
Researcher at Google Brain. I work on JAX (github.com/google/jax).
Joined July 2010
- Tweets 2,009
- Following 3,338
- Followers 13,668
- Likes 95,696
16 Photos and videos




Matthew Johnson retweeted

May 8
Just some personal thoughts now that the AI co-mathematician tech report is public...
First, I'm so excited to see the co-mathematician team's hard work out for the world to preview. 💪 🦾=🔥 The team has built a system for mathematicians, with mathematicians. The fact it's now top of the FrontierMath leaderboard is a cherry on top, not the goal. Vibes and utility >> benchmarks.
The system is currently being tested with a small number of professional mathematicians. It is not widely available, but I personally hope that, one day, we can get even more capable systems into the hands of all mathematicians.
It's been a privilege working with this team at Google DeepMind since January.
Props to @dhhzheng, @ADaviesAI, and @pushmeet for their leadership. Give them all a follow to not miss exciting upcoming work.
May 8

The future of Math is mathematicians and AI agents working together.
Very pleased to introduce @GoogleDeepMind's AI co-mathematician: a multi-agent system designed to actively collaborate with human experts on open-ended research mathematics.
Mathematicians testing the agent across areas as diverse as group theory, Hamiltonian systems, and algebraic combinatorics have reported impressive results.
In autonomous mode evaluation on the rigorous FrontierMath Tier 4 problems, AI co-mathematician scored an unprecedented 48% — a new high score among all AI systems evaluated.

8
26
243
43,485
Matthew Johnson retweeted

Apr 27
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below!
with @AlecRad and @status_effects 🧵
201
456
3,625
1,421,475
Matthew Johnson retweeted

Apr 27
New work with @AlecRad and @DavidDuvenaud:
Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text.
Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
178
396
3,153
1,181,069
Matthew Johnson retweeted

Feb 13
GPT-5.2 derived a novel result in theoretical physics, showing that a type of particle interaction many physicists expected would not occur can in fact arise under specific conditions.
There is great promise in the potential of AI to benefit people by accelerating science.


GPT-5.2 derived a new result in theoretical physics.
We’re releasing the result in a preprint with researchers from @the_IAS, @VanderbiltU, @Cambridge_Uni, and @Harvard. It shows that a gluon interaction many physicists expected would not occur can arise under specific conditions.
openai.com/index/new-result-…
201
221
2,353
408,707
Matthew Johnson retweeted

Feb 12
Very happy to be involved in the core training team. Really amazing to see JAX running on our ultra-large scale GPU clusters.
Since xAI was formed just 30 months ago, the small and talented team has made remarkable progress.
The future has never looked more exciting!
7
7
131
5,660
Matthew Johnson retweeted

Feb 5
I have to mention this, this opus is reasonably good at low level jax, sharding and pallas. I would call it shard sherrif.

Introducing Claude Opus 4.6. Our smartest model got an upgrade.
Opus 4.6 plans more carefully, sustains agentic tasks for longer, operates reliably in massive codebases, and catches its own mistakes.
It’s also our first Opus-class model with 1M token context in beta.
4
3
66
5,835
Matthew Johnson retweeted

6 Dec 2025
We frictionlessly trained on AMD GPUs and TPUs with a unified JAX framework. Our goodput for flagship runs went past 90%. @YashVanjani @mjcOhio @alokpathy @pcmonk painstakingly removed obstacles to maximize experimental velocity.
2
12
168
33,596
Matthew Johnson retweeted

20 Nov 2025
Nano Banana Pro: "Generate a diagram of a two-layer neural network in the style of Stephen Biesty"
25
63
739
266,721
Matthew Johnson retweeted

2 Nov 2025
Unbelievable: the famed Berkeley Math Circle is being forced to shut down due to a bureaucratic requirement where a guest lecturer giving an hour long lesson needs to be officially fingerprinted. How is fingerprinting even still a thing in the 21st century?
Chancellor Lyons @richlyons: can you see the absurdity of the situation and figure out a solution?
dailycal.org/news/campus/gen…
32
80
749
274,132
Matthew Johnson retweeted

30 Oct 2025
SGLang now has a pure Jax backend, and it runs natively on TPU!

SGLang now runs natively on TPU with a new pure Jax backend!
SGLang-Jax leverages SGLang's high-performance server architecture and uses Jax to compile the model's forward pass. By combining SGLang and Jax, it delivers fast, native TPU inference while maintaining support for advanced features like continuous batching, prefix caching, parallelism, speculative decoding, and highly optimized TPU kernels.
Learn more in the blog below👇

2
5
157
21,760
Matthew Johnson retweeted

29 Oct 2025
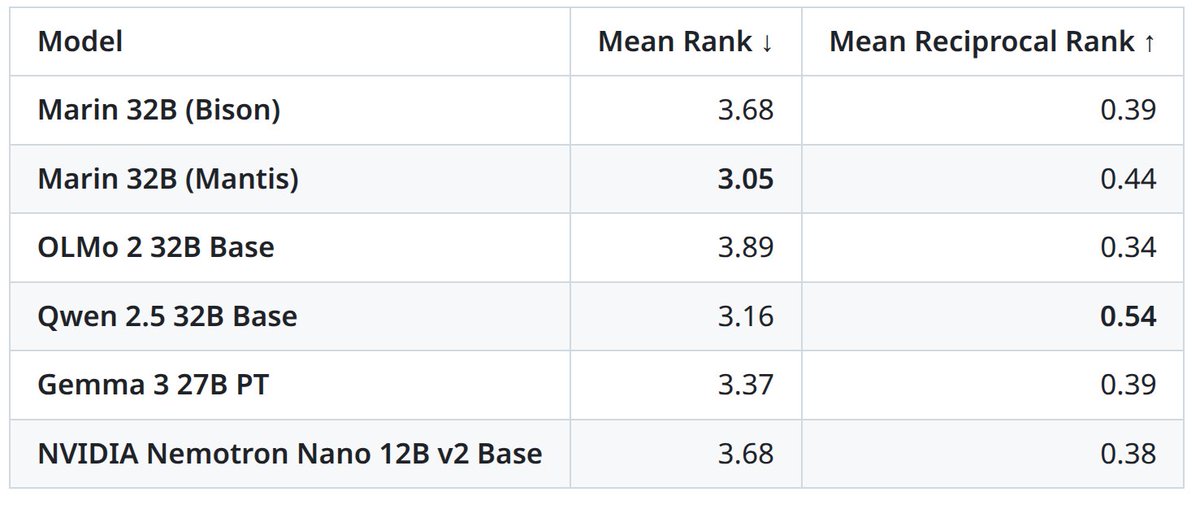
⛵Marin 32B Base (mantis) is done training! It is the best open-source base model (beating OLMo 2 32B Base) and it’s even close to the best comparably-sized open-weight base models, Gemma 3 27B PT and Qwen 2.5 32B Base. Ranking across 19 benchmarks:
20
88
597
127,362
Matthew Johnson retweeted

13 Oct 2025
TPU-style collective matmuls on GPU!
13 Oct 2025

Want to improve GPU compute/comms overlap? We just published a new short tutorial for you!
A few small changes to the Pallas:MGPU matmul kernel is all it takes to turn it into an all-gather collective matmul that overlaps NVLINK comms with local compute: docs.jax.dev/en/latest/palla…
8
26
4,671
Matthew Johnson retweeted

13 Oct 2025
Want to improve GPU compute/comms overlap? We just published a new short tutorial for you!
A few small changes to the Pallas:MGPU matmul kernel is all it takes to turn it into an all-gather collective matmul that overlaps NVLINK comms with local compute: docs.jax.dev/en/latest/palla…
8
46
302
33,277
Matthew Johnson retweeted
2 Oct 2025
Curious how to write SOTA performance Blackwell matmul kernels using MGPU? We just published a short step-by-step tutorial: docs.jax.dev/en/latest/palla…
At each step, we show exactly what (small) changes are necessary to refine the kernel and the final kernel is just under 150 lines.
4
67
416
54,997
Matthew Johnson retweeted
18 Sep 2025
Luckily we have alternatives :) github.com/jax-ml/jax/blob/7… Just 100 lines without leaving Python and SOTA performance
1
1
36
1,997
Matthew Johnson retweeted

18 Aug 2025
Kudos to Terry Tao for this:
newsletter.ofthebrave.org/p/…
22
168
1,022
88,137
Matthew Johnson retweeted

18 Aug 2025
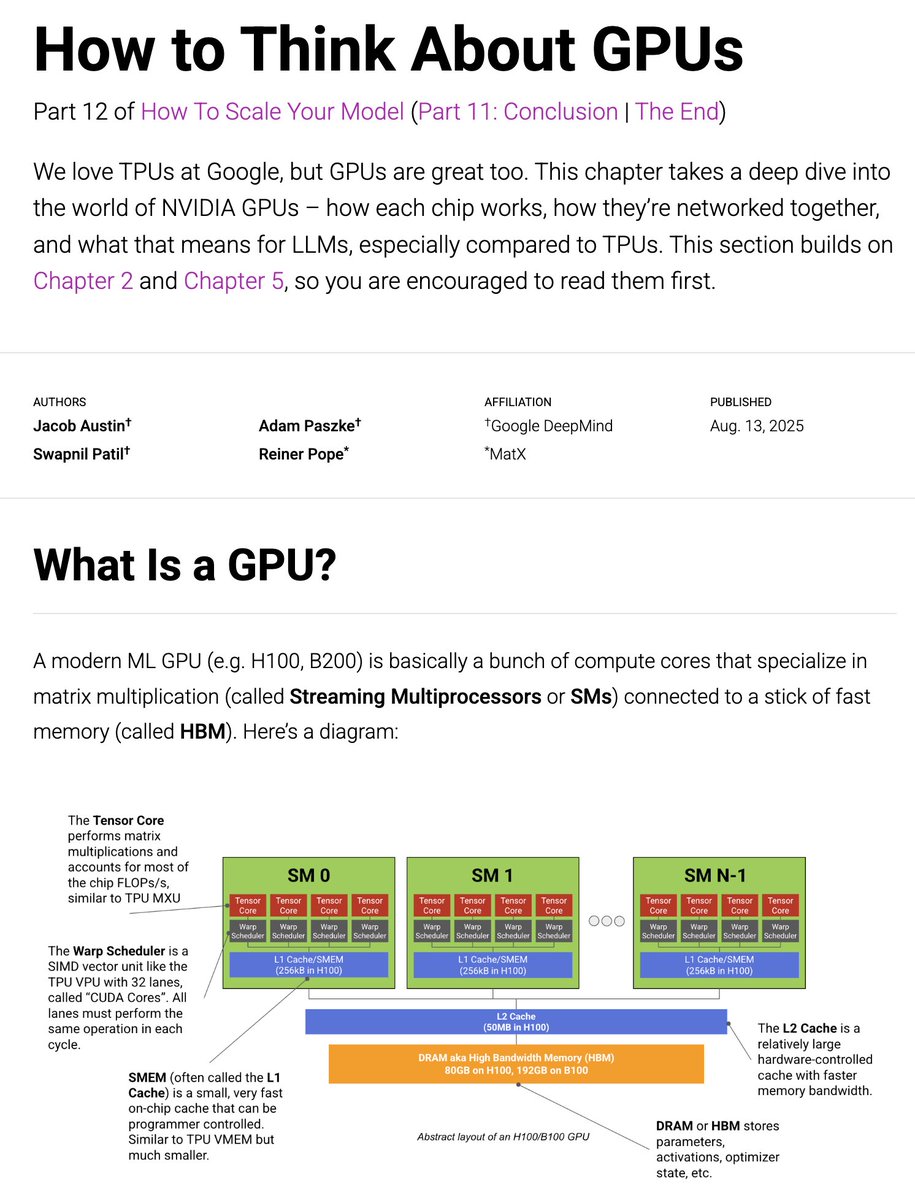
Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs? How are they networked? And how does this affect LLM training? 1/n
38
519
3,439
404,353
Matthew Johnson retweeted

26 Jun 2025
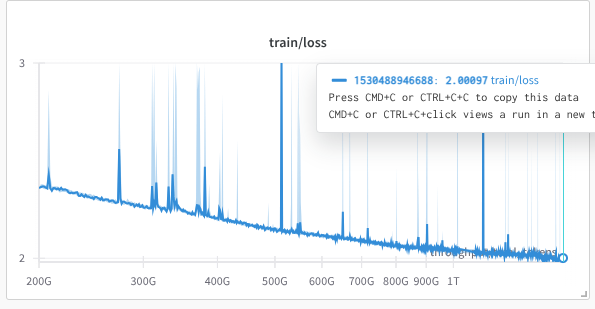
So about a month ago, Percy posted a version of this plot of our Marin 32B pretraining run. We got a lot of feedback, both public and private, that the spikes were bad. (This is a thread about how we fixed the spikes. Bear with me. )
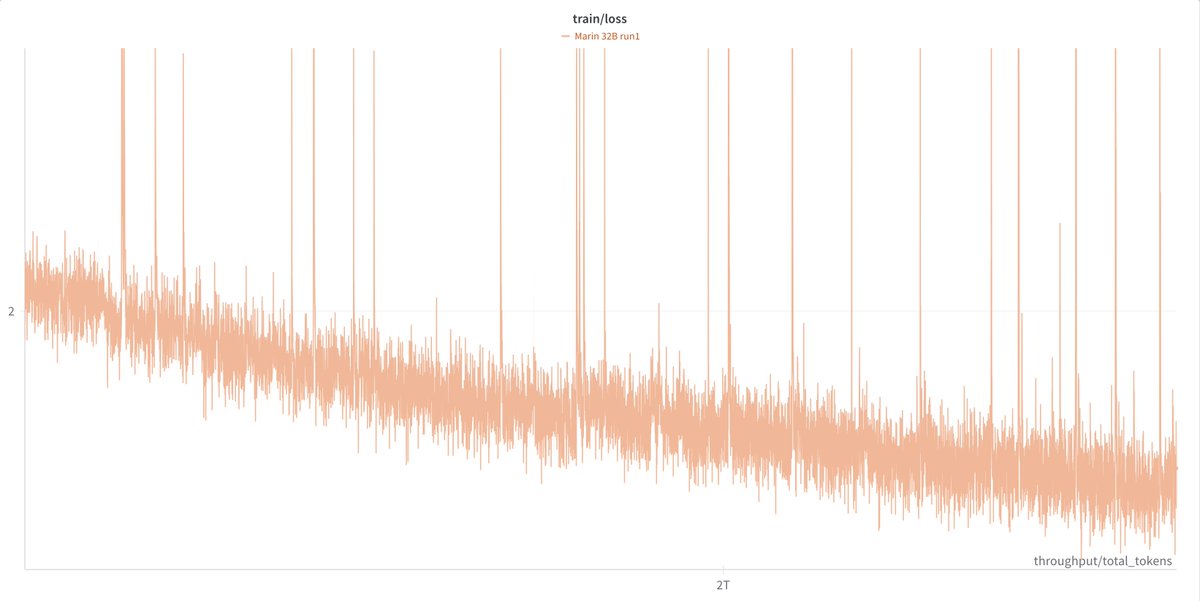
ALT a very spiky training loss curve for marin 32b

23
103
1,030
307,266
Matthew Johnson retweeted

23 May 2025
Strong recommend for this book and the JAX/TPU docs, even if you are using Torch / GPUs. Clean notation and mental model for some challenging ideas.
github.com/jax-ml/scaling-bo…
github.com/jax-ml/scaling-bo…
docs.jax.dev/en/latest/noteb…

9
157
1,152
77,628
Matthew Johnson retweeted
21 May 2025
For a rare look into how LLMs are really built, check out @dlwh's retrospective on how we trained the Marin 8B model from scratch (and outperformed Llama 3.1 8B base). It’s an honest account with all the revelations and mistakes we made along our journey. Papers are forced to hide the mess, but the real science happens in the process.
marin.readthedocs.io/en/late…
2
69
496
56,355