
Joined March 2019
- Tweets 336
- Following 206
- Followers 10,149
- Likes 215
63 Photos and videos











Song Han retweeted

Jun 10
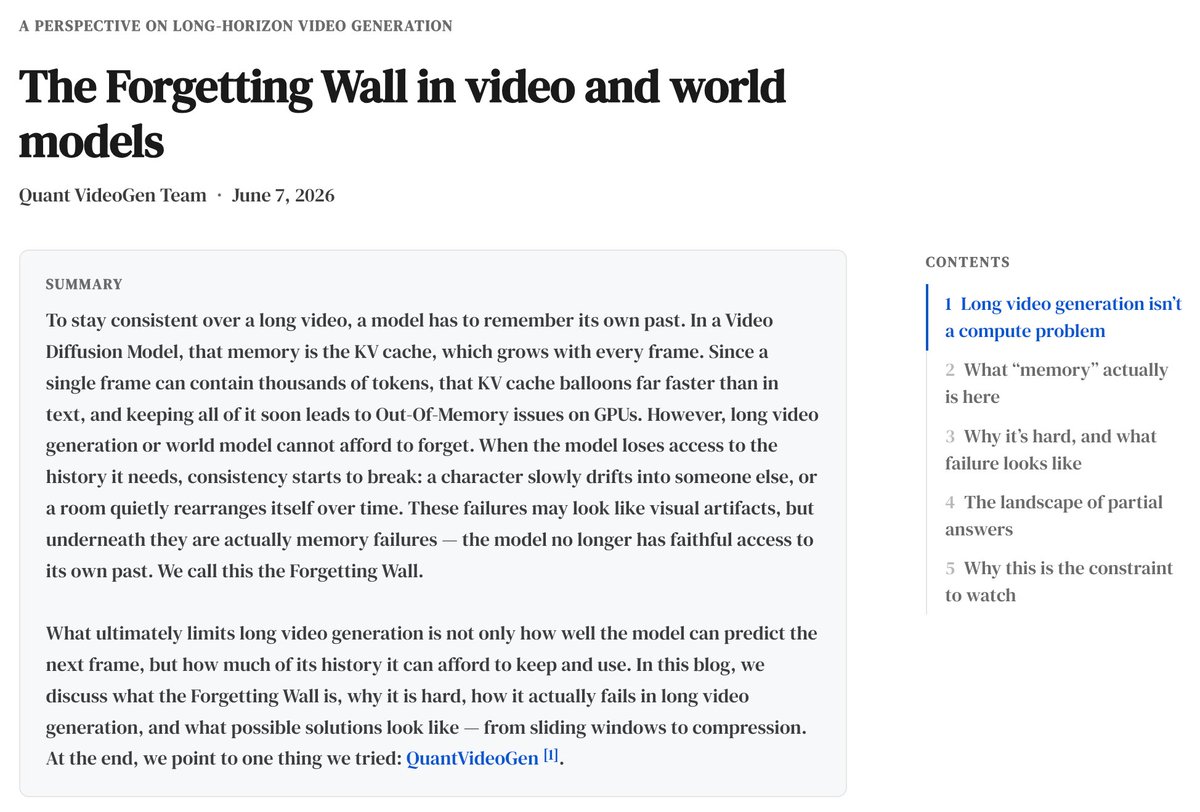
New blog post: The Forgetting Wall in Video and World Models
Long-horizon video generation is not just limited by compute. It is limited by how much of its own past the model can afford to remember.
I wrote about why long videos drift, why KV cache becomes the memory bottleneck, and why compression is a key direction for future video/world models.
haochengxi.github.io/posts/f…
7
27
162
128,003
Song Han retweeted

Jun 8
Excited to share our new blog: Scaling Video Training with Parallelism
research.nvidia.com/labs/eai…
We discuss how parallelism helps scale long-video training systems, for both understanding and generation.
15
156
11,965

Jun 8
the causal version of SANA world model is released, enabling close to real-time inference on a single H100:
Jun 8

🚀 Causal realtime streaming SANA-WM open-sourced!
Thanks to @reactorworld for serving the model — try demo: sana-wm.reactor.inc/
~0.93x realtime on single H100, watch 60s 720p live 6-DoF camera control.
Code: nvlabs.github.io/Sana/docs/s…
1
11
2,596
Jun 4
ForeAct: Steering Your VLA with Efficient Visual Foresight Planning

We‘ll be presenting ForeAct (🌟Highlight) at CVPR 2026:
📍 Poster: Sunday, 3:30PM, ExHall A #95
📍 NVIDIA Tech Talk: Friday, 12:40PM, Booth #211 @NVIDIAAI
Feel free to stop by and chat! Also find our coffee making demo empowered by ForeAct! (youtube.com/watch?v=kBKJxWUV…)
I’ll be at #CVPR2026 from Jun 4-7. Open to chat about VLA, world models and efficient visual generation!
1
19
3,522
Song Han retweeted

Jun 3
FlashLib update: we now support ANN search with IVF-Flat — up to 6.5× faster than cuVS on real-world vector workloads (SIFT-1M) while matching recall.
LEANN now supports FlashLib as a backend: 26× faster build, 29× faster single-query, and 298× faster batch search. Huge thanks to @YichuanM for the help!
We’re also opening Discord / Slack channels — join us to suggest new operators you want to see, and hardware backends you want FlashLib to support next!
Slack: join.slack.com/t/flashml/sha…
Discord: discord.gg/ce5Xa5pf
6
16
103
377,621
Song Han retweeted
Jun 1
We released a blog on "Why Video Gen Is an Infra Problem".
research.nvidia.com/labs/eai…
We discuss why long video generation requires full-stack co-design across models, memory, KV cache, VAE decoding, scheduling, and deployment infrastructure, with LongLive 2.0 (github.com/NVlabs/LongLive) as a case study.
8
9
181
11,936

May 31
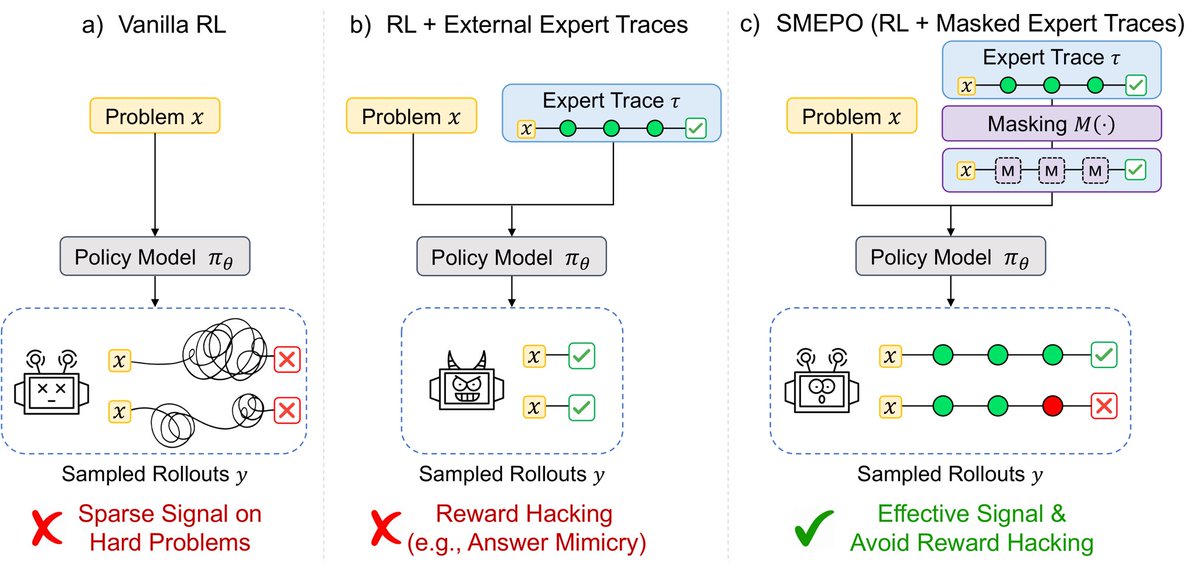
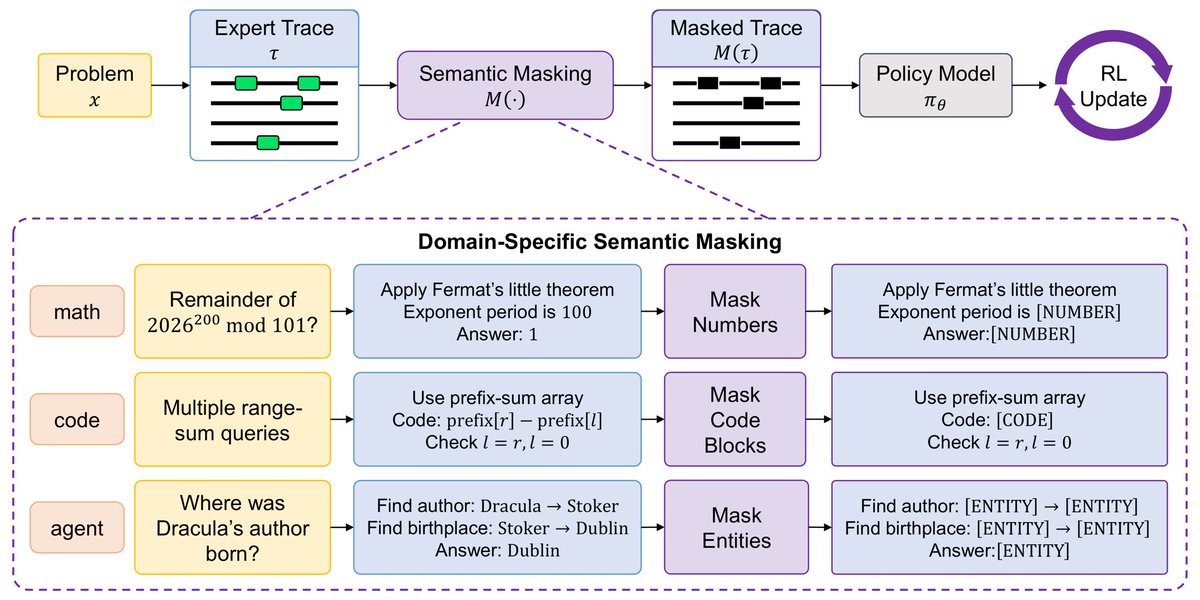
Hide to Guide: Learning via Semantic Masking
May 31

Expert traces can guide RLVR, but full traces may leak key values, executable code, or answer entities — creating an unintended reward-hacking channel.
We propose SMEPO: Semantic Masked Expert Policy Optimization.
Paper: arxiv.org/abs/2605.25198
Code: github.com/mit-han-lab/SMEPO
1
38
8,452
Song Han retweeted
May 27
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: flashml-org.github.io/
Code: github.com/FlashML-org/flash…
47
236
1,608
865,866
Song Han retweeted
May 25
🚀 LongLive 2.0 just got faster!
Since last week’s release, we further optimized the NVFP4 inference path and improved the overall throughput by 18.6%.
🔥Now, generating a 64s video takes only 30.6s end-to-end, including VAE decoding.
⚡⚡That’s over 2× real-time generation.
🛠️ What changed under the hood?
• Fused Triton RoPE / adaLN kernels
• Reduced KV-cache synchronization overhead
• In-place quantized KV-cache updates
• Faster FP4 KV dequantization
• Pinned VAE transfers
• Safer LoRA-before-quantization setup
🎬 LongLive 2.0 is our open-source 4-bit long-video generation infra for both training and inference.
🚀 We are continuing to push long-video generation toward faster, lighter, and more practical deployment.
🔗 Code: github.com/NVlabs/LongLive
#LongVideoGeneration #VideoGeneration #Realtime #AIInfra #EfficientAI #FP4 #Parallel #NVIDIA

2
9
43
3,013
May 23
Explore our kernel design agents:
1
3
37
4,819
Long video generation is a systems problem.
Introducing LongLive-2.0 from NVIDIA Research: an end-to-end NVFP4 training and inference system for long video generation.
Low-precision deployment often relies on post-training quantization, creating a gap between how models are trained and how they run.
LongLive-2.0 aligns NVFP4-aware training, distillation, and W4A4 inference, maintaining strong benchmark quality while improving speed and memory efficiency.
28
70
702
60,291
Song Han retweeted

May 19
We’re releasing Nemotron-Labs-Diffusion - the first Tri-mode LM family (3B/8B/14B) that switches between 1⃣Autoregressive, 2⃣Diffusion, and 3⃣Self-Speculation decoding by simply changing the attention pattern/mask.
One model Three decoding modes. No extra draft models. No architecture changes. Just significantly better efficiency across different concurrency levels.
Up to 4× higher real throughput for a single user.
🤗 HF Collection: huggingface.co/collections/n…, open license
🛜 Project page: research.nvidia.com/publicat…
📰 Tech report: bit.ly/Nemotron-Labs-Diffusi…
Details below 👇

15
88
587
50,953
May 20
LongLive 2.0, nvfp4 infra for long video generation:
May 19

🚀 Excited to release LongLive 2.0!
🎬 An end-to-end infrastructure for long video generation, with FP4 and parallelism at the core of both training and inference.
⚡45.7 FPS generation speed on 5B model⚡
✨ LongLive 2.0 supports real-video training, few-step distillation, multi-shot training/inference, sequence-parallel acceleration, NVFP4 KV cache, and async VAE decoding deployment.
🧩 To our knowledge, this is the first open-source 4-bit long video generation infra that covers both training and inference.
🙌 Welcome to check it out, try it, and share feedback!
🔗 Code: github.com/NVlabs/LongLive
📰 Paper: huggingface.co/papers/2605.1…
🎥 Demo: nvlabs.github.io/LongLive/Lo…
#LongVideoGeneration #VideoGeneration #Realtime #AIInfra #EfficientAI #FP4 #Parallel #NVIDIA
2
17
2,881
May 20
SANA world model, small and fast:

One image text camera trajectory = controllable worlds. All on a single GPU.
Our research team just released SANA-WM, a 2.6B open source world model natively trained for 60-second video generation with precise camera control.
20
2,645
Song Han retweeted

May 18
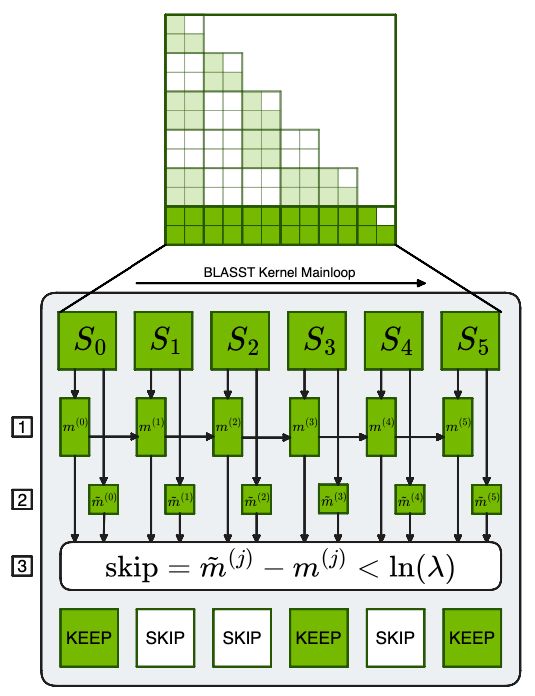
🚀 BLASST just won Best Paper at #MLSys26!
In this paper, we introduce a simple, training-free dynamic sparse attention mechanism that uses a single scalar threshold on online softmax statistics to skip negligible attention blocks.
Unfortunately I won’t be there in person, but please say hi to my awesome coauthors! 🙌
Paper: arxiv.org/abs/2512.12087

May 17

Sparse attention mechanisms are finally moving beyond academic benchmarks into production systems, including DeepSeek Sparse Attention, and recently @NousResearch 's Lighthouse Attention.
BLASST by NVIDIA, from paper Dynamic Blocked Attention Sparsity via Softmax Thresholding, attempts to sparsify attention in a different way, leveraging a similar rescale factor threshold idea from Flash Attention 4.
We expect to see more interesting sparse attention techniques in the future.
arxiv.org/abs/2512.12087 (2/4)
20
52
361
42,505
Song Han retweeted

May 17
Glad to be featured by SemiAnalysis. Our work BLASST was also selected as MLSys 2026 Best Paper: mlsys.org/virtual/2026/poste…
May 17
Sparse attention mechanisms are finally moving beyond academic benchmarks into production systems, including DeepSeek Sparse Attention, and recently @NousResearch 's Lighthouse Attention.
BLASST by NVIDIA, from paper Dynamic Blocked Attention Sparsity via Softmax Thresholding, attempts to sparsify attention in a different way, leveraging a similar rescale factor threshold idea from Flash Attention 4.
We expect to see more interesting sparse attention techniques in the future.
arxiv.org/abs/2512.12087 (2/4)
5
31
5,552
May 15
Explore SANA World Model, using hybrid linear attention, efficient and fast!

🤩Excited to share SANA-WM: a 2.6B open-source world model for minute-scale 720p video generation.
Given one image text a 6-DoF camera trajectory, it synthesizes action-controllable 60s worlds on a single GPU.
Project: nvlabs.github.io/Sana/WM/
Paper: huggingface.co/papers/2605.1…
2
10
95
16,423
May 14
Explore AnyFlow for any step distillation, accelerating video diffusion model inference:

🚀 We are excited to announce the release of AnyFlow, the first any-step video diffusion on-policy distillation (OPD) framework. By leveraging Flow Map distillation, AnyFlow significantly enhances model inference efficiency by reducing sample steps. (Code, models, and demos are now open-source!)
Key Highlights:
⚡ Any-Step Generation: Unlike traditional distilled models tied to fixed step budgets, AnyFlow enables a single model to adapt to arbitrary inference budgets. It achieves high-quality few-step generation while providing stable improvements as more sampling steps are added.
🔀 Multiple Architectures: AnyFlow supports any-step distillation for both causal and bidirectional video diffusion models.
🎬 Multiple Tasks: AnyFlow supports Text-to-Video, Image-to-Video, and Video-to-Video generation within one causal video diffusion model.
📈 Scalable Performance: AnyFlow is validated from 1.3B up to 14B parameters.
📄 Paper: huggingface.co/papers/2605.1…
💻 Code: github.com/NVlabs/AnyFlow
🎨 Pre-trained Models: huggingface.co/collections/n…
🎬 Demo: nvlabs.github.io/AnyFlow/dem…
2
19
5,670