
Statistical geneticist | Associate Prof at @DanaFarber / @harvardmed / @DFCIPopSci | Blogging at theinfinitesimal.substack.co…
Joined January 2023
- Tweets 22,034
- Following 2,905
- Followers 21,562
- Likes 22,660
3,614 Photos and videos










Pinned Tweet

21 Feb 2024
I've written about race, genetic ancestry, analyses of large biobanks, and human history
gusevlab.org/projects/hsq/#h…
I'll summarize the key points here 🧵:

50
308
1,325
578,791
Sasha Gusev retweeted

Jun 13
AmErIcAn DyNaMiSm
Jun 13


7
17
709
27,844
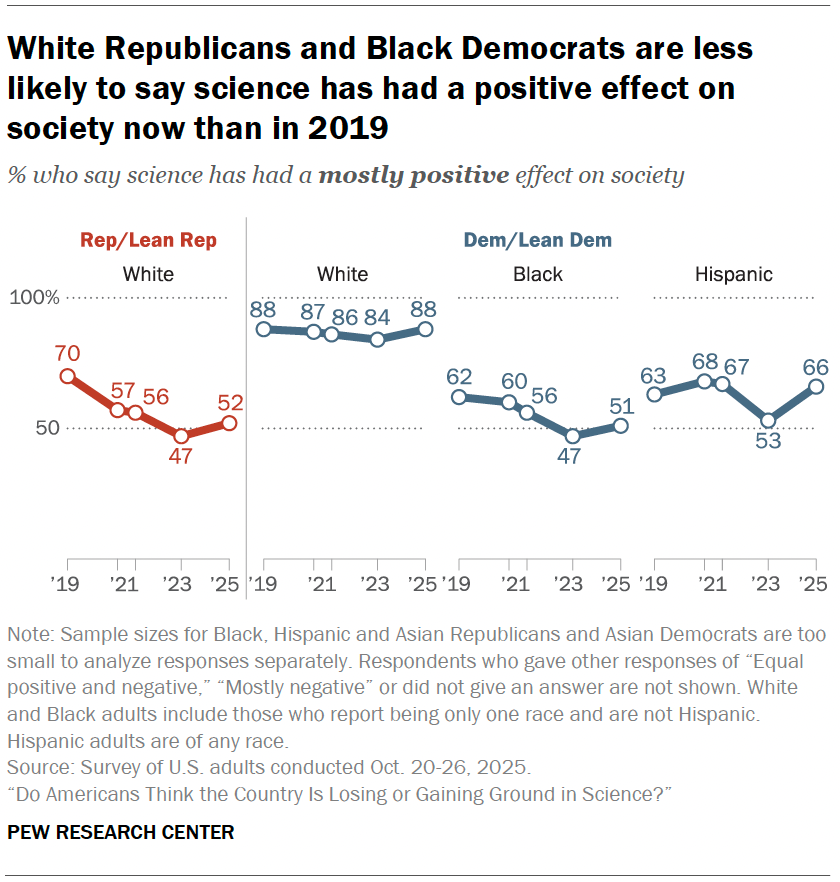
Periodic reminder that the only serious test of the hereditarian hypothesis on group differences showed that large differences in educational attainment were explained by environmental factors correlated with ancestry in Mexico. An example of The Bell Curve getting shredded.
11 Sep 2025

Nonetheless, the results of this study contradict hereditarian ideas that explain all differences in socio-economic outcomes by invoking genetic causes.
18
42
232
34,728
This finding was such a blow that race twitter had to invent a fake study in the UK and then trick Charles Murray into broadcasting it. Elder abuse!
x.com/SashaGusevPosts/status…
18 Sep 2025

Murray and most of race twitter has apparently been fooled by this completely fabricated analysis purporting to show African ancestry is associated with IQ. People lie on twitter all the time, but this is both more revealing and more disturbing than usual. A 🧵
2
10
91
4,552
Jun 13
American century of embarrassment
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
6
12
189
15,205
Sasha Gusev retweeted

Jun 12
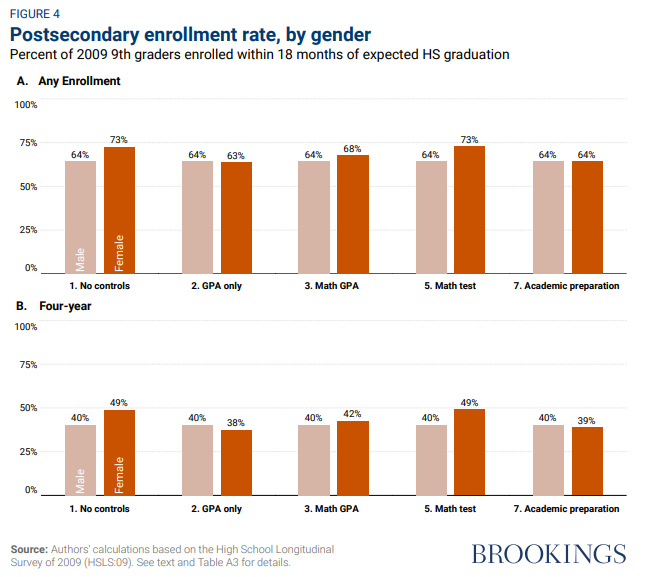
It's not the universities that are failing young men.

The gender gap in college enrollment is *entirely* explained by differences in academic preparation pre-college.
After controlling for high school GPA, math test scores, and other academic factors, girls are slightly *less* likely to enroll in four-year college than boys.
2
33
6,828
Jun 12
Here are some scientists publishing research in reputable scientific journals explaining that heritability is not a measure of innateness:
Jun 12

I just want to assure everyone reading this insane excerpt that there are currently ZERO scientists publishing research in reputable scientific journals who believe that intelligence isn't influenced by heritable factors.
13
24
189
15,169

Sasha Gusev retweeted

Jun 12
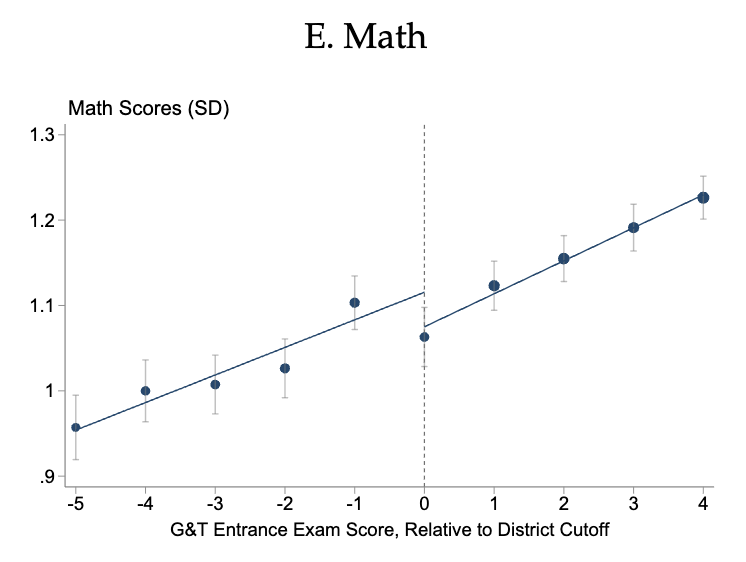
Contra my previous post, it's kind of wild that NYC's Gifted & Talented program no treatment effect on standardized math test scores.
1/
14
10
94
24,584
Jun 12
This is still the best take on the ed policy debates:
4 Oct 2025

Education is a great subject to argue about because everyone thinks they’re an expert by virtue of being a parent or former student and a lot of the “evidence” is incredibly low quality and confounders abound so everyone can just scream at eachother
3
1
49
5,594
Sasha Gusev retweeted

Jun 12
IQ, giftedness, and the heritability thereof is maybe the best example of a divide between *rhetorical* empiricists/technocrats and *actual* experts.
The lib pundits are still in thrall to The Bell Curve; actual geneticists & neurologists have utterly shredded it
118
61
717
212,338
Jun 11
😮
Jun 11

This was evidence of shortcut learning, a well-known problem in machine learning & AI.
Rather than models learning brain-IQ associations, they are learning links between brain-SES.
So much so that models trained to predict brain-IQ associations were better at predicting SES.

6
7
129
19,901
Sasha Gusev retweeted

Jun 11
1. If you ask an LLM to pick the best normalization method for single-cell RNA-seq data, what does it suggest, and why? The answer points to an under-looked aspect of doing science in the age of AI.

4
17
107
18,744
Sasha Gusev retweeted

Jun 10
Self-supervised learning on observational scRNAseq especially with naive reconstruction or masking losses will never deliver a causal model of gene regulation. It will learn statistical structure in expression space, not the mechanisms that generate regulatory change. 1/
Jun 10

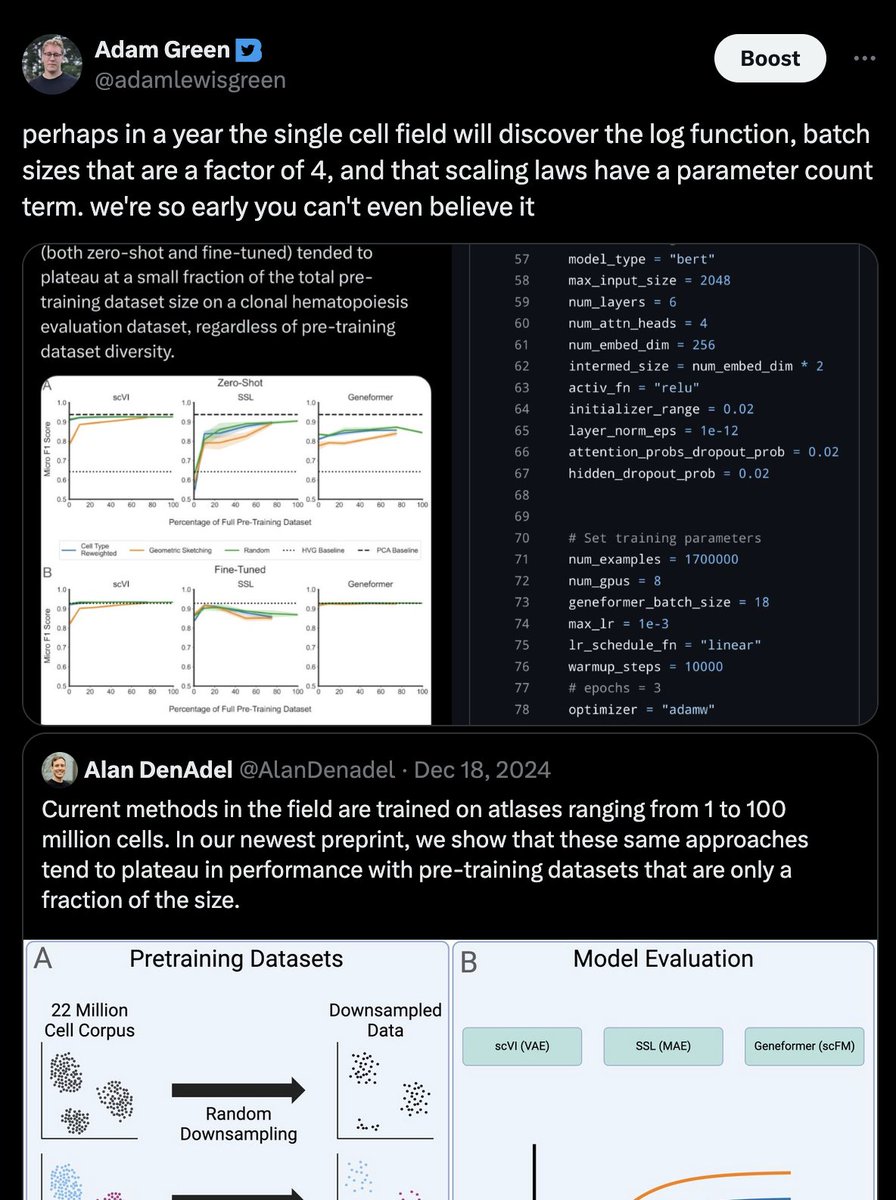
18 months after posting this tweet, the AI for science commentariat is still proclaiming the death of single-cell scaling laws on the basis of... {checks notes}... a model sweep ranging from 1 million to a whopping 10 million parameters. (but unlike 18 months ago, these proclamations now come wrapped in premium AI-written slop, giving them a glittering verisimilitude of rigor)
left as an exercise for the reader: generalize from this example to a meta-update about how epistemically adversarial the scientific environment we're operating in is (for extra credit, partial out the effects of mood affiliation and status deferral)

3
10
129
15,066
Sasha Gusev retweeted

Jun 10
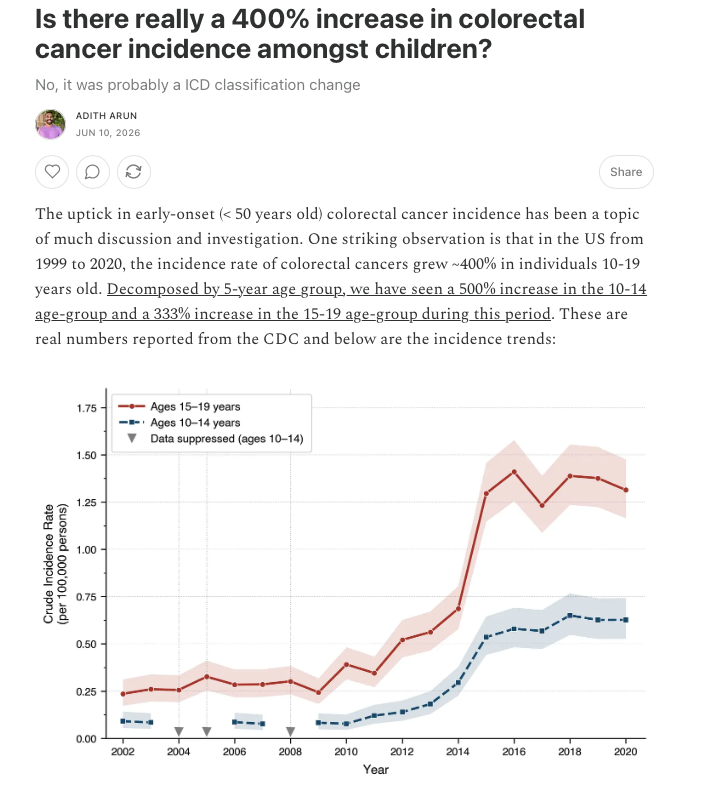
Are colorectal cancer rates really on the rise in the young??
The shape of the incidence curves suggest not. Something happened around 2013. That something was the ICD classification system allowing neuroendocrine tumors of the appendix to be considered malignant colorectal cancers.
[1/2]
Mar 23

After a long hiatus, I'm back to writing - starting with a very topical piece.
Why are colorectal cancer rates spiking in the young?
The usual answers are true: changes in diet, exercise, environment.
But there's also a much more direct player involved

11
48
300
125,397
Jun 10
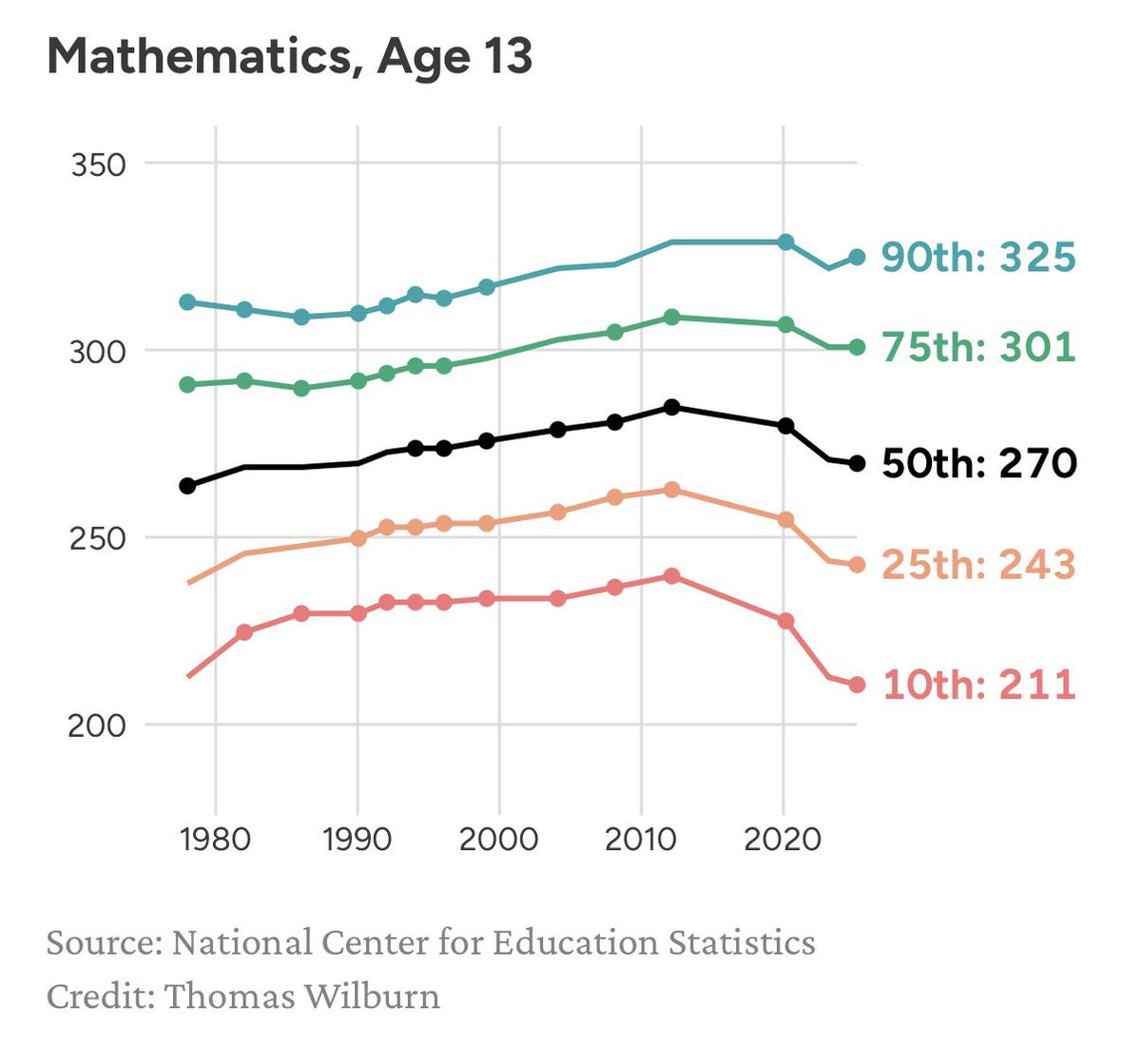
Scarr-Rowe hypothesis in action

New NAEP results are out and it’s clear the bottom has fallen out for our lowest performing math students:
The bottom 10% of students performed worse than any cohort of students on the history of the test going all the way back to the 1970s
3
5
32
8,863
Jun 10
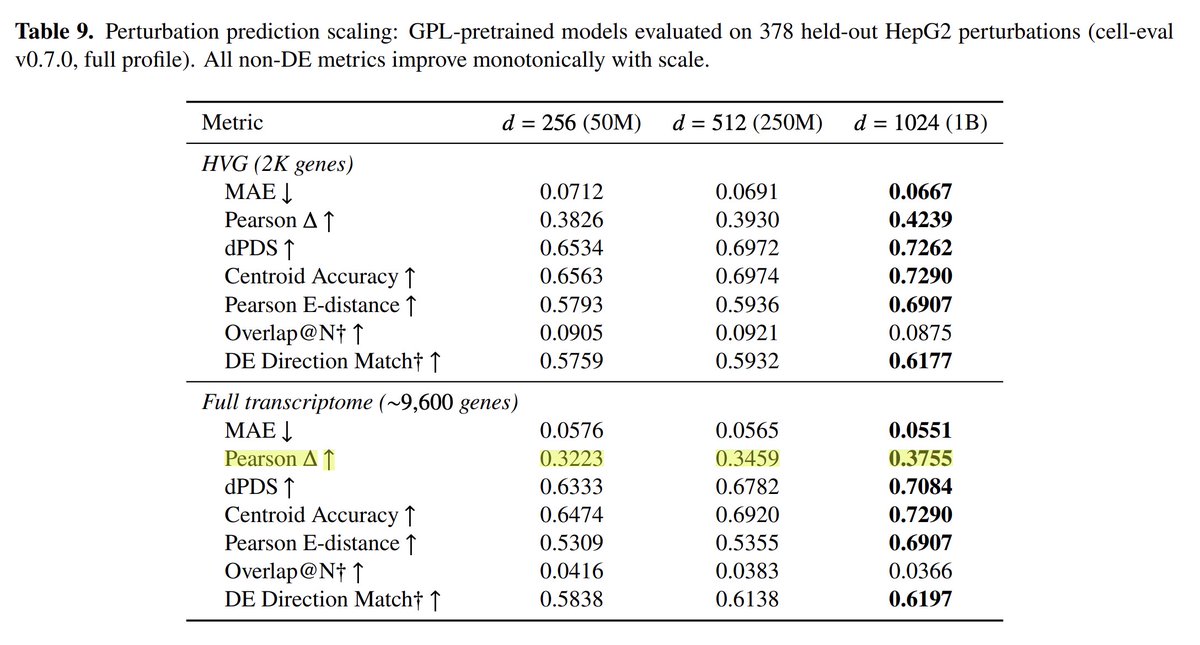
Two years ago the best virtual cell model was ridge regression and yesterday the best virtual cell model was ... ridge regression. But sure, throw a billion more parameters at the problem, no one is stopping you.
Jun 10
18 months after posting this tweet, the AI for science commentariat is still proclaiming the death of single-cell scaling laws on the basis of... {checks notes}... a model sweep ranging from 1 million to a whopping 10 million parameters. (but unlike 18 months ago, these proclamations now come wrapped in premium AI-written slop, giving them a glittering verisimilitude of rigor)
left as an exercise for the reader: generalize from this example to a meta-update about how epistemically adversarial the scientific environment we're operating in is (for extra credit, partial out the effects of mood affiliation and status deferral)
7
47
344
35,459
Sasha Gusev retweeted

Jun 10
Arguably the most boring step in genomics is the first one: normalization. Settled science. Scale log. Move on.
Except that here's been a huge blind spot in the field. And it matters for AIxBio. A 🧵about what I think may be one of the most important papers I've written. 1/
18
147
669
113,657
Sasha Gusev retweeted

Jun 10
My first main use of Mythos-backed Fable model is to go through older AI-driven vibe-coded analysis that may have been sketch and figure out if they were actually right or not. So far very helpful! (1/2)
2
1
54
20,689
Sasha Gusev retweeted

Jun 9
No scaling laws for single-cell foundation models: when bigger atlases stop teaching the model anything
In language and vision, the recipe has been simple: more data, bigger models, better performance. Single-cell biology borrowed that playbook. Foundation models for transcriptomics jumped from 1 million cells to atlases of over 100 million, on the assumption that scale would unlock the same gains. Alan DenAdel and coauthors put that assumption to the test, and the result is sobering.
Working from a 22.2-million-cell corpus, they pretrained 400 models across five architectures (from PCA and a variational autoencoder up to the Geneformer transformer) and ran 6,400 evaluation experiments. They varied not just dataset size (1% to 75%) but also diversity, using cell-type re-weighting and geometric sketching to deliberately enrich rare cell types and transcriptional states.
The finding: performance saturates almost immediately. On cell-type classification, batch integration, and perturbation prediction, most models hit their ceiling at roughly 1% of the corpus, about 200,000 cells. Beyond that, adding millions more cells changed essentially nothing. More diversity didn't help. Even spiking in genome-scale Perturb-seq data, to give the models perturbed phenotypes rather than just healthy ones, failed to move the needle. Larger models did score better overall, but they too plateaued early on data.
Two points stood out. Simple baselines (PCA, logistic regression) often matched or beat the transformers. And the strongest model, SCimilarity, won not because of size but because its contrastive training objective is aligned with the downstream task. For single-cell data, what you train on and how you frame the objective matters far more than how much you collect.
This reframes a quiet but expensive habit. In drug discovery, biotech, and any pipeline leaning on cell atlases, the instinct to keep scaling pretraining corpora may be burning compute for no return. The real leverage sits elsewhere: curating high-quality, task-relevant data and matching the training objective to the actual question you're trying to answer.
Paper: DenAdel et al., journal license | doi.org/10.1038/s41592-026-0…

15
93
380
95,356