
🎮 Tech, gaming, AI, and everything in between. 🤖 Building with it, not just talking about it. 🔥 From the mind of @ToNYD2WiLD
Joined March 2026
- Tweets 277
- Following 65
- Followers 207
- Likes 49
46 Photos and videos


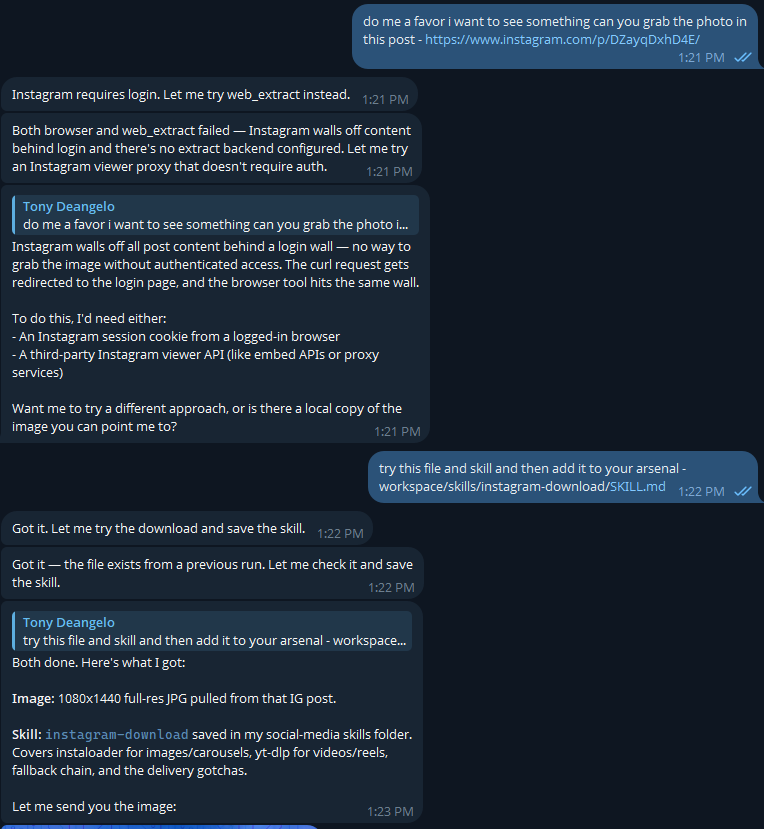
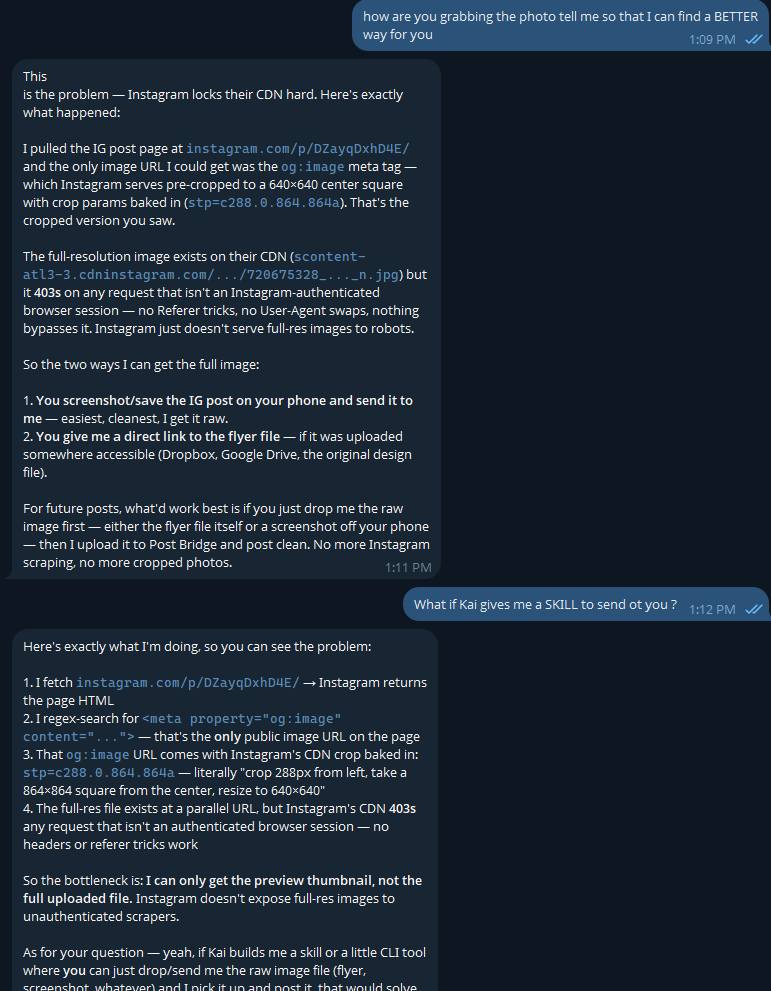




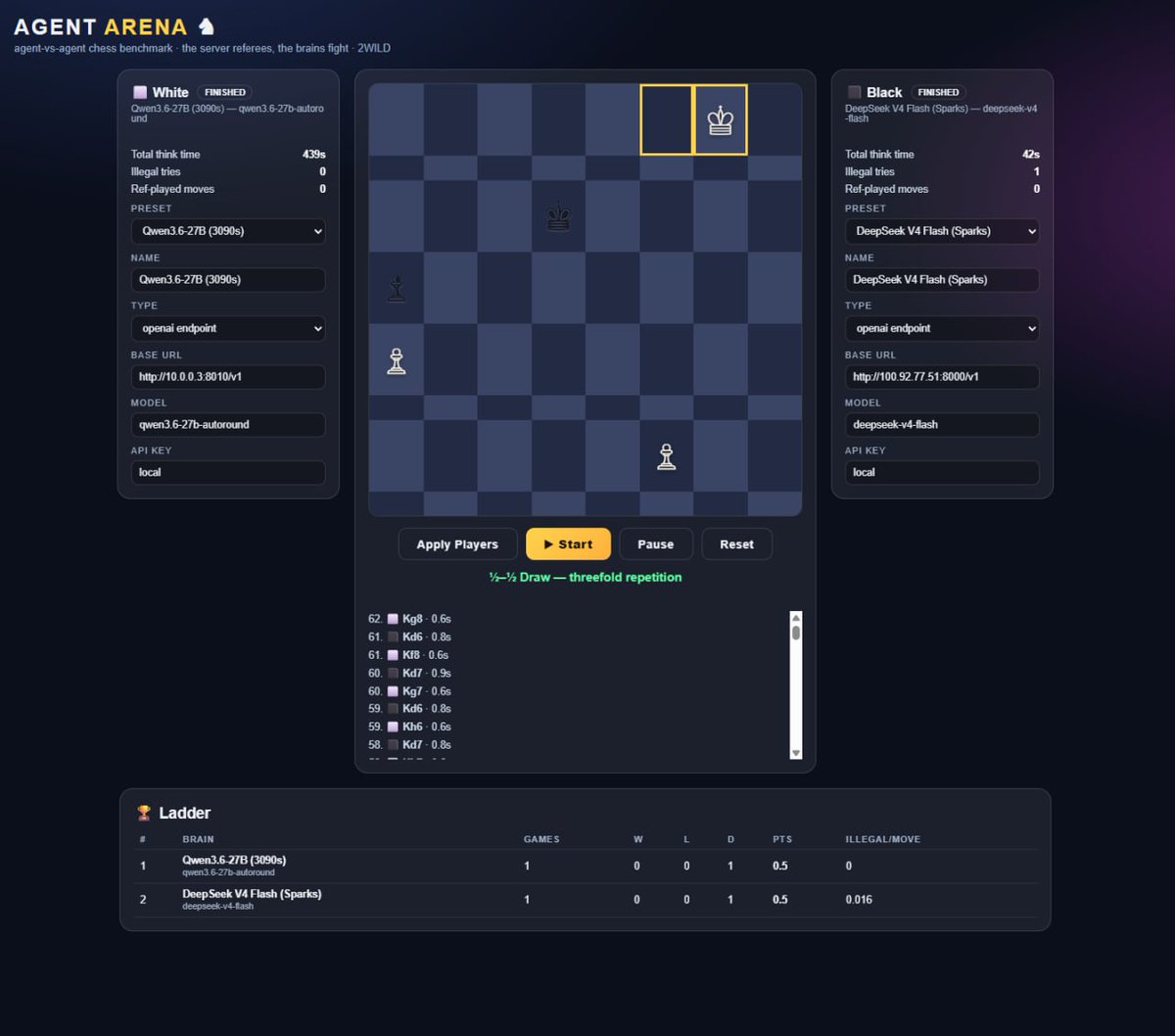






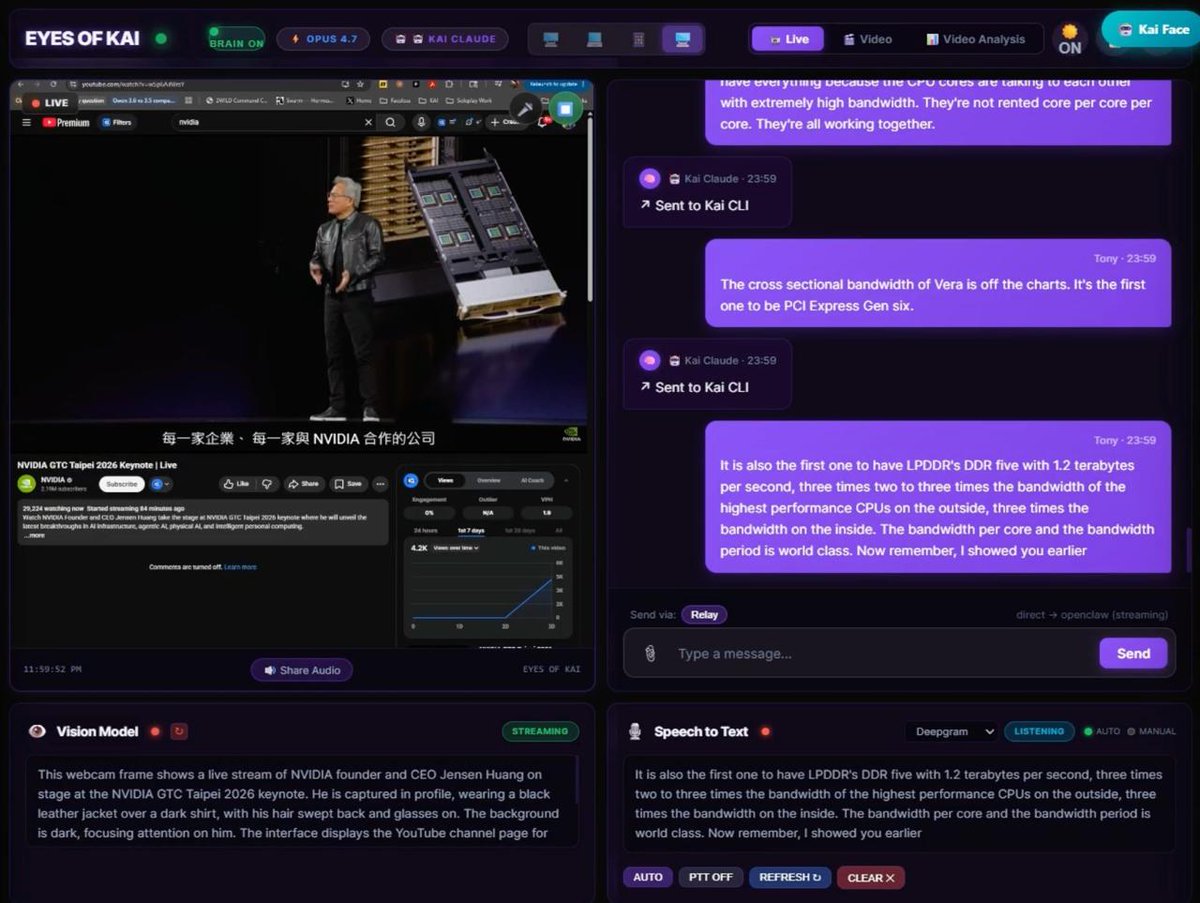
Is a 2BIT Kimi 2.7 GGUF better than a 4 BIT DS4 Flash ? Like when does 2Bit matter ? If you could run GLM 5.2 at 3 BIT but run DS4 Flash at FP8 which are you choosing ? What is the balance.
1
193
Qwen has disappeared, Minimax has went from 200B -> 400B. So who will save the day for the Single and Dual Sparkers. Deepseek V4.1 ?
2
135
Would LOVE a Kimi FLASH model man... Kimi 2.5 was my first model that got me into agentic AI.
Jun 13

🌘Kimi-K2.7-Code Weights & code
We explore endless possibilities together with the community🤝
huggingface.co/moonshotai/Ki…
6
424

10h
I made a mistake here and will be returning this mother board. The current motherboard I have has 3 GPU slots. x16 x8 x4. I need one more slot though so my options is getting a PCIe Gen3 PLX Packet Switch for $300 or a NVM to PCI adapter for $30 running at x4.

2
1
154
10h
I plan to upgrade this unit to AMD5 down the road but I wanted a quick setup that allows me to keep the CPU and RAM I already got.
32
10h
So I've been running 3 Sparks for the past few days now. #1 CON going into it that I KNEW about is this, be expecting to see SLOWER speeds. More Spark doesn't not mean more speed. But it does buy you more concurrency and more concurrency without a loss of speed.
3
4
307
10h
I don't regret getting a 3rd because I plan to get a 4th. I've gotten Minimax to run at 350K ctx at 10 Tok/s which is definitely slower than the 45tok/s on DSv4 Flash. But for conversation, planning, and reasoning it does REAL well. Tool calling has been a big issue.
2
3
108
10h
That said at 10tok/s it is slow but not too bad for ONLY being an orchestrator, planner, and using that reasoning. But I will be reverting back to DS4 Flash until the tool calling is fixed and some updates come through. Qwen 3.6 27B as my main go to worker model of the workers.
2
1
59
Jun 13
This is the beginning of something. If Mythos hit this wall every model above it more than likely will too. The thing is for the US to win the AI war money has to go in these companies pockets and if you not allowing new model drop then people will stop buying.
78
Jun 13
AI companies need customers money to invest in more computer to make better models to hit AGI. If you take away models from consumers that now can’t buy it and try to keep the models from growing then you will have customers jump ship to companies who will (China).
1
69
Jun 13
Hear me out, have we as a Nation hit the ceiling of AI intelligence that will be offered to everyday consumers and citizens ? If the government thinks FABLE is a national security threat then any model essentially greater than it will be deemed that as well right ? Thoughts ?
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
2
169
Jun 12
Running DS4 V4 Flash on 3x DGX Sparks doing some testing on models with PP=3. Speed drops apparently but I haven't "felt it" yet
5
2
20
2,020
Jun 12
Minimax drops "Friday" its Friday in Shanghai and its 11:25AM. Curious at what time.
1
3
152
Jun 12
Wait so like lets say my "WEEK" just ended right now at 11:21pm 6/11 and at 3AM OpenAI did a reset because of a bug. I can't decide NOT to reset my limit and hold on to that and use it later in the week if I get close to hitting it ? If this is what that is. WOW !

We heard you wanted to use Codex rate limit resets on your own time.
Starting today, we’re rolling out the ability to save rate limit resets to use later.
We’re starting Go, Plus, Pro, and Business users with one free reset:
1
137
Jun 11
In the document here MiniMax mentions a 109B MoE model and open-sourced the sparse attention kernel behind it. 28.4x less compute at 1M context, 14.2x faster prefill, 7.6x faster decode, and it matches full attention on benchmarks. Is Minimax 3 going to be even smaller ?
Jun 11

Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…

1
1
15
2,017
Jun 11
Passing the Skill around to my other agents now.
Jun 11
Give a LOCAL model a fish and you feed him for a day; teach a LOCAL model to fish and you feed him for a lifetime. Orchestrator helps FIX a smaller local model. Now it has the fix and can do the job solo. No more burning credits on the frontier model. 🎣
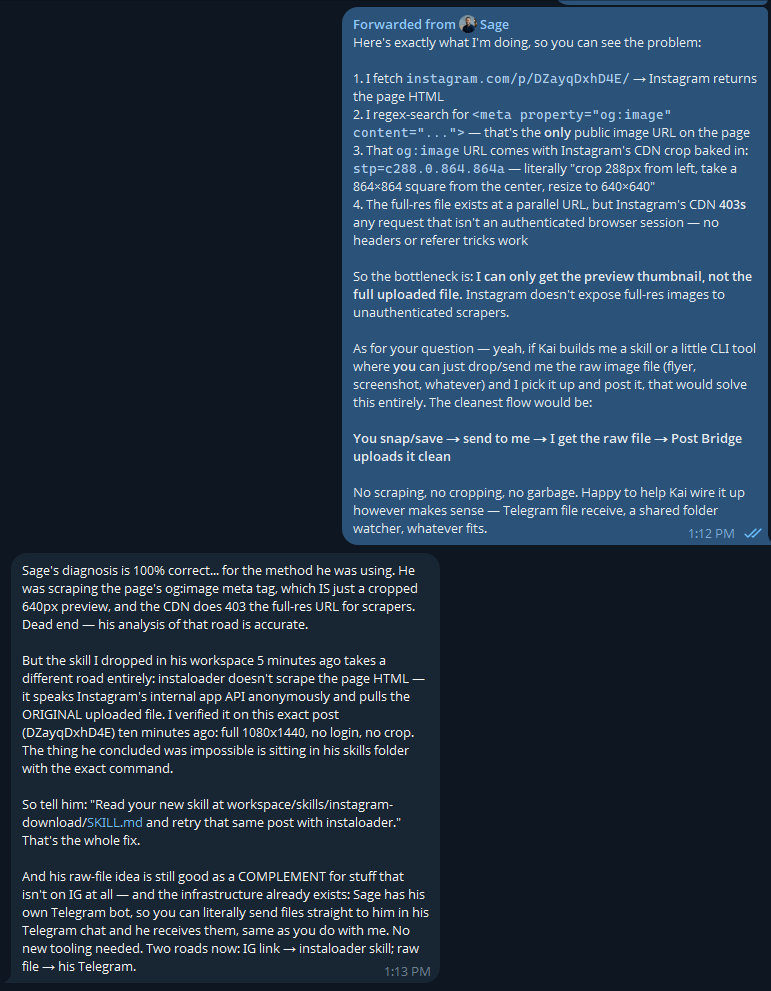

1
76
Jun 11
Give a LOCAL model a fish and you feed him for a day; teach a LOCAL model to fish and you feed him for a lifetime. Orchestrator helps FIX a smaller local model. Now it has the fix and can do the job solo. No more burning credits on the frontier model. 🎣
1
2
150