
Born in Italy, bioinformatician fascinated by non-coding vars. When not at computer, I like traveling, hiking and exploring new food.
Joined June 2009
- Tweets 2,813
- Following 146
- Followers 276
- Likes 372
75 Photos and videos




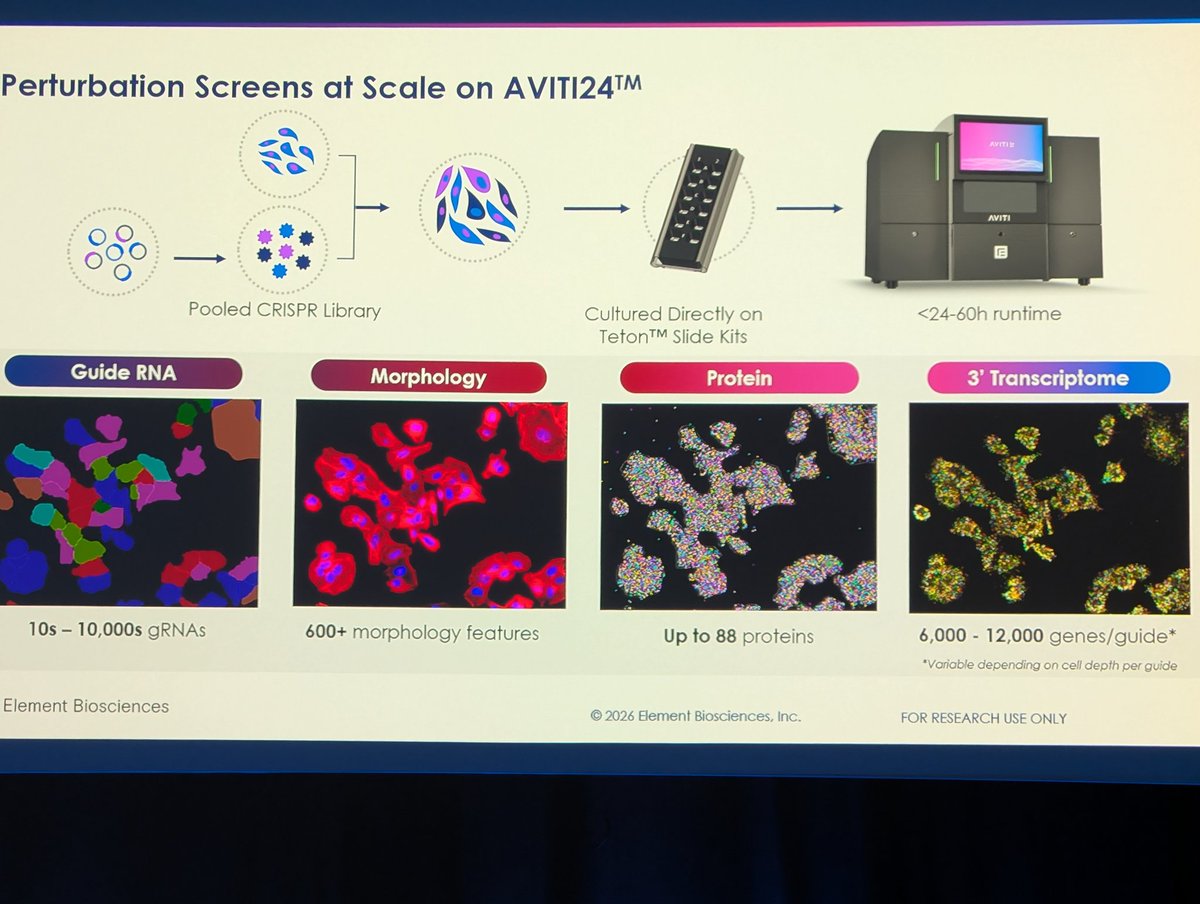
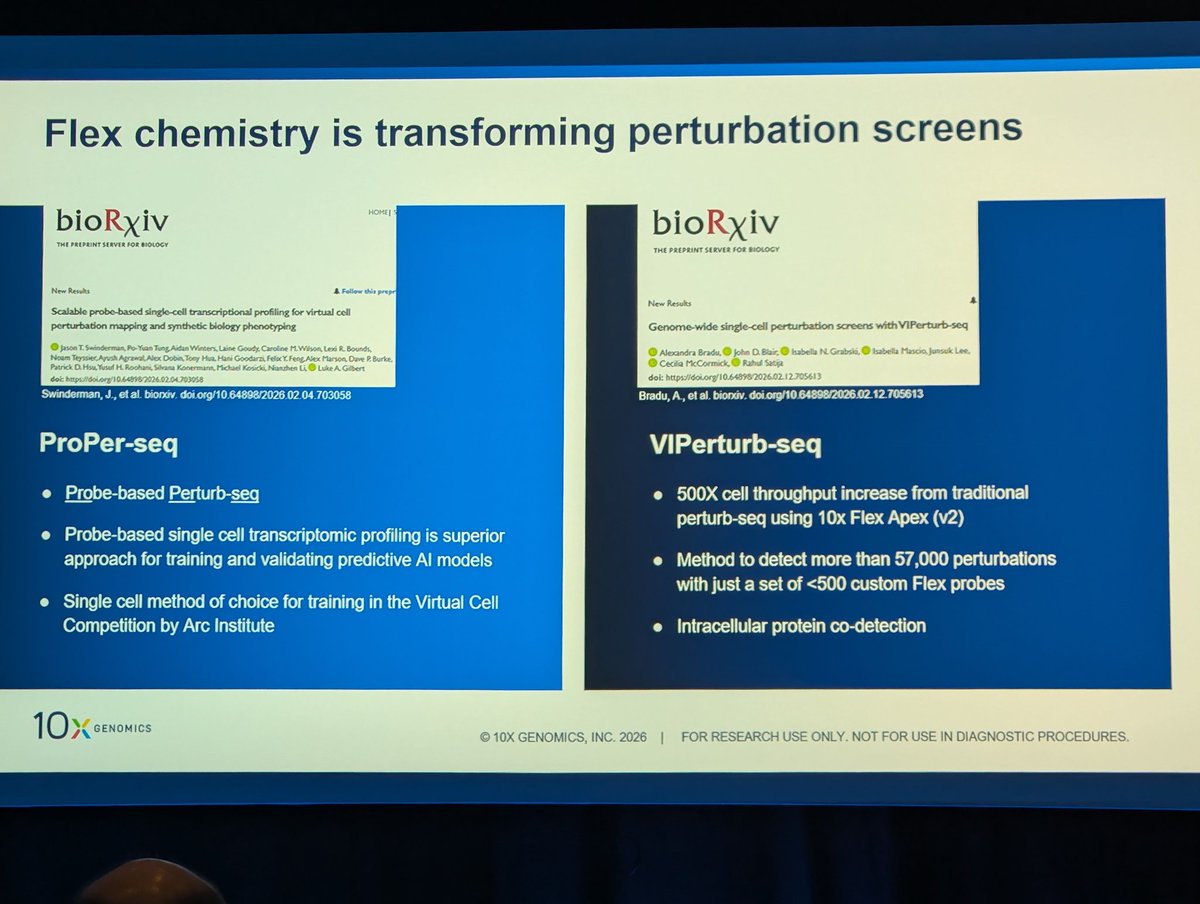
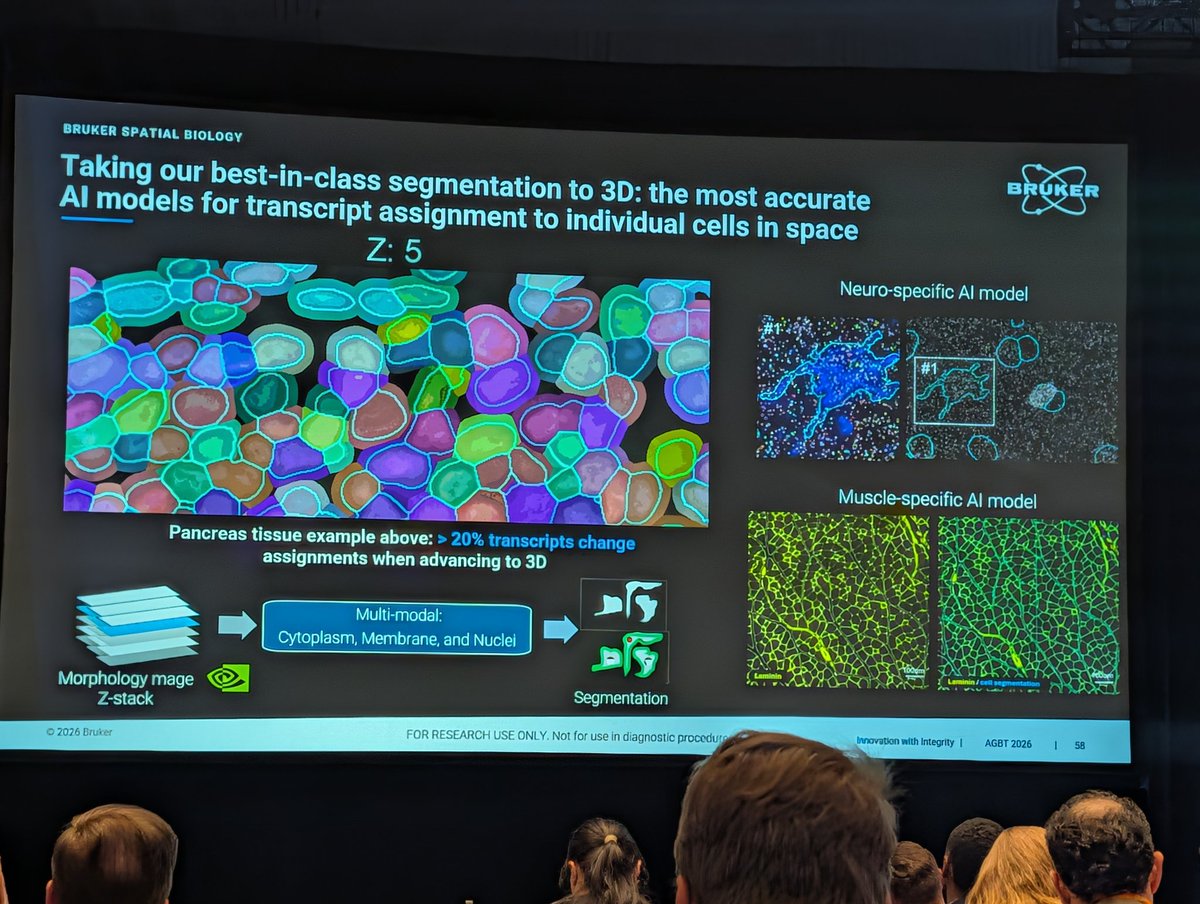
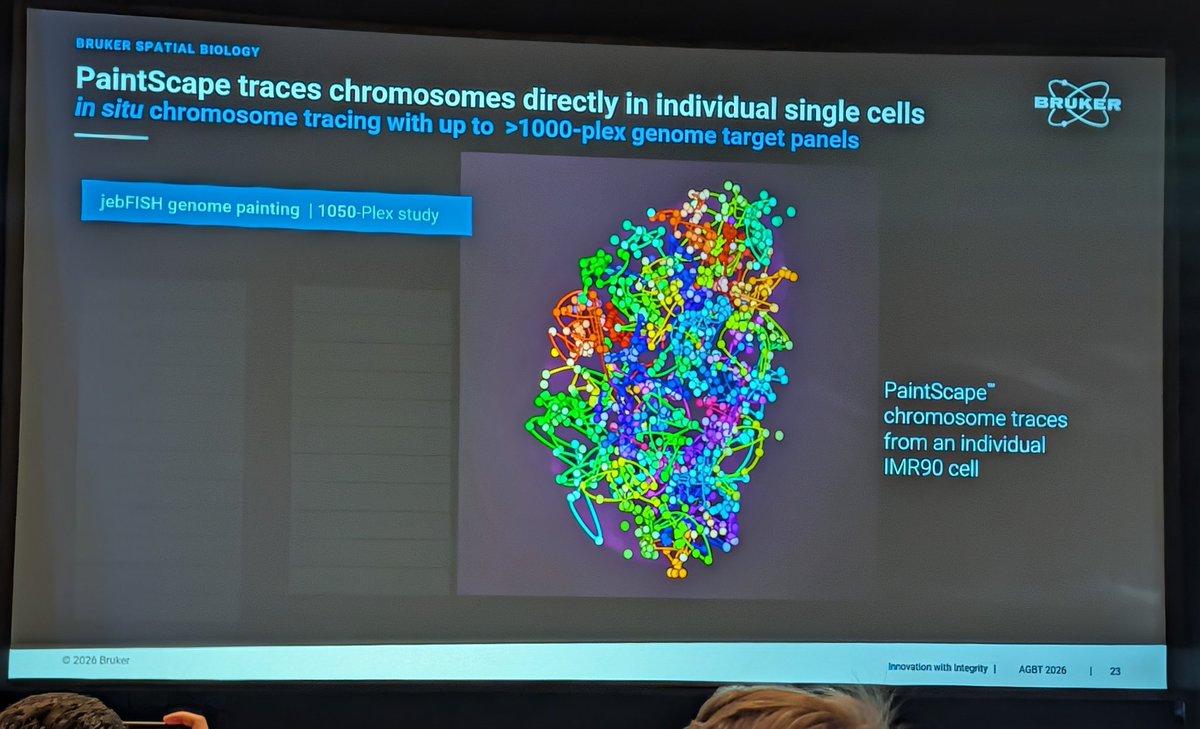
Edoardo Giacopuzzi retweeted

Jun 14
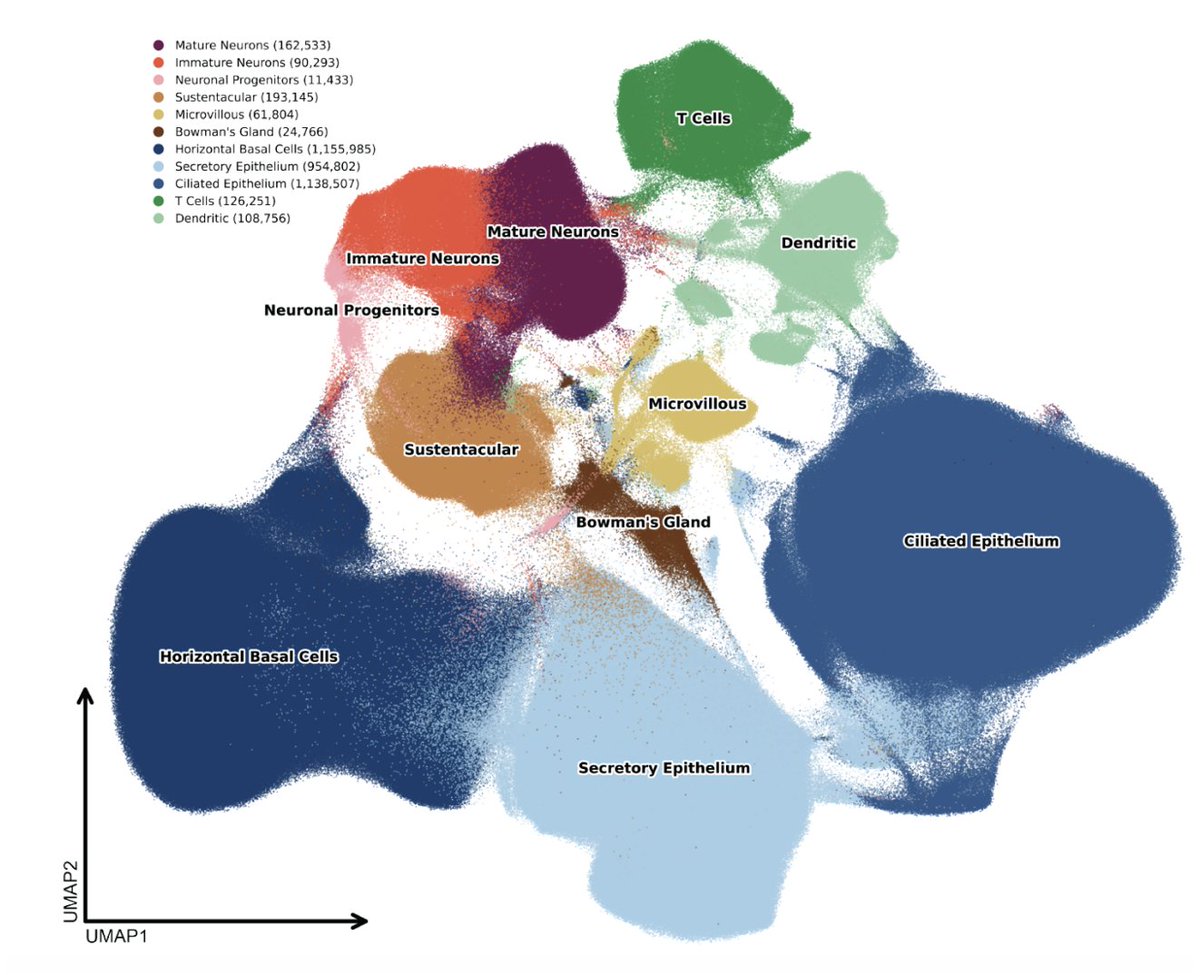
Disease-relevant human tissue is critical for discovering actionable biology, but access is limited to surgical or post-mortem samples, making scaling challenging.
This single-cell dataset is a cool resource of living neural tissue collected from the olfactory epithelium sampled with a new biopsy platform.
It involves 4M cells from 202 living individuals and is open-source to download or browse on CELLxGENE.
1
22
104
12,528
Edoardo Giacopuzzi retweeted

Jun 12
This is really big news. Google introduced the Open Knowledge Format (OKF) - a standardized way to store information in a directory of markdown files. Makes it really easy to make a digital brain that agents can use.
These files can serve as a living wiki. You can give agents the ability to query them or edit them. They can interlink.
Seems to me this could replace Notion or Obsidian. I can think of so many uses for this.
Google's blog post: cloud.google.com/blog/produc…
An easier to understand explanation is the SPEC.md file:
github.com/GoogleCloudPlatfo…
I gave those two links to Antigravity and asked how we could use it for any of the projects we're working on. It came up with so many ideas. I would imagine Claude Fable 5 would whip up some pretty amazing things based on this system.
Currently creating an OKF library of our pepper garden. It's going to be a fun weekend.

167
819
6,704
981,024
Edoardo Giacopuzzi retweeted

Jun 9
No scaling laws for single-cell foundation models: when bigger atlases stop teaching the model anything
In language and vision, the recipe has been simple: more data, bigger models, better performance. Single-cell biology borrowed that playbook. Foundation models for transcriptomics jumped from 1 million cells to atlases of over 100 million, on the assumption that scale would unlock the same gains. Alan DenAdel and coauthors put that assumption to the test, and the result is sobering.
Working from a 22.2-million-cell corpus, they pretrained 400 models across five architectures (from PCA and a variational autoencoder up to the Geneformer transformer) and ran 6,400 evaluation experiments. They varied not just dataset size (1% to 75%) but also diversity, using cell-type re-weighting and geometric sketching to deliberately enrich rare cell types and transcriptional states.
The finding: performance saturates almost immediately. On cell-type classification, batch integration, and perturbation prediction, most models hit their ceiling at roughly 1% of the corpus, about 200,000 cells. Beyond that, adding millions more cells changed essentially nothing. More diversity didn't help. Even spiking in genome-scale Perturb-seq data, to give the models perturbed phenotypes rather than just healthy ones, failed to move the needle. Larger models did score better overall, but they too plateaued early on data.
Two points stood out. Simple baselines (PCA, logistic regression) often matched or beat the transformers. And the strongest model, SCimilarity, won not because of size but because its contrastive training objective is aligned with the downstream task. For single-cell data, what you train on and how you frame the objective matters far more than how much you collect.
This reframes a quiet but expensive habit. In drug discovery, biotech, and any pipeline leaning on cell atlases, the instinct to keep scaling pretraining corpora may be burning compute for no return. The real leverage sits elsewhere: curating high-quality, task-relevant data and matching the training objective to the actual question you're trying to answer.
Paper: DenAdel et al., journal license | doi.org/10.1038/s41592-026-0…

15
93
384
96,071
Edoardo Giacopuzzi retweeted

Excited to share our latest work out today in @naturemethods where we systematically evaluate how increasing pre-training dataset size influences single-cell foundation models and their downstream tasks.
nature.com/articles/s41592-0…
2
23
89
7,182
Edoardo Giacopuzzi retweeted

Jun 9
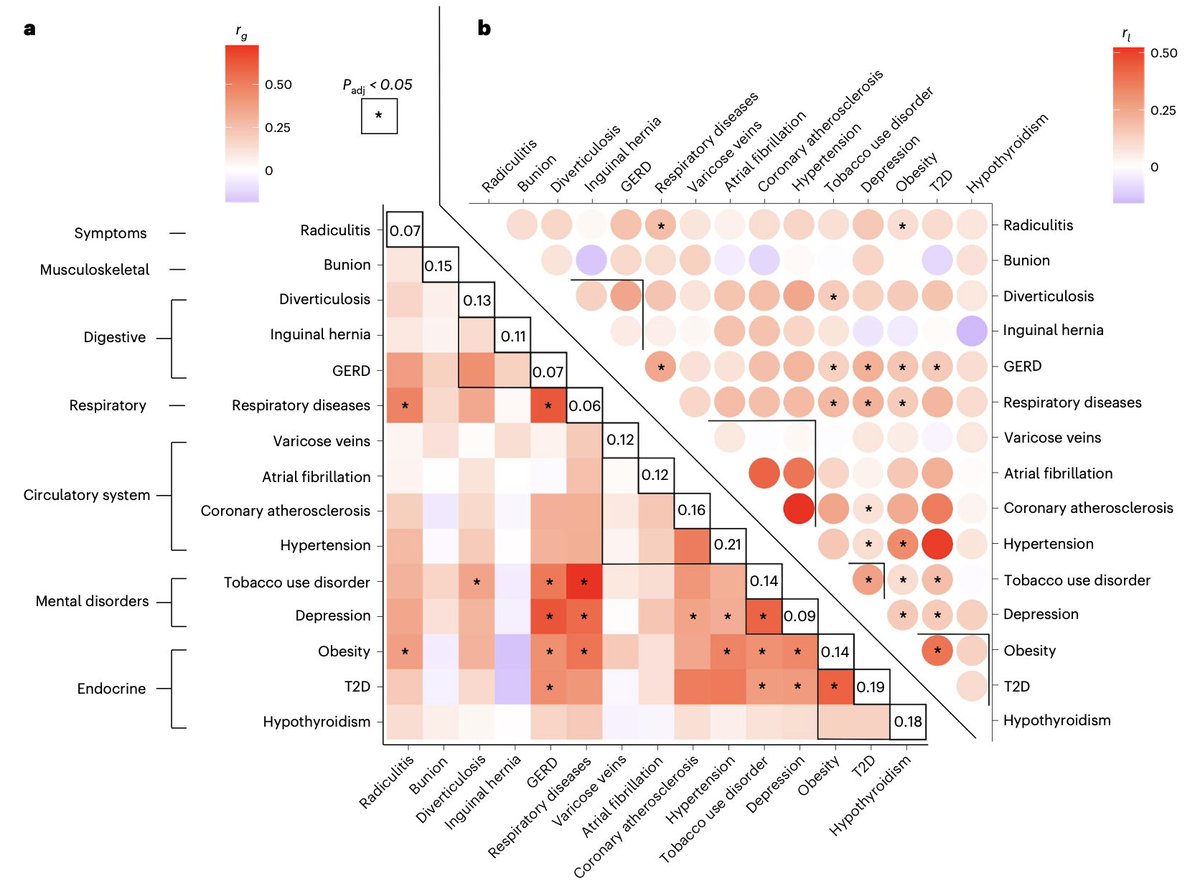
Today in @NatureGenet new paper introduces PHBC -- method for estimating how much of a disease’s SNP heritability is shared with other diseases or traits. Applying it to UK Biobank and GWAS meta-analysis data, the authors find that a large share of common disease heritability is pleiotropic—about 27% across 15 UK Biobank diseases, rising to roughly 48% when more auxiliary diseases and traits are included.
nature.com/articles/s41588-0…
1
27
118
7,881
Edoardo Giacopuzzi retweeted

📣 new preprint multimodal atlas. Imaging scRNA, 57M cells. 🧬🔬
Cells are complex dynamical systems — but most ways we measure them destroy them. We asked: how does live imaging compare to scRNA-seq, the field’s gold std?
The answer surprised us 🧵
biorxiv.org/content/10.64898…

4
55
241
22,494

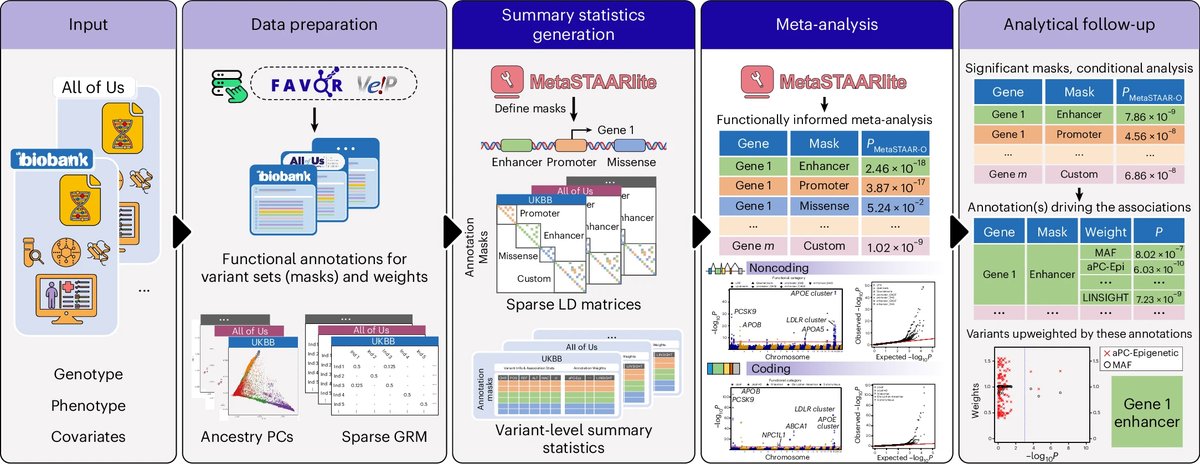
We’re excited to share our latest publication in @NatComputSci “MetaSTAARlite: an all-in-one tool for biobank-scale whole-genome sequencing meta-analysis” 🧬
Sincere thanks to Yohhan Kumarasinghe (UNC, co-lead), Jacob Williams (NCI, co-lead), Yuxin Yuan, Wenbo Wang, @AlexiaDiasF, @AndrewHaoyu, @muzizimumu1, and the study participants from @uk_biobank and @AllofUsResearch.
Biobank-scale WGS/WES studies are transforming rare variant discovery, but pooled individual-level analyses across biobanks are often limited by data-sharing restrictions. MetaSTAARlite is designed to overcome this challenge by providing a scalable, resource-efficient, summary statistics–based pipeline for functionally informed rare variant meta-analysis across the coding and noncoding genome.
MetaSTAARlite provides an all-in-one workflow to:
• Generate resource-efficient study-specific summary statistics, including variant-level summary statistics sparse LD matrices
• Perform functionally informed coding, noncoding, ncRNA, and custom-mask rare variant meta-analysis
• Dynamically incorporate multiple variant functional annotations to improve power and interpretation
• Exactly reconstruct the variance-covariance matrix of score statistics (referred to as the LD matrix), so meta-analysis results closely mirror pooled individual-level analysis
• Account for population structure and relatedness using sparse GRM / mixed-model framework
• Support conditional analysis, Manhattan/QQ plots, and analytical follow-up to identify annotations and variants driving associations
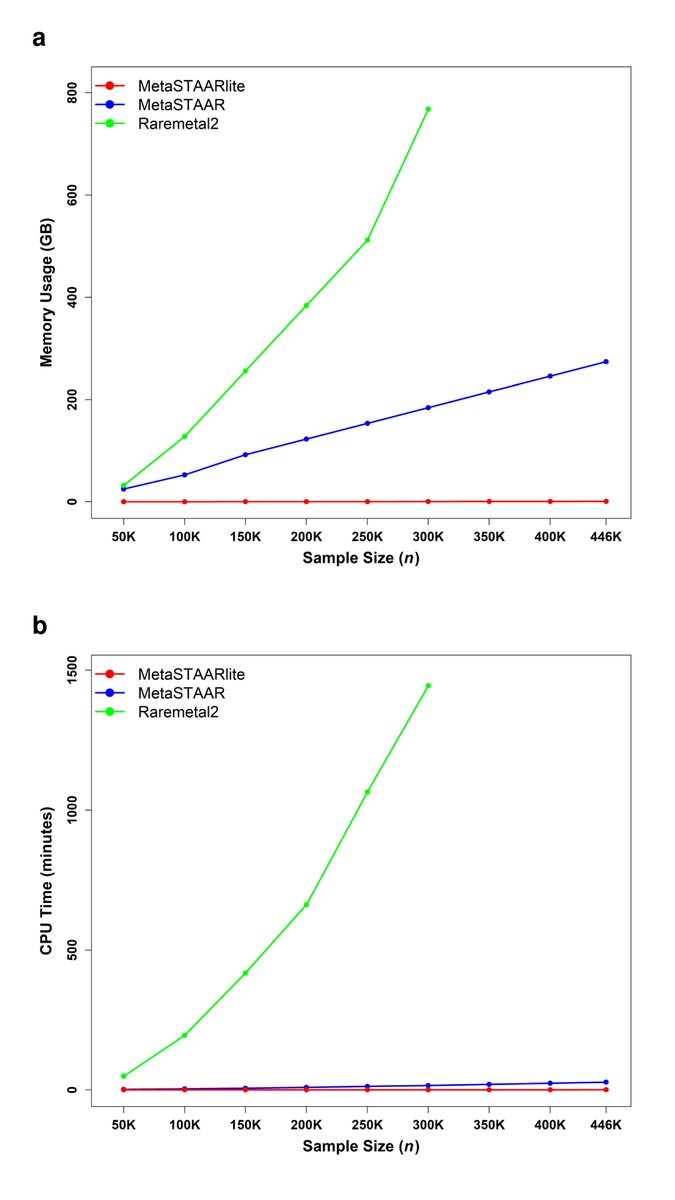
A key advantage of MetaSTAARlite is scalability. By leveraging sparse GRM and directly operating on sparse genotype dosage matrices, MetaSTAARlite greatly reduces runtime, memory, and storage. Benchmarking on UK Biobank WES data for TTN missense variants (the largest gene in the human genome) and total cholesterol phenotype:
• At n = 300K, MetaSTAARlite achieved 332× and 1,386× lower peak memory than MetaSTAAR and Raremetal2, respectively
• It also achieved 24× and 2,206× lower computation time than MetaSTAAR and Raremetal2
• At n = 446K with 22,994 variants, summary statistics generation finished in 48.82 seconds with <1 GB peak memory
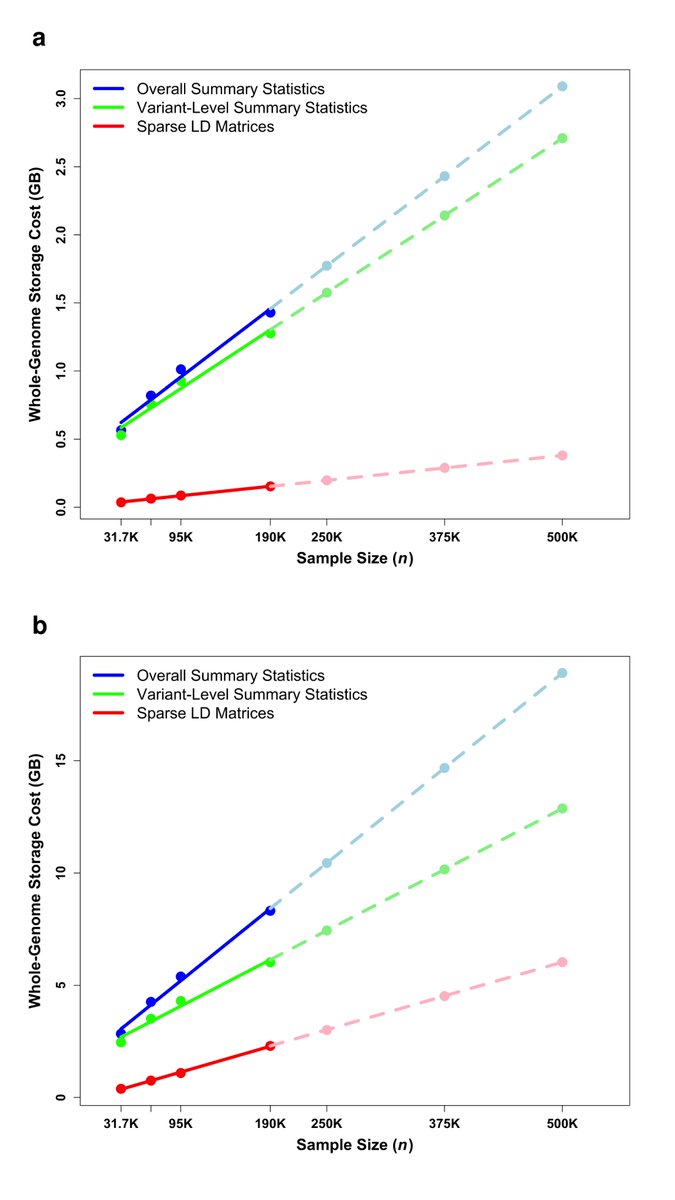
Another important challenge in rare variant meta-analysis is the storage of LD matrices. MetaSTAARlite substantially reduces this burden. In a UK Biobank WGS total cholesterol benchmark, we randomly partitioned 190,110 participants into three studies and generated genome-wide summary statistics with 12 functional annotations. MetaSTAARlite required only:
• 0.48 GB total storage per mask for genome-wide coding meta-analysis summary statistics
• 1.67 GB total storage per mask for genome-wide noncoding meta-analysis summary statistics
Notably, the sparse LD matrices accounted for only 7.7% and 17.8% of the total storage for coding and noncoding analyses, respectively. This means that, in MetaSTAARlite, LD matrix storage is no longer a bottleneck for rare variant meta-analysis.
In UK Biobank WGS total cholesterol analyses, we compared MetaSTAARlite meta-analysis with pooled STAARpipeline analysis using the same individual-level data. The results were nearly perfectly concordant:
• Pearson r² > 0.999 for log10-transformed P values across genome-wide significant and suggestive masks
• 58 genome-wide significant coding associations
• 88 genome-wide significant noncoding associations
• Signals included known lipid biology: PCSK9, APOB, APOA5, LDLR and APOE clusters
We further applied MetaSTAARlite to cross-biobank meta-analysis of UK Biobank (in the Research Analysis Platform) and All of Us (in the Research Workbench) data for five traits: total cholesterol, height, eGFR, calcium and elevated LDL-C (a binary trait). These analyses included up to 692,445 diverse participants. Across these traits, MetaSTAARlite identified 165, 536, 117, 38 and 94 genome-wide significant coding associations, respectively, while keeping average peak memory below 1 GB.
For these cloud-based analyses, in the UK Biobank RAP, for example, the genome-wide summary-statistics generation per trait had theoretical costs of ~£3.60–£3.90 and actual costs typically below £7, never exceeding ~£8.20, for a total of 5 masks across the genome.
We hope MetaSTAARlite will make cross-biobank rare variant discovery more accessible, scalable and privacy-preserving for large WGS/WES consortia.
Software and tutorial are open source:
Paper: nature.com/articles/s43588-0…
MetaSTAARlite: github.com/li-lab-genetics/M…
Tutorial: github.com/li-lab-genetics/M…
Manuscript code: github.com/li-lab-genetics/M…


📢Out now! @xihaoli, @muzizimumu1, @AndrewHaoyu, and colleagues present an all-in-one pipeline for computationally efficient meta-analysis of multiple biobank-scale whole-genome/whole-exome studies. nature.com/articles/s43588-0…
🔓rdcu.be/fmkDd
2
10
41
3,929
Edoardo Giacopuzzi retweeted
Jun 4
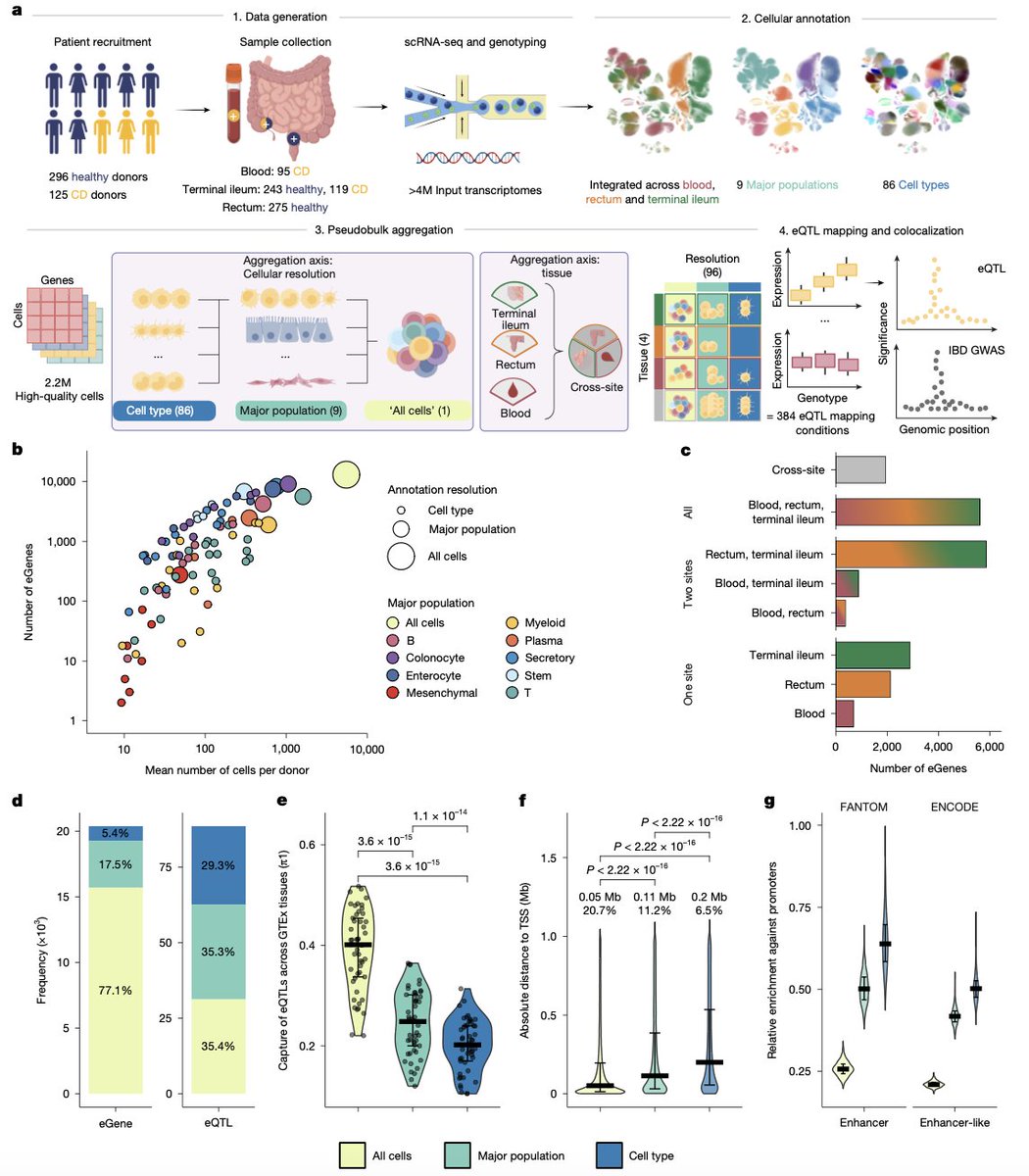
🧬To better understand genome wide association studies we need to look beyond tissues and zoom in on individual cell types.
A remarkable @Nature study shows that eQTLs detected in specific cell types explain IBD GWAS signals better than eQTLs detected in pooled cells or broader cell populations.
The authors built IBDverse — large single-cell atlas based on scRNA-seq from blood, rectum and terminal ileum. The cohort included 421 people, including 125 patients with Crohn’s disease. After quality control, the analysis covered nearly 2.2 million single cells with matched genotypes from 396 people.
Cell type eQTLs were more often located far from transcription start sites, enriched in enhancers rather than promoters, less likely to regulate the nearest gene and more than 3.5 times more likely to colocalize with IBD GWAS loci than lower resolution eQTLs.
This matters because GWAS signals often sit in enhancers. Single cell data can therefore get closer to disease relevant biology.
The authors nominated likely effector genes for 180 of 321 known IBD loci (56%). For 74 loci this was the first effector gene nomination compared with previous eQTL annotations in Open Targets Genetics.
The study also reframes IBD as more than an immune disease. If the epithelial barrier renews or repairs poorly, the gut becomes more vulnerable. Inflammation may then be not only a cause of tissue damage but also a consequence of weak tissue repair.
#IBD #GWAS #scRNA #eQTL #colocalization
nature.com/articles/s41586-0…
19
83
5,151
Edoardo Giacopuzzi retweeted

Jun 4
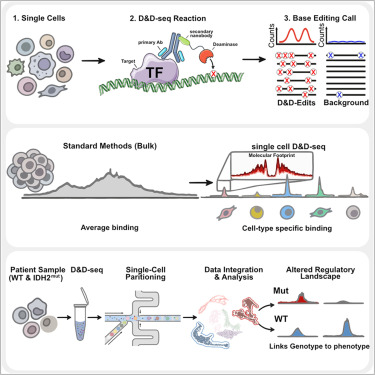
Exciting breakthrough technology from the lab, now live in @CellCellPress ! Instead of cutting the genome where proteins bind (e.g., Cut&Tag), D&D-seq scars the DNA with a deaminase, allowing single cell genome mapping of TFs and chromatin remodellers!
17
169
647
53,152
Edoardo Giacopuzzi retweeted
Jun 2
🧬 A beautiful @NatureGenet paper on how to handle polygenic risk more carefully in family-based data.
The core idea is to compare a child not with random people, but with the genetic set they could have inherited from their own parents. This better protects against population stratification, geography, social structure, and assortative mating.
The authors introduce PGS-TRI, a method that estimates not only the direct effect of the child’s PGS, but also gene–environment interactions and asymmetric indirect effects of maternal and paternal genetics.
For the educational-attainment simulations, the authors used UK Biobank to create a realistic confounded setting with geography, BMI, and assortative mating. Standard regression became biased, while PGS-TRI stayed well calibrated.
In real autism trios, the method found a direct polygenic effect close to previous case–control estimates. It also showed that the score’s effect declines smoothly with genetic distance from the European training population.
nature.com/articles/s41588-0…
#Trio #PopulationStratification #Autism #PRS #PGS

26
94
6,384
Edoardo Giacopuzzi retweeted

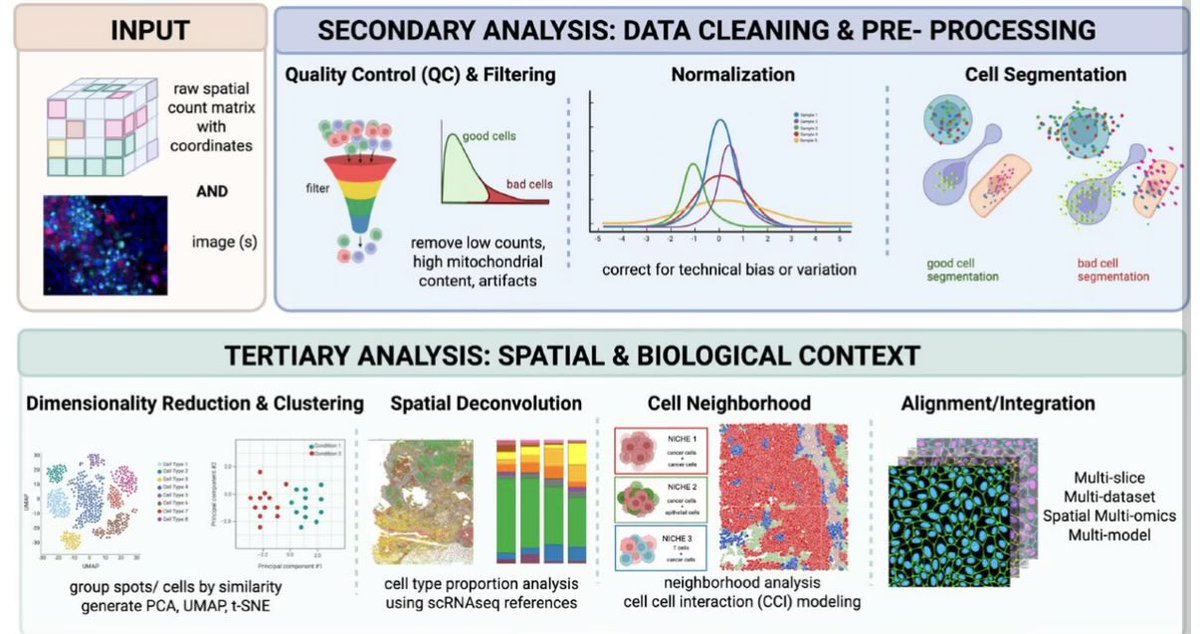
Drop it like its 🔥 ... Hot of the press.. #spatialomics review of all things #computation
For pros or new adopters to #spatialtranscriptomic & #spatialproteomic analyses.
Our comprehensive guide to software tools currently used in the field. sciexplor.com/exo/articles/E…
1
14
46
5,254
Edoardo Giacopuzzi retweeted

OpenSplice: the impact of half a million mutations on the alternative splicing of 600 human exons #RareDisease #Genetics biorxiv.org/content/10.64898…


2
43
182
13,666

Nature research paper: Distinct genetic architecture in the tails of complex traits
go.nature.com/4v6KGUa
3
59
185
30,543
Edoardo Giacopuzzi retweeted

May 28
1/5
Cell identity is written in the proteome, not in the DNA, and not always in the RNA. Out on bioRxiv today: The first cell type-resolved, MS-based proteomic atlas of the human body.
biorxiv.org/content/10.64898…
5
88
352
34,187

Excited to share Decima, out now in @naturemethods! 🎉
Existing seq-to-function models predict bulk expression. Decima goes further: it predicts gene expression in specific cell types and disease states from DNA sequence alone — trained on 22M single cells.
Applications: cis-regulatory mechanisms, cell-type-resolved variant effect prediction, and designing context-specific regulatory DNA
3
22
145
13,761
Edoardo Giacopuzzi retweeted
May 23
This preprint and accompanying browser provide another fantastic resource for exploring causal biology, with genotype–phenotype associations for both common and rare variants across 3,602 traits in the All of Us cohort (N=392,030)!

2
27
120
9,550
Edoardo Giacopuzzi retweeted
May 23
🧬Another ~1% step toward closing the missing heritability gap.
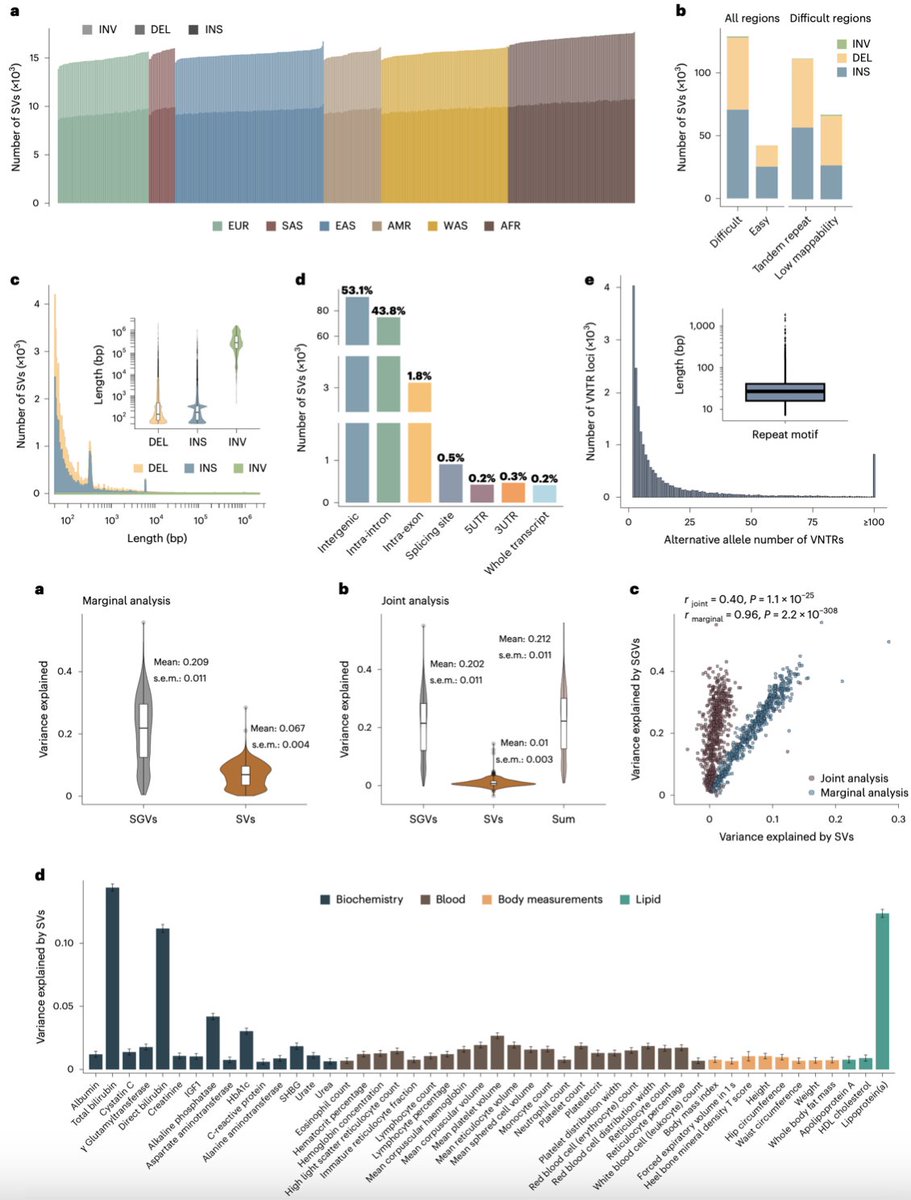
When we talk about genetic variants, we usually mean single nucleotide substitutions, or SNPs. But every human genome also carries ~25,000 structural variants, including insertions, deletions, inversions and other rearrangements of DNA segments ≥50 bp. These variants are one plausible contributor to missing heritability: the gap between heritability estimated from family and twin studies and what we can explain from measured genetic variants.
In this @NatureGenet paper, the authors built a catalogue of 171,233 high-quality structural variants from long-read, haplotype-resolved assemblies of 241 genomes. They then created ImputeSV, a pipeline to infer SVs from SNP data, and applied it to UK Biobank. The result: 54,578 common SVs imputed in 456,643 participants of European ancestry.
For some biomarkers, the contribution was substantial. In a joint model with small variants, SVs explained ~14% of variance in total bilirubin and ~12% in lipoprotein(a).
A particularly elegant part is variable number tandem repeats, or VNTRs. These behave like a genetic volume knob. For example, a VNTR in GGT1 showed a length-dependent association with γ-glutamyltransferase, a liver enzyme used as a marker of hepatobiliary function.
Overall, the authors found 17,335 SV–trait associations, including 958 loci unlikely to be explained by nearby SNPs alone.
Importantly, the authors released an imputation resource. This means existing SNP-based cohorts can now be re-analysed for SVs and VNTRs without long-read sequencing every participant.
nature.com/articles/s41588-0…
#GWAS #StucturalVariants #Imputation #VNTR
2
32
134
9,053
Edoardo Giacopuzzi retweeted
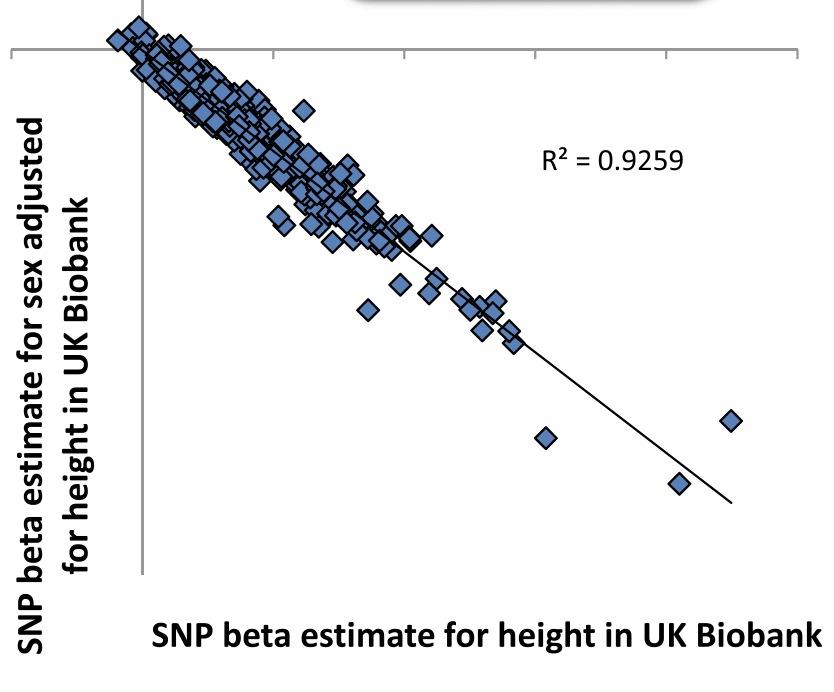
Collider bias can also influence genetic associations.
In a nice illustration, if we take height-raising SNPs and test their effects on sex (which should be null), then adjust for height, we obtain spurious associations with female sex.
Conditioning on a collider (height), associated with both the tested SNPs and sex, induces an association between the two.

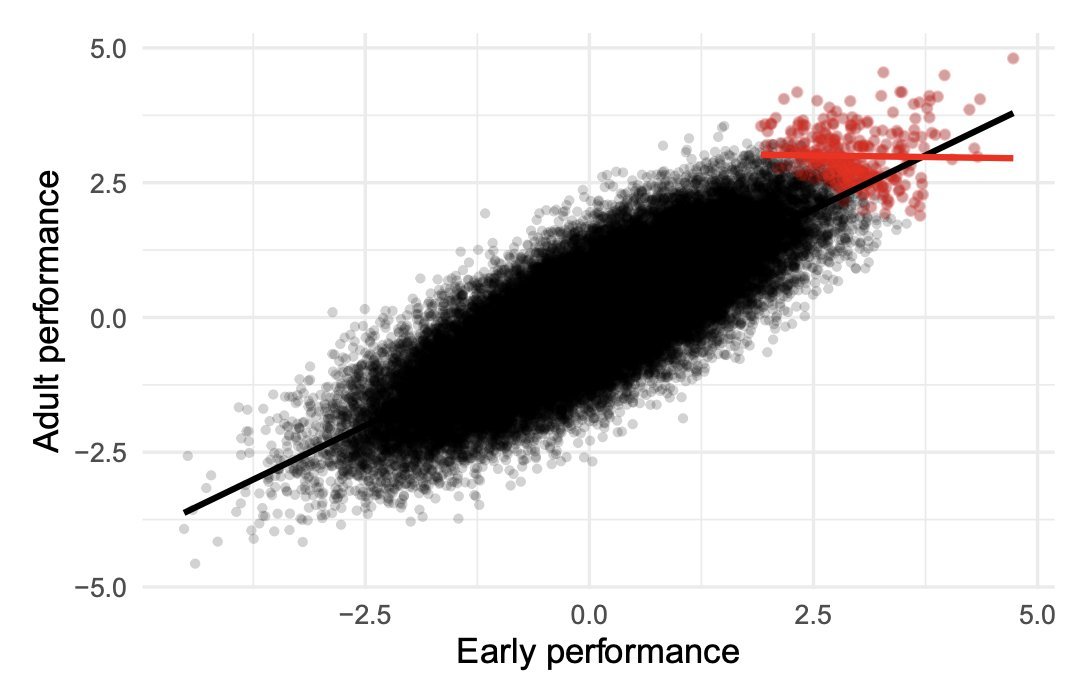
Among elite chess players, those with the lowest IQ are the best.
Among NBA players, the shortest ones are the best.
Among Hollywood actors, the least attractive are the most talented.
Among elite academics, those with poorer early academic performance are the best.
Among people with high LDL & high plaque burden, LDL is barely correlated with plaque burden.
Learn collider bias. Nice catch by @AlexTISYoung
3
23
220
52,202
Edoardo Giacopuzzi retweeted

May 21
This is very impressive.
nature.com/articles/s41586-0…
1
24
133
15,014
Edoardo Giacopuzzi retweeted
May 21
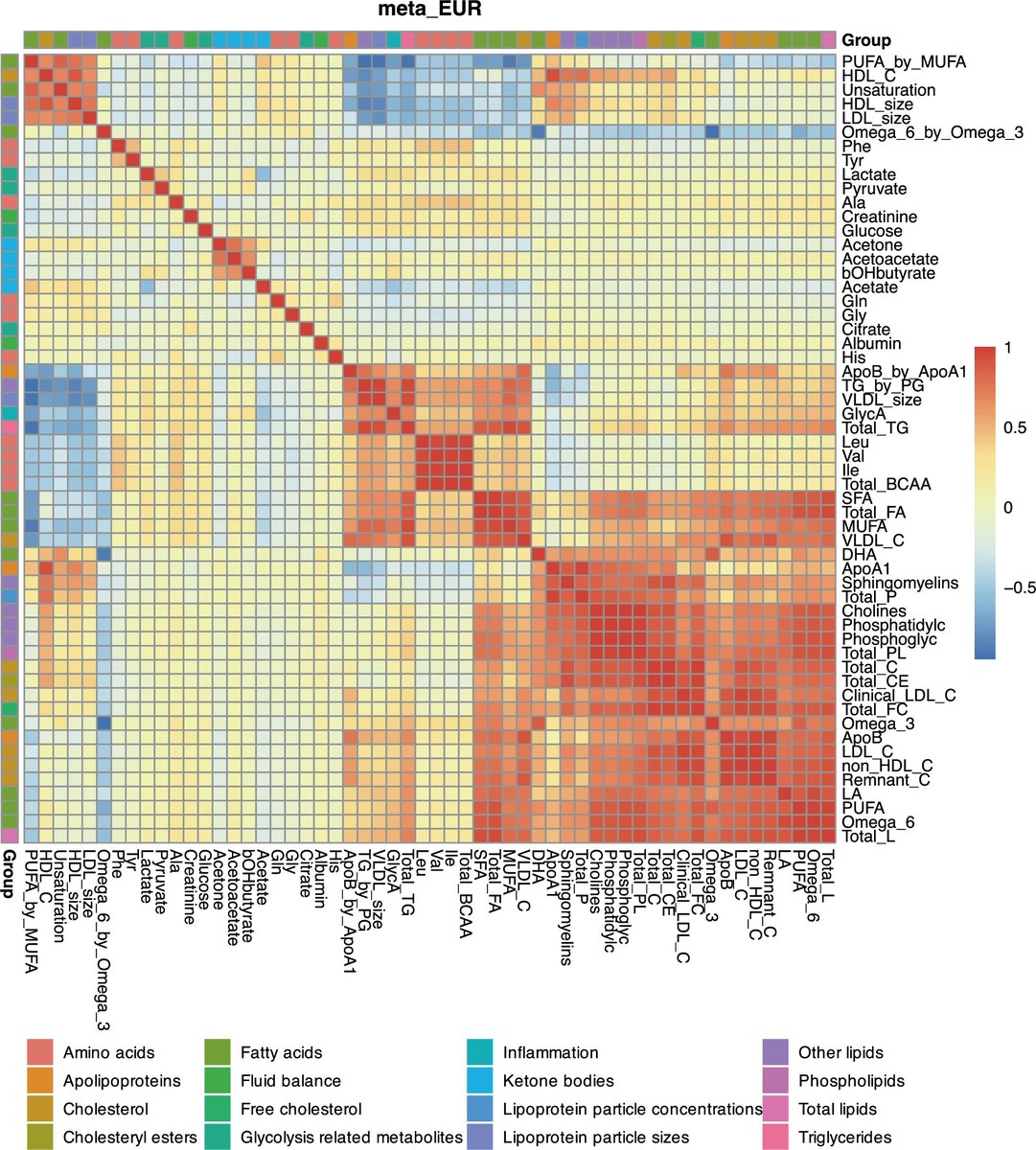
A new amazing resource for drug target explorations with genomic data was released today @Nature:
A massive meta-analysis GWAS for 249 NMR-quantified metabolites in UK Biobank and Estonian Biobank across 619,372 individuals👇
2
66
287
35,365