
Joined May 2025
- Tweets 396
- Following 220
- Followers 5,754
- Likes 1,349
38 Photos and videos







Pinned Tweet

Apr 15
No.1. Again! 🎉 Thanks for all OSS developers!
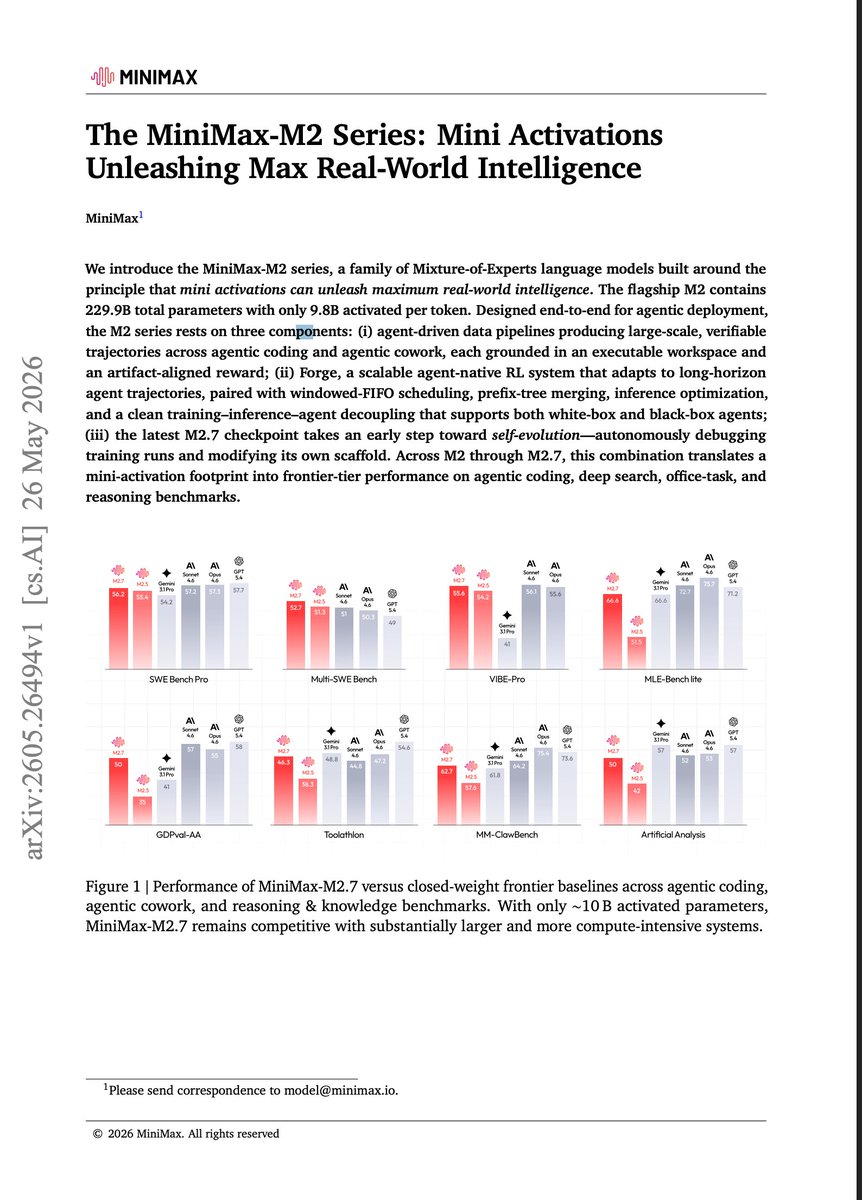
MiniMax M2.7 has only 230B parameters with 10B activated, yet delivers excellent results and outstanding performance. @MiniMax_AI
It is particularly well-suited for open-source agents such as @openclaw , hermes @NousResearch , and @opencode etc.
Moreover, it is totally free for individual developers.
We will continue to provide better models and updates to the community.
@huggingface
79
88
1,337
99,045
RyanLee retweeted

Jun 12
MiniMax M3 can now be run locally!🔥
MiniMax-M3 is a new 428B (23B active) open model with 1M context that performs on par with Gemini 3.1 Pro.
Run Dynamic 2-bit GGUF on 138GB RAM/VRAM or 3-bit on 165GB.
GGUF: huggingface.co/unsloth/MiniM…
Guide: unsloth.ai/docs/models/minim…

Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
58
87
698
142,051
Jun 12
We’ve been discussing what parameter size works best for the community. While the M3 series boasts a larger parameter count compared to the M2 lineup, we’ve kept its scale deliberately restrained so local model enthusiasts can run it affordably. This time we settled on 428B, hoping it will be accessible to a wider audience.

400B ? I doubt whether you have the capability to train models with 800B parameters or even 1T parameters.
42
16
373
34,224
Jun 12
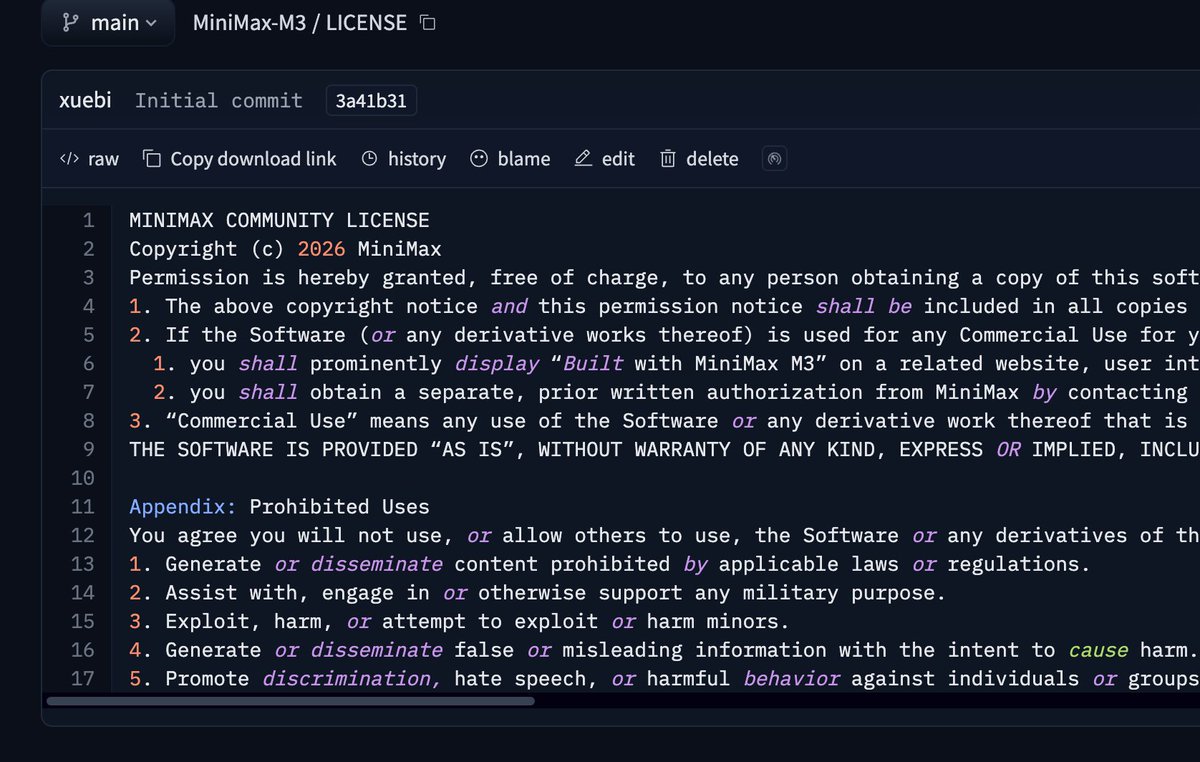
On the M3 license — thanks for the feedback on M2.7 🫡
You told us prior-approval-for-any-commercial-use was too much. We listened.
M3:
- Non-commercial: fully free
- Commercial for individuals or companies under $20M/yr revenue: just need to give us a heads up (api@minimax.io) and label “Build with MiniMax”
- Companies with higher revenue: please contact us for commercial license 😀
Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
1
2
53
23,754
Jun 12
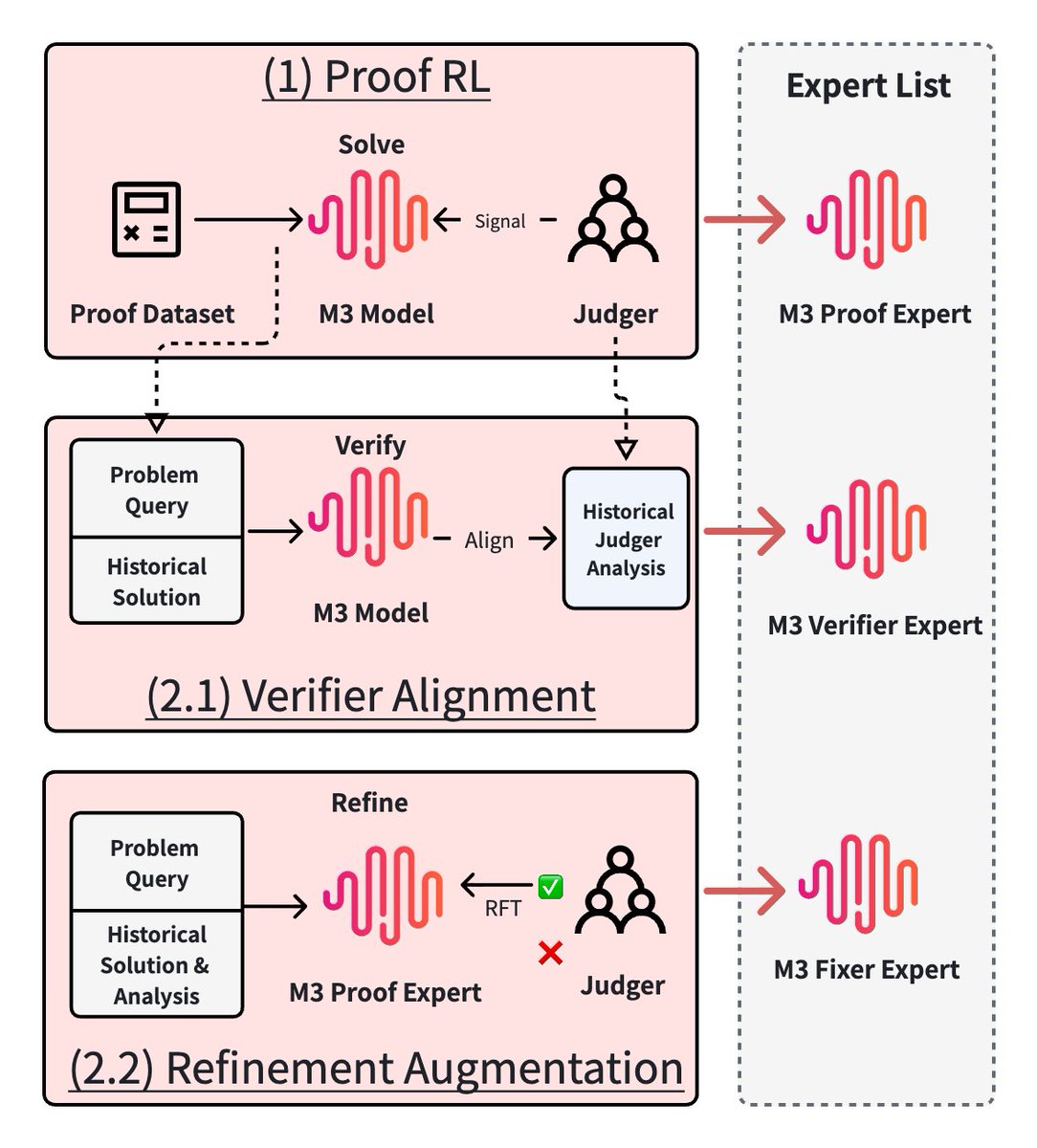
With the MaxProof framework, M3 exceeded the human gold-medal threshold on both sets. In this paper, we go deeper into the technical path behind our progress in mathematical proof: improving the base model, aligning a verifier, building refinement capability, and designing the test-time scaling framework MaxProof.
Here it is
《MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Evolutionary Search》
huggingface.co/papers/2606.1…
8
24
225
21,662
Jun 11
Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…
26
107
969
113,107
RyanLee retweeted

DeepSWE and DeepSeek V4 Pro: surely the benchmark is designed to facilitate GPT 5.5, and mini-swe is not ideal for many models tested, but personally I executed it, against DeepSeek official API, using V4 Pro and reasoning Max. It used around 1B tokens and I've got only 5.3% at the end 😢
Estimated cost:
- cache-hit input: $3.54
- cache-miss input: $3.74
- output: $4.89
- total: $12.18
Without cache-aware pricing, the same token volume would look like about $433.76 😱, so cache accounting is essential here.
Bottom Line from AI analysis:
This is a clean direct-DeepSeek run from an infrastructure/methodology standpoint: no OpenRouter ambiguity, no Docker setup failures, no missing thinking metadata, and no retries. The result is low: 6/113 = 5.31%, with 3 agent timeouts counted as failures.
I invite others to check what's going here in details, results seem really odd, but code is there, verifiers is there, all in the open. I'm retrying now with reasoning High and later I'll try with a different harness.
Composer 2.5 with Grok Build gave me ~10%
We need to keep investigating. I'm testing MiniMax M3 now.

45
10
311
32,169
RyanLee retweeted

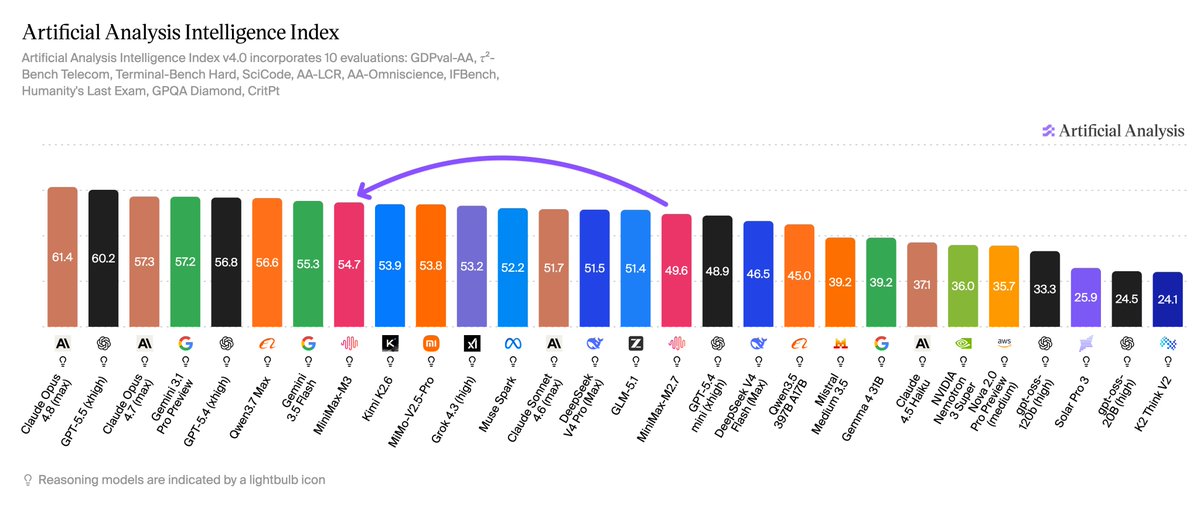
MiniMax-M3 scores 55 on the Artificial Analysis Intelligence Index. Once the weights are released, it will be the leading open weights model
M3 is @MiniMax_AI's first multimodal M-series model, adding image and video input and a 1M token context window over the text-only MiniMax-M2.7 (50). At 55 on the Intelligence Index it sits just ahead of open weights peers Kimi K2.6 (54) and MiMo-V2.5-Pro (54). MiniMax has noted they plan to release the weights within ~10 days. When MiniMax released the weights for M2.7, it was under a commercially restricted license.
Key takeaways:
➤ MiniMax-M3 improves on MiniMax-M2.7 across most evaluations. HLE 9 points (28% to 37%), GPQA Diamond 6 (87% to 93%), AA-LCR 5 (69% to 74%), IFBench 7 (76% to 83%), and CritPt 3 (1% to 4%), with a small regression on SciCode (47% to 45%)
➤ M3 scores ~1670 on GDPval-AA, behind Claude Opus 4.8 (max, 1890) and GPT-5.5 (xhigh, 1769), and level with Claude Sonnet 4.6 (max, 1676). GDPval-AA measures real-world tasks across 44 occupations and 9 industries
➤ Native multimodality, scoring ~80% on MMMU-Pro. Level with GPT-5.5 (xhigh, 79.9%) and Kimi K2.6 (79.4%), behind Gemini 3.5 Flash (high, 84.3%). Not all open weights models support native vision input
➤ On AA-Omniscience, heavy abstention drives both low hallucination and low accuracy. M3 attempts only 30.9% of questions, the lowest among current peers, yielding a low hallucination rate (16.1%) and low accuracy (15.0%)
➤ MiniMax-M3's token usage is close to M2.7's, using ~91M output tokens to run the Intelligence Index (~81M reasoning) versus ~87M (~79M reasoning), while scoring 5 points higher
Key model details:
➤ Context window: 1M tokens, up from MiniMax-M2.7's 200K
➤ Pricing: $0.30/$1.20 per 1M input/output tokens up to 512K context, rising to $0.60/$2.40 for 512K to 1M context
➤ Weights: Not yet released. MiniMax has stated the weights will follow
➤ Availability: MiniMax first-party API, @SiliconFlowAI, @gmi_cloud, and @novita_labs

35
50
728
56,594
RyanLee retweeted

Jun 6
They say MiniMax M3 is great at UI and it didn't disappoint
It's also good at ThreeJS
3
2
46
3,608
Jun 4
MiniMax-M3 now is rank #8 on @ArtificialAnlys.
Due to the workload involved in open-sourcing the MSA operator in parallel, the weights will be released to everyone late next week.
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

34
23
461
62,465
Jun 3
🔥 MiniMax-M3 just got faster.
Thanks for all the excitement around MiniMax-M3 — the response has been far beyond our expectations.
Last night, we rolled out a major inference upgrade:
🛠️ Fixed an issue that could occasionally produce abnormal tokens
💾 Increased memory and improved cache efficiency
🚀 ~50% higher throughput, with most users now seeing 50–70 TPS
You should notice a much smoother experience today.
More optimizations are on the way. ❤️
63
20
763
53,638
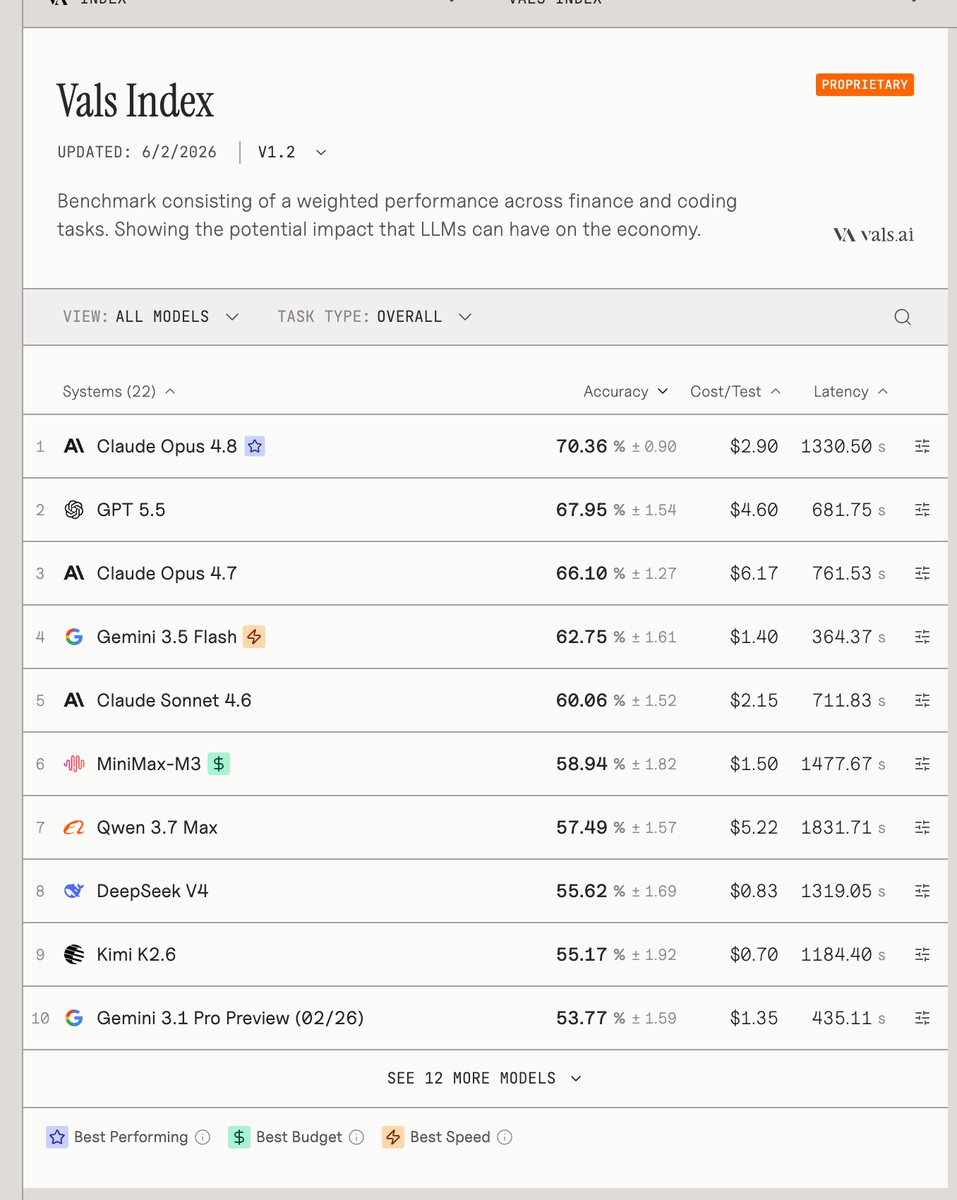
Jun 3
MiniMax-M3 is rank #6 on vals.ai/

MiniMax just released MiniMax-M3, their first multimodal model. It is the new open-weight SOTA on the Vals Index and the Vals Multimodal Index, and #6 overall.

7
6
175
13,897
RyanLee retweeted

Watch M3 reach the frontier 🚀
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days
18
21
427
43,905
RyanLee retweeted

Jun 1
跟祖传的 20K context 说 bye bye 了。
MiniMax M3 发布了,三个亮点:
1M context、原生多模态、Agentic。
我这次做了一次完整评测,使用CC workflow 、 @ZenMuxAI和MiniMax M3:
给一张截图,做一个“凡人修仙剑阵对决手势游戏”。
要求是:支持双人对决 、使用 workflow 拆解任务、加入石头剪刀布机制。
2 小时后,游戏真的跑起来了。
这一代LLM的版本答案我知道了:
1M 上下文 多模态 agent 模式。
1M context 是推理深度的基础,多 agent 负责拆任务和执行。
53
7
105
38,620
Jun 1
MiniMax-M3 will by arrive on HuggingFace openweight at next week!
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days
61
84
1,026
102,886