
TStat offers biostatistic, econometric and statistical training and statistical consultancy to researchers and professionals in the private and public sector.
Joined August 2014
- Tweets 650
- Following 226
- Followers 388
- Likes 126
269 Photos and videos














May 19
FIRST CARPATHIAN STATA CONFERENCE - 27 JULY 2026 - Cluj-Napoca, Romania.
Calling all our @Stata users in #Slovakia and #Slovenia — submit your abstracts and share your work with an international community of #Stata users. This is a great opportunity to present your research, exchange ideas, and connect with fellow Stata researchers across the region.
Submit your abstract by 30th May to be part of the inaugural Carpathian Stata Conference! More info @ bit.ly/4nXhRrb
#Stata #DataScience #Econometrics @PublicHealth #Epidemiology #Conference #Research #CarpathianRegion
1
1
806
We are delighted to announce the first Greek Stata User Meeting 🇬🇷 📍Athens | 🗓27–28 January 2027 at the AUEB.
The conferences represents a new forum for Greek Stata users across academia, research & government to share research and ideas. Info at bit.ly/4w72fos
1
2
7
882
The conference will feature presentations and discussions showcasing new #Stata commands, applications, and research. Together with Tips and Tricks to elevate your Stata experience. A space to exchange ideas and strengthen collaboration across the Stata community.
1
1
76
Day 2 will be dedicated to our conference workshop Automating Your Research in Stata. A unique opportunity for doctoral students & early-career researchers looking to strengthen their Stata programming skills. Workshop leader: Giovanni Cerulli (IRCrES-CNR, Rome)
1
64
25 Sep 2025
Combining native Stata capabilities with Python-enhanced workflows, Carlo Drago offers an accessible and policy-relevant toolkit for unsupervised text classification in multiple domains. This applied text mining & clustering framework enables users to classify & interpret text
1
1
89
25 Sep 2025
to implement hierarchical clustering using TF-IDF vectorization & cosine distance. Allowing users to identify patterns on data, uncover latent themes & organize information for macroeconomic forecasting, sentiment analysis, or real-time policy monitoring. bit.ly/42bAyxD
70
25 Sep 2025
Loreta Isaraj illustrating automated data extraction from unstructured textual sources using a scalable fully integrated workflow employing Large Language Models (LLMs), specifically @ChatGPT 4.0 via @API, in conjunction with @Python & @Stata. Details @ bit.ly/481VM4C
98
25 Sep 2025
Covariate selection is performed through a Lasso-based local estimation, ensuring valid inference under approximate sparsity. The command generates output variables that can be used for further post-estimation analysis within the same session. More @ bit.ly/3KdQY2n
37
25 Sep 2025
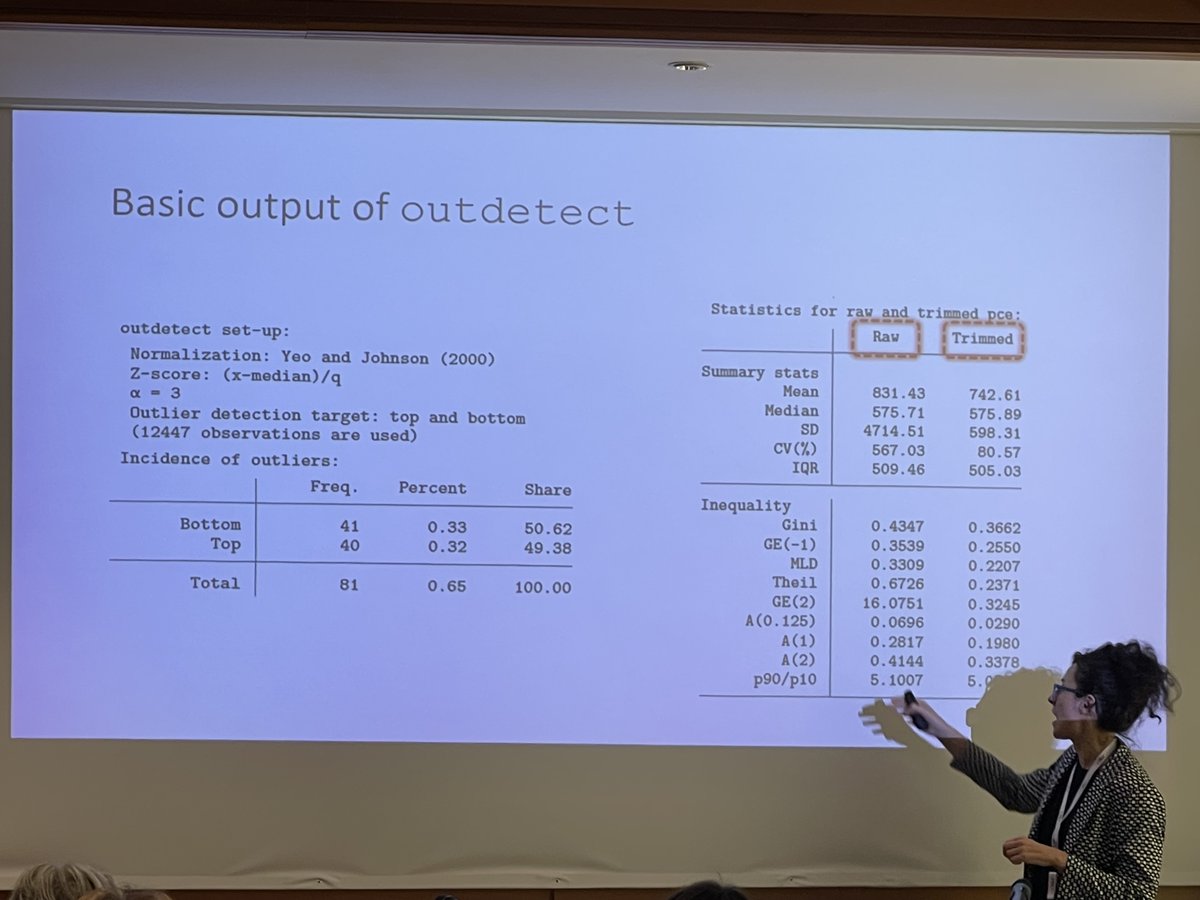
The new @Stata command outdetect by Giulia Mancini et al., offers researchers faced with extreme values in #surveydata a simple univariate detection procedure, with useful diagnostic tools for #sensitivityanalysis, for outlier detection. Detailed info @ bit.ly/48EXJEe
1
105
25 Sep 2025
Are you trying to group data into sets of similar observations without relying on predefined labels? Then Carlo Drago’s work on consensus clustering in @Stata 19 is likely to be of interest. Carlo’s approach combines bootstrapped k-means with hierarchical clustering based on a
1
37
25 Sep 2025
co-association matrix, which allows @stata users to address the possible inherent instability of partitioning-based #clustering by aggregating results from multiple #bootstrap samples, improving robustness and reproducibility. Carlo uses a combination of existing Stata routines,
1
25
25 Sep 2025
bootstrap sampling, and optimized #Mata routines to compute the co-association matrix, ensuring computational efficiency.. Download Carlo’s presentation @ bit.ly/4gJO8OE
26
25 Sep 2025
Maria Elena Bontempo illustrating how her NEW flexible panel data command pantarei extends the existing commands xtsum & loneway to consider, amongst other things, the role of CCE inside the within variability. Presentation at bit.ly/4gGHgBt
1
41
25 Sep 2025
Working on #EventfHistory (#SurvivalAnalysis) in @Stata? Then David Bussi’s splitting command, stsplit, will facilitate the breaking of your time axis into episodes in order to include time-varying covariates in your analysis. Command details at bit.ly/4pDmZRu
1
57
25 Sep 2025
Jan Ditzen's panel data xttools suite of commands opening our Tips & Tricks session this morning: xtpcaget obtains principal components from multiple variables; xtplot2 identifies panel structure for variables
1
43
25 Sep 2025
xtcorri calculates unit specific correlations or covariances. More details @ bit.ly/4nwFFRi- Commands available on request!
26
25 Sep 2025
& xtcorri calculates unit specific correlations or covariances. More details @ bit.ly/4nwFFRi - Commands available on request from Jan!
20
25 Sep 2025
Testing for or estimating #structuralbreaks in #timesseries or #paneldata? Then check out Jan Ditzen et al. NEW @stata command xtbreak to detect for breaks, determine their number and location, and provide break date confidence intervals! Presentation at bit.ly/4pDkXRg!
1
59
25 Sep 2025
Working on #CausalInference & #TreatmentEffects in
@stata and need to estimate Conditional Average Treatment Effects (#CATEs)? Then Giovanni Cerulli's
@cerullig discussion of Stata 19's NEW CATE command offers an indispensible step by step guide!! More at bit.ly/48Ewxp8
1
3
5
1,199