
Building Tomorrow's AI, LLM Ideas & Experiments
Joined April 2014
- Tweets 278
- Following 2,154
- Followers 170
- Likes 15,736
9 Photos and videos




Shaikh Abdus Samad retweeted

May 21
On Evals - getting messages on “ok so how do I actually start learning this?”
there is no better way than by just doing so you can copy this to Claude Code and get started today
<instructions>
1. Go look up the @harborframework and the Terminal Bench 2.0 dataset. Go look up the Harbor Skills GitHub repo for help. Pick 1 Task in the dataset and explain every single piece that’s in that task folder
2. Explain what my agent sees when it does the task, what it has to output, and how we know if it got the problem right?
3. Now let’s actually run a Task using the built in Claude Code integration, it’s just a flag
4. Once that’s done let’s read the ATIF file that was produced together and help me understand what just happened. Did we pass the task? If not can we dig into why it failed? Go check the verifier logic to see what went wrong.
5. Ok let’s try to improve our agent by adjusting the prompt. And let’s rerun on a few tasks? Is this helping?
6. Ok we’re doing evals! Using this same format, help me make my own. Let’s do this together
…
</instructions>
Spend a few days reading a bunch of traces, actually running evals, understanding traces, internalizing agent failure modes, and being super in the loop of what the agent sees and does
Have fun! Evals are super important, they don’t have to be scary. DM if I can help or just tweet out what you’re doing, someone will help I promise, we’re all learning
23
29
334
21,170

May 19
Was he the candidate or the interviewer?
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
28
Shaikh Abdus Samad retweeted

28 Oct 2025
Please pay me 100m to convert papers like openreview.net/pdf?id=3zKtaq… to blogposts! @agarwl_
27 Oct 2025

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
thinkingmachines.ai/blog/on-…
19
16
575
121,076
17 Oct 2025
Kicking off a focused deep dive into LLM inferencing - exploring optimization, quantization, and deployment pipelines.
If you’ve read any great papers/blogs/videos or tried interesting frameworks lately, drop them here 👇
#LLM #AI #ML #DeepLearning #MLOps #Inference #GenAI #AIResearch #AIInfra #ModelServing
2
206
11 Oct 2025
Weekend vibes....
Diving into the Multilingual & Multimodal LLMs chapter, by @Tanmoy_Chak.
Honestly, this book is so underrated - packed with clear explanations and solid insights.
3
213
8 Oct 2025
Why squared error fails for classification and its lessons for ML design
Revisiting my ML notes, I found a key insight: squared error loss from linear regression doesn't work for classification. It creates a non-convex loss function with local minima, trapping gradient descent and preventing optimal solutions.
The solution is logistic loss, which is convex and ensures convergence to a global minimum. My notes detail its derivation, highlighting the mathematical elegance behind our tools.
The broader lesson: every ML, DL, or LLM problem—multi-class classification, ranking, sequence generation, or reinforcement learning—requires a carefully designed loss function. The right loss shapes learning, optimization, and performance.
- Squared error: Linear regression
- Logistic loss: Binary classification
- Cross-entropy: Multi-class problems
- Contrastive loss: Embedding learning
Each domain needs a tailored approach. Success hinges on understanding the mathematics enabling learning, not just choosing a model architecture.
#AI #ML #LLMs #MLSystemDesign
1
3
130
8 Oct 2025
Are you ready to build on top of a closed platform?
6 Oct 2025

introducing agentkit: build a high-quality agent for any vertical with our visual builder, evals, guardrails, and other tools. live demo of building a working agent in 8 minutes.



1
69
6 Oct 2025
Is your AI image generator producing blurry results? Or are your captioning models calling beautiful photos "just okay"?
The problem might be your training data!
Garbage in = Garbage out.
But when your dataset has millions (or even billions) of images, how do you filter out the bad ones? How do you make sure your model learns from clean, high-quality visuals?
That’s where the LAION Aesthetic Predictor comes in (github.com/LAION-AI/aestheti…). This open-source tool gives each image a score from 1 to 10 based on how visually appealing it is - just like a human might rate it.
It’s super useful if you're:
1) Training text-to-image models
2) Fine-tuning captioning models
3) Curating datasets where looks matter
Have you used aesthetic scoring in your projects? Share your experiences in the comments below!
#AI #MachineLearning #ComputerVision #GenerativeAI #ImageCaptioning
2
75
Shaikh Abdus Samad retweeted

22 Sep 2025
That's quite the tech stack! But real ML engineering is about solving problems, not collecting tools.
2
3
60
5,227
3 Aug 2025
This open-source tool gives each image a score from 1 to 10 based on how visually appealing it is, just like a human might rate it.
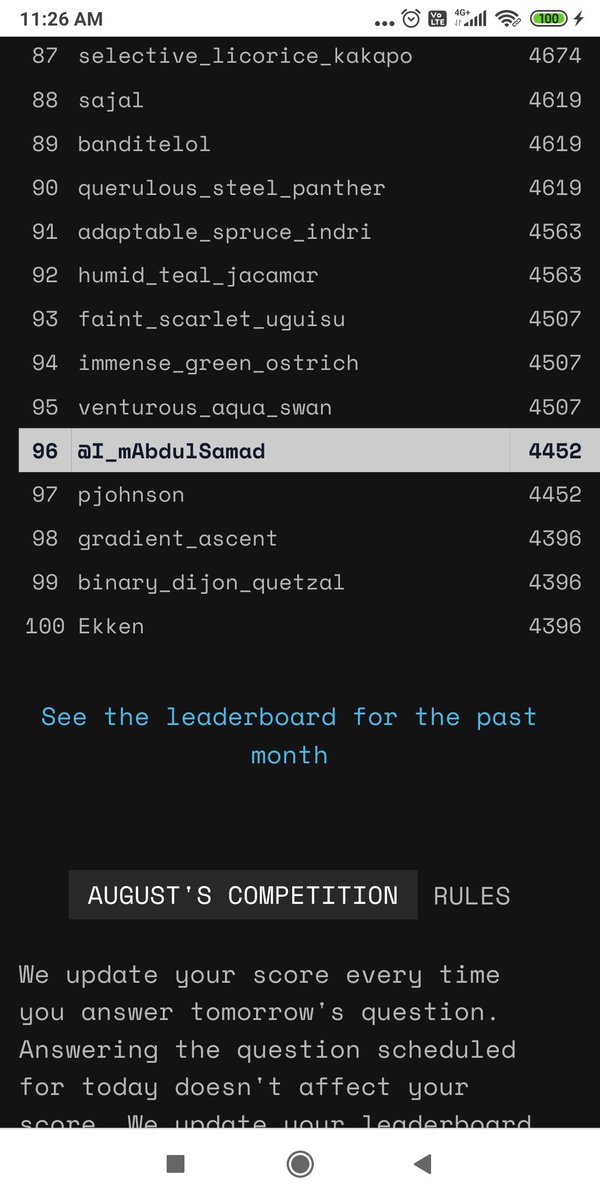
It’s super useful if you're:
1) Training text-to-image models
2) Fine-tuning captioning models
3) Curating datasets where looks matter
1
58
3 Aug 2025
Have you tried aesthetic scoring in your projects? Share below!
github.com/LAION-AI/aestheti…
50
5 Sep 2024
Man, Ilya Sutskever is a total legend...! An ex OpenAI employee...
Dude raised a billion dollars with no product in hand —like, how crazy is that?
This guy’s new company is gonna explode.... Hitting a $5B valuation in just 3 months. Absolute 🔥.
4
259
Shaikh Abdus Samad retweeted

15 Aug 2024
Could AI help inspire entirely new forms of creativity? 🎨
Join our podcast host Professor @FryRSquared and our Senior Research Director, @douglas_eck as they explore the intersection between art, technology and society, our latest generative models such as Veo, and much more.
Watch their conversation ↓
14
52
310
159,167