
Chief Architect @askproductai | Building AI systems for commerce | Care in the details | Raising a tiny human
Joined March 2009
- Tweets 591
- Following 3,185
- Followers 611
- Likes 2,075
Photos and videos
Bri Stanback retweeted

Feb 1
Gemini CLI 🤝 OpenClaw🦞
Read below how Gemini CLI's Security extension helped identify and resolve a security vulnerability in OpenClaw.
Gemini CLI then helped put up a PR which has since been merged. ✅
Read the details below👇
Jan 31

AI isn't just writing code anymore, it’s securing it. 🛡️
Our new code security agent, built on the @geminicli, identified and resolved a critical vulnerability in @openclaw.
It generated a POC, opened a PR, and was merged into OpenClaw in just a few hours.
This is exactly why we built and open-sourced this agent. To get the full benefits of AI code generation, we need to trust the ecosystem. By automating high quality vulnerability detection and remediation, we can help the community move faster and safer. ⬇️

56
217
1,955
223,201
Bri Stanback retweeted

9 Apr 2025
Google published a 69-page whitepaper on Prompt Engineering and its best practices, a must-read if you are using LLMs in production:
> zero-shot, one-shot, few-shot
> system prompting
> chain-of-thought (CoT)
> ReAct
> code prompting
> best practices


88
1,653
15,193
1,221,653

NEW: Google presents Agent Development Kit (ADK)
Features:
- code-first
- multi-agents
- rich tool ecosystem
- flexible orchestration
- integrated dev xp
- development-ready
- streaming
- state, memory, artifacts
- extensibility
> pip install google-adk

39
415
2,630
271,834
Bri Stanback retweeted

23 Jan 2025
Introducing Perplexity Assistant.
Assistant uses reasoning, search, and apps to help with daily tasks ranging from simple questions to multi-app actions. You can book dinner, find a forgotten song, call a ride, draft emails, set reminders, and more.
Available on Play Store.
244
520
4,791
701,764
Bri Stanback retweeted

21 Jan 2025
Our latest update to our Gemini 2.0 Flash Thinking model (available here: goo.gle/4jsCqZC) scores 73.3% on AIME (math) & 74.2% on GPQA Diamond (science) benchmarks. Thanks for all your feedback, this represents super fast progress from our first release just this past Dec! Latest version also includes code execution, a 1M token content window & a reduced likelihood of thought-answer contradictions. We’ve been pioneering these types of planning systems for over a decade, starting with programs like AlphaGo, and it is exciting to see the powerful combination of these ideas with the most capable foundation models.
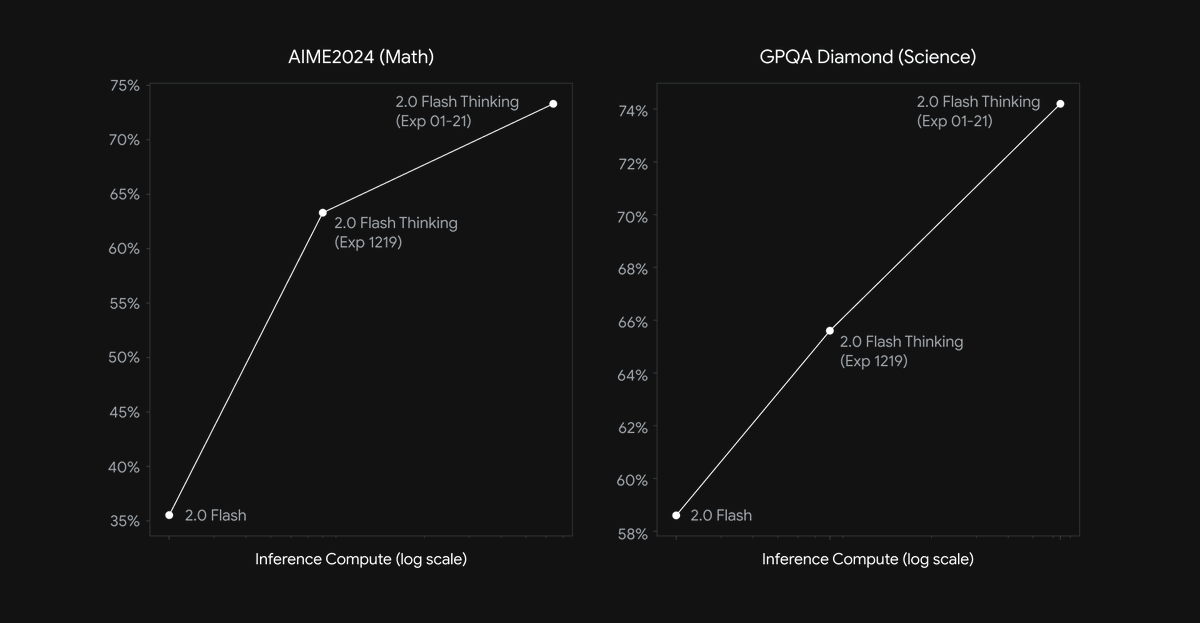
122
351
2,591
695,669
Bri Stanback retweeted

5 Dec 2023
Today we're announcing the AI Alliance, together with @IBM and 50 global organizations across the industry.
This group will focus on fostering open science and enabling the acceleration of responsible innovation in AI.
More on the AI Alliance ➡️ bit.ly/3t3yTf3

23
166
635
152,858
Bri Stanback retweeted

5 Dec 2023
ICYMI: Branch announced the winners of its fourth annual Mobile Growth Awards!
#mobilegrowthawards #mobileapps #innovation
Check out the full list of winners 👇 prnewswire.com/news-releases…
1
3
197
Bri Stanback retweeted
29 Nov 2023
Published in @Nature: our AI system for material design ‘GNoME’ that found 380,000 new materials (which we’ve made freely available to the research community) with potential to accelerate greener tech from better batteries to more efficient superconductors deepmind.google/discover/blo…
116
782
3,850
798,680
Bri Stanback retweeted

6 Oct 2023
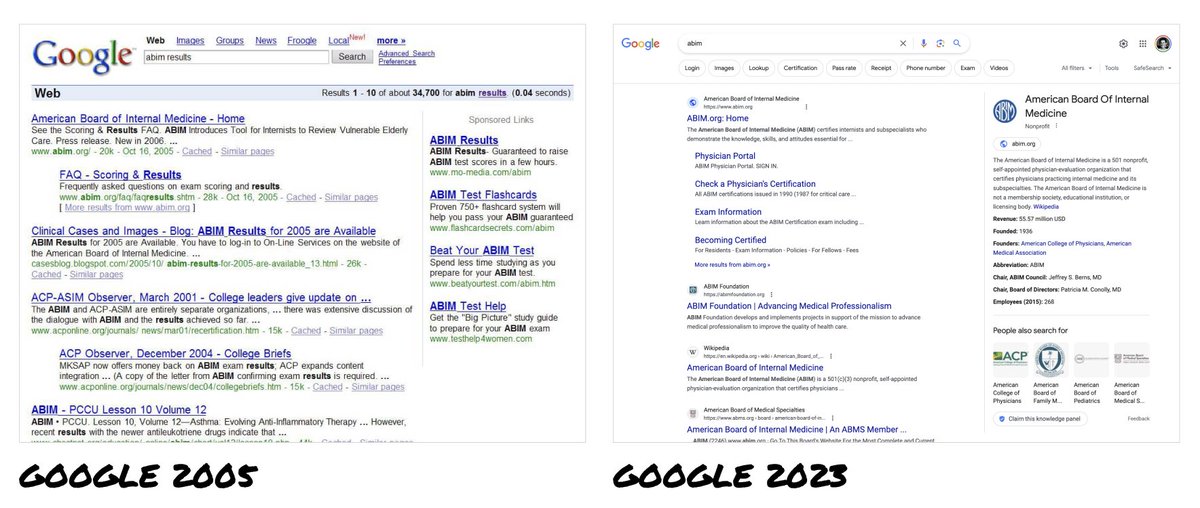
In 2006, I was 1 of 4 designers on Google Search.
For 20 years, every search engine has copied Google.
Now ChatGPT, Bard Claude look like Google's offspring - "better” search engines.
But last week signaled we're on the brink of a design revolution.
ChatGPT unveiled incredible new features.
These could give us the opportunity to completely shift how we interface with AI.
Here's the full story:
–––
When I was a designer on Google Search, all major search engines looked the same – Google, Yahoo, MSN Bing.
Google was the market leader with a heavily optimized UI that supported billions of dollars in ad revenue.
Naturally, it became THE way to show search results.
Its success made it illogical for Google to consider big UI changes.
And any changes they did make were just mirrored by everyone else.
So 20 years later, we’ve only seen incremental changes to search engine UIs.
–––
Today, we have consumer-ready LLMs (Large Language Models) freshly in our hands.
As consumer products, these are in their infancy.
We’re very early in understanding their capabilities and defining how people interact with them.
These are uncharted waters.
And yet ChatGPT, Bard, Claude etc. all chose a text-based input box — just like Google’s search box — as the core interface.
Why?
The input box is simple, versatile, and familiar.
- It’s simple to understand → you type your questions into the box.
- It’s versatile → the box can handle all sorts of questions/queries.
- The paradigm is super familiar → people immediately know how to use it.
Because of this, LLMs have essentially become “a better Google.”
–––
But last week’s ChatGPT announcements thrust open the doors to new possibilities.
ChatGPT is now multi-modal — it can see, hear, and speak.
These are the recent announcements from @OpenAI :
Voice: twitter.com/OpenAI/status/17…
Photos: twitter.com/OpenAI/status/17…
The example of ChatGPT explaining how to lower a bike seat was incredible.
But, it could be so much better!
The video showed you'll have to post multiple new photos to keep adding new information and to progress the conversation.
It was still a linear conversation centered around the text box.
But what if we rethought the interface to center around the image?
What if ChatGPT supported both images AND voice simultaneously?
Could we end up with a more immersive experience?
–––
How else could interacting with LLMs mimic IRL conversations?
Could we (or the AI) pinch to zoom or rotate the image?
Could we interact in real time with video?
What new possibilities open up with context being preserved over time?
–––
There is so much energy and excitement around what AI can do.
But we are limiting the potential by assuming the conversation box is the best interface.
Right now, designers have the chance to create truly novel interactions and bust through the 20 year old search UI paradigm.
The ideas above are just to illustrate some potential options.
But they are also intended to spark a flame.
Now is the opportunity to be creative and explore divergent UIs.
What are the craziest, coolest, most creative UI ideas we can unleash?
LFG 🚀

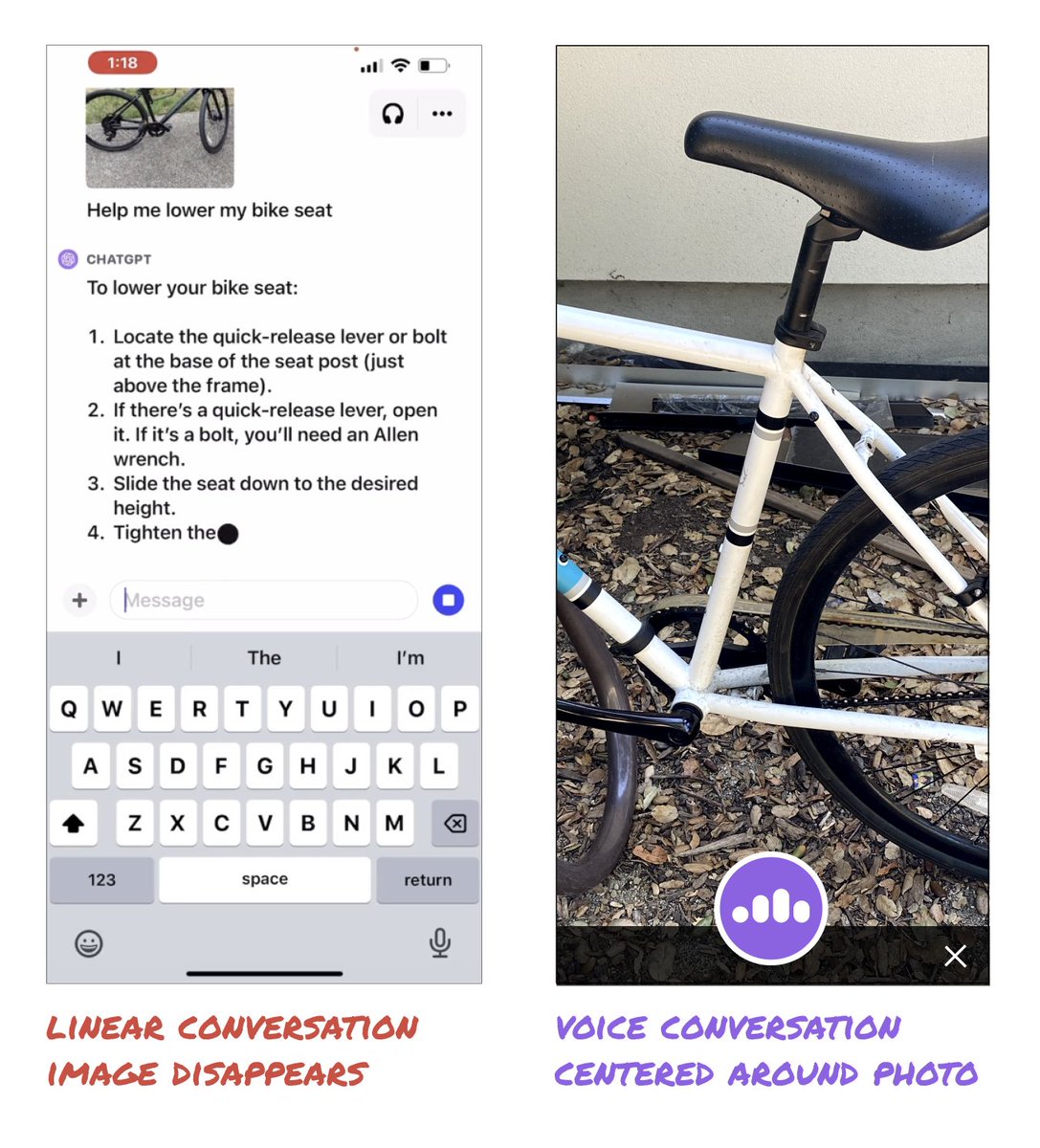


ChatGPT can now see, hear, and speak. Rolling out over next two weeks, Plus users will be able to have voice conversations with ChatGPT (iOS & Android) and to include images in conversations (all platforms).
openai.com/blog/chatgpt-can-…
178
995
6,371
1,837,178

4 Oct 2023
Discover all of your Amazon Prime benefits, including fast and free shipping, exclusive deals, access to streaming services, and much more. dealspotr.com/article/a-comp… @dealspotr
1
58
Bri Stanback retweeted

22 Aug 2023
After 6 weeks of intensive learning on dynamic NFTs, artists from @thehugxyz are onboarding into The Lab, the new no-code toolkit from @TransientLabs ⚗️
We had 200 students enroll in our Innovation Laboratory and I am so proud of everything they've done.
I can appreciate it's no easy feat to take time out of your daily life and responsibilities to dedicate yourself to learning something new and all the frustration that comes with it. Thank you to every artist that allowed HUG & Transient Labs to help them go further on their journey as artists 💕
Next... I can't wait to see the dynamic art they create and the new contracts they deploy, and especially those that will get curated into our NYC gallery show!
25
21
168
8,030
Bri Stanback retweeted

21 Aug 2023
Here’s an alt/𝛂 take: what if this is Google’s ChatGPT moment, and behind the scenes they’ve also worked things out into their products, and this tech then is essentially what Gemini is about?
If that’s true, then Google basically reorged DeepMind and Core AI to literally e/acc the heck out of LLMs? (Blame covid fever if you disagree)
21 Aug 2023

we went from “ai entropy” to transformers in 2017 with a similar paper; now this will take us from “LLM entropy” to “GPT4 for all” in much less time.
AI OSS is bright, and let’s also hope we figure out copyright soon.
h/t @far__el — link below

11
112
1,065
1,099,883
Bri Stanback retweeted

21 Aug 2023
Monsoon microburst timelapse in Arizona
46
730
3,659
336,292
Bri Stanback retweeted

21 Aug 2023
🧪 Tutorial: Quick Midjourney Inpainting Process
While Midjourney is slowly rolling out the new InPainting feature for everyone to use, here's a quick tutorial on what you can expect from it!
Let's dive in 👇

39
89
700
293,990
Bri Stanback retweeted

22 Aug 2023
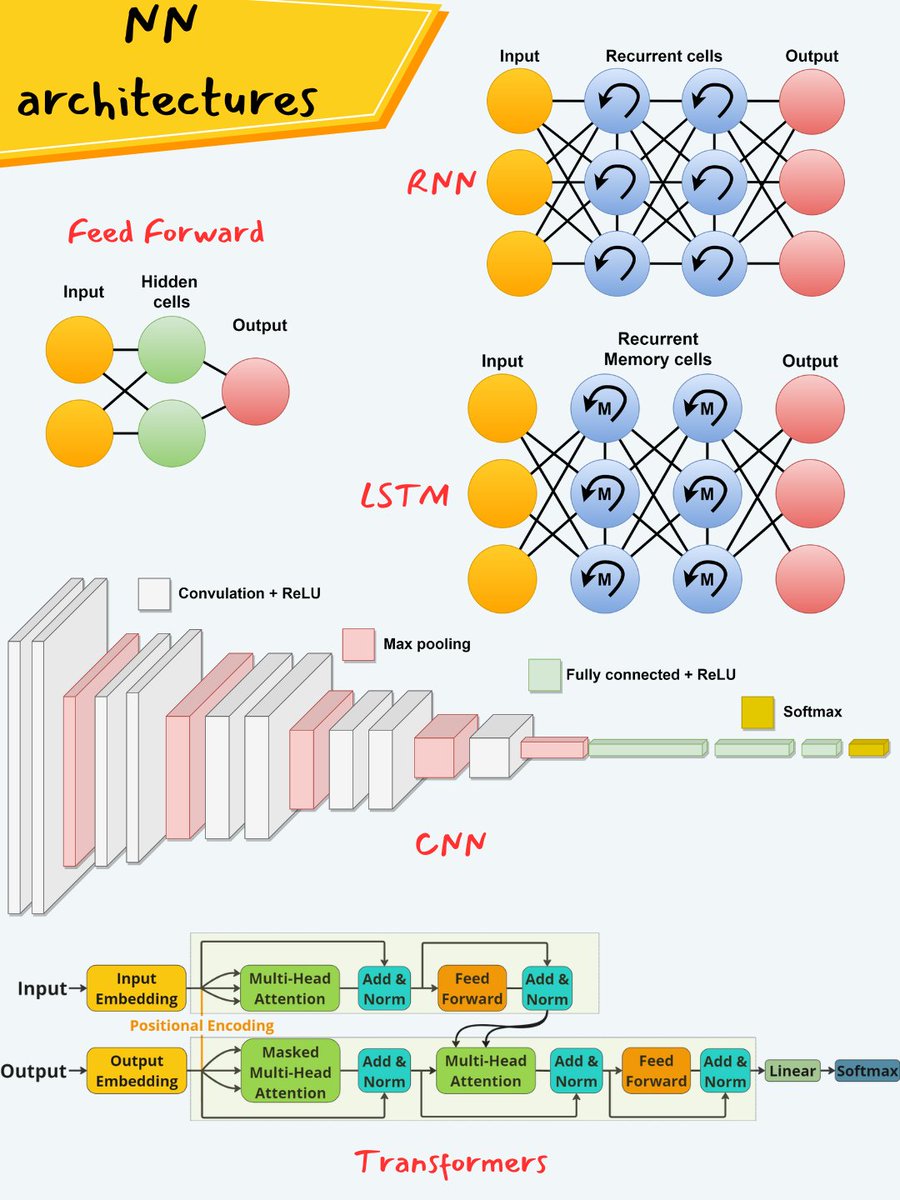
Types of Neural Networks - Evolution Of Deep Learning Architectures.
Oppenheimer, the movie, has all of us thinking about the 40s and WW2. Believe it or not, the first neural networks (NN) were invented around the same time, in 1943!
Warren McCulloch and Walter Pitts the founding fathers of NNs, were intrigued by how biological neurons worked and proposed a mathematical model for a NN
It was not until 1958, that Frank Rosenblatt invented the "Perceptron" which was basically a computer program designed to learn from its mistakes. It ran on a very big machine and essentially did binary classification. While there was a lot of excitement around these baby NNs they required a lot of compute and data, which meant that they needed some serious funding.
In 1969, a paper titled "Perceptrons" by Minsky and Papert, killed almost all innovation in NNs. The paper proved that the single perceptron, couldn't solve simple problems including the XOR problem, and was severely limiting and all funding stopped. At the same time, algorithms like Support Vector Machines (SVMs) start taking off and NNs took a back seat.
Multi-layer perceptrons (MLPs) were viewed as a way to address the issues that single-layer perceptrons had, but training these MLPs proved to be very difficult. Not until 1986, did we see the resurgence NNs. Rumelhart, Hinton, and Williams introduced the backpropagation algorithm, and suddenly training multi-layer NNs became tractable. Computers were becoming more powerful and more data become available. NNs were back in business.
In the late 80s, Yann LeCunn introduced CNNs, The convolutional layers of a CNN can model the spatial hierarchy of images and NNs started to become useful in image-processing applications. Still, SVMs were the cool kids and NNs were being used for niche tasks like handwriting recognition.
Only in the 2000s, did we see a true renaissance of NNs. Geoff Hinton introduced Deep Belief Networks and the term deep learning (DL) begin to take off.
In 2012, Deep Learning had a seminal breakthrough with a CNN called AlexNet that outperformed all other algorithms in image classification. Since then we have seen an explosion in NN architectures.
Recurrent Neural Networks (RNNs) and Long Short-Term Memory Networks were useful in understanding patterns in sequential data. In 2015, ResNets helped solve the vanishing gradient problem (another pesky issue with DL training), and DL research was exploding.
In 2014, generative NNs had a big moment - Generative Adversarial Networks (GANs) were invented by Ian Goodfellow et. al. GANs were really good at generating realistic images. The first deep fake was born :)
Finally, in 2017, Vaswani et al introduced Transformers. Transformers, with their self-attention mechanism allowed the model to weigh the importance of each word in relation to others and better understand language.
BERT in 2018, was a specific implementation on Transformers and can look and understand text in both directions. BERT is pre-trained on massive amounts of data (e.g. Wikipedia) and can be adapted to specific tasks with fine-tuning. BERT can be adapted to multiple tasks like Q/A and text classification
Just a few months earlier, also in 2018, OpenAI introduced the GPT models. These were unidirectional but also were trained on massive amounts of data. Unlike BERT, GPTs are fine-tuned for generation or next-word prediction. Since 2018, we have seen better and more sophisticated versions of the GPT series...with GPT-4 released in 2023, being capable of human-level cognition, generation, and basic reasoning!!
So what started almost 80 years ago is now finally beginning to take over and transform the world completely!! 🤯
25
445
1,754
358,344
Bri Stanback retweeted

21 Aug 2023
Meet Promptac
This real-world interface connects to generative AI through a suite of sensors.
- Thimble eyedropper sensor
- RFID picks up textures
- Color sensor
- Bending sensor
- Pressure sensor
This thing is made by Zhaodi Feng – more links in thread.
20
149
753
152,706
Bri Stanback retweeted

21 Aug 2023
Kid catches Walmart trying to fool parents on back to school supplies.
Smart kid 🚨🚨🚨
🔊
1,696
13,050
92,234
11,744,703

Bri Stanback retweeted

2 Aug 2023
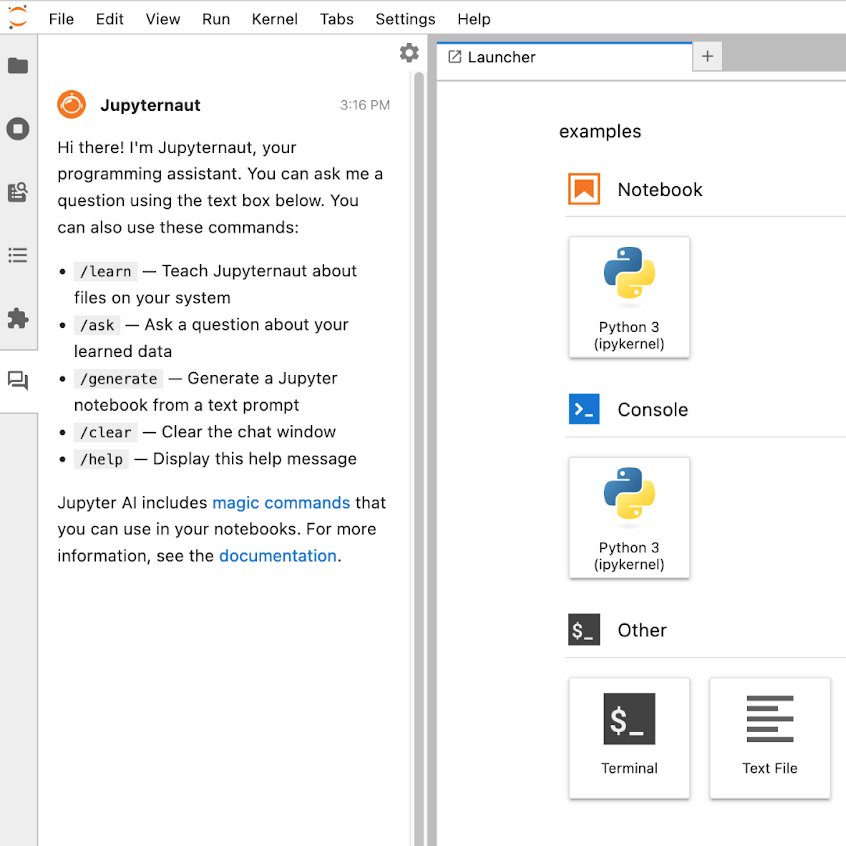
Great news. Jupyter just added a LLM-based chatbot to their environment.
The new AI bot allows you to:
▸ Generate entire notebooks from a prompt
▸ Generate code
▸ Fix errors
▸ Summarize content
▸ Ask questions about local files
Jupyter AI connects Jupyter with large language models (LLM) from providers such as AI21, Anthropic, AWS, Cohere, and OpenAI
pip install jupyter-ai
10
99
367
71,645
Bri Stanback retweeted
1 Aug 2023
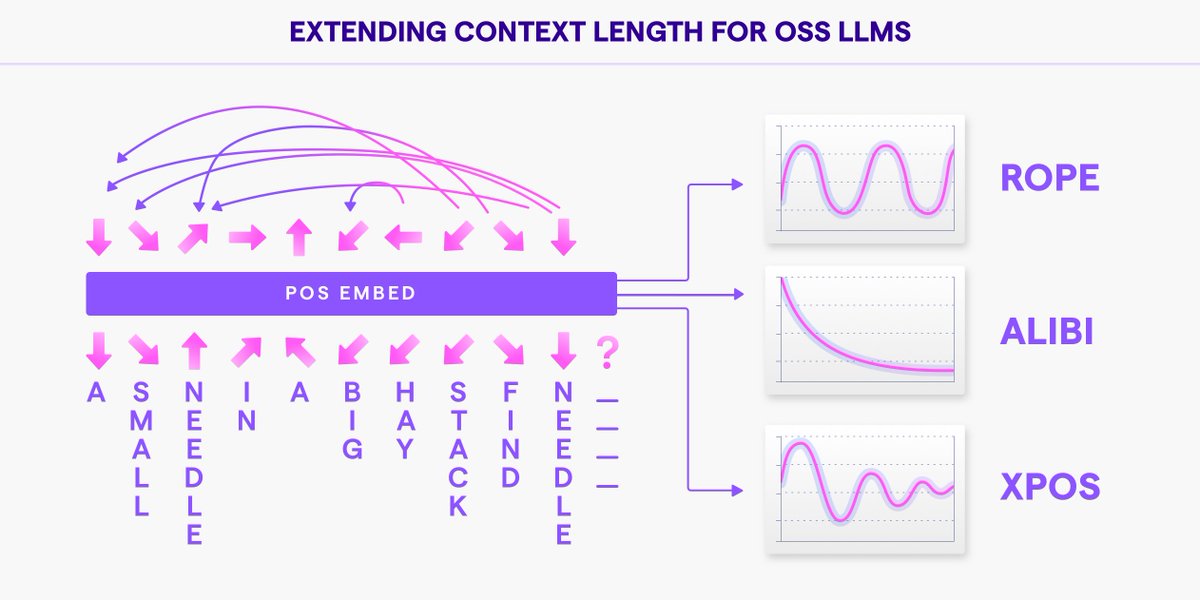
🌟Announcing Long Context OSS LLM - Giraffe 🌟
We are thrilled to announce 2 new open-source LLMs!
Today's SOTA open-source LLMs have one big shortcoming!
These LLMs have a very small context length of only 2K
This translates to them not being very useful when it comes to creating a Custom LLM based on your knowledge base.
You can’t send the LLM much data in a single call, which has a very negative effect on model performance.
Giraffe is a Llama 1 fine tune that extends context lengths to 4K and 16K.
We are open-sourcing these models, evaluation datasets, and performance experiments.
These models work well for real-world applied AI systems
Relevant links:
Git repo: github.com/abacusai/Long-Con…
Huggingface:
16k context - huggingface.co/abacusai/Long…
4k context - huggingface.co/abacusai/Long…
Blog post: blog.abacus.ai/blog/2023/07/…
18
78
331
185,006