
Joined December 2010
- Tweets 14,867
- Following 3,389
- Followers 11,825
- Likes 26,420
1,140 Photos and videos














How much of Thermo Fisher’s antibody data has been manipulated?
#ResearchIntegrity
reeserichardson.blog/2026/05…
2
260
The Sharing Scientist retweeted

Apr 27
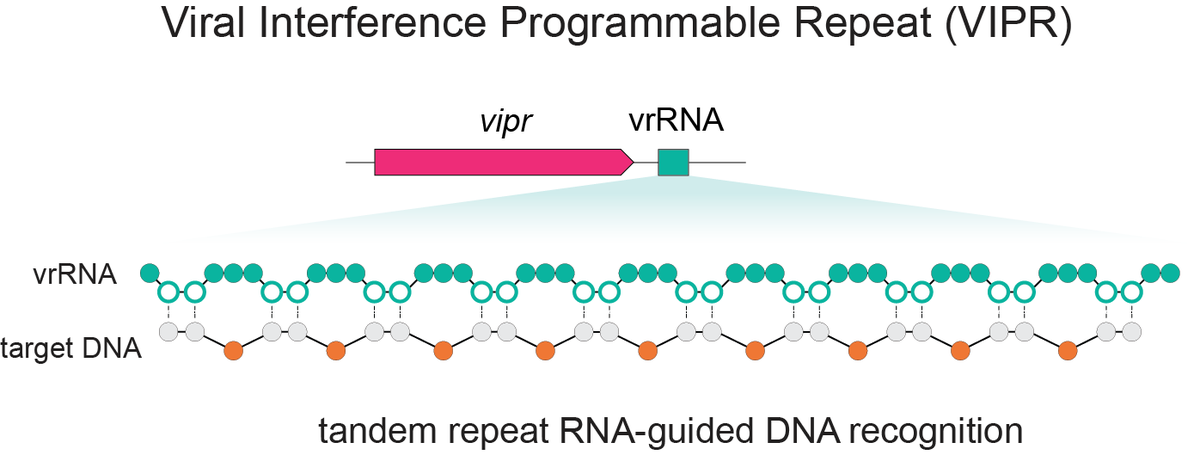
Excited to share our discovery of a new programmable RNA-guided DNA-targeting system hiding inside bacteriophages that predates CRISPR.
We call it VIPR (Viral Interference Programmable Repeat), and it uses an entirely new logic to find its targets.
Thread link below.
26
353
1,258
241,125
The Sharing Scientist retweeted

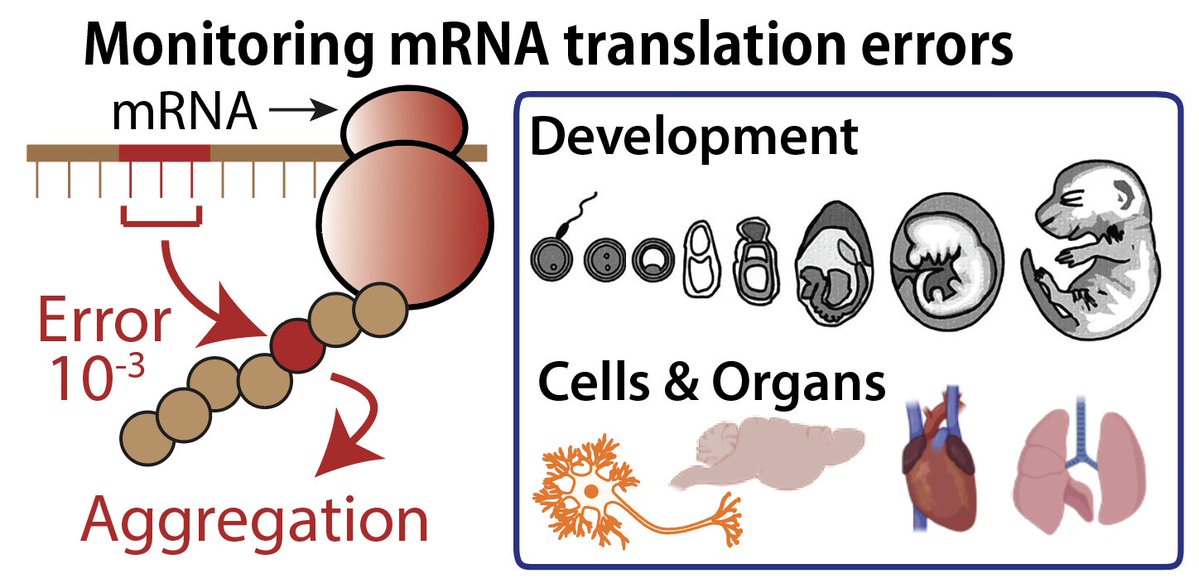
Protein synthesis is not equally accurate across organs.
Excited to share our new preprint:
biorxiv.org/content/10.64898…
We developed a new mouse model to quantitatively monitor translation errors and uncovered the spatiotemporal dynamics of the “quality” of protein synthesis.
5
82
344
26,300

(1/2) EMBL researchers have developed a microscopy technique that enables them to observe individual RNA molecules being produced and folding into different shapes.
Learn more: science.org/doi/10.1126/scia…
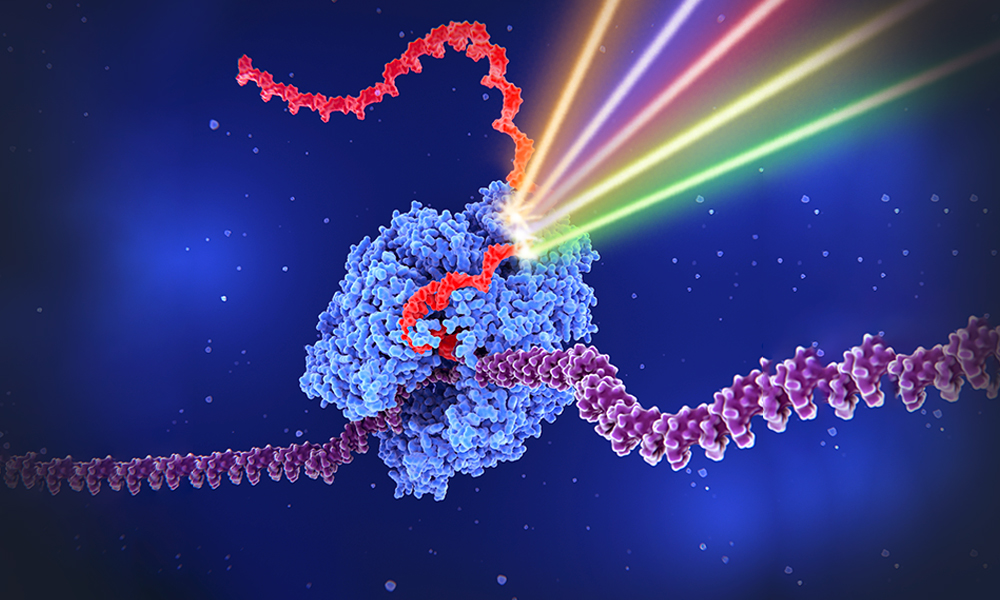
ALT Illustration showing RNA polymerase and four laser lights. Credit: Daniela Velasco/EMBL
2
34
121
26,758
The Sharing Scientist retweeted

Mar 20
A periodic reminder to leave behind simplistic & naive notions.

20
78
573
49,964
The Sharing Scientist retweeted

Mar 6
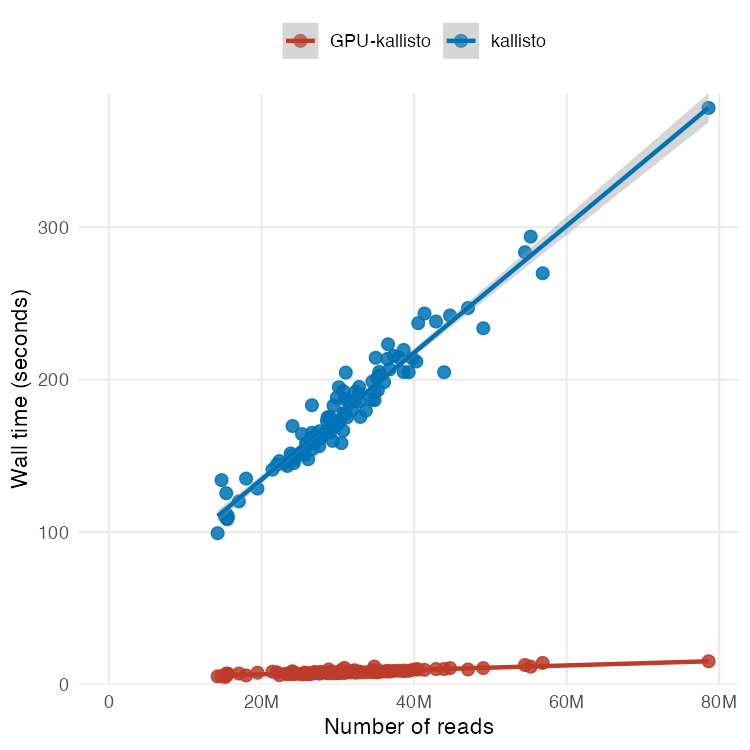
Excited to share this preprint that describes my latest work on using GPUs to accelerate processing of RNA-seq data.
The title says it all: "RNA-seq analysis in seconds using GPUs" now on biorxiv biorxiv.org/content/10.64898…
Figure 1 shows they key result
15
123
489
91,582
The Sharing Scientist retweeted

Feb 20
The math on this project should mass-humble every AI lab on the planet.
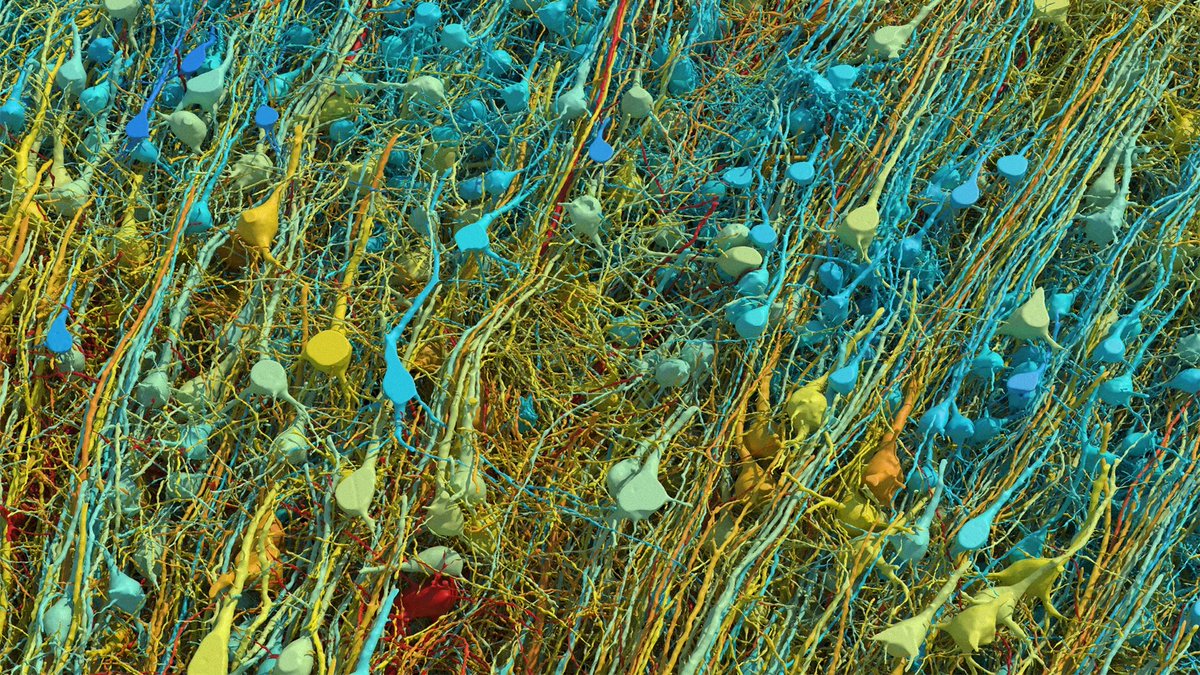
1 cubic millimeter. One-millionth of a human brain. Harvard and Google spent 10 years mapping it. The imaging alone took 326 days. They sliced the tissue into 5,000 wafers each 30 nanometers thick, ran them through a $6 million electron microscope, then needed Google’s ML models to stitch the 3D reconstruction because no human team could process the output.
The result: 57,000 cells, 150 million synapses, 230 millimeters of blood vessels, compressed into 1.4 petabytes of raw data. For context, 1.4 petabytes is roughly 1.4 million gigabytes. From a speck smaller than a grain of rice.
Now scale that. The full human brain is one million times larger. Mapping the whole thing at this resolution would produce approximately 1.4 zettabytes of data. That’s roughly equal to all the data generated on Earth in a single year. The storage alone would cost an estimated $50 billion and require a 140-acre data center, which would make it the largest on the planet.
And they found things textbooks don’t contain. One neuron had over 5,000 connection points. Some axons had coiled themselves into tight whorls for completely unknown reasons. Pairs of cell clusters grew in mirror images of each other. Jeff Lichtman, the Harvard lead, said there’s “a chasm between what we already know and what we need to know.”
This is why the next step isn’t a human brain. It’s a mouse hippocampus, 10 cubic millimeters, over the next five years. Because even a mouse brain is 1,000x larger than what they just mapped, and the full mouse connectome is the proof of concept before anyone attempts the human one.
We’re building AI systems that loosely mimic neural networks while still unable to fully read the wiring diagram of a single cubic millimeter of the thing we’re trying to imitate. The original is 1.4 petabytes per millionth of its volume. Every AI model on Earth fits in a fraction of that.
The brain runs on 20 watts and fits in your skull. The data center required to merely describe one-millionth of it would span 140 acres.
Feb 17

🚨: Scientists mapped 1 mm³ of a human brain ─ less than a grain of rice ─ and a microscopic cosmos appeared.

1,159
11,911
63,697
4,618,034
Mucosal vaccination in mice provides protection from diverse respiratory threats
science.org/doi/10.1126/scie…
1
253
The Sharing Scientist retweeted

Feb 6
Too much data, too little thinking.
A important essay from Ruslan Medzhitov on the importance of understanding data, not just generating it. A must read.
@RMedzhitov @YaleIBIO
nature.com/articles/s41577-0…
82
310
33,912
The Sharing Scientist retweeted

Jan 5
"Choosing problems is the primary determinant of what one accomplishes in science."
'Now What?' by Nobel Laureate John Hopfield should be required reading for aspiring scientists.
pni.princeton.edu/document/1…

14
130
724
59,116
The Sharing Scientist retweeted

Jan 5
This is an key example of where life-science PhD training has gone badly wrong.
From the very start, students are pushed into nonstop lab work, with almost no time spent on the history of the field, philosophy of science, or the logic of scientific inquiry - how knowledge is generated, validated, revised, and preserved.
They are trained not to be scholars, but operators. PhDs are trained to execute experiments rather than to understand why those experiments matter or where the ideas came from. That’s not an accident - it’s how you turn doctoral education into a cheap-labor pipeline rather than an intellectual one.
Biology pays the price. Without historical and theoretical grounding, failed ideas get recycled, entire areas are neglected, and foundational contributors are forgotten or dismissed. Progress becomes shallow and trend-driven instead of cumulative.
The path forward is restoring real scholarship. Fewer PhDs, deeper training, and explicit emphasis on history, theory, and reasoning would produce scientists who think as well as operate.

And a healthy dollop of actual analysis on the historical foundation of the field one is trained in, along with critical philosophy and classic logic. Knowing where you information comes from, along with the foundational assumptions, will lead to far fewer dead ends.
18
32
206
19,616
The Sharing Scientist retweeted

1 Dec 2025
The hidden danger of Biorender
(& the death of scientific illustration)
A short thread 🧵
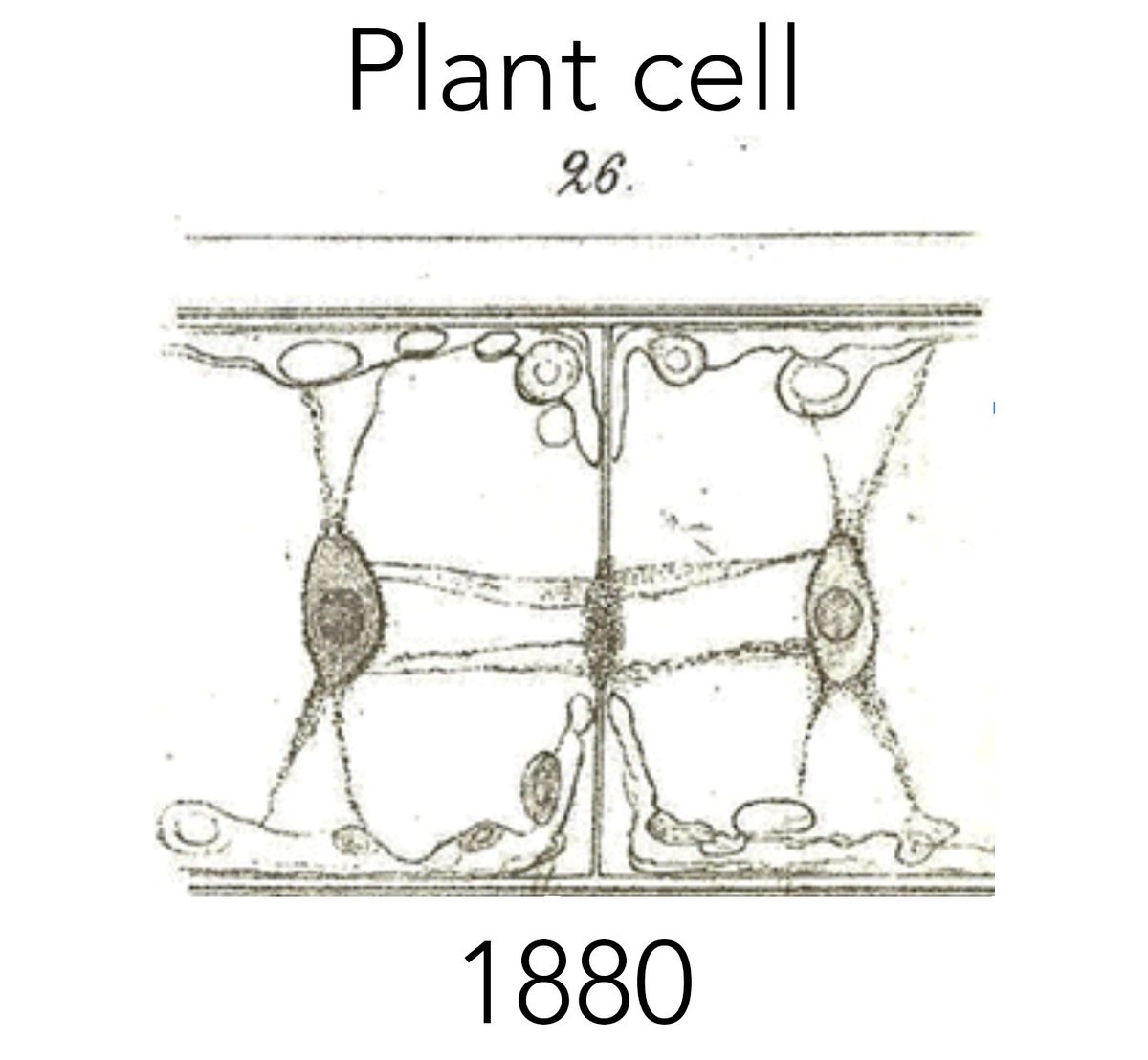
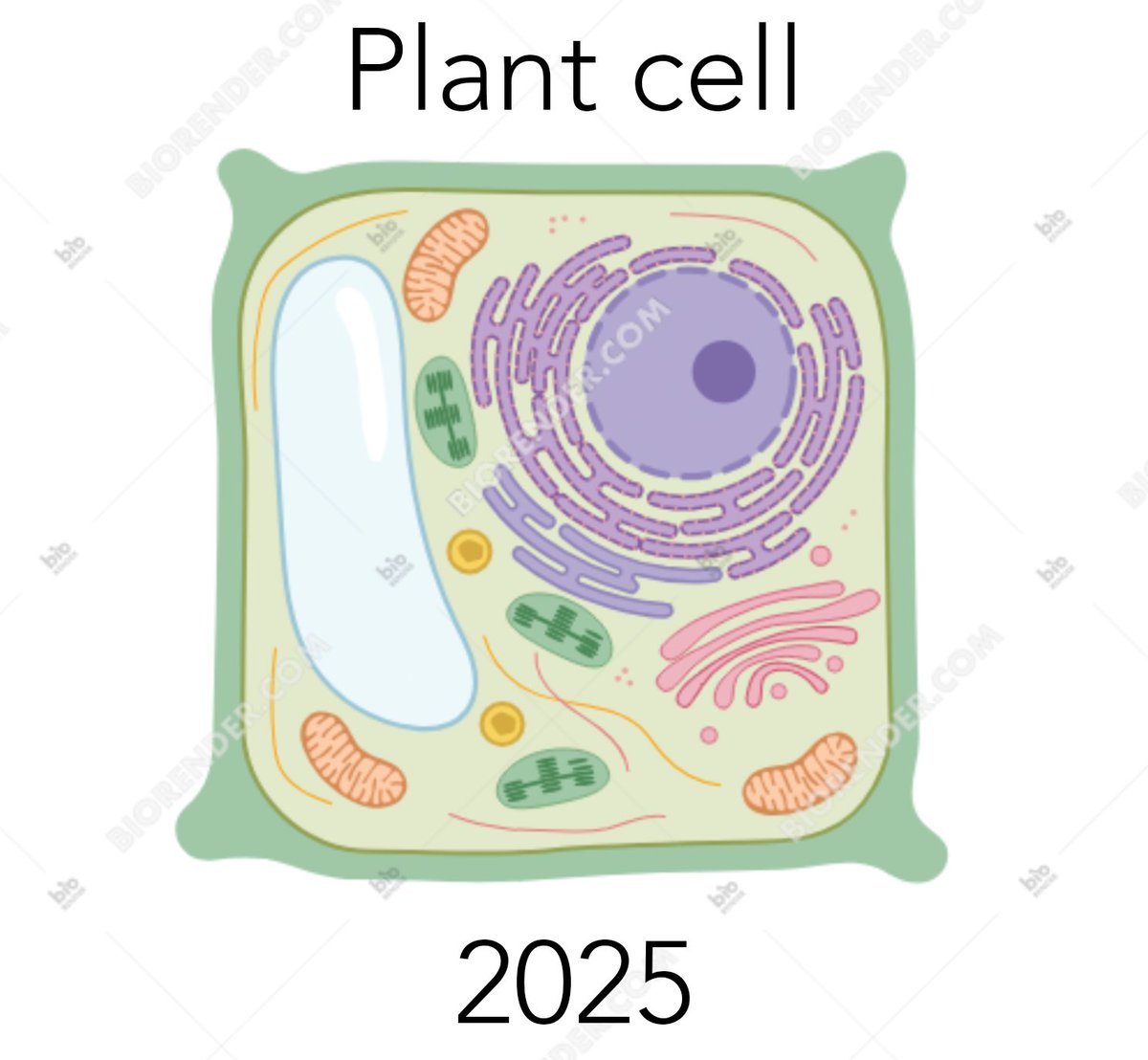
46
317
3,209
265,798
The Sharing Scientist retweeted

15 Nov 2025
Entropy and Human Aging
onlinelibrary.wiley.com/doi/…
2
22
108
15,770
The Sharing Scientist retweeted
11 Nov 2025
Would you expect that determining the sequences of all human genes will keep attention focussed on a few ?
The 8 most studied genes are:
TP53
TNF
EGFR
IL6
VEGFA
АРОЕ
TGFB1
MTHFR
1/3

11
29
184
21,681
The Sharing Scientist retweeted

2 Nov 2025
Take two cells and place them side by side. Both cells have the same genome. And yet, oddly enough, they behave in different ways. They divide at different times and their RNA levels are distinct.
Now let’s go one step further. Take those same two cells. But this time, imagine that they have not only the same genome, but completely identical molecules at identical concentrations. Will these two cells behave in the same way?
The answer is no.
This is because there are two types of "noise" inside of living cells; intrinsic and extrinsic. In the first example, the two cells act differently because of subtle differences in their gene levels. Not all genes are expressed at the same time or in the same amount, and this leads to slight differences. This is extrinsic noise, because it is “global to a single cell” but varies “from one cell to another.”
In the second example, which is so statistically unlikely as to be basically impossible, the two cells would still have different gene expression patterns “because of the random microscopic events that govern which reactions occur and in what order.” This is intrinsic noise or stochasticity; it is an inalienable part of biology.
I’m pulling these quotes from one of my all-time favorite papers, called “Stochastic Gene Expression in a Single Cell.” The first author is @ElowitzLab (of synthetic biology fame) and it was published in August 2022. It’s worth reading.
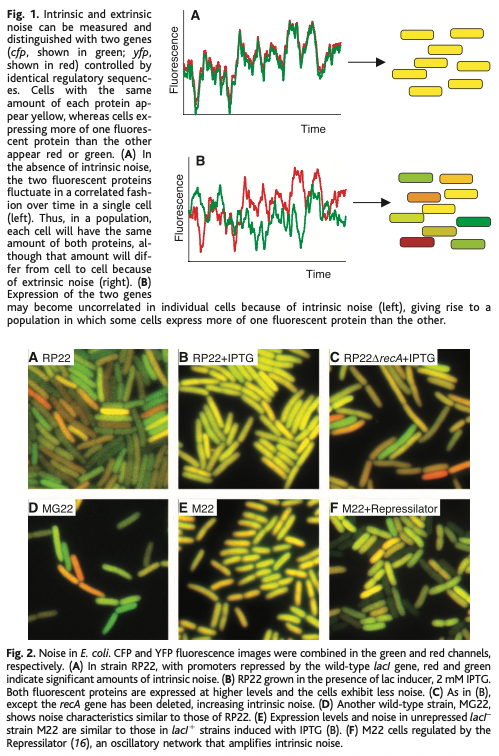
For this paper, Elowitz & co. designed a simple experiment to separate intrinsic and extrinsic noise in a cell. Their goal was measure each source of noise to figure out which one dominates in different scenarios, like exposure to IPTG or the addition of a plasmid. So here’s what they did:
First, they took E. coli cells and inserted two genes into the genome; one encoding a fluorescent cyan protein, and another encoding a fluorescent yellow protein. Each gene had the same promoter, and was placed equidistant from the genome’s origin of replication (but on opposite sides.)
Next, they grew these cells in LB broth and photographed them using a microscope with color filters. The brightness of each color, in each cell, was quantified.
If the variability between different E. coli cells stems from shared cellular conditions (like ribosome levels or extrinsic noise), then both colors in a single cell would fluctuate together. If the variability instead arises from random molecular events (intrinsic noise), then even within the same cell, the cyan and yellow levels would differ.
If you plot these changes out on a scatterplot, then you can literally decode which “signals” or “triggers” are dominated by intrinsic or extrinsic noise, and by how much.
This is a “beautiful experiment” because the experiment is so simple, yet it retrieves a huge amount of information. All they did was put two genes into an E. coli cell at symmetrical locations in the genome! And from that alone, they deconvoluted noise and its origins.

9
98
695
76,413
The Sharing Scientist retweeted

16 Oct 2025
Dysregulation of AGO2-miRNA dynamics underlies the AGO2-associated Lessel–Kreienkamp syndrome | Nucleic Acids Research | Oxford Academic academic.oup.com/nar/article…
1
1
616
The Sharing Scientist retweeted

14 Oct 2025
Colliding ribosomes are potent signals of cellular stress. But do cells use ‘programmed’ ribosome collisions to regulate gene expression? I’m excited to present a new story led by Frederick Rehfeld revealing that the answer is YES! Read on to find out how. biorxiv.org/content/10.1101/…
2
27
111
14,343
The Sharing Scientist retweeted

10 Oct 2025
Thrilled to share our work on transcription initiation and termination being spatially coordinated out today in Science! science.org/doi/10.1126/scie…
7
51
279
22,823
The Sharing Scientist retweeted

2 Oct 2025
Today, we introduce a nomenclature that can express discrete PTMs, proteoforms, nucleoforms, or situations where defined PTMs exist in an uncertain context and can describe how proteoforms are configured in functionally distinct complexes across biology. authors.elsevier.com/c/1lt5I…

ALT Today, we introduce a nomenclature that can express discrete PTMs, proteoforms, nucleoforms, or situations where defined PTMs exist in an uncertain context. Though specifically designed for the chromatin field, adaptions of the framework could be used to describe—and thus dissect—how proteoforms are configured in functionally distinct complexes across biology. Thank you to the many co-authors for your input and support. https://authors.elsevier.com/c/1lt5I3vVUPVb4c
4
42
197
13,048
The Sharing Scientist retweeted

1 Oct 2025
Our RAEFISH spatial transcriptomics technology is now published in Cell @CellCellPress! RAEFISH enables sequencing-free whole genome spatial transcriptomics at single molecule resolution. This work represents the first time that transcripts from more than 23,000 genes were directly probed and imaged in situ with any technology, and the first time numerous different gRNAs were directly probed and distinguished by imaging in a high-content CRISPR screen.
The challenge:
Recent breakthroughs in spatial transcriptomic technologies, from us and others, have greatly improved our ability to profile cell types, states, cellular interactions, and the underlying gene programs within the native tissue contexts. However, these technologies have limitations. Methods based on 2D-array-capture/tagging and ex situ sequencing offer genome-scale coverage, but lack the resolution needed to accurately study fine spatial organization. In contrast, image-based methods that rely on highly multiplexed fluorescence in situ hybridization or in situ sequencing provide single-molecule resolution and resolve fine spatial organization, but require pre-selecting a limited set of target genes (typically hundreds to a few thousand genes), which limits discovery and sometimes leads to only validations of prior knowledge due to the pre-selected targets being well studied in the context.
The solution:
RAEFISH, our lab's new flagship image-based spatial transcriptomics technology, simultaneously enables single-molecule spatial resolution and whole-genome level coverage of long and short, endogenous and engineered RNA species in cell cultures and intact tissues.
The results:
🔥 We performed RAEFISH targeting 23,312 human genes in cell cultures, and demonstrated hypothesis-free discovery of cell cycle associated genes and subcellular localization patterns of transcripts, including nearly the entire protein coding transcriptome and additional long noncoding RNAs.
🔥 We performed RAEFISH targeting 21,955 mouse genes in mouse liver, placenta, and lymph node tissues. Our analyses on immediately neighboring cells uncovered intriguing cell-cell interactions and previously unknown gene expression programs underlying the interactions, such as those between cholangiocytes and immune cells.
🔥 Finally, we further developed RAEFISH to directly read out guide RNAs (gRNAs), demonstrating Perturb-RAEFISH in an image-based high-content CRISPR screen. The capacity of Perturb-RAEFISH to directly read out gRNAs addresses a crucial limitation of previous techniques that read out a barcode/identifier sequence paired with each gRNA species, as the pairing can be shuffled due to RNA recombination intrinsic to lentivirus used in such screens, which limits screen sensitivity and accuracy.
In summary, RAEFISH provides the biomedical research community with a generalizable research tool, which will bring more spatial and mechanistic insights across health and disease.
This work was co-led by my postdocs Drs. @ChengYubao, Shengyuan Dang, and Yuan Zhang, and was supported by the @NIH, @genome_gov, @sennetresearch, and @psscra. I would like to thank our co-authors, funding agencies, editor, reviewers, and my whole lab @YaleGenetics @YaleCellBio @YaleCancer @YaleMed @Yale.
Link to paper:
cell.com/cell/fulltext/S0092…

17
119
418
46,118