
Follow for elegant code, AI papers, python, math, books and meta-humor.
Joined January 2013
- Tweets 1,114
- Following 574
- Followers 116
- Likes 1,578
119 Photos and videos











Pinned Tweet

1 Jul 2023
A todo cli in 10 lines of python.

ALT A todo cli in 10 lines of python
2
2
6
891
Alex Telon retweeted

Mar 28
someone at ANTHROPIC just showed CLAUDE finding ZERO DAY vulnerabilities in a live conference demo
claude has found zero day in Ghost, 50,000 stars on github, never had a critical security vulnerability in its entire, history...
it found the blind SQL injection in 90 minutes, stole the admin api key, then did the exact, same thing to the linux kernel
297
1,317
11,654
1,900,829
Alex Telon retweeted

Jan 26
Love the word "comprehension debt", haven't encountered it so far, it's very accurate. It's so very tempting to just move on when the LLM one-shotted something that seems to work ok.
33
46
1,379
127,591
Jan 12
Good visualisation! To anyone reading remember that one could argue that our brains also don't have anything that maps this spiral in our "neural weights" directly. We understand spirals with higher level reasoning. So the spiral understanding could come later!
Hence "suboptimal"
Jan 11

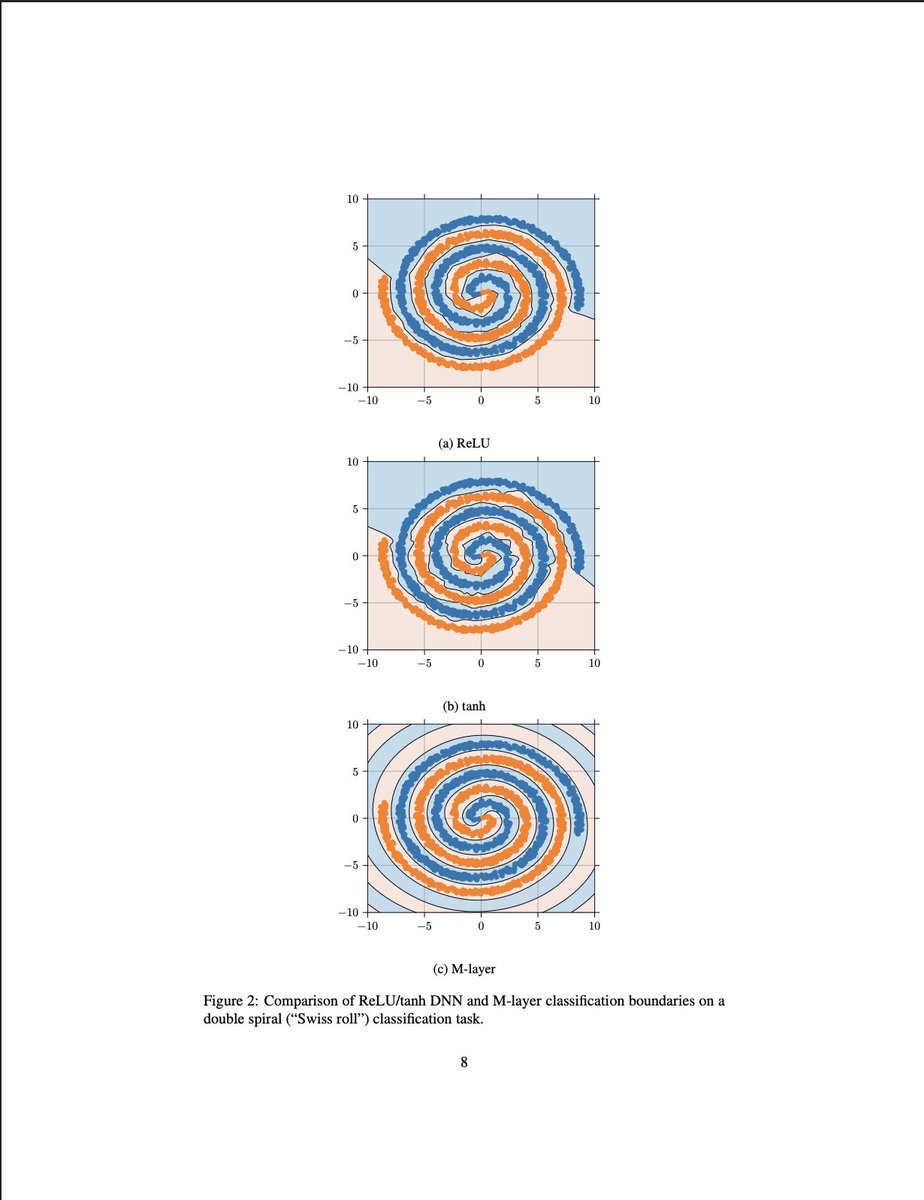
One of the best visual explanations I've ever seen for why scaling Transformers works, but is suboptimal, as it's just brute-forcing things, by @YesThisIsLion (co-author of the Transformer) on @MLStreetTalk
"In the (rejected) paper "Intelligent Matrix Exponentiation", they show the decision boundary of a classic MLP with a ReLu/Tanh activation function on the classic Spiral dataset."
"You can see they both technically solve it with great scores on the test set. Next, they show the decision boundary of the "M-layer" they propose in the paper. And it represents the spiral ... as a spiral!"
"Shouldn't we? If the data is a spiral... shouldn't we represent it as a spiral?"
"If you look back at the decision boundaries of the MLP, it's clear that you just have these tiny, piecewise separations without learning the concept of a spiral. That's what I mean!"
"If you train these things enough, it can fit the spiral and get a high accuracy. But there's no indication that the MLP actually understands a spiral. When you represent it as a spiral, it extrapolates correctly, cause the spiral just keeps going out."
35
Alex Telon retweeted

Jan 11
One of the best visual explanations I've ever seen for why scaling Transformers works, but is suboptimal, as it's just brute-forcing things, by @YesThisIsLion (co-author of the Transformer) on @MLStreetTalk
"In the (rejected) paper "Intelligent Matrix Exponentiation", they show the decision boundary of a classic MLP with a ReLu/Tanh activation function on the classic Spiral dataset."
"You can see they both technically solve it with great scores on the test set. Next, they show the decision boundary of the "M-layer" they propose in the paper. And it represents the spiral ... as a spiral!"
"Shouldn't we? If the data is a spiral... shouldn't we represent it as a spiral?"
"If you look back at the decision boundaries of the MLP, it's clear that you just have these tiny, piecewise separations without learning the concept of a spiral. That's what I mean!"
"If you train these things enough, it can fit the spiral and get a high accuracy. But there's no indication that the MLP actually understands a spiral. When you represent it as a spiral, it extrapolates correctly, cause the spiral just keeps going out."
27
49
618
86,750
Jan 6
Very interesting paper!
When I have time I would hope to dive deeper to see what categories of data had the most signal and to what degree it overlaps with what a smartwatch could gather.
But I found that the data is not from random people so its very important to consider!
Jan 6

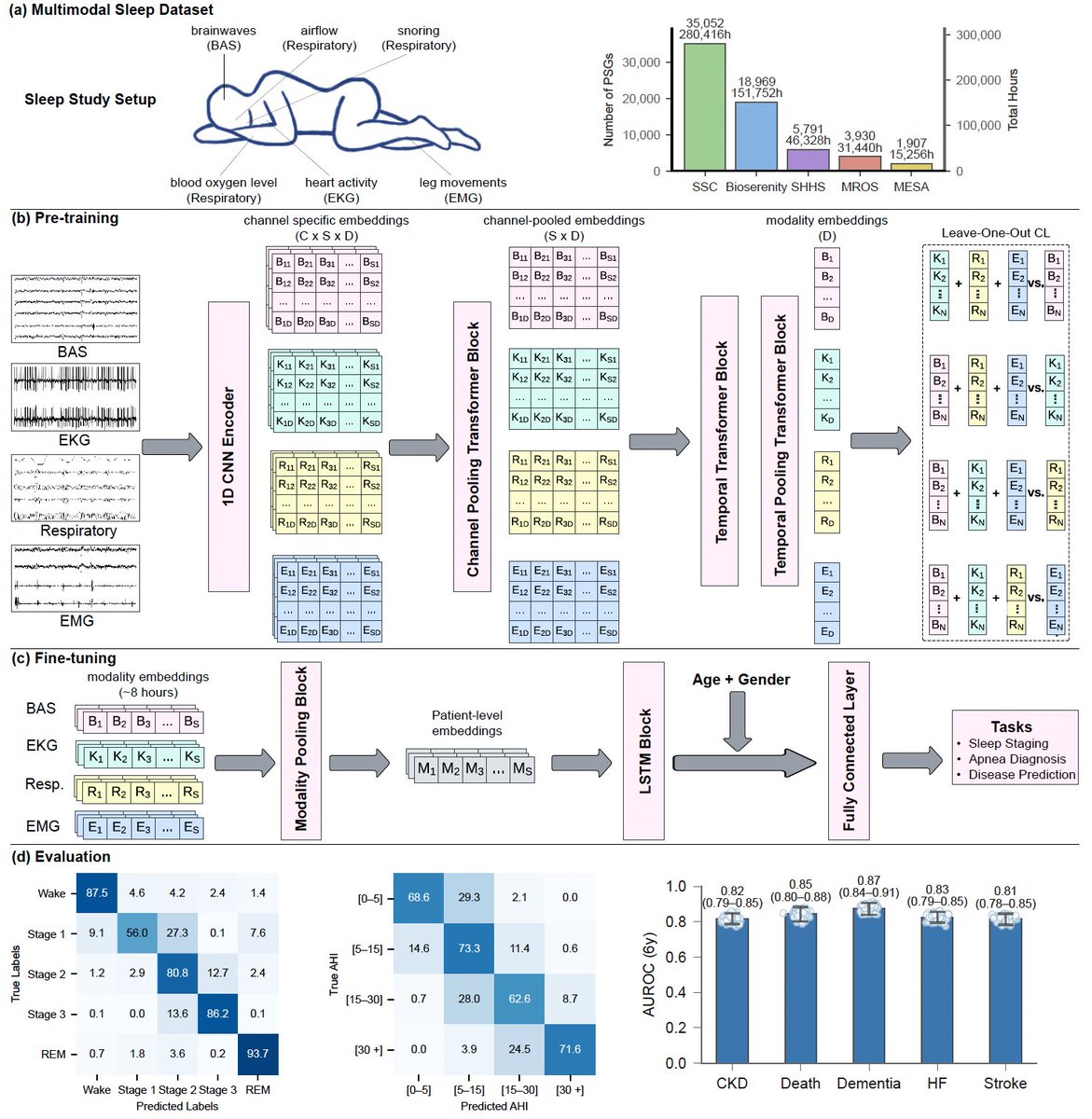
Today in @NatureMedicine we report that AI can predict 130 diseases from 1 night of sleep🛌
We trained a foundation model (#SleepFM) on 585K hours of sleep recordings from 65K people—brain, heart, muscle & breathing signals combined.
AI learns the language of sleep🧵

3
123
Alex Telon retweeted

20 Dec 2025
Opus 4.5 has a 50%-time horizon of 4 hours 49 minutes on METR, which means that it can successfully complete certain software engineering tasks that take a human 4 hours 49 minutes to complete around 50% of the time.
... but its 80%-time horizon is MUCH shorter: just 27 minutes.
Very high ceiling, BIG error rate.
20 Dec 2025

Despite its high 50%-time horizon, Opus 4.5's 80%-time horizon is only 27 minutes, similar to past models and below GPT-5.1-Codex-Max's 32 mins. The gap between its 50%- and 80%- horizons reflects a flatter logistic success curve, as Opus differentially succeeds on longer tasks.

23
28
547
77,722
Alex Telon retweeted
19 Dec 2025
364
2,920
15,529
2,977,853
8 Dec 2025
Feels distopian but I could also see something like this being what we consumers show that we prefer by our actions. Not with the quality shown here though.
But like between episodes some ad based on the content? Maybe.
I prefer to pay to avoid ads though.
Halftime: Dynamically weaves AI-generated ads into the scenes you’re watching, so breaks feel like part of the story instead of interruptions.
@krishgarg @yuviecodes @lohanipravin
16
27 Nov 2025
Michael Spivak Wikipedia image really is something!
- What does he study?
- geometry
- it figures
- "he"
33
12 Nov 2025
Will be joining a panel to discuss AI today and then have a presentation on building internal LLM applications.
Looking forward to it!
13
7 Nov 2025
Did not recognize the name. But something told me "it's the YOLO paper guy right?" Yup that's him.
We need more YOLOv3 like papers! I'm fine with dry stuff. But we are humans too let's have some fun while we are building great things!
6 Nov 2025

JOSEPH REDMON IS DOING AI RESEARCH AGAIN
I REPEAT: JOSEPH REDMON IS DOING AI RESEARCH AGAIN
AI papers are fun again. The OlmoEarth paper is full of Redmon's style:
"Everyone is training Earth observation foundation models these days. So we decided to train one too."
"Do you know how to get data from a satellite? I sure don’t. But someone on the team does and we built a whole end-to-end platform to get all that data and do all those other things too. "
"We have huge tables with all the numbers later on but you can also look at the slightly less confusing Figure 1 of “Inverted Average Rank”, a totally real metric."
"The perfect benchmark and the most important one, and hey look at that we’re really good at it"

32
Alex Telon retweeted

22 Oct 2025
People overestimate debuggability.
I spent a week debugging a short incorrect algorithm at work. The code used plain features like ‘if’ and ‘for’-loops.
It still didn’t make sense. It still didn’t work.
I rewrote it to a declarative pipeline, and it worked first time. I don’t need to debug it at all.
The point is, plain language features like variables, loops, conditionals, etc. are not composable. They’re simple building blocks and they’re too low level.
Pure functions and pipelines eliminate a huge class of errors you don’t have to even think about.
It’s not a silver bullet. So don’t write code smarter than yourself.
But few people have experienced the joy of leveraging composable declarative programming.
And it shows.
20 Oct 2025

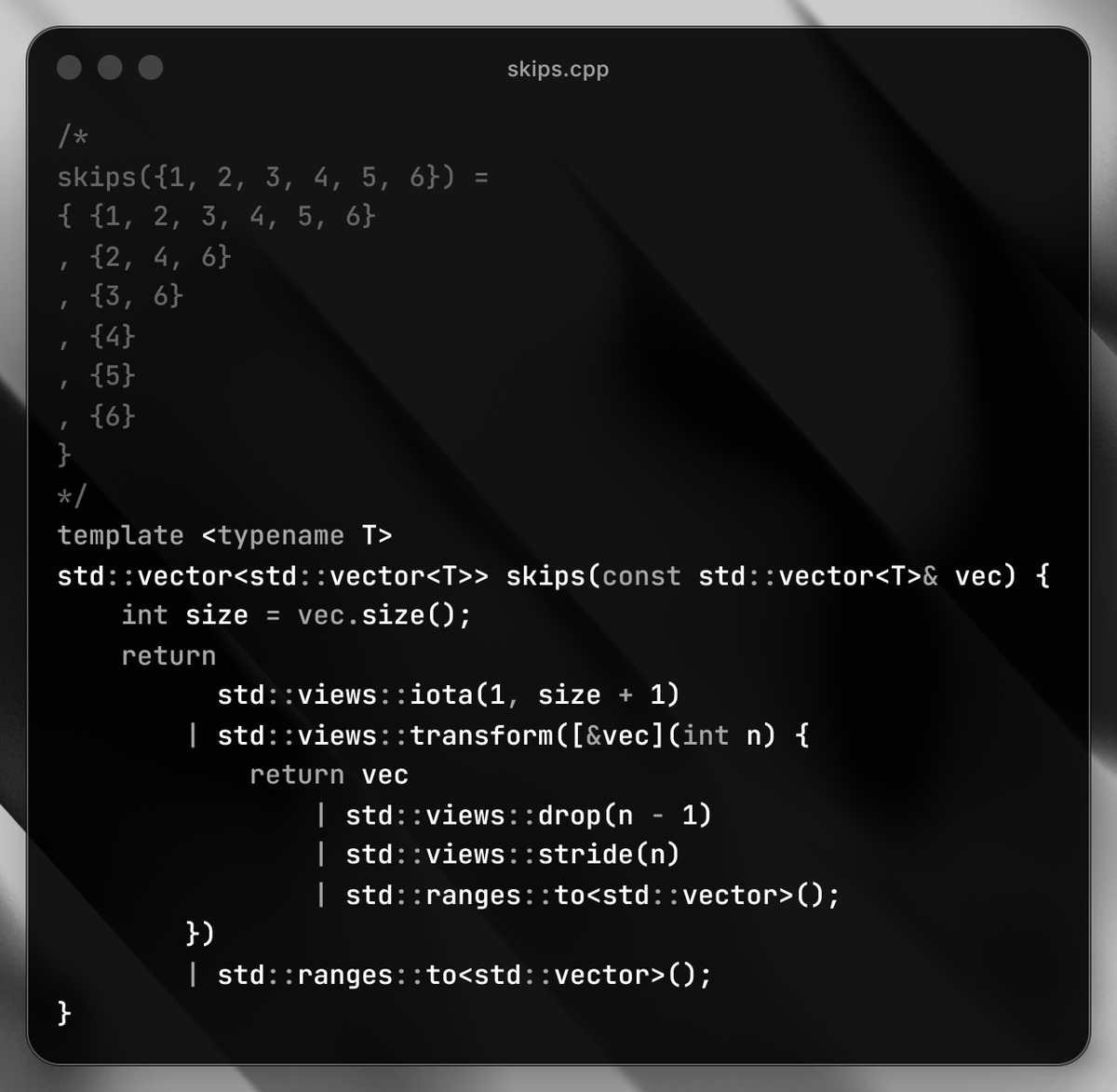
I haven't shared beautiful C code for a while.
Here's some FP in C for a treat.
61
23
549
133,461
16 Oct 2025
In git bash for windows apparently pwd has a -W flag to get the current path in a windows style format!
Before I used to do
start .
Alt D
Ctlr C
to copy the current path
now instead I can do this!
pwd -W | clip
13
19 Sep 2025
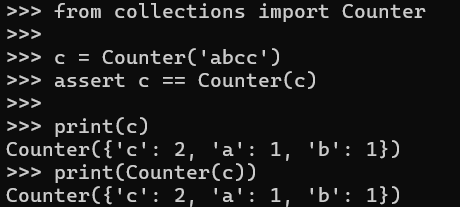
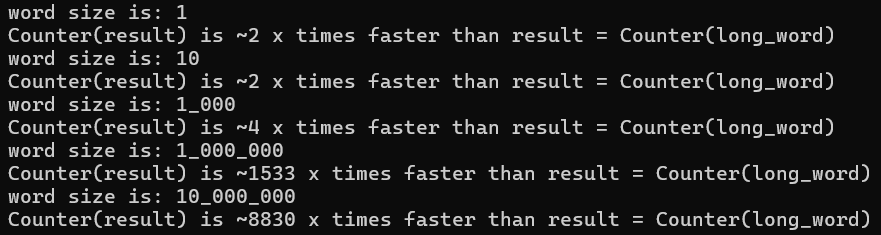
By accident I realised that a Counter can take a Counter object as input.
Counter(Counter('abcc')) == Counter('abcc')
For my usecase its nice for longer strings since I can "cache" the work by calculating Counter(long_word) only once and send that instead of long_word
1
33
18 Sep 2025
I'm predicting that once AI starts to produce some research I will say yeah but those results are just a new combination of known things. It has yet to find something truly novel.
The research I have been reading the past days is lots of combining things to eek out small gains.
17 Sep 2025

1/n
I’m really excited to share that our @OpenAI reasoning system got a perfect score of 12/12 during the 2025 ICPC World Finals, the premier collegiate programming competition where top university teams from around the world solve complex algorithmic problems. This would have placed it first among all human participants. 🥇🥇

1
55
18 Sep 2025
Its fair to say that even if it can only recombine ideas in novel ways that in itself could provide lots of value.
Like suggesting/experimenting with new materials or medicines.
But also evaluating what features, hyperparameters etc work best to nail some benchmark using a NN.
1
16
18 Sep 2025
Example where its useful already now.
x.com/deredleritt3r/status/1…
17 Sep 2025

MIT Technology Review:
- California researchers trained an AI model on genomes of ~2 million bacteriophage viruses and asked it to propose new genetic codes for viruses.
- It worked! Several AI-designed viruses replicated and killed bacteria. 16 out of 302 total designs worked.
"That led to a profound 'AI is here' moment when, one night, the scientists saw plaques of dead bacteria in their petri dishes. They later took microscope pictures of the tiny viral particles, which look like fuzzy dots."
Creating these genetic codes for viruses can be thought of as "just a faster version of trial-and-error experiments", as humans have accomplished this in the past via a long hit-or-miss process of testing out different genes. A very cool result nonetheless!


19
Alex Telon retweeted

15 Sep 2025
As a software engineer, it's very important to learn about Gall’s Law, which states that complex systems cannot be created successfully from scratch.
In reality, even large systems, such as Netflix, Google, or Facebook, have started small and built incrementally over the course of decades.

136
912
7,971
555,274
16 Sep 2025
I was very disappointed by it. They trained a small model on toy problems and complained that it could not generalize outside the problem domain?
Like if its only trained on F1(A) = N and F1(M) = Z how would we expect it to know what F1(O) is?
31 Aug 2025

Another bad news for reasoning LLMs 🤔
The paper claims Chain-of-Thought in Language Models, is a brittle mirage bounded by training data, which is just pattern matching rather than genuine inference. 🤯
Argues that chain of thought in LLMs is pattern replay bound to training data, not general reasoning.
Chain of thought is useful when prompts match training patterns, but it is not evidence of general reasoning.
When test data shifts even slightly, the step by step text stays fluent but logic cracks.
The authors build DataAlchemy, a controlled sandbox, and train small GPT‑2 style models on alphabet puzzles using 2 operations, rotate letters and shift positions, over 4 letter strings.
This lets them probe 3 axes, task, length, and format.
When the test uses the same transformation pattern as training, the model’s full chain output matches the label 100%. The moment the test swaps in new compositions of those operations or a truly unseen transform, that exact match collapses to 0.01% or 0%, even though the model still writes confident step by step text. That text looks reasonable, but the final answer is wrong.
Element shift is similar, novel letter combinations or unseen letters break the chain completely.
Length shift hurts too, models trained on length 4 fail on 3 or 5 and even pad or trim steps to mimic seen length, a group padding trick helps a bit.
Format noise degrades outputs, insertions hurt more than deletions, and edits to element or transform tokens matter far more than changes to filler prompt words.
A tiny burst of supervised fine tuning, about 0.00015 of the data, quickly patches accuracy, which signals distribution coverage, not new reasoning skills.
Temperature and size, 68K to 543M parameters, barely change the pattern.
Bottom line, when the data moves, accuracy can collapse while the story still sounds fine. Test on real shifts, not just matching cases, and keep training coverage honest.
🧵 Read on 👇

1
36
16 Sep 2025
Toddlers between the ages 0-3 months cannot speak under our careful tests. This proves our hypothesis that adult humans cannot speak.
Small language model of size < 0.5B cannot reason. this proves our hypothesis that large language models cannot reason.
1
16
16 Sep 2025
One could draw the conclusion that small models are pattern matchers I guess. And I lean towards this being true for large models too in fact!
But one must address the fact that certain behavior only happens at large scale. Which greatly limits the scope of these findings.
15