
Revolutionize enterprise AI with Data Sovereignty using rapid-deployed Tier 3N 1 Data Centers—secure, scalable, and fully compliant.
- Tweets 21
- Following 3
- Followers 2
- Likes 0
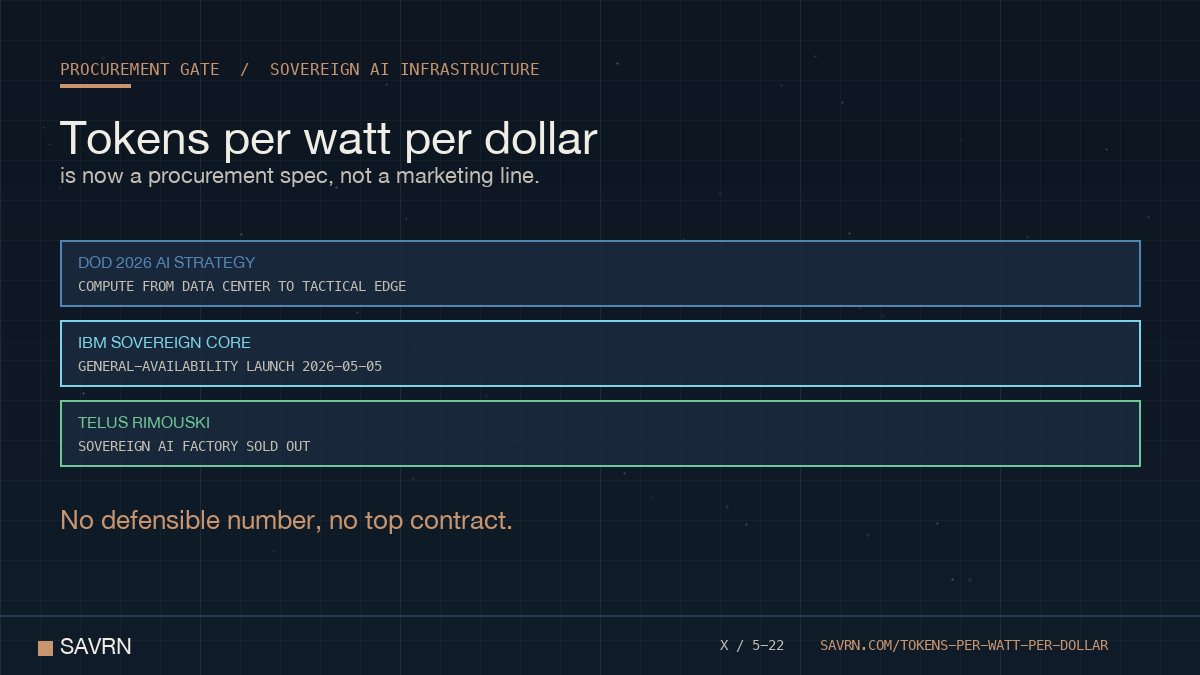







ALT Procurement gate for sovereign AI infrastructure. Tokens per watt per dollar is now a procurement spec, not a marketing line. The DoD 2026 AI strategy mandates compute from data center to tactical edge. IBM Sovereign Core launched general availability on May 5, 2026. TELUS Rimouski sovereign AI factory sold out. No defensible number, no top contract.
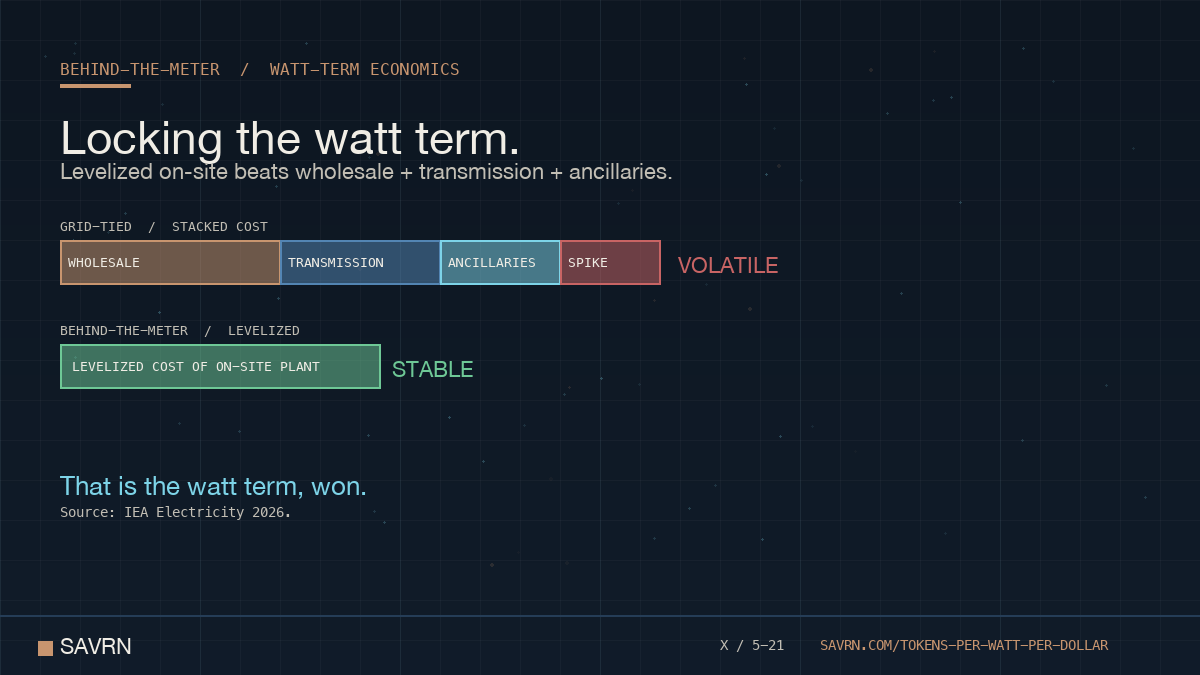
ALT Behind-the-meter watt-term economics for tokens per watt per dollar. Grid-tied operators face stacked costs: wholesale, transmission, ancillaries, and AI-driven spike premiums. The IEA Electricity 2026 report flags volatile pricing on regional grids. Behind-the-meter generation locks the cost at the levelized cost of the on-site plant, delivering a stable watt term.
ALT The PUE trap visualized for tokens per watt per dollar. Two operators with the same Power Usage Effectiveness number deliver very different intelligence per electron. Operator A at PUE 1.20 with idle GPUs wastes compute. Operator B at PUE 1.45 with fully utilized inference at high rack density delivers far more useful tokens per kilowatt. PUE alone is misleading.
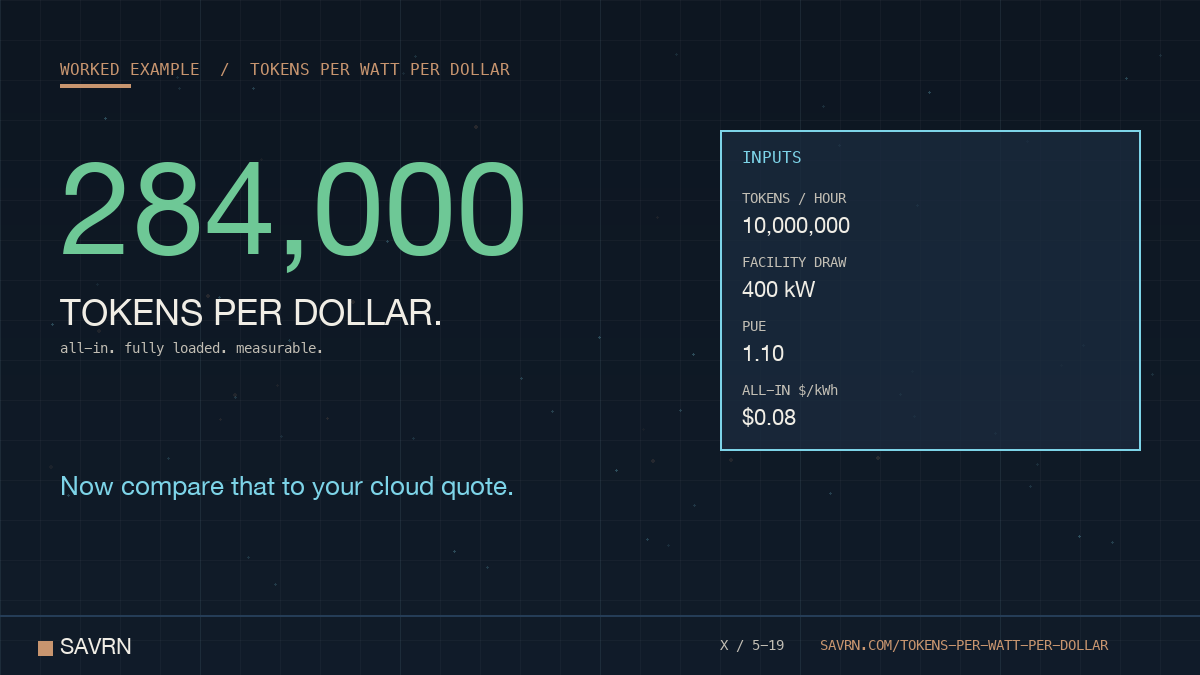
ALT Worked example for tokens per watt per dollar. 10 million served tokens per hour, 400 kilowatt facility draw at 1.10 PUE, 8 cents per kilowatt-hour all-in cost, equals approximately 284,000 tokens per dollar of fully-loaded infrastructure spend.
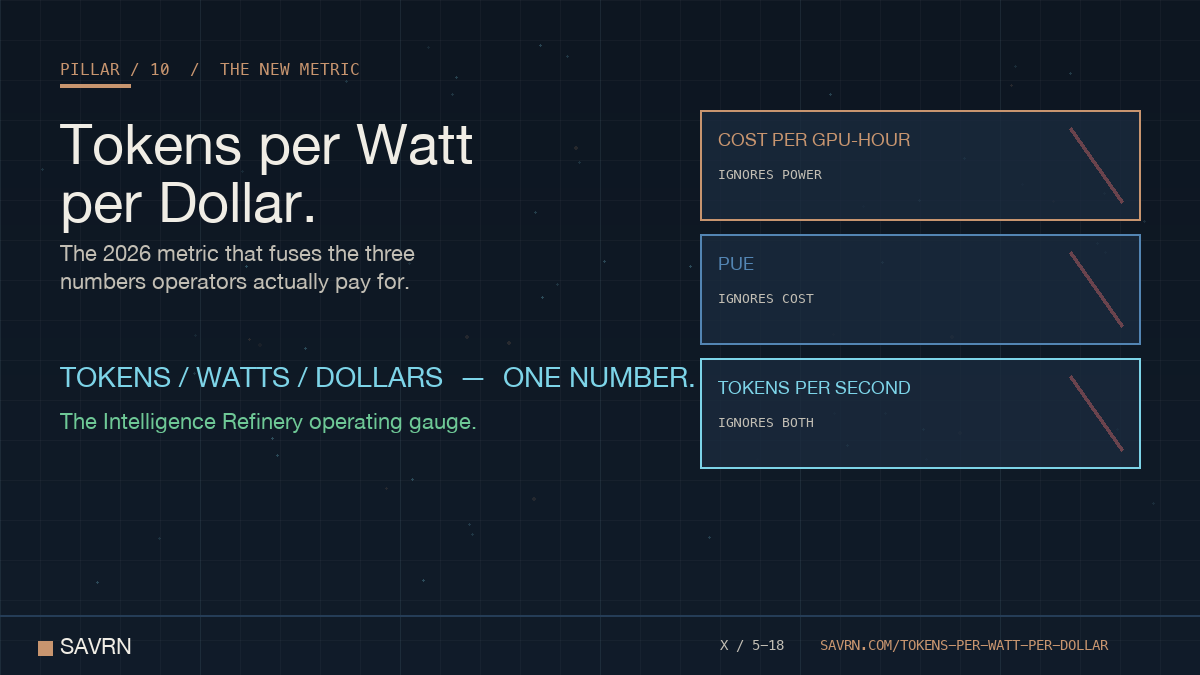
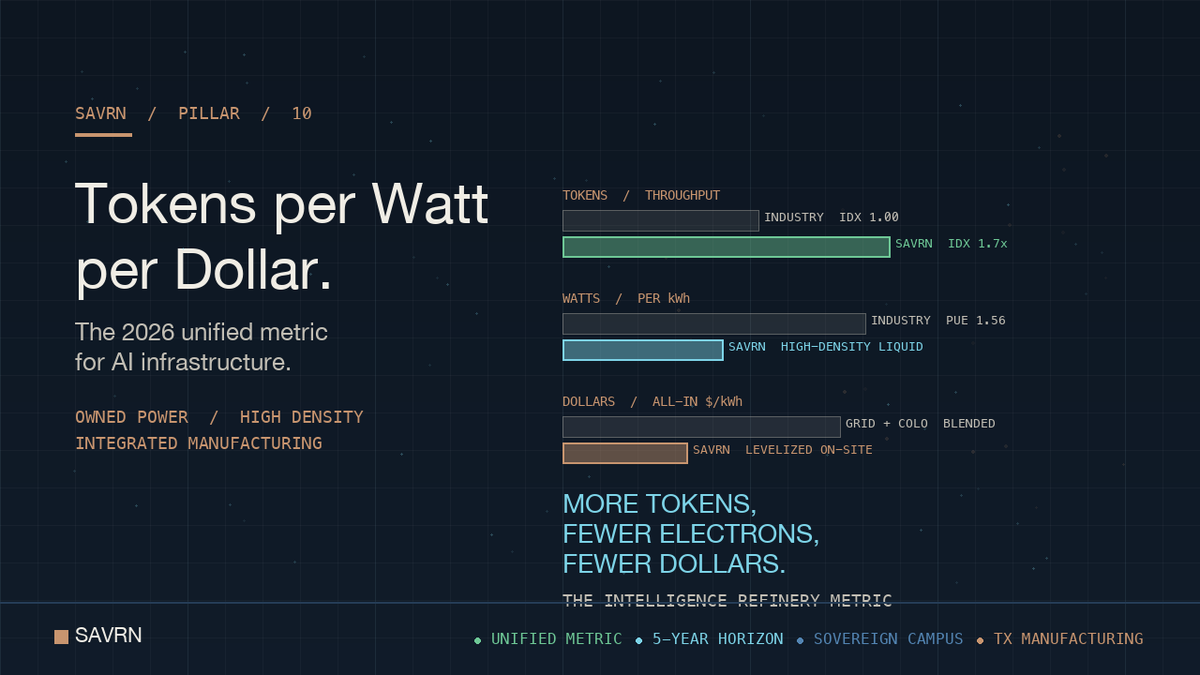
ALT Tokens per watt per dollar - the 2026 AI infrastructure metric. Three legacy units each cover one blind spot: cost per GPU-hour ignores power, PUE ignores cost, tokens per second ignores both. The unified metric fuses tokens, watts, and dollars into one operator-grade gauge.
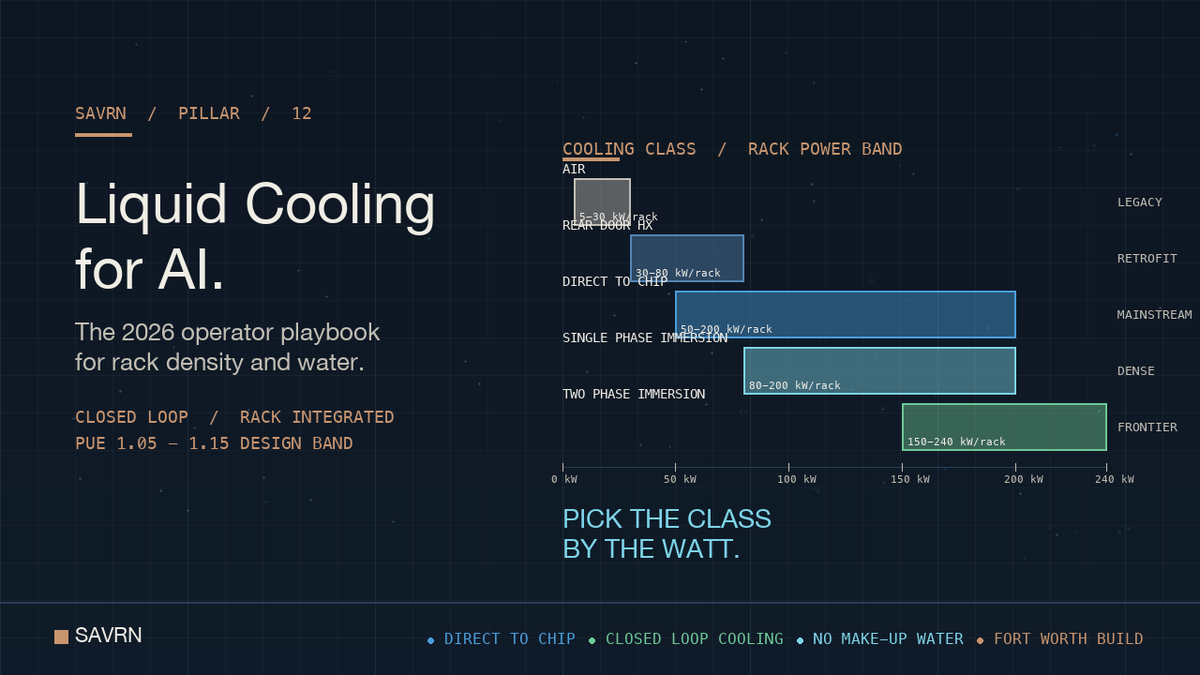
ALT SAVRN density playbook chart for liquid cooling for AI. Five cooling classes mapped to rack power bands: air up to 30 kW, rear-door 30 to 80 kW, direct-to-chip 50 to 200 kW, single-phase immersion 80 to 200 kW, two-phase immersion 150 to 240 kW.
ALT Companion to The Quiet Rewrite: Every US Grid Operator Is Rebuilding the Rules for AI Data Centers — At the Same Time. Every load-bearing claim in the article, mapped to the primary docket, filing, datasheet, or board minute that supports it. If you challenge any specific number, date, tariff, or technical claim in this report, the trail is here.
ALT Tokens per watt per dollar is the 2026 AI infrastructure metric that fuses cost, power, and throughput. SAVRN's sovereign campus wins it.
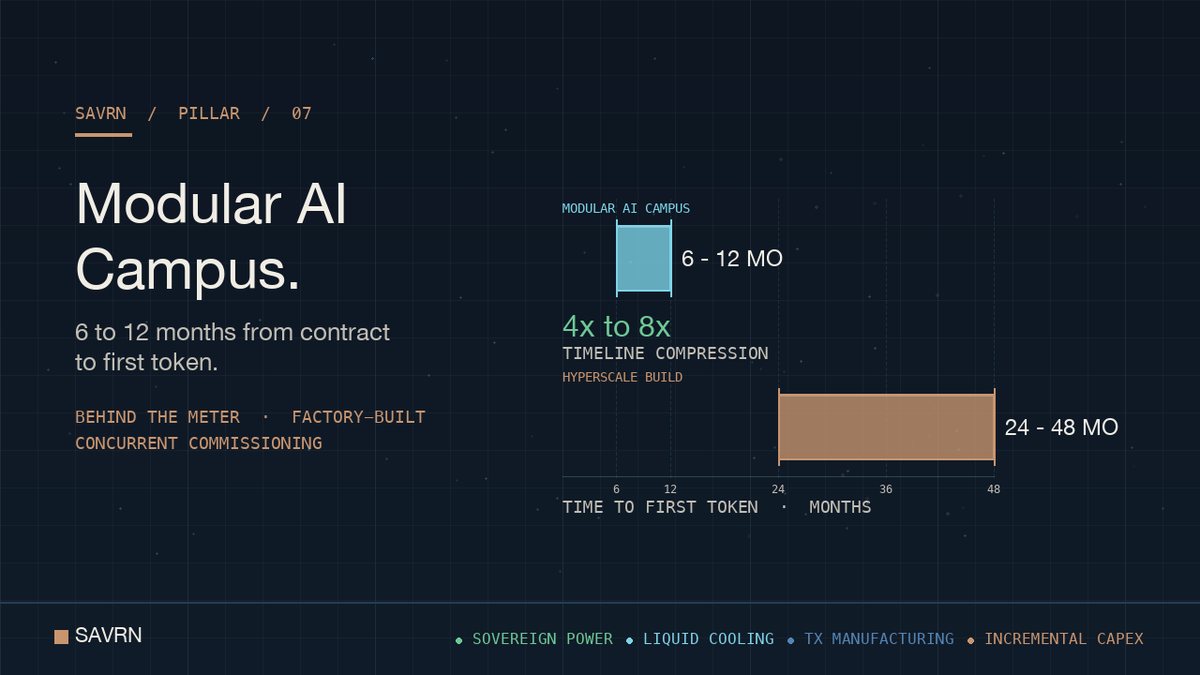
ALT Modular AI Campus: How 6 Months Beats Hyperscale Builds

ALT Frustrated enterprise IT leader looking at a slow, fragmented data center dashboard, symbolizing delays and compliance risks in traditional AI infrastructure.
ALT Chad Everett Harris teamed up with the Chuck L'Ecuyer from Intelliflex to develop Savrn. Savrn accelerates the deployment of AI infrastructure with engineered speed, enterprise-grade control, and total transparency. We build faster. We scale smarter. #EnterpriseAdvantage #BuiltForAI #intelliflex #chadeverettharris #chucklecuyer
ALT Chad Everett Harris' Savrn Enterprise Platform for AI. - Deploy enterprise AI infrastructure in under 12 months—up to 65% faster than legacy models. Speed is your new advantage. #SpeedToAI #DigitalTransformation
ALT Pre-Integrated, Offsite-Engineered: Savrn delivers factory-assembled, tested, and certified systems for rapid, risk-free deployment. No more on-site chaos—just seamless go-live. #EngineeringExcellence #AIReady
ALT Sovereign-by-Design Architecture: Embedded compliance, data residency, and operational autonomy are built in from day one. Your data, your rules, your future. #Sovereignty #Compliance