
768 Photos and videos











This thought by Tom Kirkwood probably makes a good &hopeful closing message #WhyWeAge2020.Should have tweeted it last.I think I tweeted a summary of what I found striking in all talks you can find them under the hastag #WhyWeAge2020, I have more pictures from the slides just ask!

#WhyWeAge2020 RT: Tom Kirkwood points out that we are not biological programmed for aging¬ programmed to die - it's just that our repair mechanisms don't work well enough to maintain our bodies indefinitely. A very hopeful message!
2
7
Wow that's quite a thing!
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
266
Simon L retweeted

Jun 9
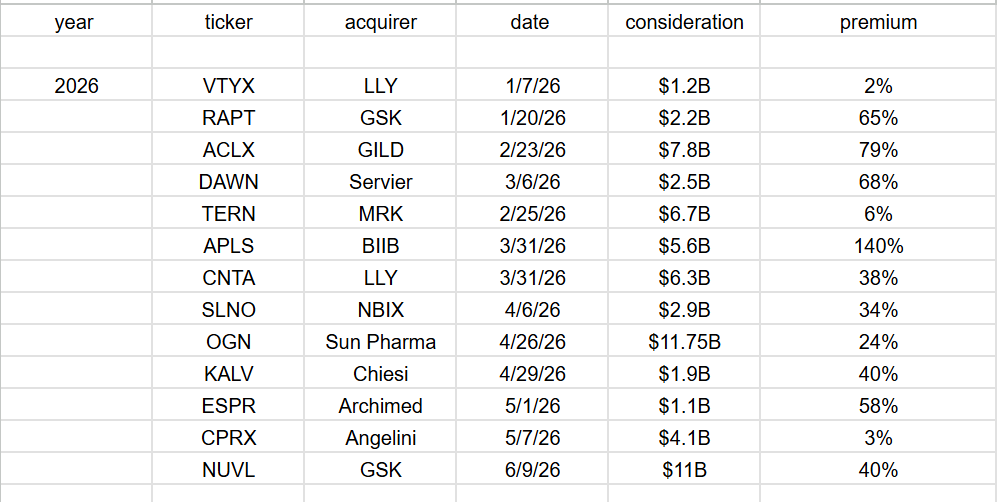
as much as I think GSK overpays here, ultimately not our problem. Lot of capital being recycled back.
And say whatever you want about 2026. M&A has NOT been an issue. Best 1H in a really long time.
3
3
37
5,338
Wild actions in European banks!

INTESA PREPARES JOINT BID WITH BPER FOR MONTE PASCHI: FT
Never a dull moment.
426
Simon L retweeted

Jun 6
This is an insane paper and I love it
arxiv.org/abs/2605.31514

157
1,305
11,216
620,273
Can't leave this thing (the XBI) alone for half a day looked much better when I left earlier ha. @pawcio2009 fishing this weekend?
1
187
Simon L retweeted

Jun 5
What are more recent equivalent books to MacLane’s “Mathematics Form And Function”? eg js Lawvere’s “Conceptual Mathematics” of a similar vein?
7
2
51
4,616
Simon L retweeted

Jun 4
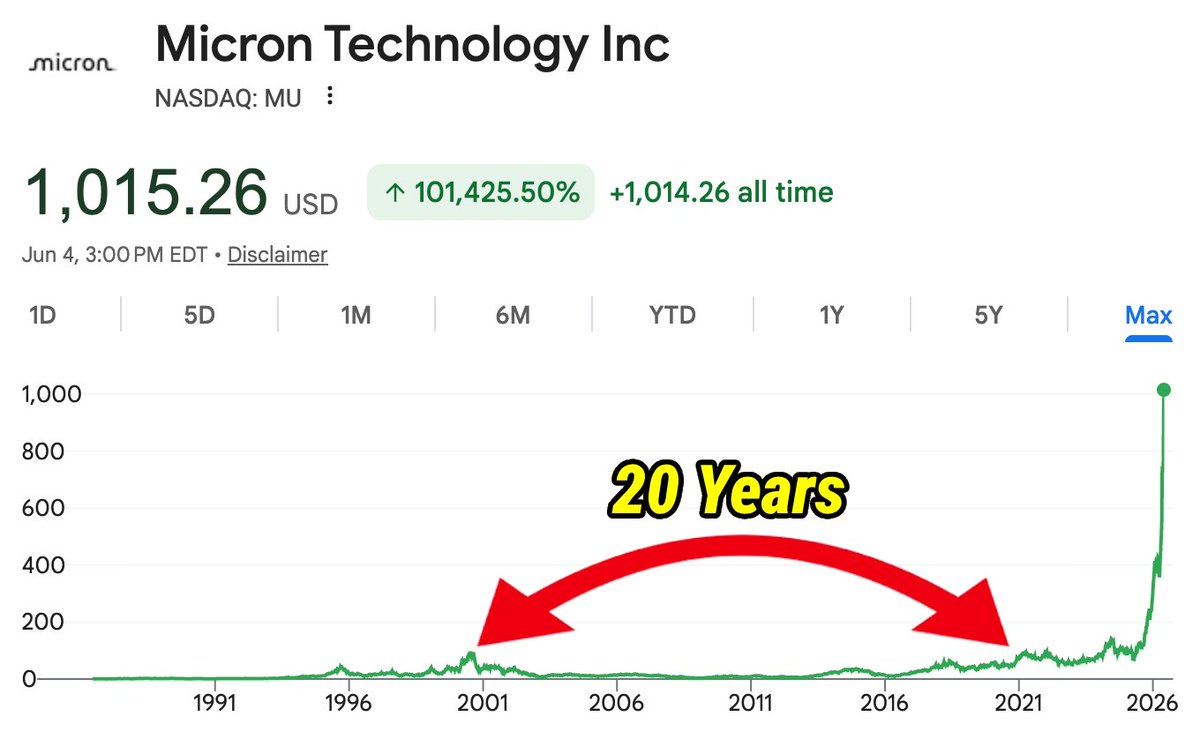
This is the funniest chart.
It took Micron around 20 years to recover from the Dot Com Bubble-
And then they climbed by 900% in the last year.
84
208
5,160
609,535
Simon L retweeted

Jun 4
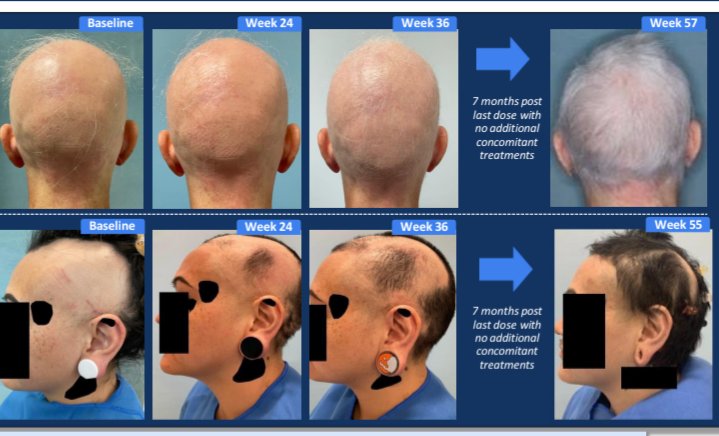
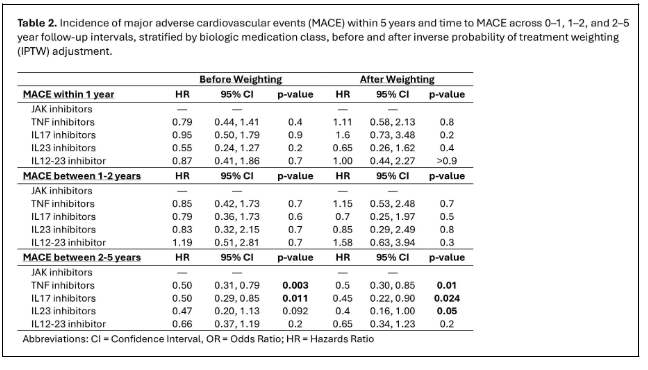
❤️ Do biologics differ in MACE risk in PsA?
YES - JAKi highest risk after 2.5yrs vs TNFi/IL-17i/IL-23i in a retrospective cohort of 22,246pts.
OP0181 #EULAR2026 @RheumNow
5
14
4,758
Simon L retweeted

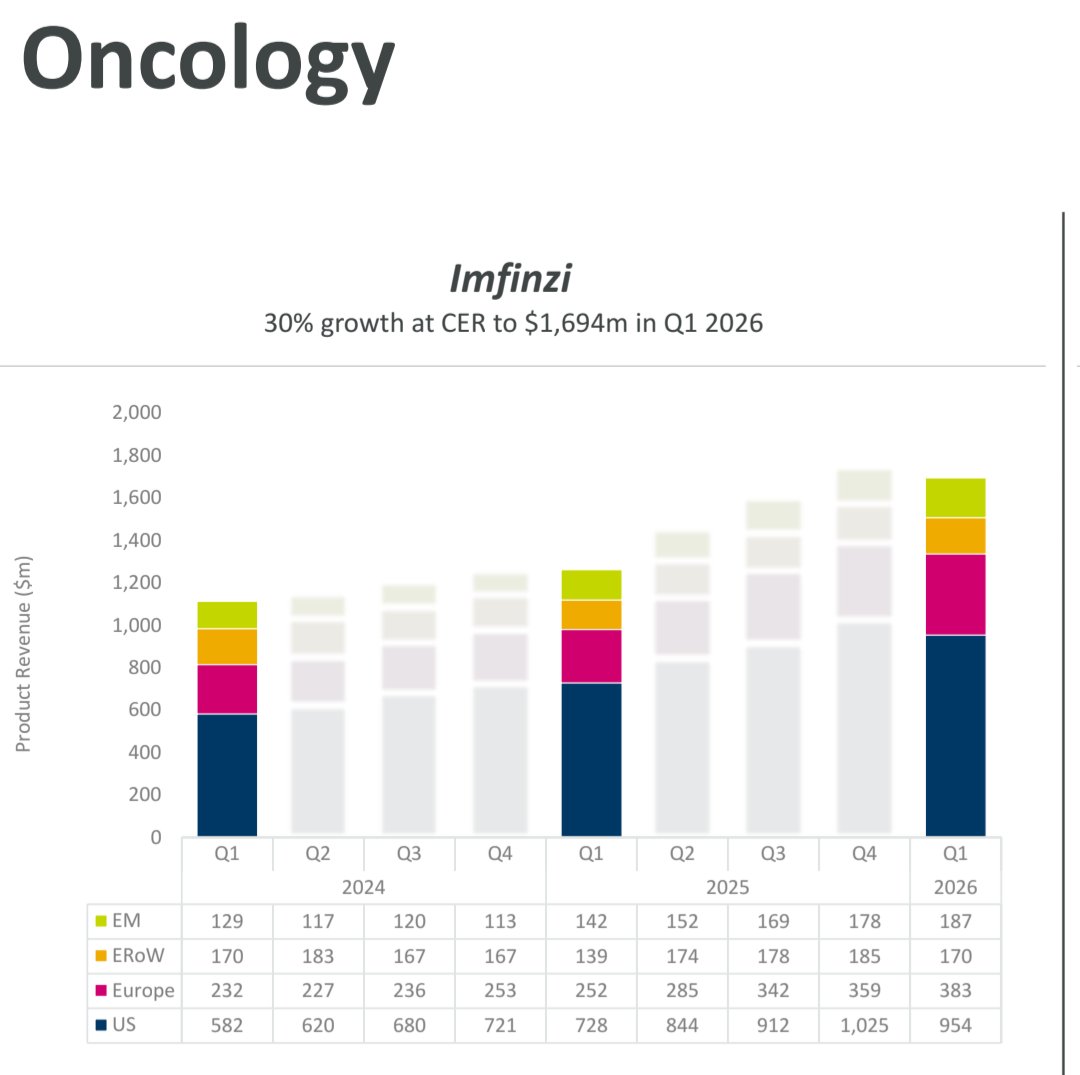
🚨 Stage III unresectable NSCLC has quietly become one of the biggest precision oncology success stories.
A decade ago:
➡️ Median OS ~2 years
Today:
✅ PACIFIC: mOS 47.5 months
✅ LAURA: mPFS 39.1 months in EGFR-mutant disease
✅ 5-year OS approaching 43%
The key lesson?
Every patient needs upfront molecular testing.
🧬 EGFR-mutant → Osimertinib
🛡️ EGFR wild-type → Durvalumab
The era of “all stage III patients get the same treatment” is over.
Full paper in comment below ⬇️
#OncoTwitter #MedTwitter #LungCancer @OncoAlert @myesmo @esmo_open @JCO_ASCO

2
41
128
9,379
Simon L retweeted

If the S&P closes up this week, it would be 10 up weeks in a row. The last time this happened was in 1985. So a real rarity.
2
3
57
7,876
Simon L retweeted

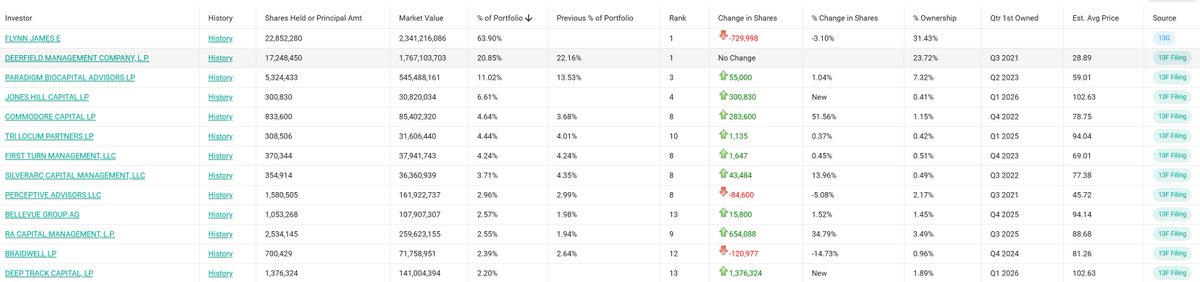
$MLYS Really is a strange name. Looked at their deal (buying back ~7% royalty, maybe a bit more, it´s tiered 5-10%) for 200m upfront 100m in m/s (lets call it 225m NPV).
One hand, they buy like 14-20% (roughly?) of the economics of the drug (assuming a spending-heavy sales force to compete against AZN) for a ~6.9% dilution 75m in debt which is pretty damn great if you´re a bull.
OTOH Tanabe sells its royalty for an implied "drug value" of ~1.1-1.6B (225/14-20%) against today´s market cap of 2.2B / EV 1.7B.
All of that against AZN expectations they´ll be doing 5-10B with Baxfendy and MLYS possibly taking 15-30% of market?
If they manage to sell the Co for a decent price, this will have been a very strong deal.
8
9
41
8,427
Simon L retweeted

Horror! - Doppelknall in der deutschen Pharmabranche. Lilly halbiert Milliardenprojekt in Deutschland. Die Investitionskrise erreicht nun auch die Pharmabranche.
Wenige Stunden zuvor hatte bereits Boehringer Ingelheim öffentlich bekannt gegeben, 900 Millionen Euro nicht in Deutschland zu investieren. Dir Ursache läge in Berlin.
#Pharma #Investitionen #EliLilly #Industrie
Standort: Der US Pharmakonzern Eli Lilly plante ursprünglich Investitionen von 2,5 Milliarden US Dollar in Alzey. Am 3. Juni 2026 teilte das Unternehmen mit, dass der noch ausstehende Projektumfang um 50 Prozent reduziert werden soll.
Ursachen: Konzernchef Dave Ricks begründete die Entscheidung mit den gesundheitspolitischen Rahmenbedingungen in Deutschland. Im Handelsblatt erklärte er, Deutschland werde bei der Unterstützung der Branche auf den letzten Platz der europäischen Märkte zurückfallen.
Die Entscheidung ist ein weiteres Signal dafür, dass internationale Konzerne ihre Investitionen in Deutschland zunehmend kritisch bewerten.
Vielen Dank für den wichtigen Hinweis!
Quelle: boerse.de / dpa AFX
boerse.de/nachrichten/Eli-Li…
41
274
943
45,589
Because of the Drexler Smalley debate? And because Smalley kinda "won" even though all the 90's kids how there is a secret way!
Jun 2

Why was nanotechnology such a big deal in the 2000s but it's totally forgotten now? Why is this?

1
2
968
Simon L retweeted

Main reasons why LLMs are bad at multi-layered abstraction-heavy domains like Langlands program:
> LLMs can come up with 1-2 tricks, they can't theory build in any significant way, and this kind of domain usually requires new methods/settings to begin with.
> Combinatorics and similar domains are definition-light, which makes it fully about the tricks. Arguments are usually short. Definition-heavy domains require juggling many layers of abstract concepts, and going from global (macro level of where we are in the proof, e.g. we want to prove an equivalence of categories) to local computations (e.g. computing cohomology groups of some ad hoc defined schemes) many times over, back and forth. This is a bit like Go in terms of making local plays that are useful globally, but here the board is basically infinite.
I've been thinking about how to overcome this with auto-research methods and it looks genuinely hard. You could solve it sometimes by throwing way more compute (context, Monte Carlo brute forcing attempts, AVO-style evolution, etc, etc), but this is definitely not the right solution. We need some new understanding here of what local-global, multi-layer problems involve.

There are math worlds inaccessible to even the best internal AI models.

10
30
159
20,831