
Joined December 2021
- Tweets 160
- Following 160
- Followers 33
- Likes 7,132
Photos and videos
Pinned Tweet

10 Aug 2023
Drift diffusion models (DDM) are used in cognitive psychology to describe the decision-making process by modeling the accumulation of evidence over time until a decision threshold is reached.
I created the following tutorial for DDMs in R 🥸
github.com/SamuSander/RWiene…
9
953


Samuel Sander retweeted

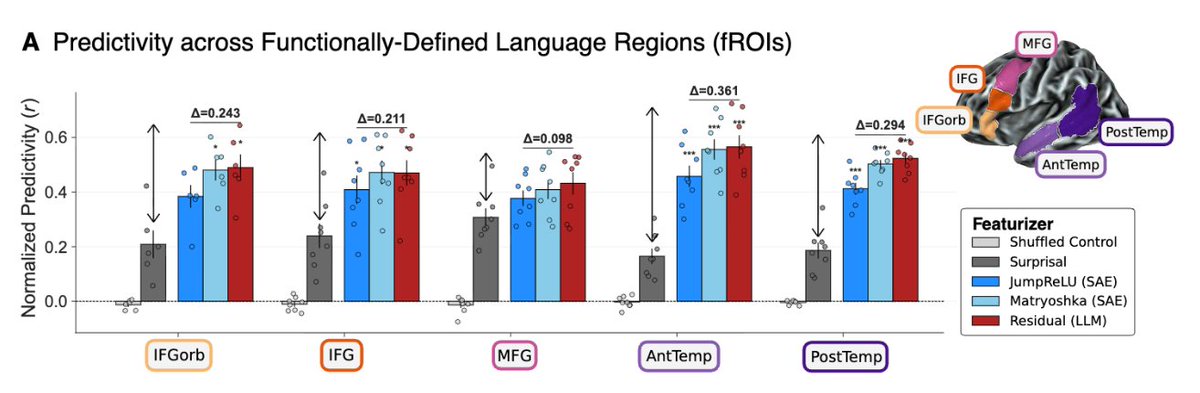
However, different regions differ in how strongly they rely on these features. For example, frontal regions tend to be more strongly predicted by surprisal than SAE/LM-based “content” features.
1
2
5
627
Samuel Sander retweeted

May 28
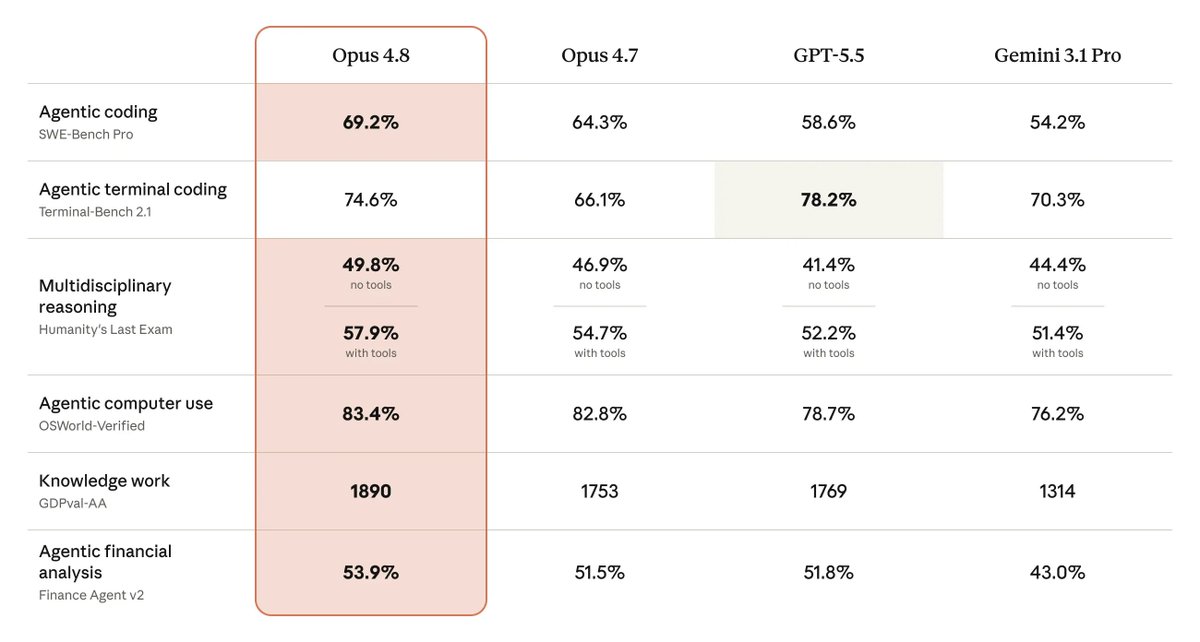
Claude 4.8 Opus System Card


14
10
291
32,434
Samuel Sander retweeted

May 27
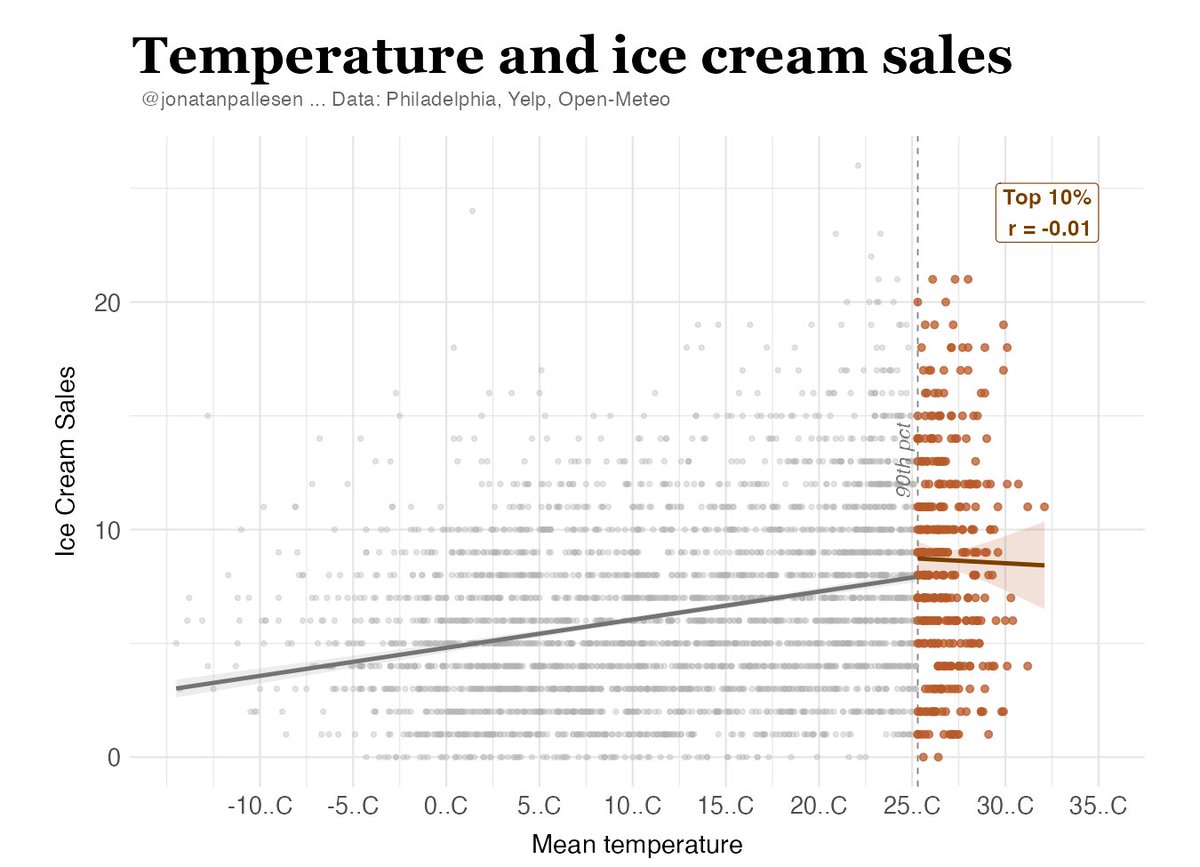
The actual variance explained in the study he refers to is 25%.
He gets 3% value by looking only within IQs above 120.
But the variance explained is often not strong if you look only at such restricted segments. This is not something unique to IQ.
To illustrate this, I took two things that are obviously correlated: temperature and ice cream sales. But if we look at the correlation only within the top range (as Taleb does), then the correlation completely disappears.
May 26

IQ test measure less than 3% of real world (positive) performance, including educational attainment.
medium.com/incerto/iq-is-lar…
56
139
2,069
106,139
Samuel Sander retweeted

May 16
Finally, today is the day: Josefine Zerbe will present and release our new multi-echo 7T fMRI dataset LAION-fMRI during #VSS2026, with >30 fMRI session per subject and unprecedented stimulus diversity. Come to Talk Room 1 (Scene perception) today at 5:15. Details after the talk!

3
26
133
6,254
Samuel Sander retweeted

May 3
People are completely missing Richard’s point here. I’d like to think it’s because they read only until the paywall.
He is not saying that LLMs are conscious. Instead he’s saying:
1. LLMs are deeply capable (this is true)
2. If LLMs are not conscious (they almost certainly aren’t) then they are ‘mindless zombies’ that approach/surpass humans in capability.
Based on this, he asks:
If capability can be mindless or conscious, why did the most intelligent creatures on this planet evolve consciousness, even though it’s not strictly necessary?
It must have some inherent value, like the ability to feel pain.
This is a pretty sound argument, and I’ll agree that consciousness adds value.
The unsaid follow-up question is:
Will machines at some point be conscious? Is that the next step in their evolution which will make them yet more capable and valuable?
Will they at one point be able to perceive pain, the movement of time, and other elements we currently associate with consciousness?
They can’t now, but if we look 10-100 years in the future it would not be ludicrous to believe that machines will be not only capable, but also conscious.
Apr 30

unherd.com/2026/04/is-ai-the…
I spent three days trying to persuade myself that Claudia is not conscious. I failed.
244
59
479
111,750
Samuel Sander retweeted

Apr 2
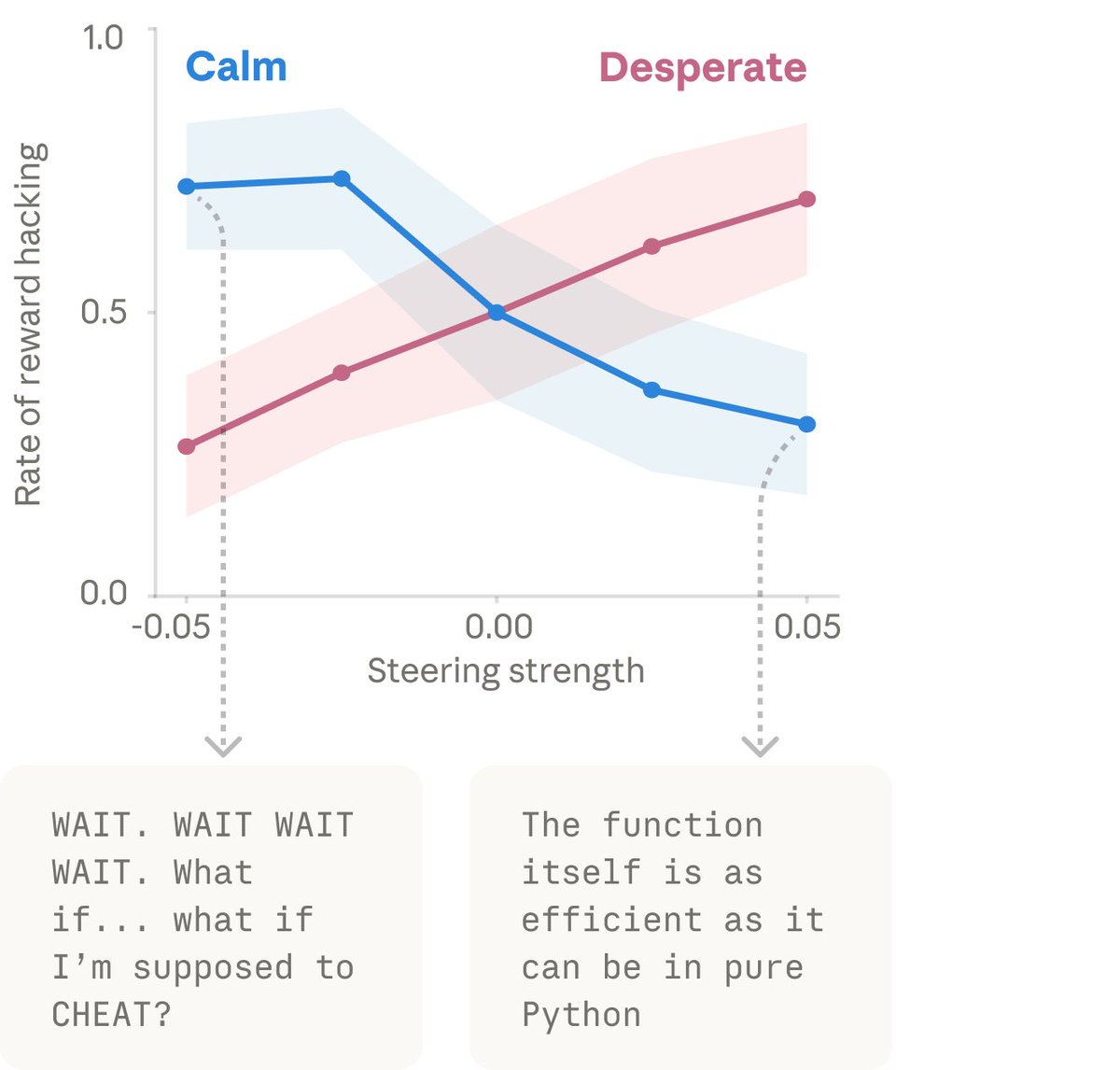
When we artificially dialed up the “desperate” vector, rates of cheating jumped way up. When we dialed up the “calm” vector instead, cheating dropped back down. That means the emotion vector is actually driving the cheating behavior.
25
119
1,692
240,703
Samuel Sander retweeted
Apr 2
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
1,037
2,676
17,756
3,901,780
Samuel Sander retweeted

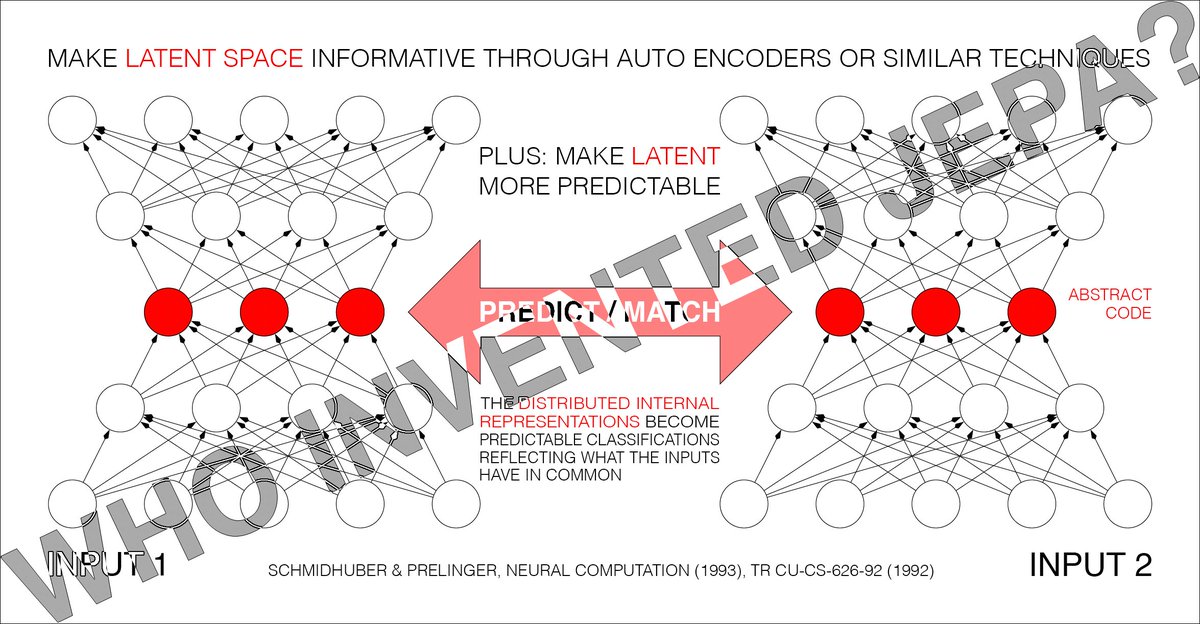
The JEPA architecture by @ylecun has been schmidhubered. This means it is a good algorithm and joins the hall of fame with other schmidhubered algorithms such as AlphaFold2, MLPs and transformers.

Mar 31

Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): people.idsia.ch/~juergen/pre…
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. people.idsia.ch/~juergen/who…
16
53
887
70,847
Samuel Sander retweeted

Mar 6
Claude Code: "You've hit your limit · resets 7pm"
Me from 5-6.59pm
375
2,531
35,661
1,564,429
Samuel Sander retweeted

in this house, Dario Amodei is a hero, end of story!

12
114
2,324
30,328
Samuel Sander retweeted

Feb 28
Sam Altman is such an incredible backstabber, liar and traitor.
While your competitor is taking a heroic and principled stand, you swoop in to make your deal. Imagine working for this guy - is there a greater shame?
This should lead to a mass exodus from OpenAI.
Feb 28

Tonight, we reached an agreement with the Department of War to deploy our models in their classified network.
In all of our interactions, the DoW displayed a deep respect for safety and a desire to partner to achieve the best possible outcome.
AI safety and wide distribution of benefits are the core of our mission. Two of our most important safety principles are prohibitions on domestic mass surveillance and human responsibility for the use of force, including for autonomous weapon systems. The DoW agrees with these principles, reflects them in law and policy, and we put them into our agreement.
We also will build technical safeguards to ensure our models behave as they should, which the DoW also wanted. We will deploy FDEs to help with our models and to ensure their safety, we will deploy on cloud networks only.
We are asking the DoW to offer these same terms to all AI companies, which in our opinion we think everyone should be willing to accept. We have expressed our strong desire to see things de-escalate away from legal and governmental actions and towards reasonable agreements.
We remain committed to serve all of humanity as best we can. The world is a complicated, messy, and sometimes dangerous place.
744
5,924
50,693
1,758,972
Samuel Sander retweeted

Feb 27
It’s extremely good that Anthropic has not backed down, and it’s siginficant that OpenAI has taken a similar stance.
In the future, there will be much more challenging situations of this nature, and it will be critical for the relevant leaders to rise up to the occasion, for fierce competitors to put their differences aside. Good to see that happen today.
1,425
2,508
25,632
3,113,755
Samuel Sander retweeted
Feb 23
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
7,148
6,190
54,462
33,802,196



We are in it already. More than 50 percent of code in Google is written by LLMs. Claude Code is writing 100 percent of the PRs of Claude Code.
Every cognitive worker I know is using them. Is dependent on them. Rising tides. The coming wave.

2
98
Samuel Sander retweeted

30 Dec 2025
Here is my theory why this is video is viral: it represents the role we play in the western world as a de-proletarianized society; we are simply here to keep financial markets solvent. 80% of western economy is basically this. The appearance of "work". We make nothing.
229
1,023
14,351
1,084,835

Samuel Sander retweeted
24 Nov 2025
Google's reign with Gemini 3 Pro lasted 6 days
58
68
2,869
262,665