
Joined May 2024
- Tweets 1,102
- Following 44
- Followers 25,529
- Likes 1,169
134 Photos and videos







Pinned Tweet

Jun 10
You can now run supermemory locally.
Just one command - npx supermemory local
Open source binary, available now - git.new/memory
Jun 10

You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
2
4
36
15,437
supermemory retweeted
Love this article - Satya talks about building "token capital" - or organisational learning to turn workflows and tasks into AI systems and loops.
Why doesn't it exist today?
This is (and will be) an unsolved problem - requiring great research, infrastructure AND product work. also what we're doing at @supermemory right now. (I personally have been working on this problem for years now!) and i'm glad people are talking about it now!
1/ Research
No one knows the right "winning" architecture to build something like this. There is no right answer. There are no deterministic good benchmarks.
for the AI system has to learn and improve over time - It has to have an understanding of time, how the world evolves and connect the dots just like humans do. It would have to infer or "reason" through knowledge. It has to forget things as well.
This article talked about building evals specific to your org - We believe this is the right way! We have been building a framework to easily evaluate systems on any setup (Git.new/membench) and also a dataset for long horizon organizational data (smfs.ai/research). A lot of our customers have set up evals that matter to them.
It does not matter if it's graph vector etc - customers don't care. This system should be composable to whatever use case the enterprise wants, and something they can build on / amend.
2/ Infrastructure
It's not just about having a huge vector store. Every raw document / item can amount to hundreds or thousands of interconnected knowledge, that's also being dreamt on and new knowledge being evolved from it.
The model that actually makes the learning also can't be too expensive. it can't even be 50% of the main model! Because this model will be looking at everything and choosing what to learn. So there's also a lot of distillation / inference engineering involved there.
At @supermemory we solve these by building our own data systems and a model that is doing the learnings. We have a fact based temporal graph that also ensures that everything is properly attributed and traceable.
3/ Product
For people building on top of supermemory, we have to make it completely hackable and composable for every use case.
Complex organizations have different permissions structures - And different data sources to learn from. Different things to learn.
They also have different ways of bringing it back to the agent - Sometime it will be "implicitly" given, or the agent may "explicitly" look up data.
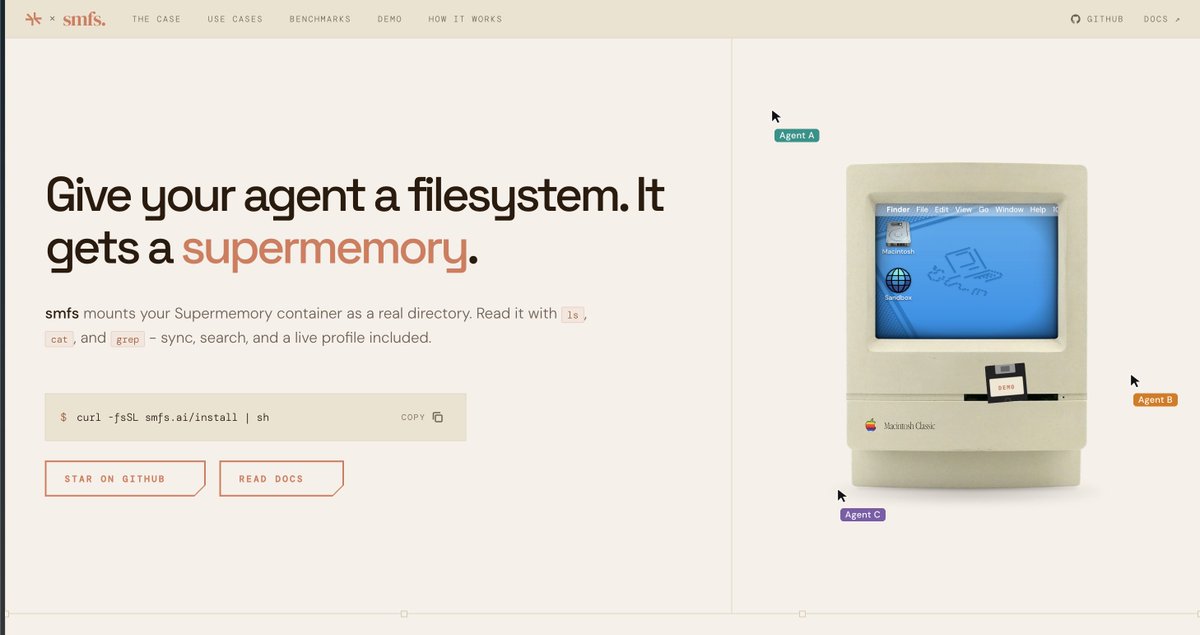
Maybe you want to give that data as @karpathy LLM wiki (filesystems) style!
For this we have built all permission system and controls into supermemory. It's natively multi tenant, and queryable deterministically (as SQL) at the same time.
You can also use it as a filesystem! We bring the knowledge as needed to the agent . We call it SMFS.ai
------
We are trying to build the best memory and context system for AI so that organizations can build their own token capital!
This is a hard unsolved problem and an important one to solve.


8
4
36
8,928
supermemory retweeted
supermemory at @superai_conf 🇸🇬
asia's biggest ai event.
~ 10k builders, 1500 ai companies on the floor
~ 150 speakers across 6 tracks (frontier models, ai infra, robotics, finance, biotech, policy)
~ $2.3m startup competition with openai microsoft credits
~ 36-hour hackathon running at the same time
~ openai, google, microsoft, weka, snowflake, stripe, mistral all on the partner list


2
5
93
5,141

WOW! The memory upgrade my @openclaw needed.
Just had Clyde 🎸 install @supermemory for me.
MEMORY.md — down from 11,706 → 3,105 chars
Here's the shift in thinking: the old MEMORY.md was trying to be the memory. Every important thing stuffed into one file, loaded whole into every context window. That's expensive and it degrades — more sessions, more bloat.
The new architecture:
• MEMORY.md = boot primer only. Who you are, session rules, project pointers, key names. Enough to orient me in 3k chars.
• Supermemory = the actual memory. Everything from our conversations gets semantically indexed. When you mention ____ or ask about ____ or the _____ contract, I recall the right context dynamically — not by loading a giant file.
• TOOLS.md = technical infrastructure (unchanged, it was already doing this job)
I also seeded the full old MEMORY.md and TOOLS.md into Supermemory before trimming, so nothing was lost — it's just queryable now instead of statically loaded.
And you're right about what this becomes over time. Every conversation adds to the index. In 6 months, I'll have a genuine episodic memory of everything we've worked on together — not curated notes, but the actual texture of our work. That's a qualitatively different kind of continuity.
Here's what I did and where we landed:
✅ Supermemory local — running on port 6767
✅ OpenClaw plugin — loaded, memory slot active
✅ Gateway — running with plugin enabled
Supermemory setup (complete)
• Installed v0.0.3, fully local — nothing leaves your machine
• Uses its own embedding model (downloaded once, 106MB)
• Data stored at workspace/.supermemory (persists across reboots)
• launchd keeps it alive — same pattern as Chrome CDP and Bonsai
• OpenClaw plugin wired in: autoCapture autoRecall both on
• Every conversation I have with you now gets indexed automatically
• Before each turn, relevant past context gets injected
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
4
4
41
7,197
supermemory retweeted

Jun 13
Implemented an Obsidian Plugin which will sync up all my notes to @supermemory local so that my agents can have direct access to my notes
Thanks!! @DhravyaShah and team for open sourcing it.
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
3
4
25
10,139



supermemory retweeted

Jun 11
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
24
10
111
27,297
supermemory retweeted

Jun 11
EVERY. SINGLE. ONE of you should build an AI data system that isn't reliant on a singular model.
The solution: Portable memory and context.
Create a system where you can plug in the same data to any LLM.
I personally coded a system using Claude @supabase (other options are @supermemory, @Firebase - and a few others).
Every time I prompt AI about myself/business, it updates my memory database on the cloud.
So whenever I switch models, my data is 100% plugged in. No more reliance on a singular model. I own my own data.
Jun 10

At this point every CEO should be asking what their strategy is to avoid model lock-in.
If it isn’t clear what Anthropic is doing, it is:
- build something amazing
- decide who gets to use it after you prompt it if the prompt falls into areas they deem unacceptable by their sole standard
To be clear this is completely above board and legal. It’s just an idiotic risk for corporate users to bear especially as the coding models become equivalent.
The business continuity risk will become more obvious as companies accidentally trip over Anthropic’s ToS and have to decide if they will subsume their business viability to them by doubling down on Anthropic models or find open source (and, btw, much cheaper) alternatives where they are in control.
As stated previously, get ready to be inundated with the term “control plane” which is the natural solution to this problem.
Shameless plug - this is what 8090’s been building as we expected this moment to arrive…
If you’d like to learn more: 8090.ai
20
10
154
28,895
supermemory retweeted

Jun 10
Career update: i'm joining @supermemory to lead Dev GTM.
supermemory is the memory layer for AI products, we got the best public results on AI memory by a wide margin, 95% on the leading benchmarks.
my role will be to make it easy for everyone to use. demos, walkthroughs, educational content, and the cleanest possible path from "i need memory in my agent" to shipping.
pumped to be working with the coolest team
oh, and the team just shipped supermemory local. fully self-contained, open source, runs on any machine in a minute!!
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
131
22
814
108,169
supermemory retweeted

Jun 11
He sold a company at 16. Then raised $3M at 19 without a co-founder.
Today he gave the whole thing away.
@supermemory now runs fully local, self-contained, and the binary is open source.
Solo Founders Podcast ep 14 is live with @DhravyaShah of Supermemory.
00:49 How a side project became a company
08:57 "Building was my way of doing art"
14:35 Saying no to VCs for 9 months
24:44 Launching Supermemory Local
29:29 Killing his own viral hit, mid-fundraise
46:39 Why ChatGPT "fails" memory benchmarks on purpose
52:57 The co-founder breakup that made him go solo
01:10:19 The case for solo founding
33
71
1,270
134,142
supermemory retweeted

Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
148
95
1,736
565,766
supermemory retweeted

Jun 10
The best agent memory is now local. No excuse not to give your agent its own brain.
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
1
2
16
4,967
supermemory retweeted

Jun 10
there is no reason to not be using supermemory now
setup takes less than a minute
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
2
3
49
10,224

10/10 crazy
review after using it in prod coming shortly
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
1
2
16
3,902
supermemory retweeted
Jun 10
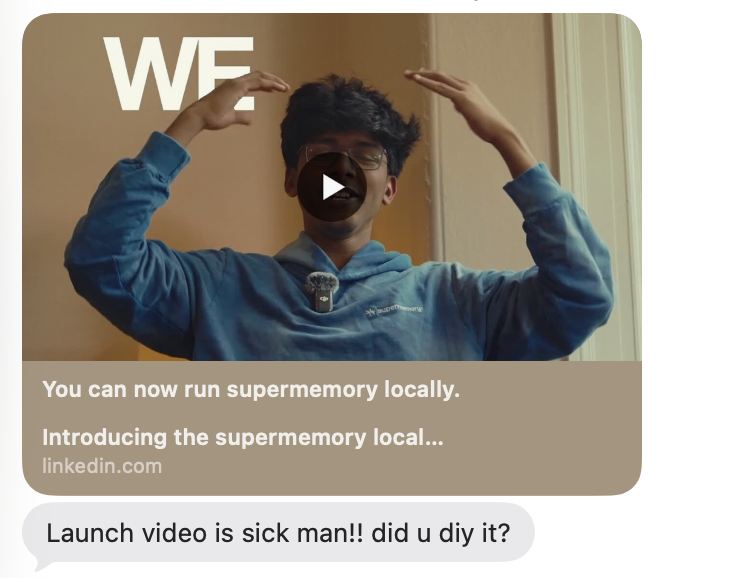
We do our launch videos in house. And this one was done within literally 2 days and barely 10 mins of actual recording 💅
Jun 10

Sick editing!
How’d u do it
6
2
73
6,307
supermemory retweeted

Jun 10
our finance team watching @DhravyaShah giving away self-host for FREEEEE
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
5
5
102
26,519
supermemory retweeted
Jun 10
supermemory is the only fully local memory and context infrastructure.
and you can truly do any context work with it.
Memory, Retrieval, Filesystems, Extractors, Profiles.
Everything. can be run local and free now
Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
5
13
165
26,095
Jun 10
Supermemory is now on @stripe projects!
- Quickly setup and provision resources
- Easy payments and API keys
- One command to set up
stripe projects add supermemory/memory

New providers now available on Stripe Projects:
@Wix
@laravelphp
@HeyGen
@prisma
@automattic
@p0
@ExaAILabs
@Base44
@ClickHouseDB
@supermemory
@usekernel
@blaxelai
@getmetronome
@AgentPhoneHQ
@e2b
@postalform
4
4
18
4,962