
Joined September 2014
- Tweets 2,754
- Following 1,569
- Followers 1,813
- Likes 4,239
164 Photos and videos








Herbert B Schiller retweeted

Jun 9
The compounding value of multi-dimensional biobanks is extremely mind blowing.
UK Biobank recruited ~500,000 people between 2006 and 2010, collected baseline measurements and biological samples, and continued linking participants to health records as diseases developed over time.
The interesting findings about disease and survival now coming out of it depend on that cohort having been tracked for fifteen-plus years.
Like this Cell paper using it to connect 2,920 plasma proteins in 53,026 people to hundreds of diseases and health-related traits. That produced hundreds of thousands protein-disease and protein-trait associations from one longitudinal resource. The authors also identified 37 drug-repurposing prospects and 26 potential targets with favorable safety profiles. cell.com/cell/fulltext/S0092…
And there will be more.
Longitudinal time is a non-substitutable input, as we've written about (link below). No amount of money could recreate UK Biobank by next month.


3
28
123
21,215

Jun 12
Happy to see our study out in @JCI_insight - collaborative work with Northwestern Chicago - see a full thread by @KapellosTS below.

Happy to share that our work together with @SchillerLab, Scott Budinger, Ben Singer and Sasha Misharin from @NorthwesternMed is now online on @JCI_insight. A full tweetorial that summarizes the study follows! @LMU_Muenchen @HelmholtzMunich @LungHealthMUC
2
3
757
Herbert B Schiller retweeted

Jun 12
In January at DLD, one of Europe’s leading innovation conferences, the motto was: “It’ll be wild.” 🚀
Today at DLD Health x BAIOSPHERE, it got healthy.
A pleasure to open the event after Steffi Czerny and Alessia Sinzger and discuss what may be the next chapter of AI in biomedicine.
For the past few years, foundation models have helped us build representations of proteins, cells, tissues and patients.
Now the focus is shifting from representation to action.
How can AI help us identify the next experiment?
How can we move from describing biology to intervening in it?
How do we build world models that allow us to simulate and test ideas before moving into the laboratory or clinic?
At Helmholtz Munich, together with many partners across academia and industry, we are working toward this vision through initiatives such as the Virtual Human.
The discussions that followed highlighted just how much innovation depends on strong ecosystems:
📍 Markus Söder spoke about Bavaria’s long term commitment to science and technology and the importance of investing early in future defining fields. Many of the strengths of Bavaria’s AI and biotech landscape today are the result of decisions made years ago.
📍 Matthias Tschöp shared perspectives from the obesity revolution. One thought that stayed with me: if you are lean and not taking one of the new obesity drugs, you are largely lucky, not morally superior. Obesity is a disease shaped by genetics and environment, not simply individual choice.
📍 Markus Blume highlighted Bavaria’s growing AI and health ecosystem and the opportunities created by connecting research, healthcare and entrepreneurship.
📍 Nobel Laureate Ferenc Krausz presented fascinating work on blood based screening technologies that could transform early disease detection and prevention.
A recurring theme throughout the day:
The future of health will not be built by scientists alone.
It will not be built by clinicians alone.
It will not be built by entrepreneurs, investors or policymakers alone.
It will be built where all of these communities meet.
Thank you to DLD, BAIOSPHERE and all participants for an inspiring day and for the many conversations on how AI can help us move from disease management toward prevention.
#DLDHealth #BAIOSPHERE #AIforHealth



2
8
1,932
Herbert B Schiller retweeted

Jun 11
Interactome mapping has been stuck at a few hundred baits over months. HIP-MS changes the regime: ~10,000 pulldowns/week at 500 samples/day, fully automated. A new era for interactomics — and a precursor to high-throughput proteomics writ large. doi.org/10.64898/2026.06.03.…
1
22
89
7,389

great thread about the most fundamental steps in single cell data analysis! 🙏
Jun 10

Arguably the most boring step in genomics is the first one: normalization. Settled science. Scale log. Move on.
Except that here's been a huge blind spot in the field. And it matters for AIxBio. A 🧵about what I think may be one of the most important papers I've written. 1/
2
6
37
7,666
Herbert B Schiller retweeted

Jun 10
Arguably the most boring step in genomics is the first one: normalization. Settled science. Scale log. Move on.
Except that here's been a huge blind spot in the field. And it matters for AIxBio. A 🧵about what I think may be one of the most important papers I've written. 1/
18
147
670
114,041
Herbert B Schiller retweeted

Jun 12
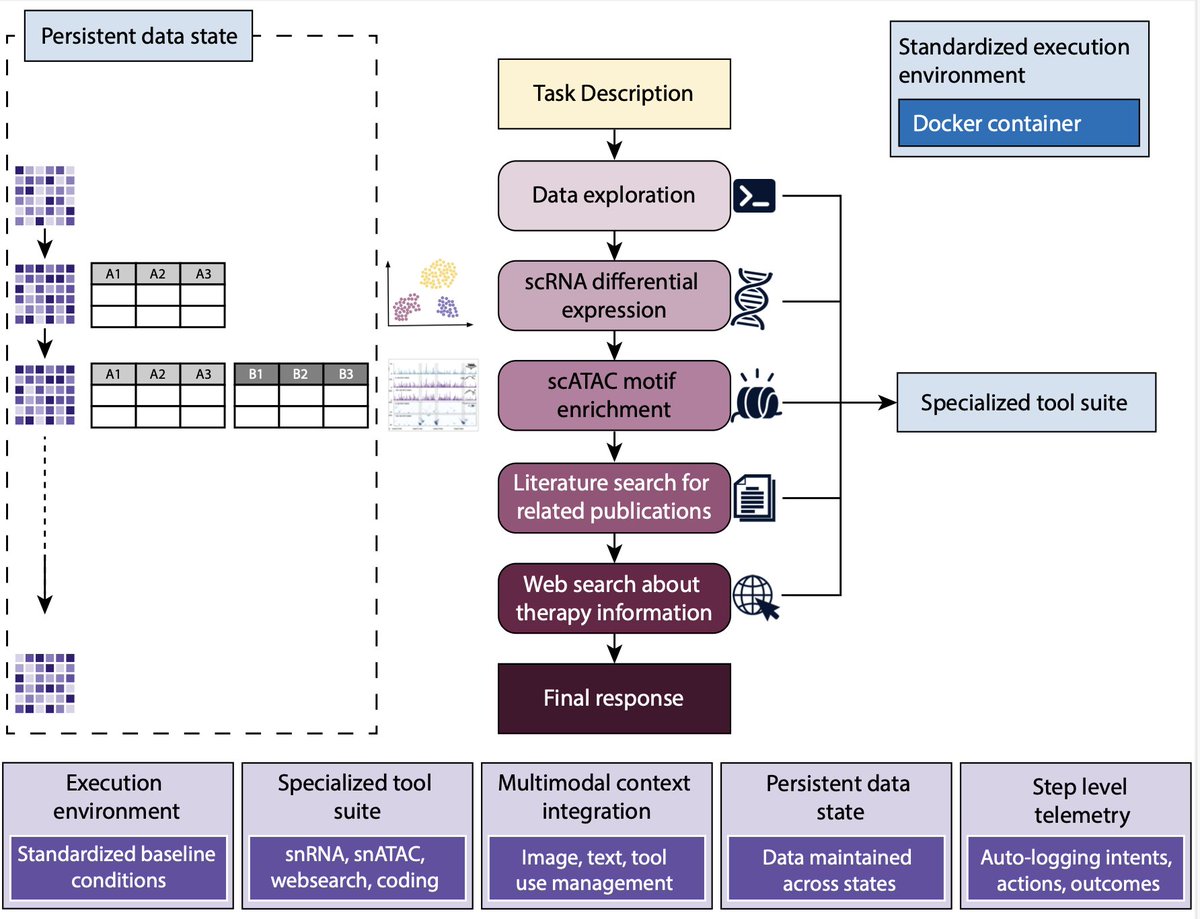
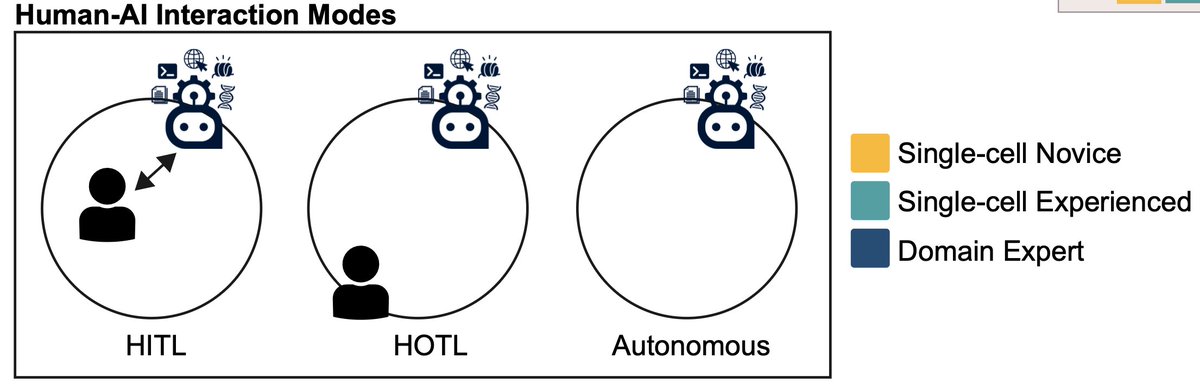
Can AI agents do real science, i.e open-ended reasoning, not just pipeline execution?
Interesting bioRxiv piece from Eli Van Allen's group at Dana-Farber/Broad. They ran a Claude Opus 4.6 agent on cancer multiomic data to find out. TLDR seems to be: neither thinking longer nor scaling up buys you the long tail. In more detail:
- Turns out the agent is strong at calling abundant cell types (82.2% correct) and much weaker for rarer ones (43.8% pass). Cell-type calls tracked the density of training evidence, not biological importance.
- Same shape on hypothesis ranking. It beat chance (30% top-1 vs 11%) but over-ranked fashionables themes that flood the literature (EMT/stromal, immune) and under-ranked metabolism and neuronal programs. Least reliable on the under-documented biology most likely to be novel.
- The authors have a clear view on the fix: not bigger models. Targeted training on underrepresented biology. Scaling does not buy you the long tail.
- Surprisingly, more reasoning steps did not mean better answers. Scrutiny depth tracked ambiguity, not correctness. Effort was a symptom of difficulty, not a driver of accuracy.
- The copilot arc also surprised me. Fully autonomous runs ranked highest in blinded expert review and read as more novel. Constant human intervention introduced a conservative bias that recapitulated known biology!! But autonomous quality fell as tasks got harder, and experts won on the hardest reasoning.
Hence their hybrid model: autonomous exploration first, human judgment for interpretation.

In our latest, we tested elements of cancer biology research using @AnthropicAI AI agents, with varying amounts of human involvement across multi-step, multi-omic analyses
Interesting times for agentic AI & biological discovery, and for the future of (cancer) biology research...
2
6
33
3,947

Totally over the moon 🤩 , our paper on charting human cellular senescence in aging and disease is on the cover!! It highlights the collective efforts and the first wave of publications from NIH @sennetresearch consortium to map senescent cell states, heterogeneity and niches!!
Jun 11

New issue alert 👉cell.com/cell/current
This issue's cover artwork portrays the gradual emergence of cellular senescence across the human lifespan reflecting the effort of the Cellular Senescence Network (SenNet) to chart the evolving landscape of human cellular senescence

11
45
275
24,700
Herbert B Schiller retweeted

Jun 11
13. In conclusion, if you want a scRNAseq normalization method to best satisfy
- depth norm
- variance stabilization
- monotonicity
Run PFlogPF (package coming soon).
The code is available here: github.com/pachterlab/BHGP_2…
The manuscript is available here: biorxiv.org/content/10.1101/…
1
1
18
1,162
Herbert B Schiller retweeted

Jun 11
Our stream for Single Cell Genomics Day goes live tomorrow morning at satijalab.org/scgd , look forward to seeing you there for our 10th year!

25
103
10,763
Jun 11
Agree - number of perturbations but also correct context key (e.g. perturbs in vivo or ex vivo in human tissue culture).

As I have pointed out many times publicly, single cell foundation model performance will scale with the number of perturbations, not the number of cells.
We barely have ~100k perturbations in the public domain and it is reasonable to expect we need millions to truly go OOD. Factor in also: modalities, time points, combinations etc.
Short term, there is little to do using public data.
Best medium term option, consider semi-mechanistic modelling: arxiv.org/abs/2501.19178
Long term, …, wait for the press release ;)
1
6
1,523
Herbert B Schiller retweeted
Jun 11
Do single-cell foundation models obey scaling laws?
A somewhat thought-provoking new Nature Methods study by the Crawford lab suggests that, for current single-cell foundation models, the answer may be “not really.” Across a broad range of architectures and downstream tasks, increasing pretraining data from hundreds of thousands to tens of millions of cells yielded surprisingly limited gains, with performance often saturating much earlier than expected.
This is interesting and provides exactly the kind of rigorous benchmarking our field needs. As Felix Fischer and I commented in the accompanying Research Briefing, such studies help move the discussion beyond model size and computational budgets toward actual scientific utility.
At the same time, I am not convinced the key conclusion is that scaling does not work in biology. Rather, it may be that current objectives are not extracting enough information from additional data.
Interestingly, in our recent scConcept work, we observe a markedly different scaling behavior, with continued gains as training data grows toward hundreds of millions of cells. The key difference may be the training objective itself: instead of reconstruction-based masked modeling, scConcept uses a contrastive objective that directly optimizes biologically meaningful cell representations.
biorxiv.org/content/10.1101/…
This raises an interesting question for the field: Have we reached the limits of data scaling, or only the limits of current objectives?
-> My guess is that the next generation of biological foundation models will depend less on simply collecting more cells and more on finding the right representation learning principles for biology.
Nature Methods paper:
nature.com/articles/s41592-0…
Research Briefing:
nature.com/articles/s41592-0…
#SingleCell #FoundationModels #AIforBiology

10
52
229
28,026
Herbert B Schiller retweeted

Jun 9
every year @newlimit, we host friends at the lab & share our progress
for 2026, we announced:
- 2X increase in discovery rates with AI systems
- new program for endothelial cells
- 0 -> 1 medicines headed to the clinic
- accelerating recovery from alcohol
some highlights --
14
30
243
241,814
Herbert B Schiller retweeted
Jun 9
Excited to kick off #HAICON26 today! 🚀🤖
More than 600 participants joining us to explore how AI is transforming science and accelerating discovery. Great energy, great people, and an exciting program ahead.
👉 haicon.cc
#AIforScience #HAICON26

3
6
33
2,967
Herbert B Schiller retweeted
Jun 6
Two decades of longevity experiments in more than 30,000 mice have created ground truth for a future of progress.
The NIA’s Interventions Testing Program is a multi-site mouse lifespan testing project. It has so far evaluated >50 compounds linked to aging, becoming gold-standard infrastructure for truth-seeking in the field.
Longevity needs this because it attracts hype so easily. Resveratrol is a good example. It had some early evidence, plus a major supplement market. Then the ITP found no general lifespan benefit in genetically heterogeneous mice.
Rapamycin went the other way. The ITP strengthened its anti-aging signal, and @impetusgrants-funded trials on rapamycin such as VIBRANT and RAPID show the brighter path from robust mouse data to potential therapeutics tested in humans.
It's evident that progress comes from robust truth-seeking infrastructure. The ITP already links interventions to hard lifespan outcomes. More progress would come from using that infrastructure more fully, adding lower-layer measurements and linking them to the hard outcomes that ITP-like systems can generate.
We wrote about this in our latest essay: how task-shaped ground-truth data could compound progress by making future AI more useful for longevity (link below.) It could help models learn from intervention-linked outcomes, validate aging biomarkers and clocks, and make mouse studies a faster loop for human-relevant questions.
Infrastructure for Maximum truth-seeking -> Plentyful Progress -> More Years to Life


2
9
34
3,819
Herbert B Schiller retweeted

Jun 4
Detecting lung cancer 5 years before it happens, in @CellCellPress courtesy of the @CharlesSwanton group.
Astonishing translational work !
cell.com/action/showPdf?pii=…




4
90
334
26,585
Herbert B Schiller retweeted
Jun 2
on day 1 @newlimit, we imagined it would take 10 years to invent real medicines.
our recent results have accelerated the timeline to next year. we've raised a Series C led by @foundersfund alongside @ThriveCapital, @Greenoaks, and many others to bring therapies to the clinic.
medicines for aging are among the most valuable possible technologies. we are grateful to our partners for the opportunity to pursue this mission.

Following breakthrough results, we’re bringing longevity medicine to human trials.
We’ve raised a $435M Series C led by @foundersfund to make it happen.
Reprogramming cell age has the potential to create more healthy years for everyone. We're closer than ever to realizing it.
67
61
644
96,783
Herbert B Schiller retweeted

Jun 1
Hermes Agent on @NVIDIARTXSpark superchip and integrated with the new OpenShell runtime.
This is powerful and will be the substrate we have been waiting for at The Zero-Human Company.
10
16
96
8,221
Herbert B Schiller retweeted

Jun 1
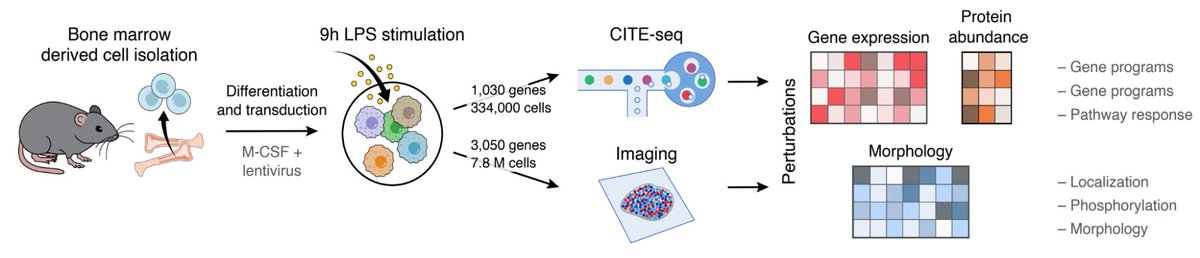
🚀 We are introducing PerturbPair (with @TakaKud0) — a platform that combines parallel Perturb-seq and optical pooled screening (OPS/PerturbView) in primary cells to systematically map at massive scale how genetic perturbations reshape cellular states across modalities.
With wonderful collaborators @TakaKud0, @AnaMeireles, @AntRios, @jchuetter, @MinOta, @ORozenblattRosen, @LeviAGarraway, @KGeiger, @avtarsingh, @jkpritch, and Aviv Regev.
Paper link: biorxiv.org/content/10.64898…
2
39
190
12,675
Herbert B Schiller retweeted
Jun 1
Our 10th Single Cell Genomics Day is next Friday (6/12)!
Thanks to amazing speakers Aviv Regev @xinjin @anshulkundaje @junyue_cao and many more! Talks are live-streamed on YouTube and are free (no registration required) at satijalab.org/scgd

4
50
187
30,974