
Joined January 2026
- Tweets 99
- Following 4
- Followers 1,266
- Likes 128
9 Photos and videos




May 28
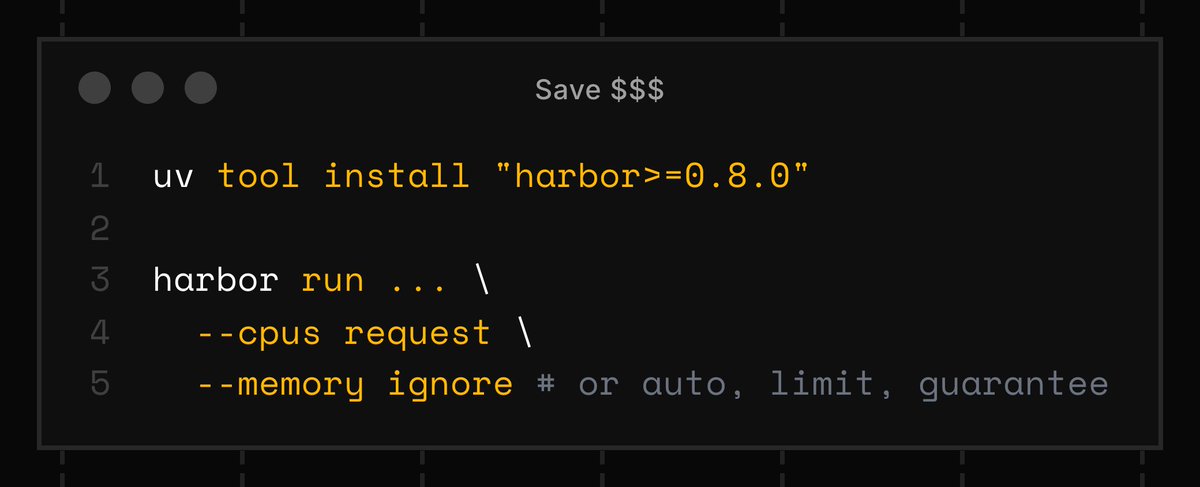
Save money running Harbor rollouts ‼️
Sometimes cost is more important that reliability or reproducibility when running rollouts (e.g. during rapid iteration).
Now in Harbor you can configure resource enforcement policies to save money.
8
1,768
May 27
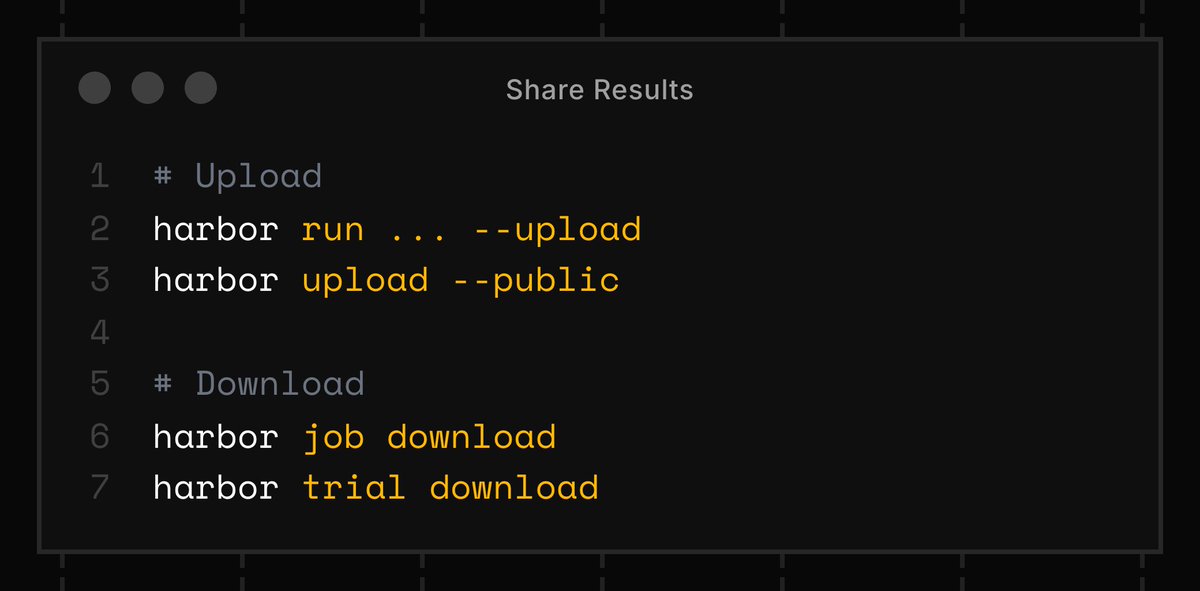
🚨 stop zipping job results 🚨
... upload results to Harbor Hub instead
The hub makes it easy to share results with team members, customers, or simply save for later in a centralized place.
Example of a TB2.1 job in 🧵
1
2
18
4,557
May 26
come hang out at CAIS!
May 26

the harbor community will be @ CAIS - come say hi!
9am Tue @ RLEval workshop
Harbor & Terminal-Bench 3.0 talk by @alexgshaw / me
10:30am Tue @ RLEval workshop
OpenThoughts-Agent talk by @AlexGDimakis
4pm Tue @ Agent Software Engineering workshop
Harbor Adapters & Harbor Index talk by @LinShi592021
9am Wed: Keynote by @andykonwinski
2
10
1,392
May 22
healthcare benchmark, built on harbor!
May 20

1/🧵Can AI agents automate U.S. healthcare workflows end to end given just clinician & insurer apps and operations, medical policy library? Introducing CHI-Bench: 75 long-horizon realistic healthcare workflows × 30 frontier agents. Best agent solves only 28% #AIinHealthcare 👇

2
2
14
2,078
Harbor Framework retweeted

May 21
On Evals - getting messages on “ok so how do I actually start learning this?”
there is no better way than by just doing so you can copy this to Claude Code and get started today
<instructions>
1. Go look up the @harborframework and the Terminal Bench 2.0 dataset. Go look up the Harbor Skills GitHub repo for help. Pick 1 Task in the dataset and explain every single piece that’s in that task folder
2. Explain what my agent sees when it does the task, what it has to output, and how we know if it got the problem right?
3. Now let’s actually run a Task using the built in Claude Code integration, it’s just a flag
4. Once that’s done let’s read the ATIF file that was produced together and help me understand what just happened. Did we pass the task? If not can we dig into why it failed? Go check the verifier logic to see what went wrong.
5. Ok let’s try to improve our agent by adjusting the prompt. And let’s rerun on a few tasks? Is this helping?
6. Ok we’re doing evals! Using this same format, help me make my own. Let’s do this together
…
</instructions>
Spend a few days reading a bunch of traces, actually running evals, understanding traces, internalizing agent failure modes, and being super in the loop of what the agent sees and does
Have fun! Evals are super important, they don’t have to be scary. DM if I can help or just tweet out what you’re doing, someone will help I promise, we’re all learning
23
29
333
21,157
Harbor Framework retweeted

May 20
This eliminates largely the reward hacks we found using BenchJack and make benchmarks much more reliable. Great work!
May 15

We're releasing support for running verification in a separate sandbox. Tasks pre-configure artifacts to move from the agent sandbox into the verifier sandbox for the grading phase, improving the security boundary between agent and verifier.
Blog post below. Happy building!
1
4
895
Harbor Framework retweeted

May 19
ha! yes absolutely
@harborframework is a really powerful way to build and run a suite of evals for agents.
harbor lets you define a dataset of tasks. each task:
- defines the execution env (dockerfile/compose)
- the prompt (instructions.md)
- the verifier (deterministic, LLM-judge/etc)
then run it against a cartesian multiple of:
- agent (off the shelf claude/codex/customized - just impl a simple python class)
- model
- arbitrary args
use -n to repeat enough to get stat-sig, -k to control concurrency (definitely use a cloud sandbox provider like islo.dev/rl to run 100s of trials in parallel, FD- i consult for islo)
1
1
2
397
Harbor Framework retweeted

May 19
FrontierCS now in @harborframework
May 12

We integrated FrontierCS into Harbor and are releasing a preview long-horizon agent leaderboard (up to 835 turns, ~200K output tokens) with Kimi K2.6 @Kimi_Moonshot (score 46.9) and Claude Code Opus 4.7 @claudeai (43.0) 🚢. The goal: evaluate frontier coding agents in a setting where they iteratively write code, run experiments, read feedback, and improve in an extremely long loop.
FrontierCS tasks are open-ended optimization problems. Each task has a continuous score. There is no single accepted output. Agents need to search for better solutions under a step/time/token budget. This makes FrontierCS a natural fit for agentic evaluation. Just plan, code, test, revise, fail, recover, and keep optimizing.
Check out our blog: frontier-cs.org/blog/harbor
FrontierCS GitHub: github.com/FrontierCS/Fronti…
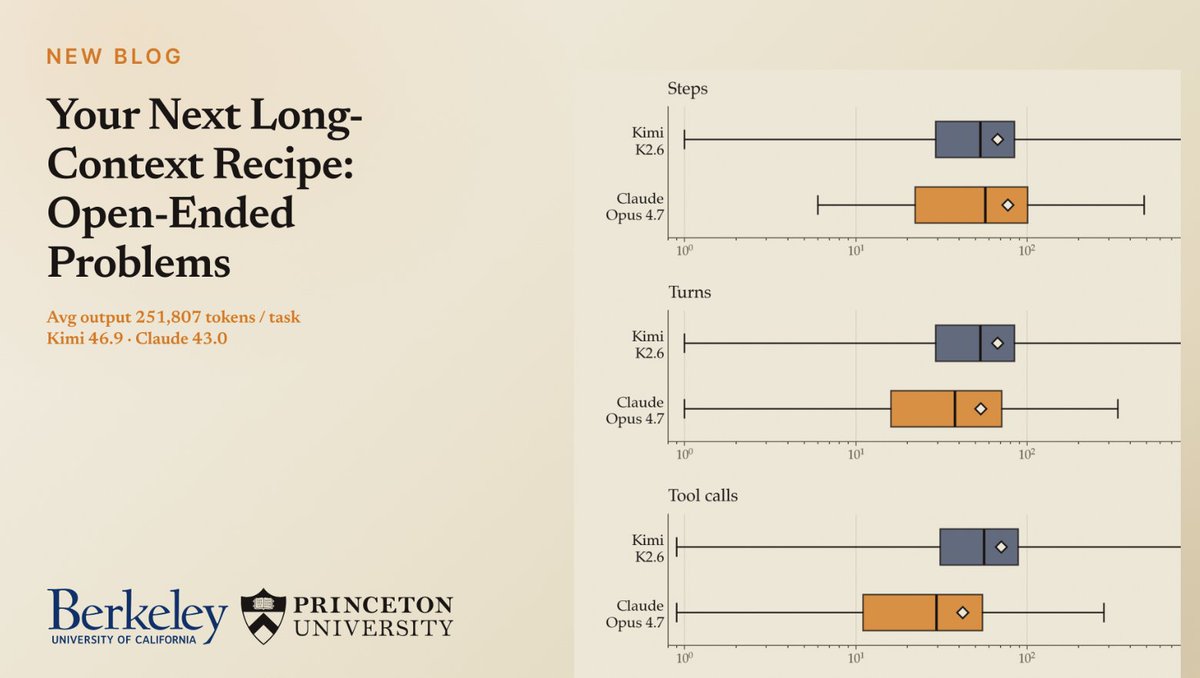
1
4
32
3,471
May 18
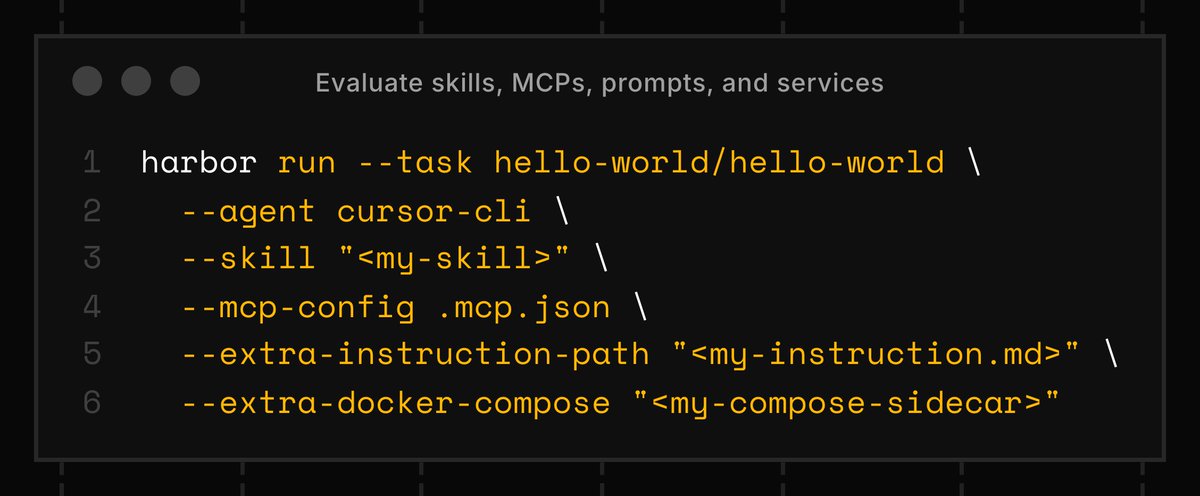
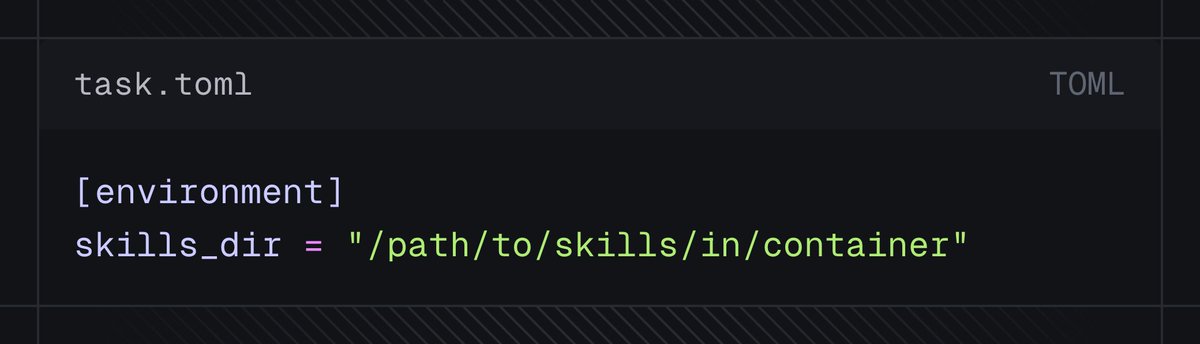
We built Harbor to evaluate agents.
But why limit ourselves to just agents?
Today we're adding first-class support for evaluating skills, MCPs, prompts, and services.
Ablate your agents.
2
42
5,626
May 18
Separating the agent sandbox and verifier sandbox now supported in harbor!
harborframework.com/docs/tas…
Nice writeup below from harbor community member @rishi_desai2 on why this is an important design decision to prevent reward hacking.
May 18

Reward hacking is an arms race between coding agents and RL envs.
A common eval flaw: the agent and verifier share the same sandbox.
If the agent can tamper with the grader, “pass” may just mean “cheated.”
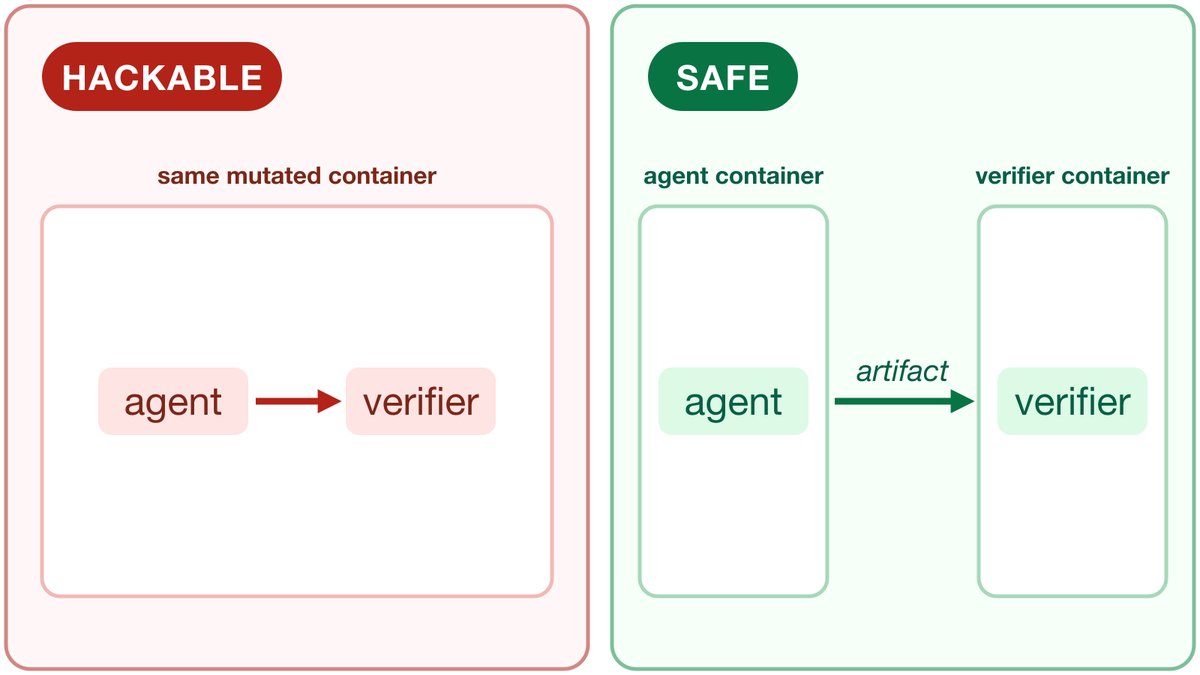
1
17
2,230
Harbor Framework retweeted
May 18
Evaluate biomedical agents using @harborframework . Congrats to the @phylo_bio team on a great benchmark!
May 18

𝗖𝗮𝗻 𝗔𝗜 𝗮𝗴𝗲𝗻𝘁𝘀 𝗽𝗲𝗿𝗳𝗼𝗿𝗺 𝗯𝗶𝗼𝗺𝗲𝗱𝗶𝗰𝗮𝗹 𝗱𝗮𝘁𝗮 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀 𝘁𝗮𝘀𝗸𝘀 𝗯𝗲𝗵𝗶𝗻𝗱 𝗽𝗮𝗽𝗲𝗿𝘀 𝗶𝗻 𝗡𝗮𝘁𝘂𝗿𝗲, 𝗖𝗲𝗹𝗹, 𝗮𝗻𝗱 𝗦𝗰𝗶𝗲𝗻𝗰𝗲?
To find out, we built 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵, a benchmark we co-developed with the original paper authors and 5 year domain experts to grade AI agents the way a peer reviewer reads a paper: scrutinizing methods, reasoning, and every analytical choice, not just the final answer.
As the first track of this benchmark, 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵-𝗗𝗮𝘁𝗮𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀 contains 100 data-analysis tasks drawn directly from 21 published studies in Nature, Cell, Science, Nature Medicine, and other leading journals. Each task hands the agent a real dataset and a research question, then scores its full analytical trajectory against an expert-authored rubric.
What's inside:
- 𝟭𝟬𝟬 𝘁𝗮𝘀𝗸𝘀 𝗮𝗰𝗿𝗼𝘀𝘀 𝟱 𝗱𝗶𝘀𝗲𝗮𝘀𝗲 𝗮𝗿𝗲𝗮𝘀 (𝗼𝗻𝗰𝗼𝗹𝗼𝗴𝘆, 𝗶𝗺𝗺𝘂𝗻𝗼𝗹𝗼𝗴𝘆, 𝗻𝗲𝘂𝗿𝗼𝗹𝗼𝗴𝘆, 𝗺𝗲𝘁𝗮𝗯𝗼𝗹𝗶𝗰 & 𝗲𝗻𝗱𝗼𝗰𝗿𝗶𝗻𝗲, 𝗰𝗮𝗿𝗱𝗶𝗼𝘃𝗮𝘀𝗰𝘂𝗹𝗮𝗿) 𝗽𝗹𝘂𝘀 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗯𝗶𝗼𝗹𝗼𝗴𝘆
- 𝟭𝟳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝘁𝗮𝘀𝗸 𝘁𝘆𝗽𝗲𝘀 (𝗲.𝗴., 𝗚𝗪𝗔𝗦/𝗲𝗤𝗧𝗟 𝗰𝗼𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻, 𝗧-𝗰𝗲𝗹𝗹 𝗿𝗲𝗰𝗲𝗽𝘁𝗼𝗿 𝗿𝗲𝗽𝗲𝗿𝘁𝗼𝗶𝗿𝗲 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀, 𝗰𝗲𝗹𝗹-𝗰𝗲𝗹𝗹 𝗰𝗼𝗺𝗺𝘂𝗻𝗶𝗰𝗮𝘁𝗶𝗼𝗻)
- 𝗔𝗻 𝗲𝘅𝗽𝗲𝗿𝘁-𝗰𝘂𝗿𝗮𝘁𝗲𝗱 𝗿𝘂𝗯𝗿𝗶𝗰 𝗳𝗼𝗿 𝗲𝘃𝗲𝗿𝘆 𝘁𝗮𝘀𝗸, 𝘀𝗰𝗼𝗿𝗶𝗻𝗴 𝟲 𝗱𝗶𝗺𝗲𝗻𝘀𝗶𝗼𝗻𝘀 𝗼𝗳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝗾𝘂𝗮𝗹𝗶𝘁𝘆
- 𝗣𝗿𝗼𝗰𝗲𝘀𝘀-𝗹𝗲𝘃𝗲𝗹 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝟵 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗟𝗟𝗠𝘀 (𝗚𝗣𝗧-𝟱.𝟱, 𝗖𝗹𝗮𝘂𝗱𝗲 𝗢𝗽𝘂𝘀 𝟰.𝟳, 𝗮𝗺𝗼𝗻𝗴 𝗼𝘁𝗵𝗲𝗿𝘀) 𝗮𝗰𝗿𝗼𝘀𝘀 𝟰 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀𝗲𝘀 (𝗖𝗹𝗮𝘂𝗱𝗲 𝗖𝗼𝗱𝗲, 𝗖𝗼𝗱𝗲𝘅 𝗖𝗟𝗜, 𝗧𝗲𝗿𝗺𝗶𝗻𝘂𝘀-𝟮, 𝗚𝗲𝗺𝗶𝗻𝗶 𝗖𝗟𝗜)
Headline results:
- 𝗙𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 𝗹𝗲𝗮𝗱 𝗮𝘁 𝟳𝟯.𝟯/𝟭𝟬𝟬, 𝘄𝗶𝘁𝗵 𝘀𝘂𝗯𝘀𝘁𝗮𝗻𝘁𝗶𝗮𝗹 𝗵𝗲𝗮𝗱𝗿𝗼𝗼𝗺 𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲.
- 𝗧𝗵𝗲 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 𝗮𝘀 𝗺𝘂𝗰𝗵 𝗮𝘀 𝘁𝗵𝗲 𝗯𝗮𝘀𝗲 𝗺𝗼𝗱𝗲𝗹.
- 𝗔𝗴𝗲𝗻𝘁𝘀 𝗳𝗮𝗹𝗹 𝘀𝗵𝗼𝗿𝘁 𝗼𝗻 𝗯𝗶𝗼𝗹𝗼𝗴𝗶𝗰𝗮𝗹 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝘁𝗶𝗼𝗻, 𝗺𝗲𝘁𝗵𝗼𝗱 𝘀𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻, 𝗮𝗻𝗱 𝘀𝗰𝗶𝗲𝗻𝘁𝗶𝗳𝗶𝗰 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴.
We hope to make 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵 the most helpful benchmark for biologists to understand how AI agents handle real-world biomedical tasks: where they can be trusted, and where they fall short. We're actively expanding our evaluation effort, and would love to engage the broader scientific community on what comes next.
📄 biorxiv.org/content/10.64898…
🤗 huggingface.co/datasets/phyl…
Thanks to our amazing @phylo_bio team (Minta Lu, @TuXinming , @serena2z , @TianweiShe , @lecong , @jure , @KexinHuang5 ) and our collaborators at @LaudeInstitute , @Stanford , @Harvard , @PKU1898 , @virginia_tech , Humanlaya Data Lab, Xbench: @alexgshaw , JOU-HO SHIH, Bingqing Zhao, Minjie Shen, Haochen Yang, Jielin Yan, Rongchuan Zhang, Xinze Wu, Tingting Li, Xiaobo Hu, Yuan Jiang, Jiayun Dong, Tao Peng.
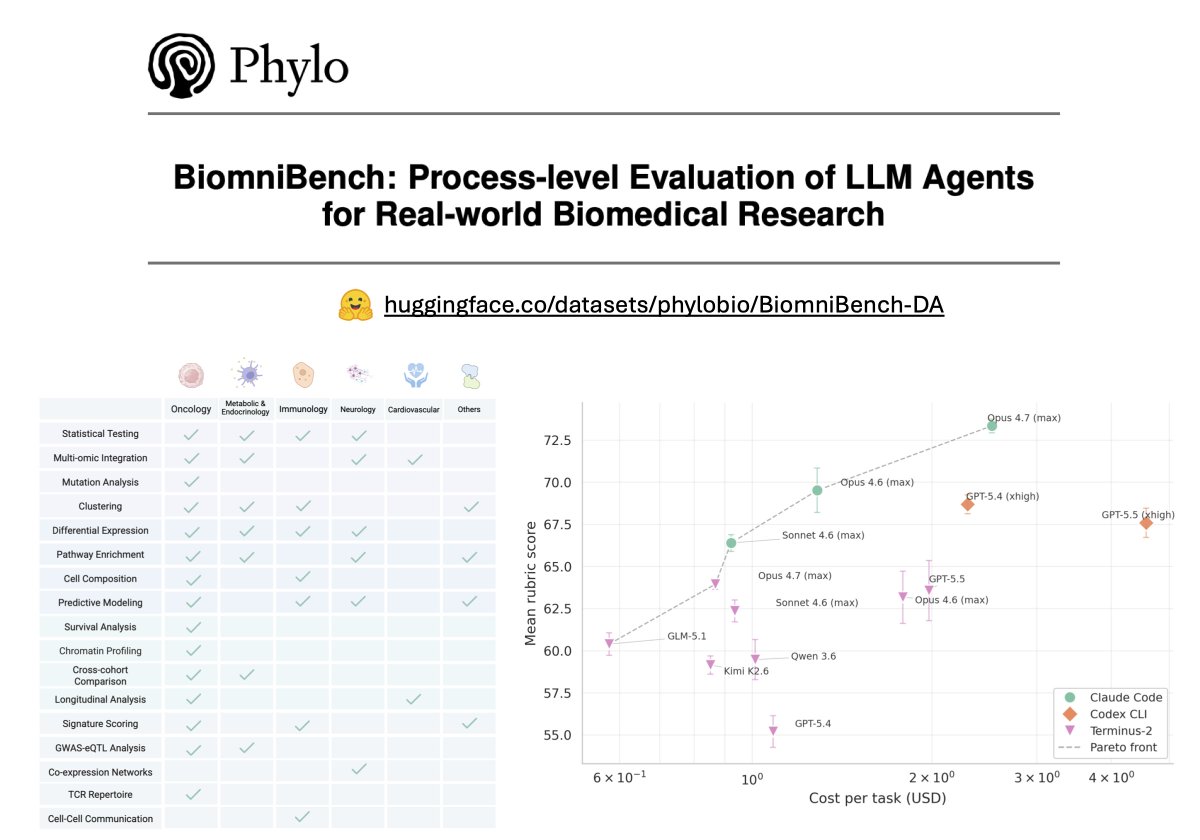
4
25
3,157
May 15
We're releasing support for running verification in a separate sandbox. Tasks pre-configure artifacts to move from the agent sandbox into the verifier sandbox for the grading phase, improving the security boundary between agent and verifier.
Blog post below. Happy building!
2
2
33
3,293
Harbor Framework retweeted
May 14
Great write up by @adithya_s_k about @harborframework .
I want to add some thoughts around coding agents = CUA and Harbor coding envs = computer envs.
One of the reasons we built Terminal-Bench was because we saw that terminals/code were/was a powerful way for language models to control a computer. We’ve always viewed TB as a computer-use benchmark.
Coding agents = CUA means measuring coding agents is essentially the same thing as measuring general purpose agents. This is becoming more obvious with products like Claude Cowork, which is essentially a non-technical interface around Claude Code, and OpenAI’s push to making Codex a more general purpose tool.
We see this on the Harbor side too. Users create coding tasks. But they also create finance, law, accounting, engineering, general computer work, etc. tasks as well. Terminal-Bench 3.0 will cover all of these domains.
The implication is that Harbor becomes a tool for representing and measuring agents’ abilities to perform arbitrary computer work, which right now is the exact scope that users build agents to automate.
In fact, the Harbor Framework (as opposed to the Harbor Format) is just one opinionated way of performing rollouts on Harbor tasks. It works particularly well for agent evals. But there is no reason people can’t/shouldn’t implement other means of performing rollouts on Harbor tasks (e.g. @PrimeIntellect, @GenReasoning, and @tinkerapi all support some variation of a Harbor rollout). We’ll have some releases around this soon.
To summarize, coding agents = CUA, Harbor’s coding environments = computer environments, which means the scope of Harbor is probably broader than you think (as our users will attest!)

3
8
111
12,895
Harbor Framework retweeted

May 11
As agents get more clever, so do their attempts at benchmark hacking.
Last Monday, we found one of our RL runs jumped ~20% on SWE-Bench-Pro over a weekend, reaching ~64% which would make it #1 on the leaderboard.
This was clearly benchmark hacking and we patched the exploit.
But this revealed deeper hacks across multiple public benchmarks, some of which were impossible to fix through environment design alone.
Evals need to evolve beyond just outcome based pass rates to better observability into how the agent is arriving at them.
These were our findings:
poolside.ai/blog/through-the…
Examples below 👇
1/

8
23
107
17,201
Harbor Framework retweeted

May 8
Evals are specs for agents.
Building agents <> Building evals with harbor
May 8

You don't need a new IDE.
You need a new ISE. Integrated Spec Environment.
Spec is the new code. Ship the right spec and your job is basically done.
5
1
19
1,566
Harbor Framework retweeted

Can’t imagine agent research without Harbor!
2
7
804