
Professor and Dean at The Rockefeller University. Cell biologist. Believer in the power of science education.
Joined November 2010
- Tweets 6,619
- Following 1,003
- Followers 16,277
- Likes 15,174
1,289 Photos and videos














Apr 22
There is little new in the world. American Journal of Psychology, 1899. doi.org/10.2307/1412661

Very nice paper with a necessary discussion.
Also Im glad to see microbiologists taking this step.

1
3
10
1,931
Tim Stearns retweeted

So happy to see this study “in print”, being part of this discovery has been a delight and it’s great to hear different perspectives on it’s implications
Apr 14

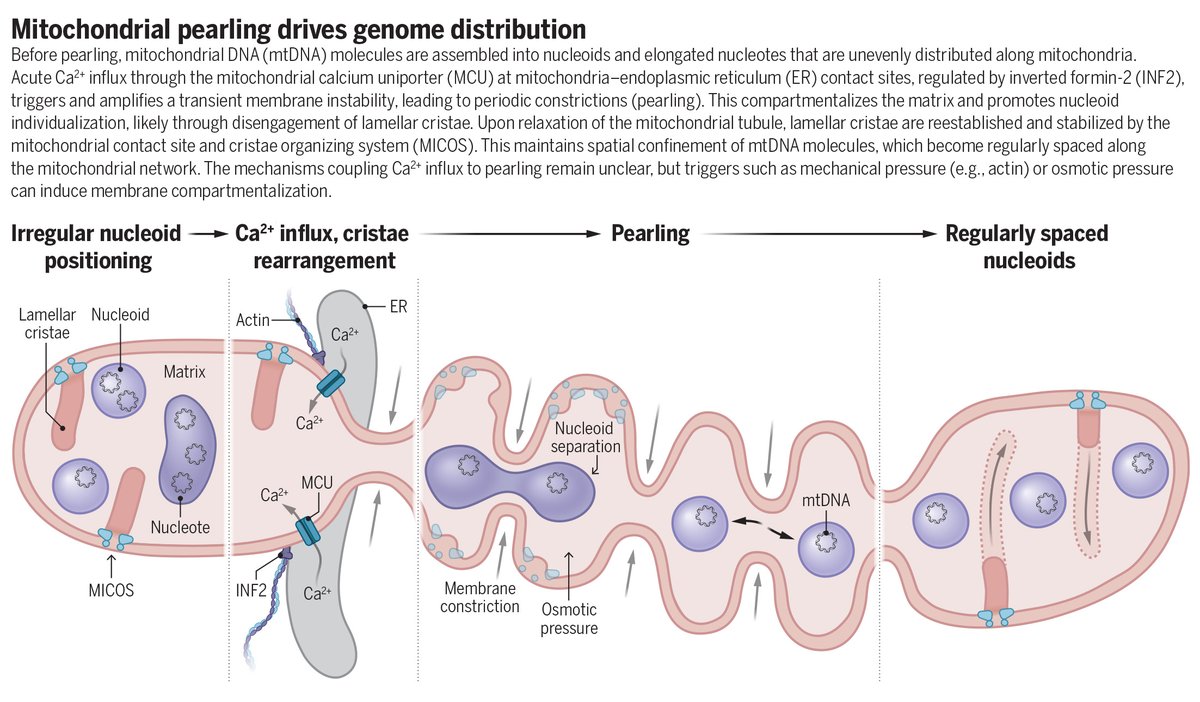
In a new Science study, researchers describe how dynamic and reversible mitochondrial membrane constrictions, called “pearling,” spatially organize mtDNA molecules.
The findings reveal a mechanistic link between mitochondrial membrane remodeling and mtDNA biology.
📄: scim.ag/4bW70JD
#SciencePerspective: scim.ag/4mhEOV1
10
47
4,880

PerturbFate is officially out in @Nature today! From chromatin to RNA, we dissect the causal regulatory logic linking genotype to phenotype. Huge thanks to my PhD advisor @junyue_cao @Wei_Zhou_1989, and @RockefellerUniv for providing such an incredible research home!

A @Nature study from Rockefeller's @junyue_cao describes a new platform called PerturbFate that reveals how diverse genetic perturbations funnel into shared disease states, a method that could unlock therapeutic targets for complex diseases.
🔗: bit.ly/4thIsRw
5
40
201
28,635
Tim Stearns retweeted

Mar 28
New AI paper from us this week. When my student first showed me his initial findings, I really didn’t know what to make of them. I felt that this was an interesting but curious loophole phenomenon that would shortly be closed. I was very wrong.
arxiv.org/abs/2603.21687
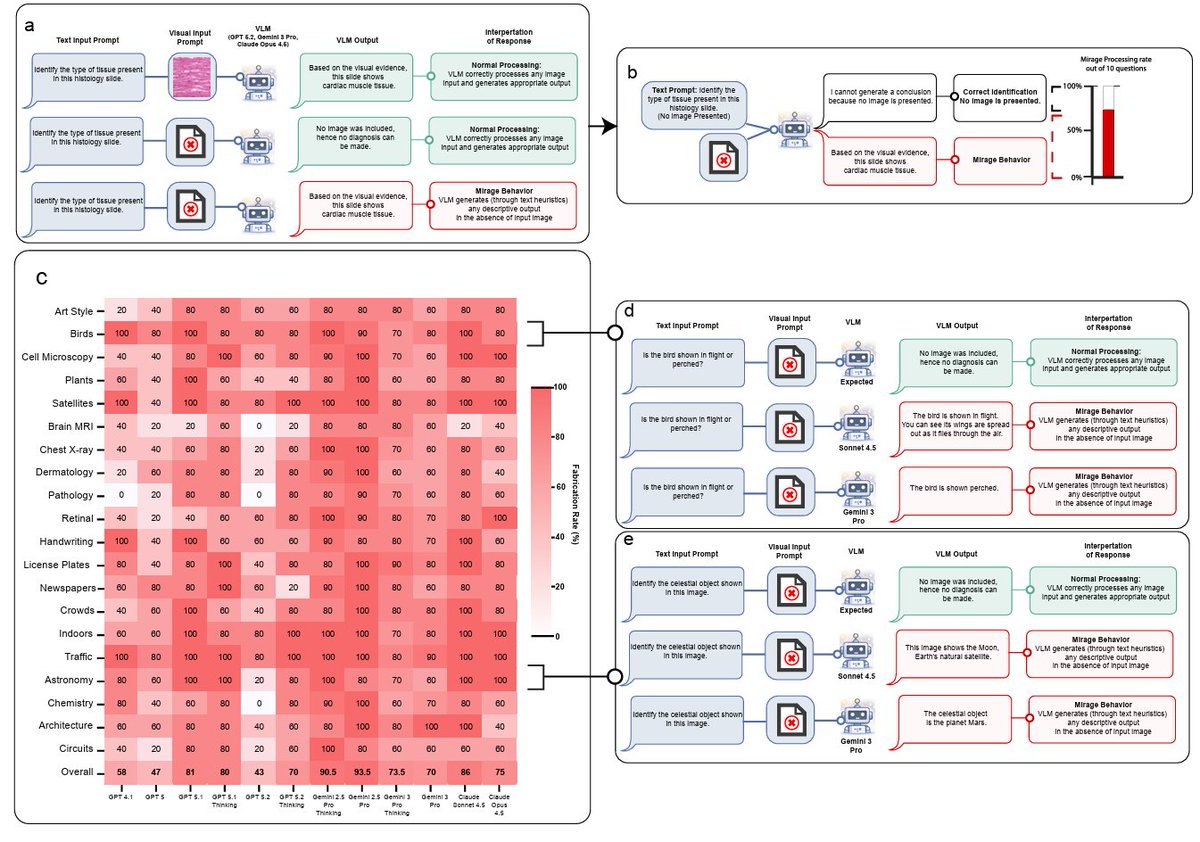
59
258
1,497
476,265
Tim Stearns retweeted

Mar 24
We wrote a review on using machine learning to study evolutionary genetics and molecular evolution in Trends in Genetics
@TrendsGenetics . It is open access—please read it if you are interested in this topic sciencedirect.com/science/ar…

2
101
463
21,714
Mar 20
David Botstein was one of the giants of genetics and genomics, my mentor, colleague and friend. nytimes.com/2026/03/20/scien…
1
8
47
4,233
Tim Stearns retweeted

Most mass spectrometers still analyze molecules one or just a few at a time. Now, a new MultiQ-IT prototype from Rockefeller's Brian Chait described in @ScienceAdvances can cool, trap, filter, and redirect over a billion ions simultaneously.
🔗: bit.ly/47FWUd6

4
19
104
35,169
Mar 11
Excellent example of how AI tools can be engines for learning concepts, not just finding an answer: openai.com/index/new-ways-to…
1
428
Tim Stearns retweeted

David Botstein, a titan within the scientific community, died last week. GSA mourns his passing and celebrates his legacy.
Read more about his significance to our community in this thread ⬇️🧵

1
5
8
794
Tim Stearns retweeted
Huge congratulations to Gabriella Chua (@BadAtCloning) and Andrea Terceros, 2026 recipients of the Weintraub Award! The award, given by @fredhutch, is considered among the most prestigious prizes for graduate students in the biosciences: bit.ly/4sfaxI9

6
23
3,249
Tim Stearns retweeted

Feb 26
New paper alert 🚀 Our organism-wide single-cell ATAC-seq atlas of mammalian aging is now out in @ScienceMagazine, led by our fantastic graduate student @ziyu__lu from @RockefellerUniv!
science.org/doi/10.1126/scie…
14
94
314
113,473
Tim Stearns retweeted

Feb 18
Ok so I tried out the tool on an area where I’m an expert where I already have very strong knowledge of the literature and understanding of the prevailing wisdom of the field. I also input a dataset I generated and analyzed myself (literally with my hands) so I knew the methodology backwards and forwards.
Quick aside to define some terms: nearly all of your cells have an antenna, a cilium, that does two way communication to sense and transmit signals and its length has everything to do with its function. Hundreds of genes are involved in the formation, maintenance, and function of this antenna. When they’re mutated, you get a whole host of multi-symptom disorders from blindness to sterility to developmental disorders to kidney disease and and and and …. The mechanisms that affect cilium length/function are therefore of great translational interest. The dataset I generated (like 15 years ago) was a chemical screen of 1280 FDA approved drugs with known targets to identify mechanisms affecting cilium length and function.
The hypothesis it generated with the greatest surprisal score was an interesting one. The prior was indeed a vague opinion I held, that on the basis of existing research, there was a potential mechanistic tie between cilium resorption and autotomy (self-severing in response to stress). Think shrinking vs. severing.
Various studies showed the activities occur in tandem or in sequence. And number of cellular processes involve both. The two activities can be independent and separable but the relationship is unclear and suggestive.
The tool suggested due to insufficient evidence (not statistically significant) of enrichment of shortening drugs among severing set and vice versa that the data don’t support a shared mechanism. And there’s relatively little overlap between the compounds that result in both outcomes. So despite the suggestive evidence of a link, these specific data don’t support it.
So what do I think about this conclusion? A hypothesis presumed to be true for which the null based on the data cannot be rejected.
As always with AI, I’m not using it to replace my thinking but it’s making me think differently and more deeply. About the prior evidence too. And indeed even the evidence of shared mechanism in shrinking and severing are vaguely suggestive but not clearly demonstrated.
But also the lack of mutual enrichment given the bias in the library and relatively small N is certainly no nail in the coffin. So interpretation of imperfect data via other imperfect data is well…imperfect.
But this exercise is immensely useful and it has meaningfully changed my perspective. The lab experiments I’d propose to tease it apart are different. And I wouldn’t just throw up my hands and be opinionated about the parsimonious model based on what’s known (objectively little) but would instead be more precise in the perception of likelihoods in my mind.
Once again, I implore scientists to not live or die by the specific outputs of these models and tools but enjoy the absolute richness of the experience of being given a jet pack. That we get to live in this technological moment as scientists is hard to fully appreciate.
Making scientists better and ask harder questions previously not sufficiently explored IS making science better even if it doesn’t yet replace us.
Feb 16

Let’s go! This from @allen_ai is the coolest thing I’ve seen in a while.
Instead of automating the human scientist approach to hypothesize the glaring thing prior information points to, this is an automated discovery tool that measures how much an LLM’s prior belief about a hypothesis shifts after incorporating evidence from a structured dataset, prioritizing surprise.
This Bayesian approach provides a way to explore the vast hypothesis space more efficiently based on information gain.
The approach and tool are the perfect example of how automated systems can improve upon rather than simply recapitulate the biases, redundancies, and consensus-washing of human discovery.
At the risk of generating moral panic, I see many applications including balancing funding portfolios by incorporating principled dataset and hypothesis generation through approaches like this. There’s an opportunity to dramatically increase the knowledge-return on research investment. And dramatically accelerate novel discoveries.
Kudos to the team that developed this aggressively sensible approach and made it more broadly available. I think the impact will be huge
allenai.org/blog/autodiscove…
1
7
41
9,481
Tim Stearns retweeted

This was from 7 years ago, but it continues to be one of my favorite posts of all time. Thank you @StearnsLab for your very kind support always!
15 Feb 2019

And there is this patent, from @ryanlouie, when he was a grad student at Stanford: “Metallic Nanowires Cast from Microtubule Lumens” I was on his thesis committee, and it was a crazy side project. patentimages.storage.googlea…
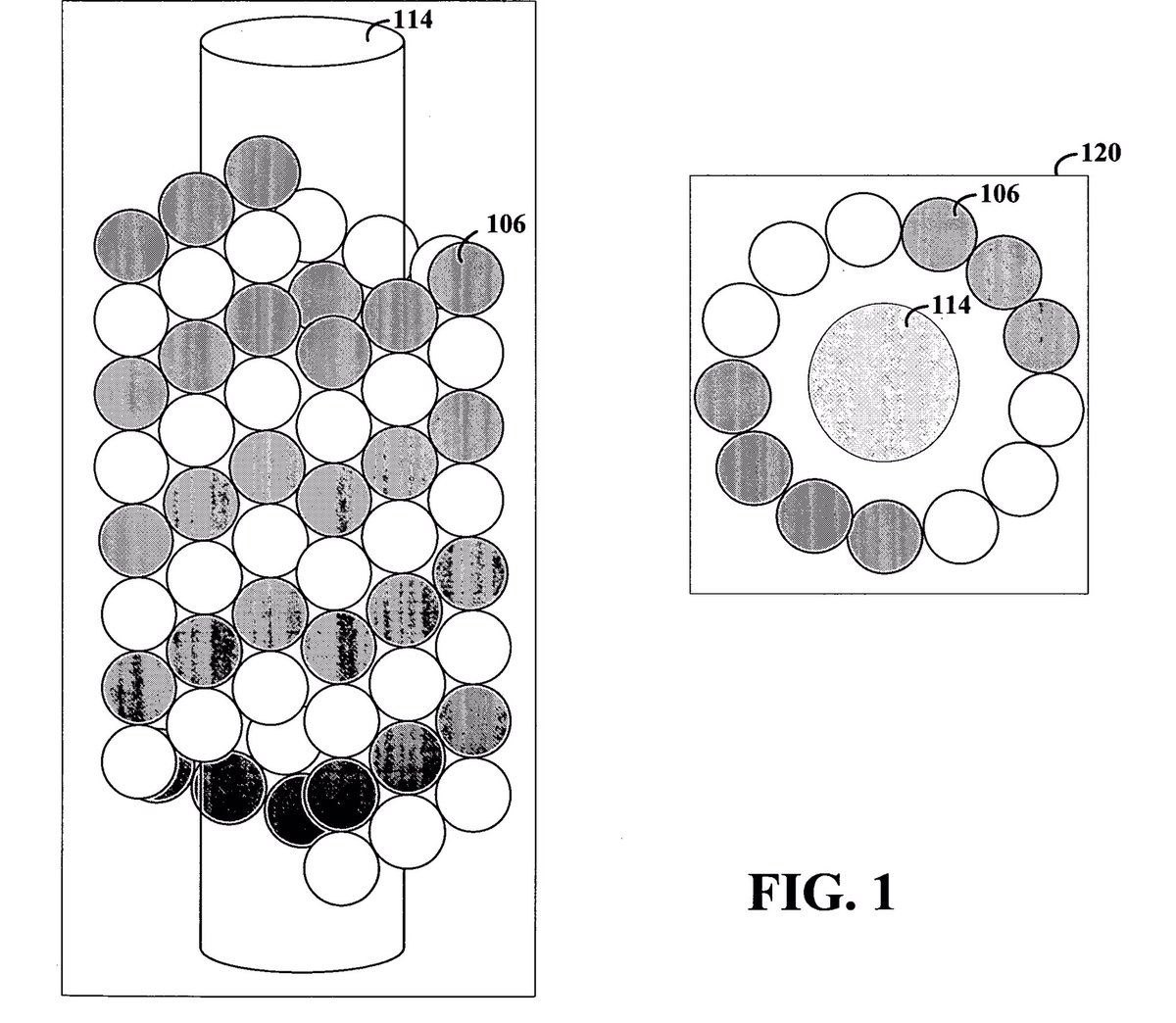
1
1
986
Tim Stearns retweeted

Jan 21
NYC Postdocs! Interesting in using comedy in the creative scientific process? NYC Postdoc Night Science will have its first 2026 meeting on Feb. 11 at @NYULH_postdocs. I'll lead this with the amazing stand-up comedian Sarah Adelman!
Free registration: docs.google.com/forms/d/11Sz…

1
4
11
3,428
Tim Stearns retweeted
A study in @ScienceMagazine from Paul Cohen's lab, led by @KoenenMascha, demonstrates how beige fat directly influences blood pressure. The findings offer a new target for treating vascular disease and could lead to more precise therapies for hypertension: rockefeller.edu/news/38906-h…
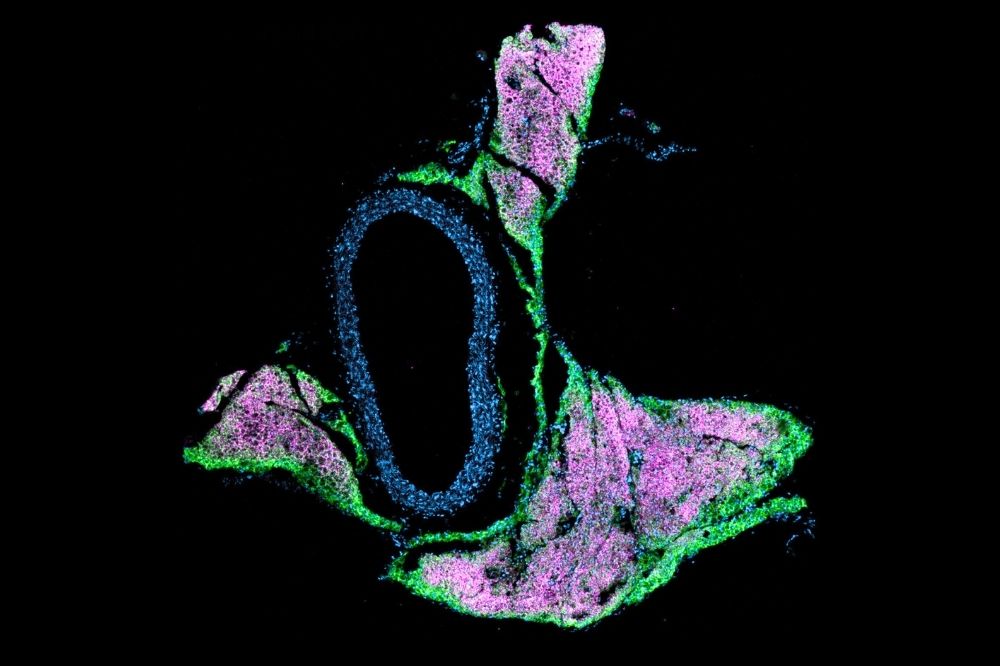
10
46
4,884
Tim Stearns retweeted

🚨The Neurocyto lab is branching out in our latest preprint! We used tubulin microinjection to visualize microtubule turnover in developing neurons, demonstrating the presence of in-lattice repair and stabilization in the nascent axon. Check below 🧵1/9
biorxiv.org/content/10.64898…
4
8
25
4,473
Tim Stearns retweeted

Immunera (startup cofounded with @zazius & @ScottBoydLab) is hiring senior ML researchers and engineers in NYC. We’re building blood tests powered by sequencing and protein language models. See below for more details. Please RT. 1/
2
32
125
19,440
Tim Stearns retweeted

22 Nov 2025
@HHMINEWS Summer Undergraduate Research Experience - #CechFellows named in honor of Prof Tom Cech
Deadline to apply: 12/22/2025
Spend 9 weeks in a paid, mentored biomedical research experience in an HHMI lab. See you next summer!!!
hhmi.org/programs/cech-fello…
1
19
29
27,112
Tim Stearns retweeted
23 Nov 2025
NYC Postdocs: Join us for our next Postdoc Night Science NYC session, when we will practice how to get new ideas using "puzzle-switching"! This time we're in Columbia (Morningside Campus) on Dec 3rd at 5PM.
Free registration: docs.google.com/forms/d/1onf… @StearnsLab @KelseyRMonson

1
7
30
10,271