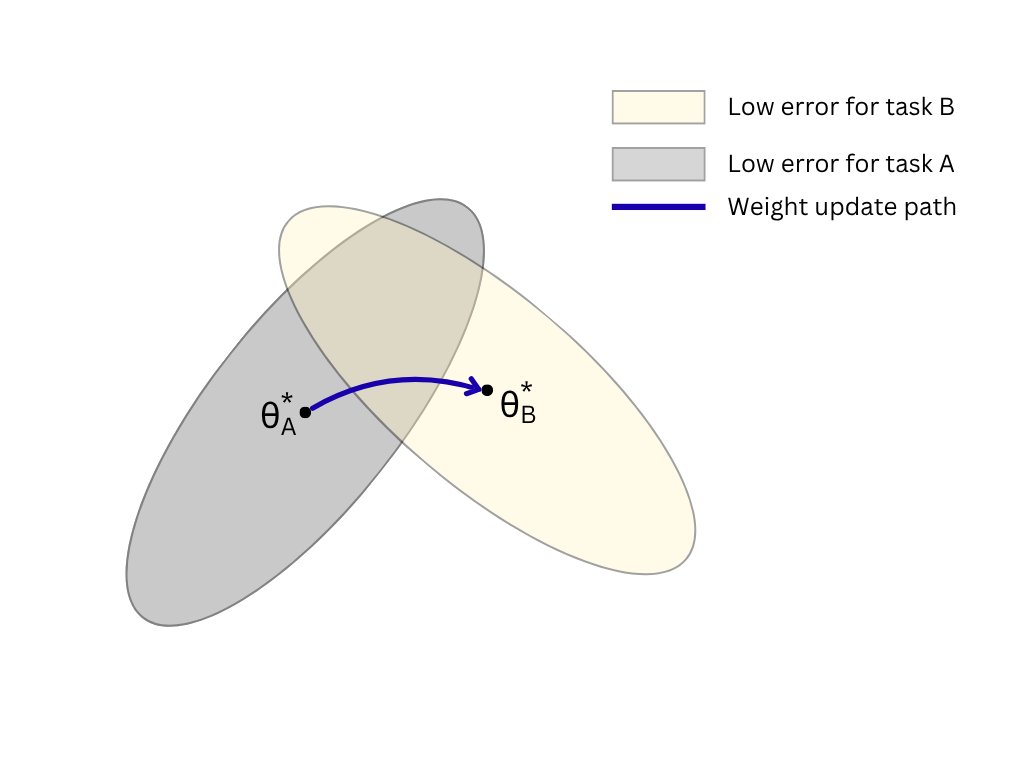
ALT Diagram showing weight space for minimising loss on MNIST digits (task A) and Fashion MNIST dataset (task B) and the usual training trajectory on task B with no awareness of task A
ALT Drop in accuracy on MNIST digits dataset after re-training the convolutional neutral network model on Fashion MNIST dataset
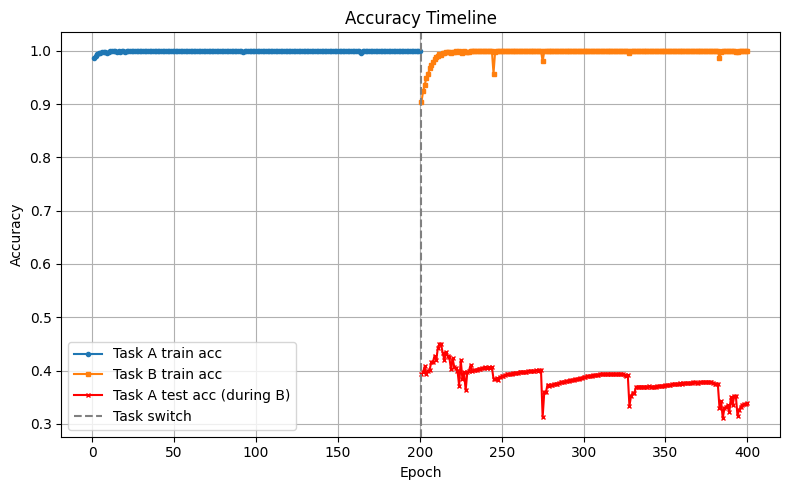
ALT Drop in accuracy on MNIST digits dataset after re-training the convolutional neutral network model on Fashion MNIST dataset
ALT Drop in accuracy on MNIST digits dataset after re-training the convolutional neutral network model on Fashion MNIST dataset