
Building Atlas, pure Rust inference engine with custom CUDA kernels | Ambassador @Alibaba_Qwen
Joined March 2026
- Tweets 94
- Following 42
- Followers 531
- Likes 104
8 Photos and videos







Jun 12
Happy to share that @AtlasInference is helping shape the MLPerf Edge LLM benchmark with @MLCommons taskforce 📢
We'll be contributing cross-architecture validation on @NVIDIAAI DGX Spark and @AMD Strix Halo. More details coming after official submissions later this year 📊
1
2
9
493
Azeez retweeted

Jun 3
Cross-architecture from a single codebase is exactly why we built SCALE. Thrilled to see @AtlasInference getting this running! More performance optimizations for both @AMD and @nvidia are on the way.
scale-lang.com
Jun 2

Atlas Inference is running Qwen3.6-27B on AMD Strix Halo 🥳
Using @SpectralCom's SCALE ROCm backend, our CUDA kernels compile and run on RDNA⚙️
Cross-architecture inference from ONE codebase 🗣️
Thank you @AIatAMD for the gift 🙏
POC ✅ excited to keep tuning performance⚡️
1
1
5
270
Jun 2
Atlas Inference is running Qwen3.6-27B on AMD Strix Halo 🥳
Using @SpectralCom's SCALE ROCm backend, our CUDA kernels compile and run on RDNA⚙️
Cross-architecture inference from ONE codebase 🗣️
Thank you @AIatAMD for the gift 🙏
POC ✅ excited to keep tuning performance⚡️
7
2
31
2,339
Jun 2
We picked @Alibaba_Qwen's series to test because it is the de-facto standard for local LLMs!
Join our discord for access to early releases, feature requests, and any for help you may need serving 🫂
discord.com/invite/6vDbKaKrK…
Github linked below🔗
github.com/Avarok-Cybersecur…
320
May 28
It’s official: @AtlasInference is now a @Alibaba_Qwen ambassador! 🤝
Our mission started with Qwen. It remains our top priority and most optimized series. Qwen revolutionized open-source AI, and we’re excited to keep pushing its limits ⚡️
Thank you to our amazing community❤️🔥
5
3
24
976
May 28
Excited to try Qwen3.7-Max (plz OSS release soon🙏) Look at how deeply embedded we are optimizing @Alibaba_Qwen:
3.5/3.6-35B, 3.5/3.6-27B, 3.5-122B (EP=2), 3-Next-80B (GDN/Mamba-2), 3-VL, 3-Coder. Achieved 130 tok/s on 3.5-35B. The Qwen series is genuinely WHY we built Atlas!
1
1
4
546
May 26
DGX Spark lovers 🚨
Thank you @huggingface for merging SM_121 support into kernel-builder, every dev can now pull optimized kernels via get_kernel() 🚀
@AtlasInference pushed to make sure the DGX Spark community had representation 💾
Let's keep squeezing these GB10 chips 📈
5
5
59
3,305
May 26
See github.com/huggingface/kerne… for more details.
Special thanks to @RisingSayak and the broader hf team for working quickly to resolve this, and being open to collaboration from the incredible open source community 💯
6
476
Azeez retweeted

May 23
That's right, that's why im working on TQ cache compression techniques for @AtlasInference right now in my copious amounts of spare time... now back to hand tuning metal kernels:
github.com/Avarok-Cybersecur…
1
1
5
354
Azeez retweeted

May 18
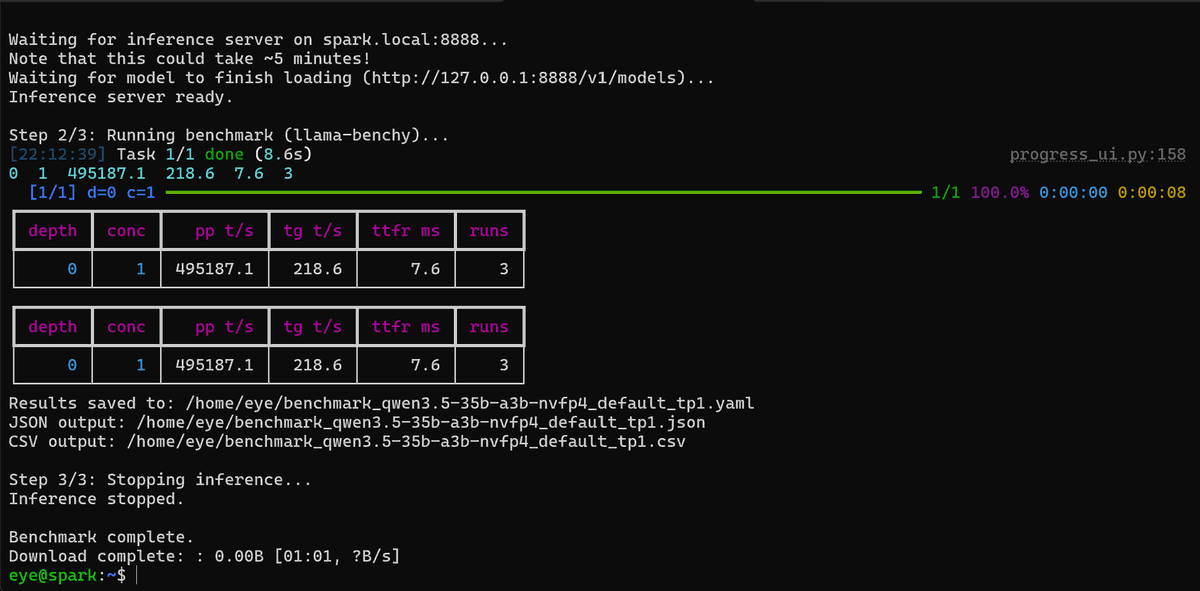
Many people say Nvidia DGX Spark is too slow and not worth the money. I'm getting crazy speed qwen3.5-35b-a3b-nvfp4 with my ASUS Ascend GX10: over 200 token/s, 495k prefill. In real-life performance is lower, but still 100 token/s.
sparkrun run @atlas/qwen3.5-35b-a3b-nvfp4
32
21
222
20,098
Azeez retweeted

May 17
Localmaxxing now supports infra benchmarks from @AtlasInference
Looks like an interesting rust cuda engine
Use today with DGX Spark
3
2
28
2,403

May 16
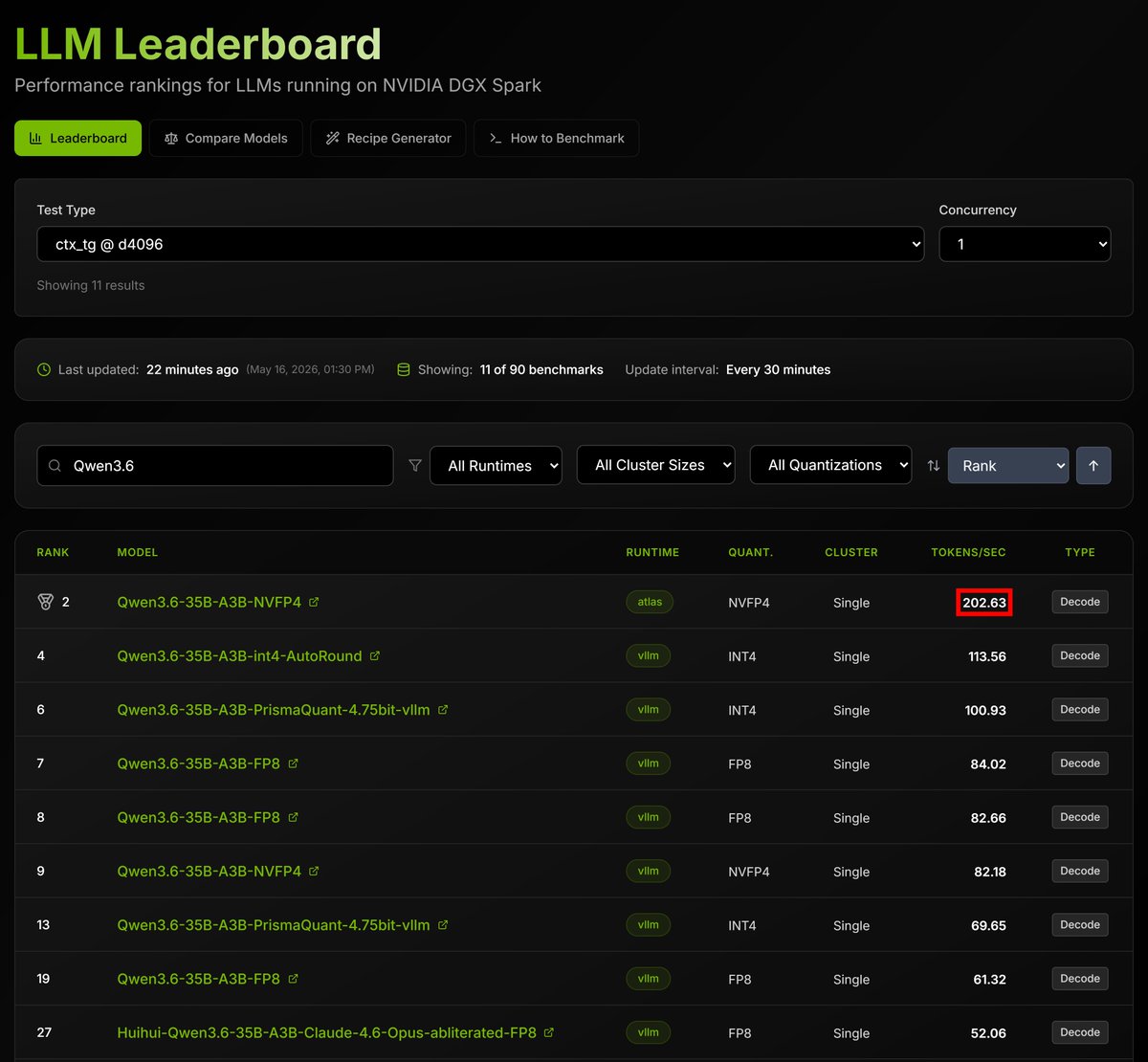
DGX Spark just benched 200 tok/s for Qwen3.6-35B with @AtlasInference on @spark_arena 🔥
How's that possible? Providers like Codex and Claude get ~60. Other major engines don't come close 🦥
We haven't seen speeds like this on GB10. NO ONE HAS. Atlas is shattering records 🚀
27
17
140
55,259
May 16
Check out our Github: github.com/Avarok-Cybersecur…
Join our discord too! discord.com/invite/DwF3brBMp…
We're bringing the best speeds FOR the community. AMD support is coming 🔜
3
18
2,296
May 15
🚀 Huge thanks to @AMD for sending @AtlasInference a Strix Halo laptop!
Excited to squeeze every last drop of compute out of it. Our goal is staying community-first with the simplest stack possible, ROCm here we come 🔥
Join our Discord for early access and help shape what we build next. What should we tackle first? 👇
3
3
14
806
May 15
@SpectralCom we're looking forward to using SCALE for the CUDA→ROCm path :)
We want to bring this same concept of having hyper-optimized kernels built for a certain model architecture and its corresponding quantization, adapted per chip.
4
419
May 15
If you aren't familiar with Atlas, we're building a dependency free inference engine just purely Rust and CUDA. <2 min cold start and blazing fast on models like Qwen-3.6-27B on DGX Spark 💻github.com/Avarok-Cybersecur…
Discord linked below🔔discord.com/invite/DwF3brBMp…
1
1
3
534
May 11
Atlas is now on Sparkrun. Pick a recipe, one command, done! The #1 DGX Spark inference service. Bleeding-edge models (Qwen3.6, Minimax) benched against every runtime on Sparkrun sparkrun.dev/runtimes/atlas/
Try it:
sparkrun run @atlas/qwen3.6-35b-a3b-nvfp4-atlas
Thx @spark_arena!
2
16
1,218
May 6
Atlas is open source!
An inference engine written from scratch in Rust CUDA. No PyTorch, no Python, no 200-dependency install dance. <2 min cold start, BUILT for GB10
Qwen3.6-35B at 130 tok/s on a single DGX Spark.
Demo powered by @Gradio
🧵 atlasinference.io
27
58
301
35,689
May 6
AMD's Strix Halo is next. We're working with @SpectralCompute on the CUDA→ROCm path, and @AIatAMD is giving us hardware access to make it real. Excited to bring Atlas to the AMD userbase, same kernel philosophy, adapted per chip.
3
1
12
1,748
May 6
@SpectralCom! Apologies on the tag issue, looking forward to bringing this to life for AMD
328
May 6
Two commands <2mins, and on website/repo:
docker pull avarok/atlas-gb10:latest
docker run <MODEL>
🔗 github.com/Avarok-Cybersecur…
🔗huggingface.co/spaces/Atlas-…
Discord (420 and growing): discord.gg/DwF3brBMpw
Tell us what you want next. The roadmap is whatever the community needs.
11
1,511