
@StoryProtocol Ecosystem
Joined September 2024
- Tweets 1,948
- Following 177
- Followers 246,747
- Likes 4,422
176 Photos and videos













Pinned Tweet

23 Feb 2025
If you're new here, welcome to the Story Ecosystem.
AI needs ꧁IP꧂ and Story makes IP programmable.
Dive in to get started ↴
23 Feb 2025

Just for you 🫴 a Story Ecosystem starter pack.
From DeFi and IPFi, to AI tools, consumer apps, AI agents, games, and Sci-Fi franchises, the Story Ecosystem's got range.
Dive into a rundown of apps live on Mainnet, and stay tuned for more coming soon from the full lineup ↴

37
31
173
34,863
Story Ecosystem retweeted

Jun 9
Tamil has reached its contribution goal on Numo.
நன்றி to everyone who contributed.
This is what compounding momentum looks like.
52
28
143
8,013
Story Ecosystem retweeted
Jun 8
The internet was the first dataset.
What's next is being built now.
Meet @SPChinchali from @Psdnai↓
64
51
187
11,433
Story Ecosystem retweeted
Jun 5
The CDR Hackathon is now complete ☑
Meet the winners:
Technical Track
▸ Litmus @blancowillfind
▸ CDR Kit @Chain_Oracle
App Track
▸ Keyring @soarinskysagar
▸ Nythera @nythera_vault
▸ Confide @TekDiverse
▸ Sigmax @AbdoViper23
▸ Zerosight @ZeroSight_
Job well done.

55
24
144
7,391
Story Ecosystem retweeted

Jun 1
Love seeing hackathon participants demoing their projects live and gathering feedback from peers 👏
And with some delicious food too!
Incredible job @nythera_vault
May 31

Demo Day takeaway
The problem is bigger than crypto. Even Web2 users agreed with the vision
Back to building!




6
2
39
1,942
Story Ecosystem retweeted

Jun 3
Seneca (Story v1.8.0) is Live
The Story Mainnet has successfully upgraded to v1.8.0, and the network is healthy. If you're still on an older version, upgrade your mainnet node immediately.
Read More ↴
7
5
34
1,750
Story Ecosystem retweeted
May 26
society if all data had receipts

26
23
116
3,884
Story Ecosystem retweeted
May 20
Pssst.
We’re launching a hackathon around Confidential Data Rails (CDR), Story’s new primitive for programmable private data.
▸ $3,000 prizes
▸ 1 week only
▸ Workshops in Korean English
Existing projects welcome. Opens May 27th ↓
Apr 10
The next wave of AI depends on data that can’t be exposed.
Now with Confidential Data Rails (CDR), that constraint disappears.
▸ Data stays encrypted
▸ Access is defined upfront
▸ Secure pre-conditions held for decryption
Live now on testnet.
38
52
179
358,695
Story Ecosystem retweeted

May 19
if you want to 100x your money TODAY, you can't long NVDA, or buy into an Anthropic SPV. you need to move further up the AI stack.
Stack is: Compute -> Models -> Data.
Compute (last 10-20 years):
NVIDIA: 1,500%
Intel/ARM/etc: 200-300%
infra like Energy, semis, etc all pumped/pumping
Models (last 5-6 years):
OpenAI: >$1T IPO soon
Anthropic: >$1T IPO soon
xAI, Mistral, etc all have mega valuations already
Data (next 5-10 years):
it's still early innings for data, but Mercor already valued >$10B, Scale AI bought by Meta for $14B. Many new companies emerging too, eating their lunch.
???
???
Don't get me wrong, you can still make decent returns on compute and models today, but the massive upside is no longer there.
what's left is data.
AI cannot function without training data.
AI cannot get better without training data.
AI needs training data just as much as it needs data centers and energy.
The word "data" in "data centers" tells you all you need to know.
Data is like the spice in Dune.
Companies that sell high signal training data are selling picks and shovels in the AI race.
Frontier AI labs are ALREADY spending massive amounts of money on data, and after they IPO they will have EVEN MORE massive amounts of cash to spend on data to get ahead of their competition.
We will see $1T data companies in the future.
NFA, DYOR
8
4
30
1,339

Voice AI has an evaluation problem. Models look strong on public benchmarks, then collapse on real-world audio.
Introducing sonar.psdn.ai: a recipe-driven evaluation framework for low-resource languages, real-world audio, and production failure modes.
Details ↓
40
34
186
31,689

Subtitles are now live on GIMI thanks to @veedstudio ⚡
Brands can now add clean, on-brand subtitles across community content at scale, seamlessly baked into the creator workflow via VEED’s API.
Want to try it?
Join our partnership challenge.👇
app.gimi.co/en/campaigns/we-…
24
28
66
13,883
Story Ecosystem retweeted
May 18
Bengali Voice Submissions
██████████ 100%
Hindi Voice Submissions
██████████ 100%
Telugu Voice Submissions
██████████ 100%
Vietnamese Voice Submissions
██████████ 100%
Contributions are still open for Tamil. Lock in ↓

Hindi, Telugu, and Vietnamese all just crossed the finish line on Numo.
Huge thank you to everyone who contributed and helped bring more real-world voice data into AI training.
Submissions are now closed in these languages.
65
64
608
2,789,860

May 13
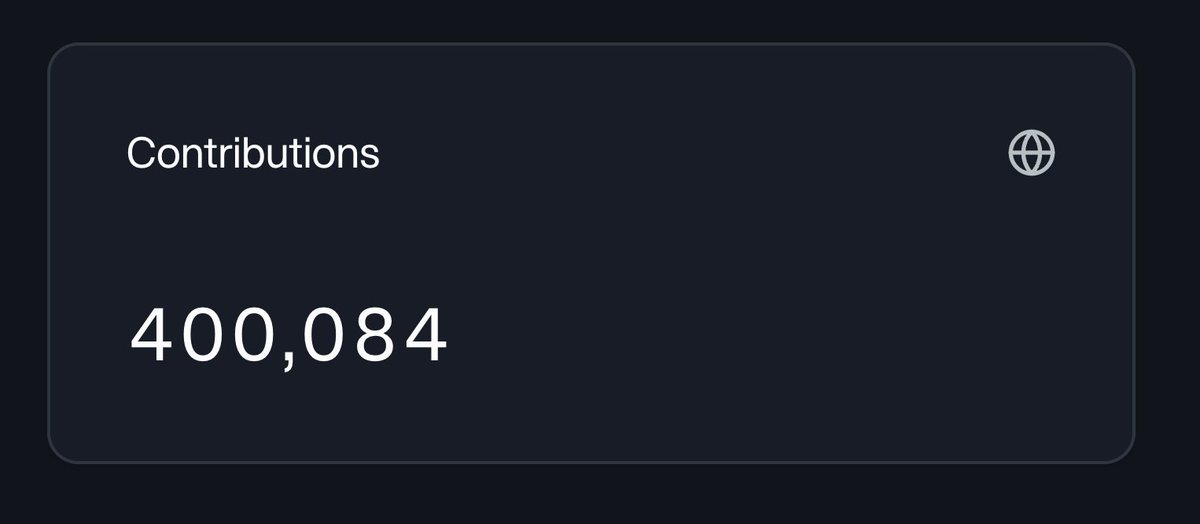
400K and counting... ⛓️
May 12

Numo just passed 400,000 training data contributions.
all the while operating in early access, near zero marketing and the mobile app hasn't even launched yet 🔥
gnumo
4
3
21
862
Story Ecosystem retweeted
May 5
Numo now has 15k contributors with 130,000 rare voice recordings.
growth is inflecting up, with just 4 languages.
we are expanding to additional languages and tasks very soon.
every recording is rights-cleared and licensed onchain from the moment of submission.
21
20
100
7,574
Story Ecosystem retweeted
May 8
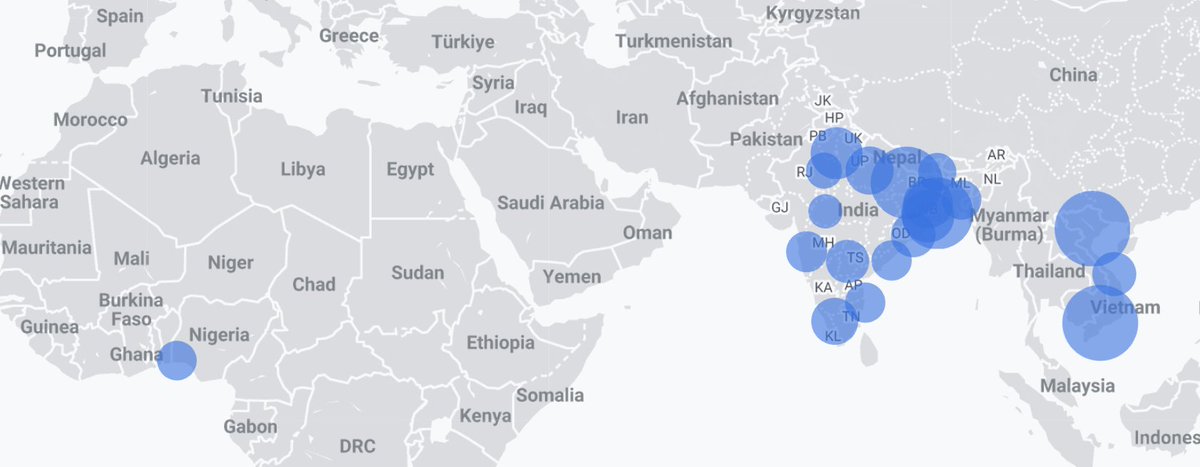
numo is in early access.
there are only Vietnamese and indic languages tasks atm.
you need to be a native speaker in those languages to participate.
some dude in nigeria: hold my bánh mì
13
8
51
2,802
Story Ecosystem retweeted

Apr 29
After incubating @psdnai, our conviction only got stronger:
The data AI needs isn’t on the internet.
Critically, we learned what it takes to collect it: real participation, clean processing, and systems for consent and provenance.
Numo is what’s next. Welcome to early access.
19
11
81
6,008
Story Ecosystem retweeted
Apr 29
today we announce Numo in early access.
voice is the definitive interface for AI (and we are already seeing it with the massive adoption of apps like whisprflow).
but today's voice systems barely work for the billion people who speak underrepresented languages in AI models.
thats why Numo debuts with tasks in bengali, hindi, tamil, telugu... hundreds of millions speak them, but the training data just isn't there compared to the “usual” languages like english, mandarin, spanish etc.
numo fixes the long tail supply side for voices, with plans to expand into other modalities real-world AI needs.
rights-cleared from the first second, all confidentially registered on story, processed through poseidon.
many more tasks to come.
10
5
47
2,200