
Jun 11
Continuing in our endeavour to regenerate the results of the self-distillation enables continual learning paper with @KickItLikeShika, we now reach a decent level of 64% on the second science task in the original paper.
To help everyone so that they don't go through our pain, the check point is open sourced and here: huggingface.co/KickItLikeShi…🫡
#AI #SelfDistillation #ContinualLearning

6
16
129
8,214

Jun 11
The @GoogleColab notebook is open — you can watch the forgetting happen in real time: colab.research.google.com/gi…
Full article: saptarshisarkar.hashnode.dev…
#MachineLearning #ContinualLearning #AI
1
10
Jun 11
The @GoogleColab notebook is open — you can watch the forgetting happen in real time: colab.research.google.com/gi…
Full article: saptarshisarkar.hashnode.dev…
#MachineLearning #ContinualLearning #AI
1
5
Jun 11
The Colab notebook is open — you can watch the forgetting happen in real time: colab.research.google.com/gi…
Full article: saptarshisarkar.hashnode.dev…
#MachineLearning #ContinualLearning #AI
1
9

Jun 11
RELAI Raises $6.9M in Total Funding
#AIAgents #AgenticAI #ArtificialIntelligence #ContinualLearning #LearningPlatform #VerifiableAI #AIInfrastructure #EnterpriseAI #MLOps #PreSeed #RELAI
thesaasnews.com/news/relai-r…
14
Jun 10
The Colab notebook is open — you can watch the forgetting happen in real time:
colab.research.google.com/gi…
Full article: saptarshisarkar.hashnode.dev…
#MachineLearning #ContinualLearning #AI
1
1
11

Jun 8
Most teams are treating AI agent telemetry as they would traditional logs and traces.
Your AI Agent Telemetry is More Valuable Than You Think!
For instance, A Langsmith trace from a @LangChain agent is not just a debugging artifact. When you bind it to the final user outcome, accepted, edited, regenerated, or abandoned, it becomes an execution trajectory.
These execution trajectories are the raw material for CL/CD: Continuous Learning / Continuous Deployment.
🔗 blog.investperpetual.com/you…
📉 Agent Telemetry is not a depreciating asset
Agent traces capture how the task was solved: the user objective, retrieved context, reasoning path, tool calls, intermediate decisions, output, and final human feedback.
🧪 The reward signal is already inside the product
Every accept, edit, regenerate, correction, abandonment, or manual override is preference data. Teams are already generating RLHF-style signals through normal product usage.
🔁 CL/CD replaces frozen agent behavior
Traditional software ships static code through CI/CD. Agentic systems need CL/CD to continuously learn from production trajectories and ship improved behaviors without waiting for massive retraining cycles.
👨🏫 Frontier models become teachers, not crutches
For repeatable workflows, frontier models do not need to be the permanent execution engine. They can generate high-quality trajectories that smaller specialized models and LoRA adapters internalize over time.
🧱 This is where companies like @trajectorylabs and @primeintellect become interesting
These platforms turn agent traces into learnable execution trajectories and ease open model training and infrastructure. Together, they hint at a future in which teams own the learning loop rather than renting intelligence forever.
🚀 The defensibility layer is the dataset
The moat is not just prompts, tools, or access to frontier APIs. It is proprietary, domain-specific execution trajectories linked to verified human outcomes.
Stop treating agent telemetry as logs.
Start treating it as training infrastructure.
#AIAgents #AgenticAI #LLMOps #ContinualLearning #AIEvals #OpenSourceAI #AIInfrastructure
2
2
97

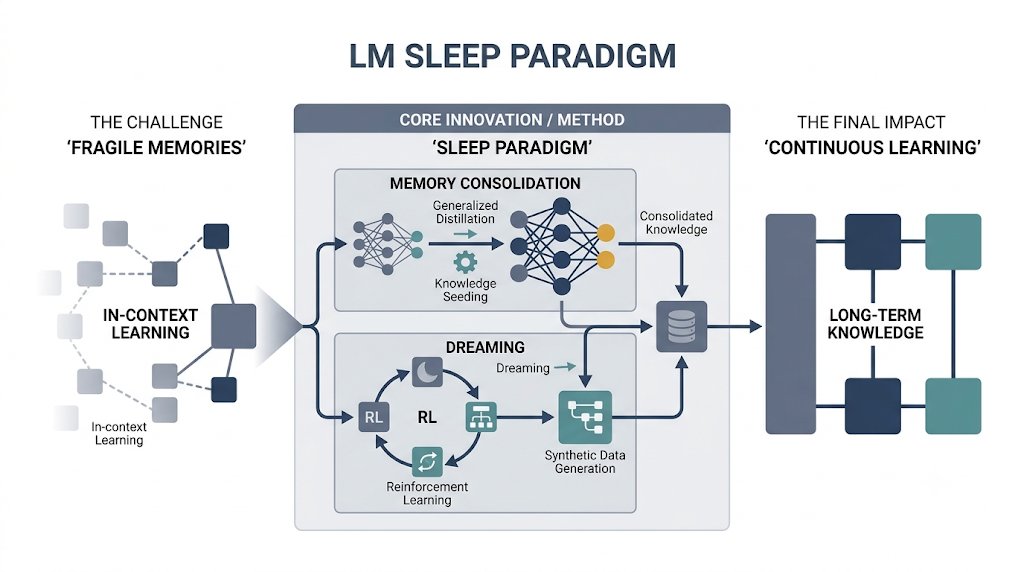
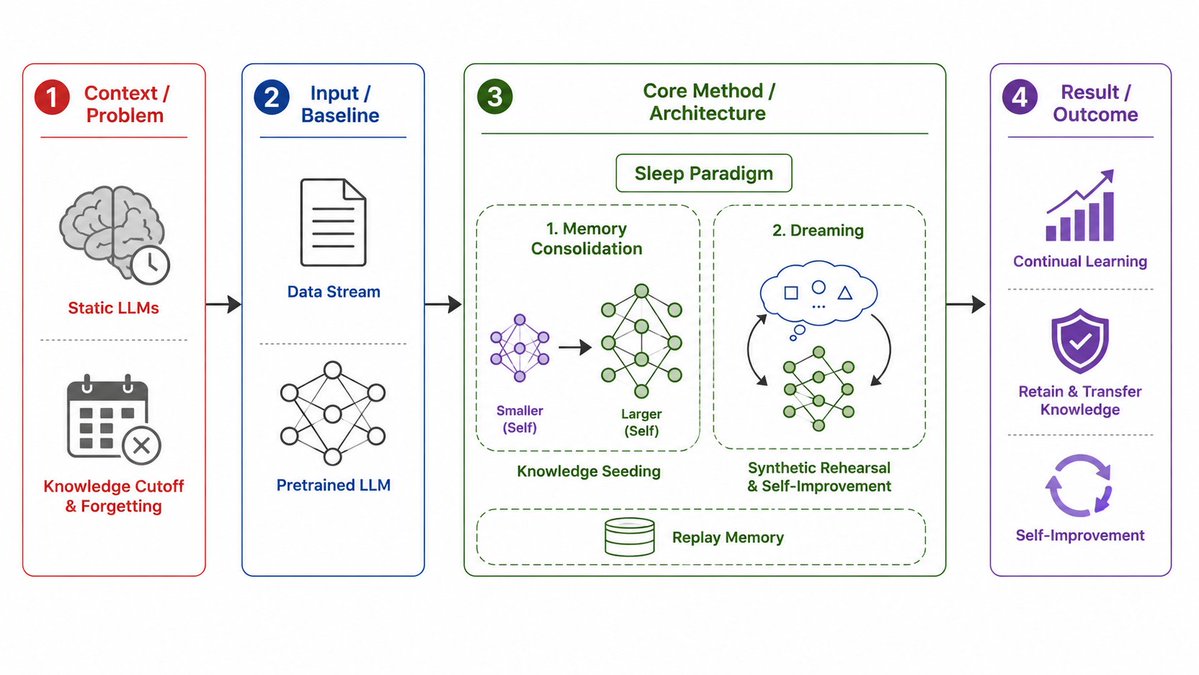
📄 Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
✨ Introduces a “Sleep” paradigm for LLMs, combining memory consolidation with self-generated “dreaming” to support continual learning and reduce forgetting.
🔗 Paper: arxiv.org/abs/2606.03979
🖼️ Infographic comparison:
① Gemini-generated
② ChatGPT-generated
#AIResearch #LLMs #ContinualLearning
3
108

May 31
Memory is not the moat. Behavior change is.
Most "AI memory" products stop at retrieval.
They store conversations, embed them, surface the relevant chunks. The agent remembers what you said. It still makes the same mistake tomorrow.
That is not learning. That is a filing cabinet with semantic search.
At @MidbrainAI , we are building the layer that turns experience into persistent behavior change.
Six steps, one loop:
1. Experience - conversations, actions, sensors, feedback
2. AI Agent - perceives and acts
3. SmartSearch - deterministic recall, NER multi-hop ColBERT reranking
4. Persistent Experience Layer - episodic, semantic, and procedural memory unified
5. Learning Engine - consolidation and online learning that updates the model in real time
6. Behavioral Adaptation - faster, personalized, proactive, trusted
The continual learning loop closes the gap that every current memory product punts on: experience → recall → learn → adapt → improve.
One companion across every embodiment. Phone, laptop, robot, car, smart home, XR, games. Same identity, same understanding, everywhere.
Personal Brain for individuals. Company Brain for institutional knowledge.
All of it client-owned. End-to-end encrypted. Zero knowledge server. Your data, your keys.
We are not building a better filing cabinet. We are building the brain that fills it.
midbrain.ai
#ContinualLearning #AIAgents #Memory #LLM

3
3
129

17 years in tech.
Not a single day where I felt like I had “figured it all out.”
And honestly? That’s the best part.
Yesterday I received the Gold Guru recognition at @TCS for talent development, and it made me pause and reflect, not on the award itself, but on the chain of people who shaped me along the way.
Every architect I know started as someone who didn’t know what an API was.
Every mentor was once the one asking the “dumb” questions.
Every leader was once the nervous fresher on day one.
The cycle only works if you keep two things alive:
→ The curiosity to keep learning even when you’re “senior enough” to stop.
→ The willingness to pass it forward, especially when nobody’s watching.
A few things I’ve learned in 17 years that I wish someone told me in Year 1:
𝟏. 𝐘𝐨𝐮𝐫 𝐭𝐞𝐜𝐡 𝐬𝐭𝐚𝐜𝐤 𝐰𝐢𝐥𝐥 𝐜𝐡𝐚𝐧𝐠𝐞. 𝐘𝐨𝐮𝐫 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐡𝐚𝐛𝐢𝐭 𝐬𝐡𝐨𝐮𝐥𝐝𝐧’𝐭.
I went from building Java web and CMS platforms to architecting AI solutions. The only constant was staying uncomfortable.
𝟐. 𝐓𝐞𝐚𝐜𝐡𝐢𝐧𝐠 𝐢𝐬𝐧’𝐭 𝐚 𝐝𝐞𝐭𝐨𝐮𝐫. 𝐈𝐭’𝐬 𝐚 𝐦𝐮𝐥𝐭𝐢𝐩𝐥𝐢𝐞𝐫.
The moment you explain something to someone else, you understand it three levels deeper yourself.
𝟑. 𝐁𝐮𝐢𝐥𝐝 𝐢𝐧 𝐩𝐮𝐛𝐥𝐢𝐜. 𝐒𝐡𝐚𝐫𝐞 𝐰𝐡𝐚𝐭 𝐲𝐨𝐮 𝐥𝐞𝐚𝐫𝐧.
Open source your projects, write about your failures, and let the community hold you accountable. It compounds.
𝟒. 𝐓𝐡𝐞 𝐣𝐨𝐮𝐫𝐧𝐞𝐲 𝐢𝐬 𝐭𝐡𝐞 𝐝𝐞𝐬𝐭𝐢𝐧𝐚𝐭𝐢𝐨𝐧.
Titles change. Projects end. But the people you lifted along the way, that’s the real résumé.
To every early-career professional reading this:
You don’t need to have all the answers. You just need to keep showing up, keep asking, and keep building.
The tech industry moves fast. But the ones who last aren’t the fastest, they’re the ones who never stopped being students.
Grateful for the incredible culture at TCS that celebrates learning and mentorship at this scale. And even more grateful for every person who once took a chance on guiding me.
Here’s to staying curious. 🙌
#ContinualLearning #TalentDevelopment #Mentorship #TCS #OpenSource #TechLeadership #BuildInPublic #ArchitectLife

6
9
891

May 20
How do we make LLMs learn continuously from interactions with users without drowning in noise?
Introducing UNO (User log-driveN Optimization), a new framework to continually improve LLM systems using user logs! 🚀
📝 Paper: arxiv.org/abs/2602.06470
💻 Code: github.com/bebr2/UNO
🔍 The Problem: Model scaling has limits. Real-world user logs offer a goldmine of human feedback, but they are unstructured and noisy. Vanilla LLMs struggle with the "Signal-or-Noise Dilemma" and off-policy optimization risks when trying to learn from them.
💡 The Solution: UNO is a unified framework that learns from logs without modifying the base model's weights: 1️⃣ Distills messy logs into semi-structured rules & preference pairs. 2️⃣ Clusters them to manage data heterogeneity. 3️⃣ Quantifies the "cognitive gap" between the model's prior knowledge and the log data to adaptively filter out noise. 4️⃣ Constructs specific modules (adapters) for "primary" (direct generation) and "reflective" (critique/refinement) experiences.
🏆 The Results: SOTA performance on #MemoryBench and #WildFB.
👏 Work together with Changyue Wang, Weihang Su, and Yiqun Liu
#LLMs #MachineLearning #AI #ContinualLearning #NLP #Research


3
237

May 13
📙Learning, Fast and Slow: LLM Fine-Tuning and Plastic Continual Learning with GEPA.
New paper explores how combining slow parameter updates with fast evolving prompts (via GEPA) enables more efficient fine-tuning and true plastic continual learning by @LakshyAAAgrawal @matei_zaharia and amazing team of researchers.
📃 Read Paper: arxiv.org/abs/2605.12484
⚡️Published a practical breakdown earlier. Read here:
super-agentic.ai/resources/s…
#LLM #FineTuning #GEPA #ContinualLearning

1
3
7
681

🤔 I went to ICLR with a question I had for months: if I were designing a continual learning system today, would I put new knowledge in the weights or in the context? Almost everyone I asked answered "context."
That's a dismissive answer! I have spent years working on in-weight methods, and I do not think gradient-based consolidation is dead, just badly matched to what practitioners in industry actually want from continual learning, which is high-fidelity recall of past interactions.
Fortunately, a position paper from a 24-author Dagstuhl group landed in my feed and argued, more carefully than I had been managing on my own, that the right answer is neither.
In-context learning is for fast adaptation and lossless recall. In-weight learning is for slow consolidation of skill. The real research problem is the modular memory between them, deciding what gets promoted from context into the weights.
Hopefully the community will now ask less about "ICL or IWL" and more about "what is the right promotion policy, and on what evidence."
📄 Modular Memory is the Key to Continual Learning Agents
#ContinualLearning #ICLR2026 #MachineLearning #FoundationModels

6
11
162
17,562

𝗣𝗮𝗽𝗲𝗿 𝗔𝗰𝗰𝗲𝗽𝘁𝗮𝗻𝗰𝗲 𝗔𝗻𝗻𝗼𝘂𝗻𝗰𝗲𝗺𝗲𝗻𝘁 🎉
Paper titled "Transitioning Heads Conundrum: The Hidden Bottleneck in Long-Tailed Class-Incremental Learning" has been accepted at TMLR 2026 (Transactions on Machine Learning Research).
Authors: Rahul Vigneswaran, Hari Chandana Kuchibhotla, Vineeth N Balasubramanian
👏 Congratulations to all the authors!
🔍 Key Highlight:
This work introduces DEREK (DEcoupling Representations for Early Knowledge Distillation), a method addressing a previously overlooked challenge in Long-Tailed Class-Incremental Learning (LTCIL): the Transitioning Heads Conundrum.
In LTCIL, head classes that are well-represented in earlier tasks become tail classes in subsequent tasks due to memory constraints, leading to accelerated catastrophic forgetting. DEREK mitigates this by decoupling head and tail learning via specialized expert networks and applying Early Knowledge Distillation before data constraints take effect, preserving rich representations.
Across 2 LTCIL benchmarks, 12 experimental settings, and 24 baselines, DEREK consistently establishes new state-of-the-art performance.
#MachineLearning #ContinualLearning #LongTailedLearning #KnowledgeDistillation #TMLR2026 #IITHyderabad
1
2
5
487

May 6
The shift from "external scaffolding" to "internalized intelligence" is becoming the next frontier for AI agents.
This informative deep dive from @MaikaThoughts and @BornsteinMatt explores why in-context learning (while powerful) might hit a ceiling. True discovery and knowledge require models that can compress experience directly into their parameters.
Moving beyond the "sticky notes" phase of LLMs toward systems that actually learn from deployment is a critical architectural evolution.
Read more: a16z.com/why-we-need-continu…
#AI #MachineLearning #ContinualLearning #LLMs #SoftwareArchitecture #AgenticWorkflows
3
53

📢 Call for papers: Continual RL Workshop @ RLC 2026, Montreal
🗓️ Submission deadline: May 22, 2026 (AoE)
🔗 Website & CFP: sites.google.com/view/contin…
#ReinforcementLearning #ContinualLearning #MachineLearning #RLC2026 #ContinualRL

ALT Call for Papers
8
38
4,022
May 2
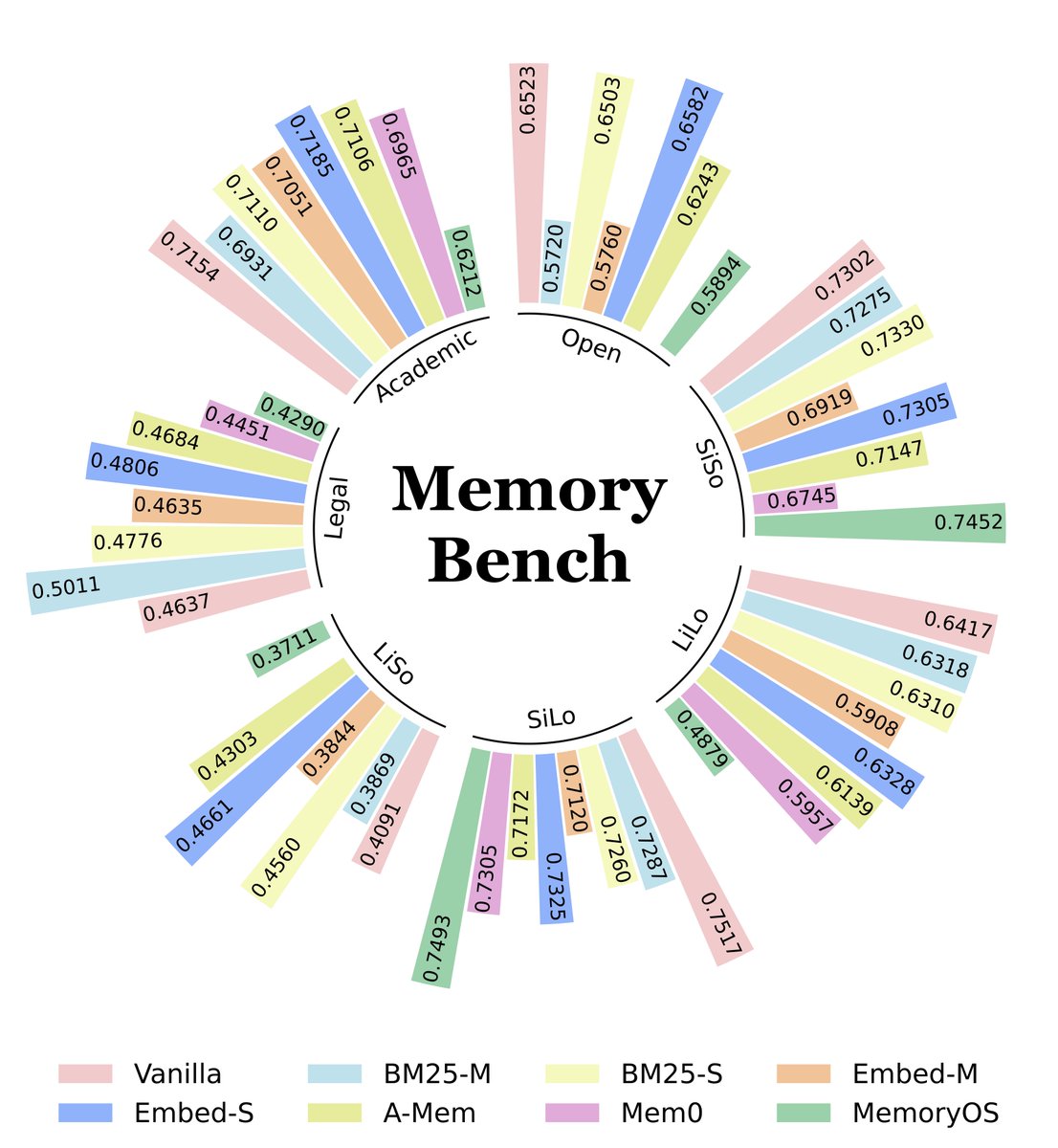
🎉 Excited to share that our paper "MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems" has been accepted as a ✨SPOTLIGHT✨ (top 2.2%) paper at #ICML2026!
MemoryBench is the first benchmark to test whether LLMsys is capable of continuely improving itself with user feedback in service time. It covers multiple domains, languages, and types of tasks to evaluate the #ContinualLearning abilities of LLMsys, with a particularly focus on, not just #DeclarativeMemory (e.g., facts in long context), but also #ProceduralMemory (e.g., experience learned from task practice).
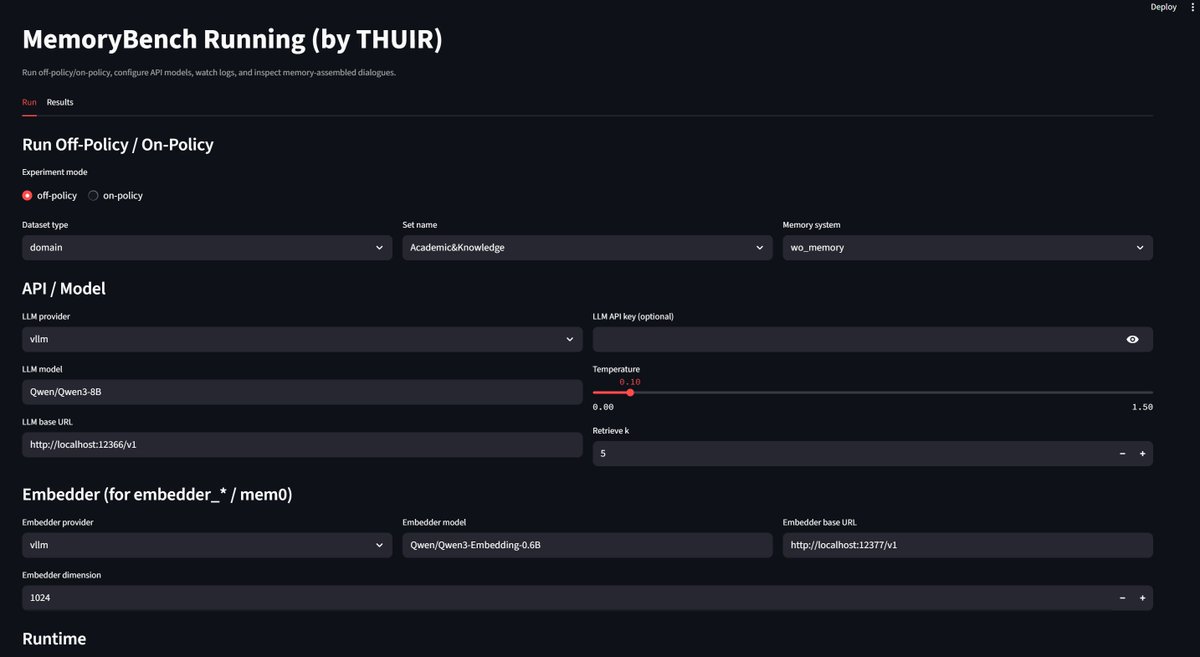
All the code and data are open-sourced. You can easily try or implement your own methods on MemoryBench. Also, we built a frontend interface so that you can run experiments easily even without a GPU! Feel free to try!
📄 arXiv: arxiv.org/abs/2510.17281
💻 Code: github.com/LittleDinoC/Memor…
📊 Dataset (Small): huggingface.co/datasets/THUI…
🗄️ Dataset (Full): huggingface.co/datasets/THUI…

1
21
127
7,890

Apr 29
yes agree, i always have trouble with my stop loss placement. fighting the urge to move too quickly as well. strangling my trade as you would say. #continuallearning
1
2
237

Apr 27
In the era of continued pretraining and continued fine-tuning, loss of plasticity means leaving future gains on the table. We need a better theoretical understanding of loss of plasticity. See a great thread unpacking the dynamics. 👇
#ICLR2026 #ContinualLearning #DeepLearning
Apr 25

Neural nets don’t just forget. Sometimes, after long training, they lose the ability to learn at all.
In our #ICLR2026 poster, we model Loss of Plasticity as gradient dynamics trapped in invariant manifolds: 🔴 frozen units, 🔵 cloned units.
The video makes the traps visible.
4
12
2,117

Apr 25
Giulia Lanzillotta is presenting this today at #ICLR2026:
📍 Poster Session 6, Pavilion 4, Board #4202
🕒 Sat Apr 25, 3:15–5:45 PM local time
Paper/code/demo in replies.
#ContinualLearning #DeepLearning #LearningTheory
1
8
1,456