
Nerds taming the green dragon with SCALE, our framework for compiling CUDA codebases for AMD GPUs, with support for more accelerated platforms coming soon.
Joined September 2025
- Tweets 317
- Following 54
- Followers 280
- Likes 175
64 Photos and videos














Jun 12
A lot of people assume that going cross-vendor means settling for lowest-common-denominator performance.
@SpectralMichael breaks down why that's wrong in his latest blog post:

Generality is free when your abstraction sits at the right level. Dive into Part 4 of my series, "Why hardware-agnostic isn't the same as lowest-common-denominator": scale-lang.com/posts/2026-06…
1
20
Jun 10
🇸🇬 Spectral is at @superai_conf 2026 — Marina Bay Sands, Singapore, 10–11 June.
Singapore is one of the fastest-moving AI hubs in the world, and the conversations here about compute capacity and GPU vendor optionality are exactly the ones we care about.
If you're around, let's talk.
1
22
Jun 9
Spectral Compute is at ISC High Performance 2026 — booth C50, Hamburg, June 22–26.
📅 Book a slot with us: scale-lang.com/s/booth-c50-a…
1
2
30
Jun 9
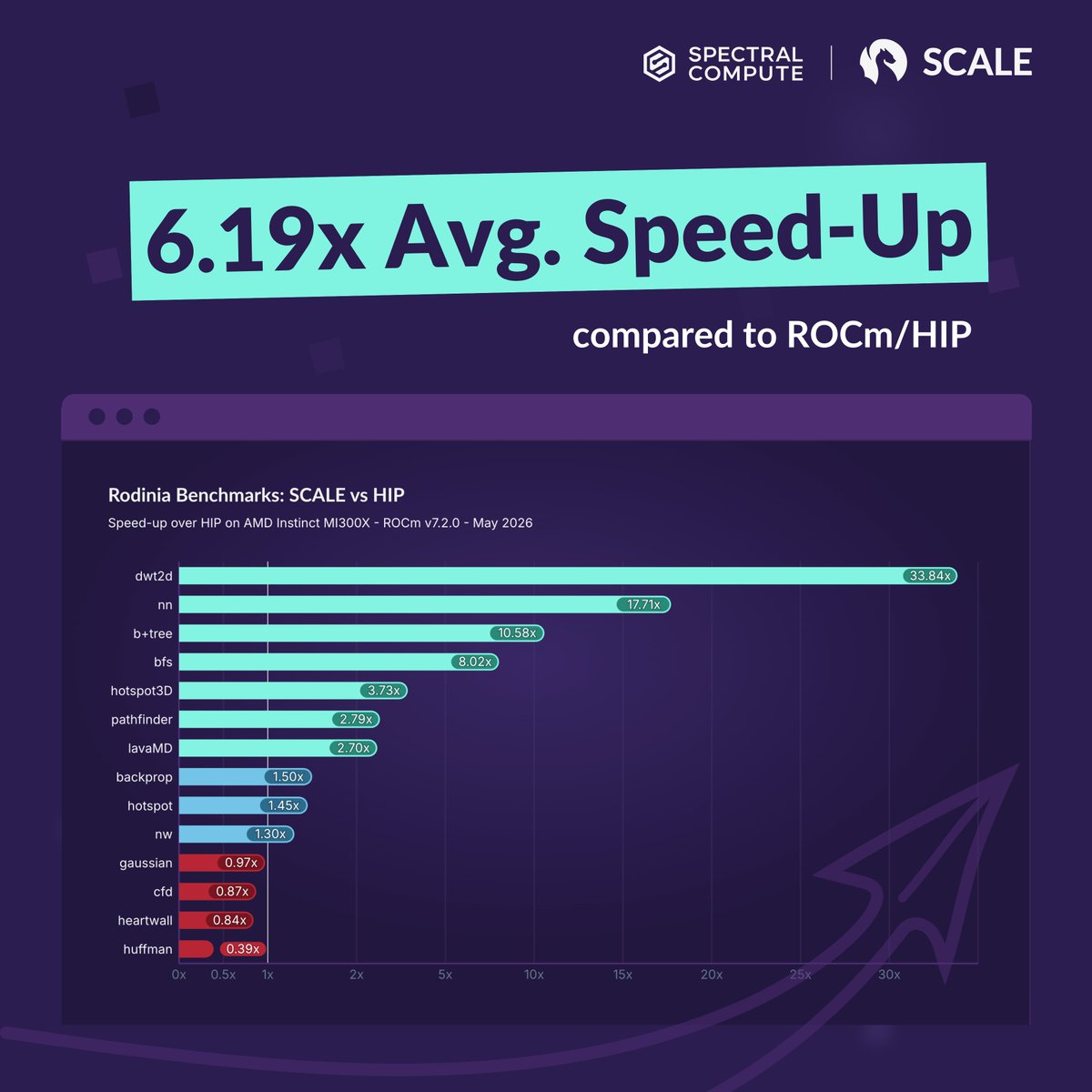
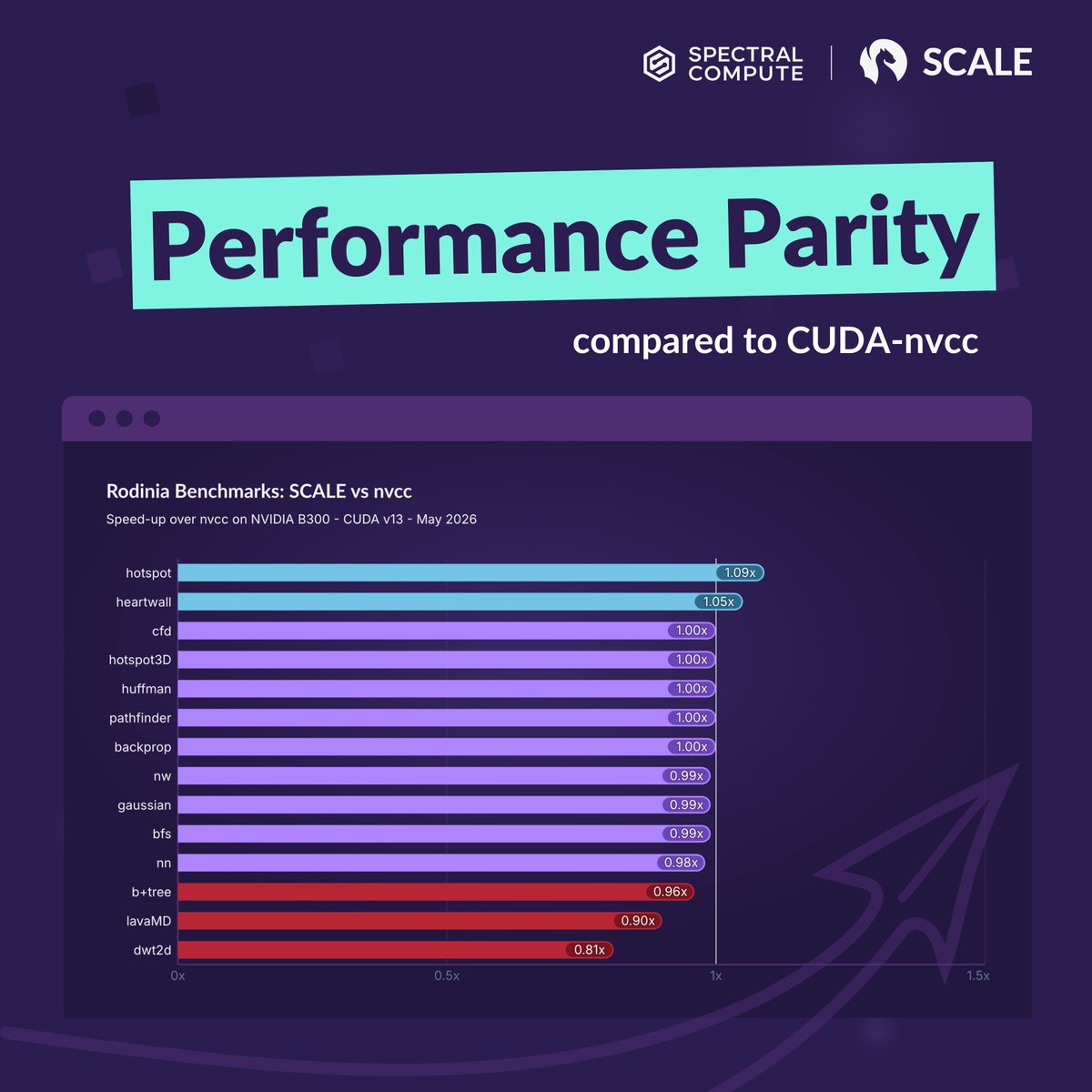
SCALE compiles unmodified CUDA code natively for AMD and NVIDIA. The numbers:
⚡ Up to 33.8× faster than HIP on AMD MI300X
⚡ Up to 9% faster than nvcc on NVIDIA B300
One codebase. Any GPU. No rewrites.
See you in Hamburg 👋
1
49
Jun 5
That's a wrap at @computex_taipei!
Great few days talking about the future of heterogeneous accelerated computing.
1
1
2
41
Jun 5
Attendees were especially interested in the performance boost and better-than-native developer experience they can unlock with scale-lang.com - while expanding their compute capacity without being locked to a single vendor.
1
1
24
Jun 5
COMPUTEX always delivers on serendipity: the unplanned hallway chats turn into the most valuable ones. Heading home with a full notebook and a longer list of people to follow up with.
Until next time. 👋
1
24
Jun 3
Cross-architecture from a single codebase is exactly why we built SCALE. Thrilled to see @AtlasInference getting this running! More performance optimizations for both @AMD and @nvidia are on the way.
scale-lang.com
Jun 2

Atlas Inference is running Qwen3.6-27B on AMD Strix Halo 🥳
Using @SpectralCom's SCALE ROCm backend, our CUDA kernels compile and run on RDNA⚙️
Cross-architecture inference from ONE codebase 🗣️
Thank you @AIatAMD for the gift 🙏
POC ✅ excited to keep tuning performance⚡️
1
1
5
270
Jun 3
𝗦𝗽𝗲𝗰𝘁𝗿𝗮𝗹 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗶𝘀 𝗻𝗼𝘄 𝗽𝗮𝗿𝘁 𝗼𝗳 𝘁𝗵𝗲 𝗡𝗩𝗜𝗗𝗜𝗔 𝗜𝗻𝗰𝗲𝗽𝘁𝗶𝗼𝗻 𝗽𝗿𝗼𝗴𝗿𝗮𝗺. 🟩
Inception is @nvidia's program for AI startups - a membership that gives access to technical resources, preferred pricing on NVIDIA hardware and software, and exposure to a global network of investors and partners.
CUDA is the de-facto standard for AI developers, and we’re honored to play our part in growing the ecosystem.
1
3
7
109
Jun 1
New benchmark numbers are in, and SCALE keeps pulling ahead.
1
1
42
Jun 1
And on NVIDIA's B300 (CUDA 13), SCALE lands within a whisker of nvcc on its home turf: 𝗼𝗻 𝗽𝗮𝗿 𝗼𝗻 𝗮𝘃𝗲𝗿𝗮𝗴𝗲, 𝘂𝗽 𝘁𝗼 𝟵% 𝗳𝗮𝘀𝘁𝗲𝗿 on individual workloads.
That's native CUDA tooling, matched and occasionally beaten, by a third-party compiler.
1
1
30
Jun 1
Hardware freedom shouldn't cost you performance. Increasingly, it buys you some.
Benchmarks here: tinyurl.com/2j8vftsr
1
17
Spectral Compute retweeted

Everyone says CUDA can't target TPUs.
What they mean is nobody has written the compiler that raises CUDA code to something a systolic backend can consume.
Those are very different sentences.
Full post — Part 3 of why @SpectralCom exists: tinyurl.com/mtnxcjsw
2
4
502
May 26
@ChrisKitching17, our CTO and co-founder of Spectral Compute, recently presented at the 𝗡𝗛𝗥 𝗣𝗲𝗿𝗳𝗟𝗮𝗯 𝗦𝗲𝗺𝗶𝗻𝗮𝗿 hosted by NHR@FAU. The recording is now online: youtu.be/uSLD40GX5nM
1
1
3
58
May 26
The Q&A at the end is worth the watch on its own.
Attendees asked about:
↳ Whether optimized deep learning kernels flow through the same pipeline
↳ Support for Intel GPUs and emerging hardware
↳ How SCALE compares to NVIDIA's own compiler when targeting NVIDIA
↳ Adding custom accelerators (RISC-V came up) and emulating missing functionality
↳ Code-level transformations to improve occupancy on AMD
↳ Plans for OpenACC, CUDA Fortran, and OpenMP
1
2
40
May 22
𝗨𝗽 𝘁𝗼 𝟮𝟱.𝟳× 𝗳𝗮𝘀𝘁𝗲𝗿. Unmodified CUDA. AMD silicon.
Thanks to the @tensorwave team for benchmarking SCALE on MI355X and publishing the numbers.
Port to AMD used to mean a rewrite. Now it means a recompile.
May 22

Spectral Compute (@SpectralCom) used TensorWave’s AMD-native infrastructure to benchmark CUDA portability and performance on @AMD Instinct™ MI355X GPUs.
See how they did it - tensorwave.com/blog/spectral…

2
7
160
May 21
Sort the issues of almost any popular open-source CUDA project by most commented, and you'll inevitably find the exact same unresolved thread: 'Any chance of AMD support?'"
1
1
6
92
May 21
For most maintainers, that thread stays open indefinitely. Porting a complex CUDA codebase is a part-time job, and volunteer contributors rarely have one to spare.
𝗦𝗖𝗔𝗟𝗘 𝘁𝘂𝗿𝗻𝘀 𝘁𝗵𝗮𝘁 𝗶𝘀𝘀𝘂𝗲 𝗶𝗻𝘁𝗼 𝗮 𝗿𝗲𝗰𝗼𝗺𝗽𝗶𝗹𝗲.
1
2
26
May 21
Our compiler toolchain is free for research and evaluation. If you maintain a CUDA project and want to finally close that thread, come say hi: discord.com/invite/KNpgGbTc3…
2
26