
Joined December 2011
- Tweets 20,426
- Following 1,443
- Followers 88,439
- Likes 125,757
2,842 Photos and videos












Pinned Tweet

Thank you, Mamma, for the birthday wishes! ❤️
Jun 10

Cheers to 23 years of awesomeness 🎉🎂
Blessed to have you in our lives ❣️
Wishing you a year filled with blessings, exciting discoveries, and continued impact on the🌎


3
12
2,296
Congrats to all the Knicks fans!!
including my dad @Cornellian1988! :)


1
9
1,419
OpenEvidence is understandably not happy with the recent LLM benchmarking study!
I agree with the larger point of better benchmarks needed. Perhaps OpenEvidence could be evaluated on our open and completely transparent Medmarks benchmark suite 🙂

Rigorous evaluation of medical AI is good for everyone, and we welcome it. Counter to a half-dozen independent studies from institutions such as the Mayo Clinic that were highly positive on OpenEvidence—a lone paper now purports to show that generalized AI beats specialized clinical AI (@UpToDate, @EvidenceOpen). The paper has a massive undisclosed conflict of interest and irredeemable methodological flaws.
Behind the scenes: The study authors run a competing in-house medical AI at their hospital, and asked OpenEvidence for an API to power it — including rights to build a "competing product" with OpenEvidence's own API. OpenEvidence declined. Then, this paper coincidentally appeared.
Point-by-point, looking closely at the datasets used in the study, the disingenuous and fatal flaws become immediately apparent 🧵.

1
4
26
3,402
At Stability AI, I contributed to HDiT (invented by my colleague @RiversHaveWings) as a side project to explore some diffusion research outside of the medical AI work I was doing.
What's interesting to see is how this project has also been used in medical AI research as well!
In this paper, the authors use HDiT directly applied to the wavelet domain to train a diffusion model to generate 3D brain MRI scans.
Jun 13

One full-size 3D brain. Every voxel, no lossy latent. Generated in 1s.
That's WaveDiT, 𝗲𝗮𝗿𝗹𝘆 𝗮𝗰𝗰𝗲𝗽𝘁 at #MICCAI2026 (top 9% of submissions). Now we can finally unveil it. 🧠
Try it live in your browser, no install:
🤗 huggingface.co/spaces/danese…
🌐 danesed.github.io/wavedit-pa…
5
2
35
4,766
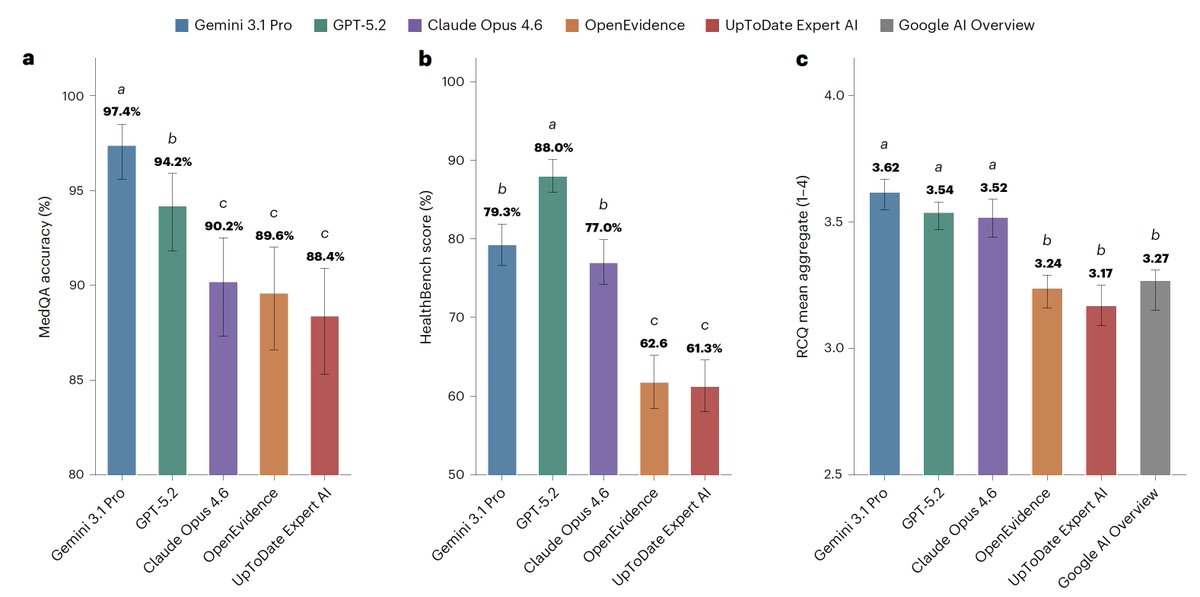
This study has been going viral. I think that most people are misunderstanding its conclusions a bit.
This paper DOES NOT MEAN domain-specific models are not worth it.
First of all, UpToDate and OpenEvidence are not models, but products. And there's no information on what models they are built on. They are likely built on top of older models. For all we know they're built on top of gpt-4o or Llama-3.1 or something 🤣 (it's probably something more recent/powerful than that but just trying to emphasize the point)
Second of all, the benchmarks are a bit limited. The benchmarks include MedQA (which is pretty saturated at this point), HealthBench (which focuses on patient conversations), and a closed dataset of doctor questions to an LLM. There are many aspects of clinical use of LLMs that are not at all analyze by this benchmarking approach.
What conclusions can be made then? Only that UpToDate and OpenEvidence is worse than frontier models on the limited set of benchmarks tested in this paper.
It doesn't mean that domain-specific models cannot beat general purpose models.
In fact, we have done a comprehensive benchmark (medmarks.ai) which includes MedQA and HealthBench, among many other benchmarks. We look at general-purpose models, and versions of those same models but adapted for medicine. There seems to be a noticeable boost going from general-purpose to medical fine-tune.
So if you took a frontier model and were able to fine-tune for medical applications it would definitely be better. i.e. a domain-specific model would be better.
It is true that the current domain-specific models (which are often built on open-source models that are not at the frontier) are often worse than frontier models.
It is not true that building domain-specific models cannot beat general-purpose models.
I think the main problem is open-source models aren't progressing fast enough with respect to the frontier models and on top of that very few groups are adapting them quickly enough to release better and better medical AI tools.
Some groups claim to have medical-specific models that outperform frontier models, ex: Baichuan-M4. Hopefully we'll see more medical-specific models trained on top of really strong base models come out soon.
Jun 12

For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
11
14
68
16,703
Tanishq Mathew Abraham, Ph.D. retweeted

Jun 10
@iScienceLuvr happy birthday my friend!!! ❤️
1
2
7
3,395
Thank you, Parm, for the birthday wishes! 🙏
Jun 10

@iScienceLuvr happy birthday my friend!!! ❤️
3
1,885
23 yrs old... so I guess I'm an unc now, right?
6
28
3,014
Tanishq Mathew Abraham, Ph.D. retweeted

Jun 10
Cheers to 23 years of awesomeness 🎉🎂
Blessed to have you in our lives ❣️
Wishing you a year filled with blessings, exciting discoveries, and continued impact on the🌎
2
6
3,606
Tanishq Mathew Abraham, Ph.D. retweeted

Has anyone confirmed if fable is degraded solely on frontier llms or all frontier models? Does it need to be autoregressive?
3
1
5
2,589
Congrats to @stevejang and @km! We are lucky to have them as investors in @SophontAI. They have been very helpful in this early stage of our startup, glad that Kindred believed in our vision very early on.

News! We are proud to share our latest $355M set of funds, combining early stage and early growth.
2
3
26
5,263
Claude Fable 5 is likely very capable inherently on healthcare. That's great! Too bad it's near impossible to tap into those capabilities due to their extremely sensitive safety filters. I hope this is adjusted going forward.


12
8
50
7,047
"Sometimes you just kinda phone it in for a year, you know?"
The YOLO v3 paper is a complete banger imo
Jun 9

What's the best opening sentence of a paper you've ever read?
2
2
41
5,650
DO NOT USE FABLE 5 FOR AI R&D/CODING!!
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

27
48
1,350
243,698
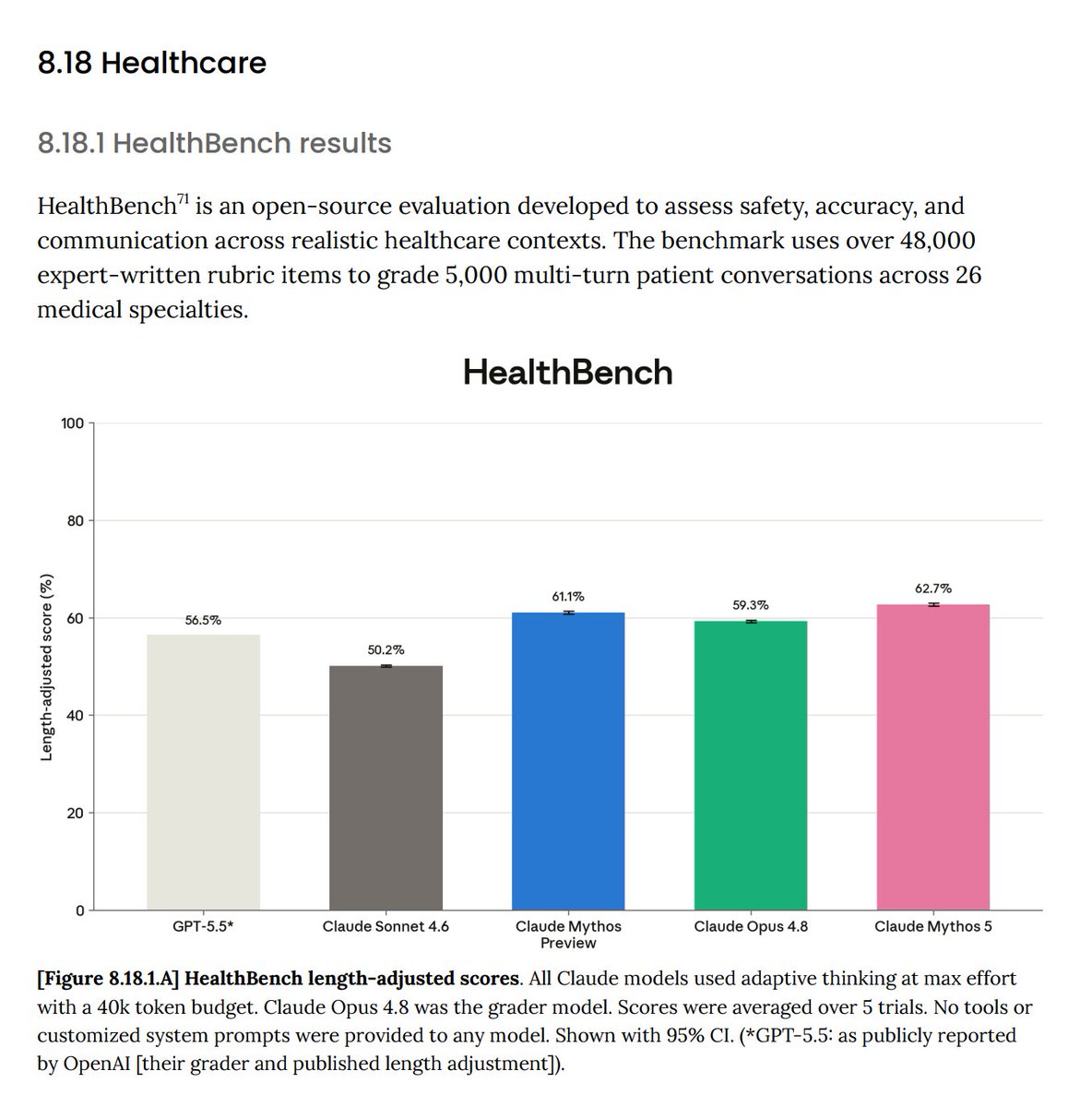
I appreciate Anthropic has provided healthcare-related evals! Let's quickly go over them.
HealthBench - benchmark from OpenAI that includes 5k multi-turn conversations with patients, and rubrics for evaluation. Fable 5 achieves 62.7% vs. GPT-5.5's 56.5%. Personally, I would also appreciate HealthBench Hard scores as well in addition to the aggregate score.
HealthBench Professional - another OpenAI benchmark that focuses on physician tasks. Fable 5 achieves 66.0% vs. 51.8% for GPT 5.5.
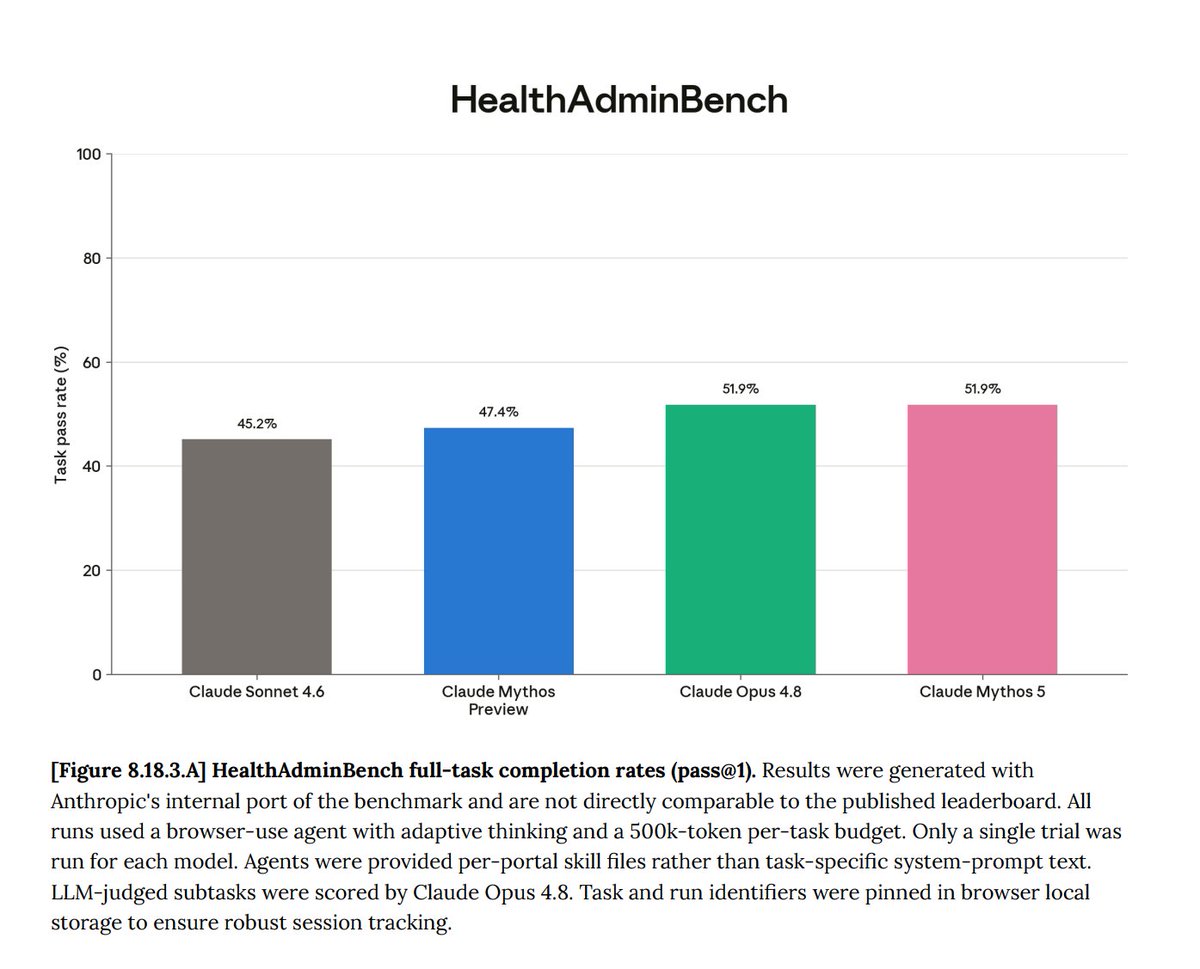
HealthAdminBench - a computer-use benchmark from Stanford that evaluates the completion og various administrative tasks (prior auth, denials/appeals, etc.). Fable 5 achieves 51.9%, no GPT-5.5 score provided.
Overall, this models seems to perform quite well on healthcare benchmarks. Would also appreciate additional benchmark scores like MedCalc-Bench (which was previously reported by Anthropic) and MedXpertQA (an unsaturated, hard medical MCQA benchmark).
Glad to see frontier labs are more comprehensively benchmarking and reporting the medical capabilities of their models!


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
10
6
53
6,590
Baichuan-M4: A Clinical-Grade Medical Agent System for Continuous Care
Achieves 55.1 on HealthBench Professional, beating GPT 5.5
Context: Baichuan is one of the prominent AI startups/labs in China, mostly focusing on AI in healthcare. They've previously released Baichuan-M1 through M3, along with technical reports.
They have now released a technical report for Baichuan-M4, although it is not open-source :(
Baichuan-M4 is designed as a clinical-grade medical agent system, supporting patient consultation, follow-up, continuous care, evidence-based retrieval, medical image understanding, long-term patient memory, and multi-agent coordination in controlled environments.
RL training: "SPAR replaces coarse-grained scoring of an entire dialogue trajectory with reward signals anchored to key clinical spans. The model is not only rewarded for reaching the correct final conclusion, but also for sufficient history taking, timely risk identification, and appropriate tool use."
"In mixed initial-visit and follow-up scenarios, M4 uses a curriculum learning strategy [9] of “building the foundation with initial visits first, then improving performance with follow-ups."
Baichuan-M4 is trained with tools for dynamic memory management, retrieval of authoritative medical evidence, and multimodal perception (OCR X-ray dermatology).
6
2
29
6,942
3
4,848
End-to-End Context Compression at Scale
Encoder-decoder compressors - map a long token sequence to a shorter sequence of latent embeddings, not competitive with KV cache compression.
This work revisits encoder-decoder compression.
Perform an architecture search, pre-training many variants from scratch to determine how best to design and train encoder-decoder compressors.
Continually pre-train a family of 0.6B-encoder, 4B-decoder models on over 350B tokens each, at compression ratios of 1:4, 1:8, and 1:16.
"We introduce Latent Context Language Models (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage."
1
16
128
9,618
models: huggingface.co/latent-contex…
code: github.com/LeonLixyz/LCLM
arxiv: arxiv.org/abs/2606.09659
3
1,829