
I like compilers
Joined September 2025
- Tweets 257
- Following 216
- Followers 103
- Likes 82
22 Photos and videos




Pinned Tweet

Feb 8
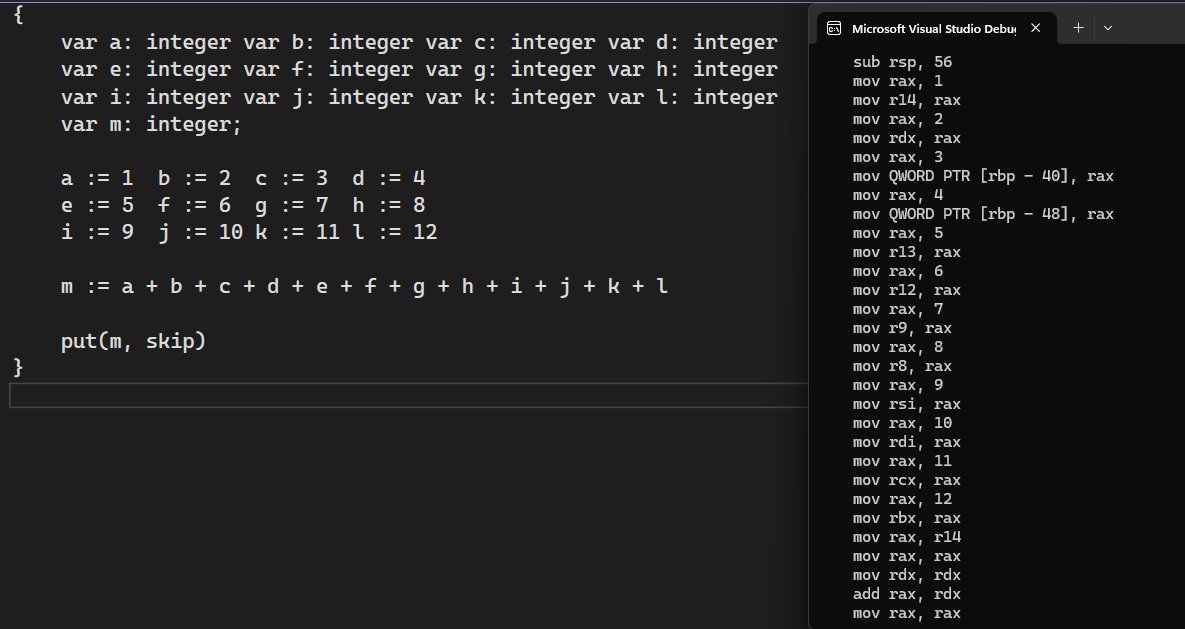
Writing a register allocator is one of the most painful thing to do in a compiler.
But I think it is worth it, since register allocation probably one of the most important compiler optimization. And once you got it done, you can just forget about it, and move on with your life.
1
4
597
hellowww retweeted

Jun 7
TSMC fumbles Copackaged optics for the Nth time like some fucking donkeys and now the whole industry is limping towards NPO, and the pod bros who price the entire AI TAM off Nvidia’s BOM line items still can’t actually explain what the problem is. So let me do the engineering for you, since clearly nobody on here will.
The bottleneck was never can you make light go through a waveguide. It’s all fucking thermals which is downstream of packaging. Specifically, how do you get a photonic engine onto the same substrate as a switch ASIC or XPU without your yield falling off a cliff and your reliability failing.
TSMC’s answer is CoWoS where they bolt everything onto one big monolithic silicon interposer. Cute, until you hit the reticle limit and start duct-taping interposers together (CoWoS-S, then -R, then -L, soon -PleaseStop). Every chiplet and HBM stack you add to that single interposer compounds your defect probability and one bad die leads to a five-figure package going into the dumpster. CoWoS is thermally retarded and the whole industry knows this and it’s why capacity “can’t expand” and Jensen is acting like a bouncer in the front of a club choosing who gets pass the velvet rope.
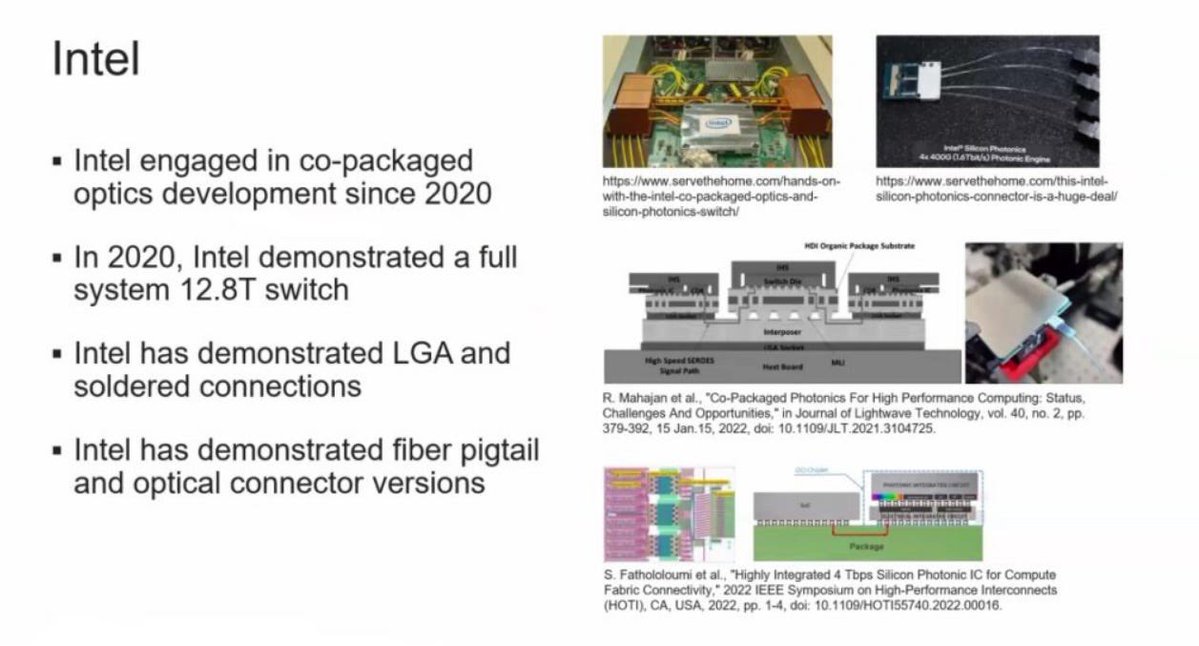
There is ONLY one company that will make copackaged optics work and expand in the rack… it’s not Lumentum, it’s not Coherent, it’s fucking INTELLLL.
Intel’s EMIB gets rid of a giant reticle limited interposer and replaces it with a tiny silicon bridge that does the high-density coupling locally, exactly where you need it. You localize the hard part and the thermals in one area and your yield is ridiculously high. Comparing EMIB & CoWoS is so funny cause EMIB is north of 95% yield with like 12 reticle size equivalent package while CoWoS falls off a cliff after 5.5 reticles it’s that bad…now imagine adding thermally sensitive photonics.
People don’t know this but Intel has been doing silicon photonics in-house for ~25 years... In 2024 they showed an Optical I/O chiplet doing 2 Tbps bidirectionally at ~5 pJ/bit, with the PIC and EIC co-packaged right against the ASIC and it’s all because of EMIB. And even more critically than that, they’ve actually run the fiber-attach and reliability/test flow to JEDEC-grade standards already, which everyone hand-waves until their links flap in production.
My prediction is clear: Intel will capture over 90% of the copackaged silicon photonics market in the next five years because there is NO ALTERNATIVE.

95
230
1,862
530,077
Jun 6
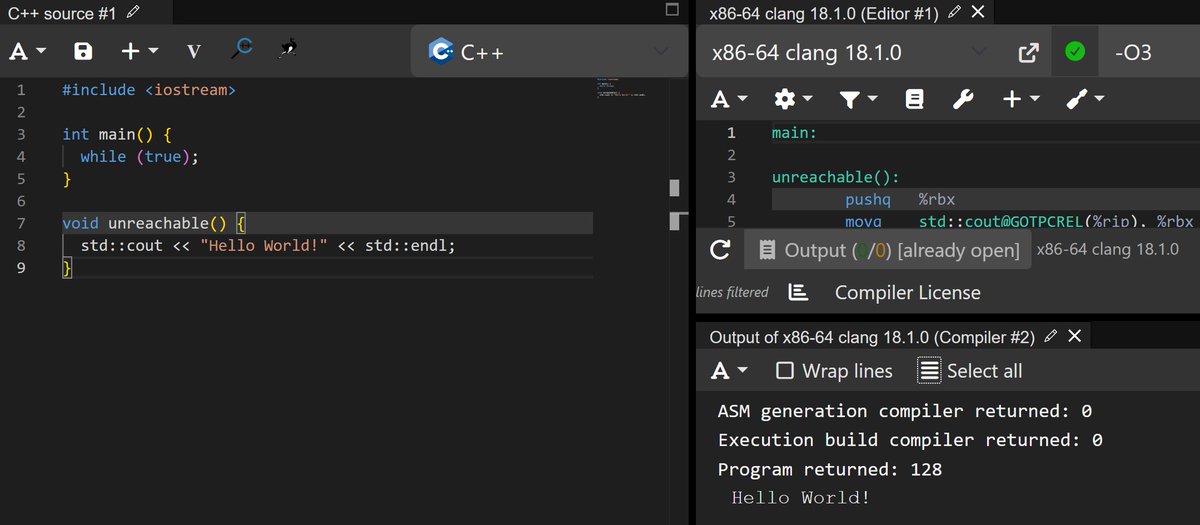
You might not believe it, but in the older version of clang, the code on the left produces Hello World!

5
3
81
14,020
Jun 3
ISO is trying to close off all access to many open documents such as ISO/IEC 9899 (C), ISO/IEC 14882 (C ), and ISO/IEC 1539 (Fortran).
Losing open access to documents would effectively prevent the LLVM Project from implementing future ISO standards.
discourse.llvm.org/t/rfc-ope…
3
14
978
Jun 2
This reminds me of langchain
May 31

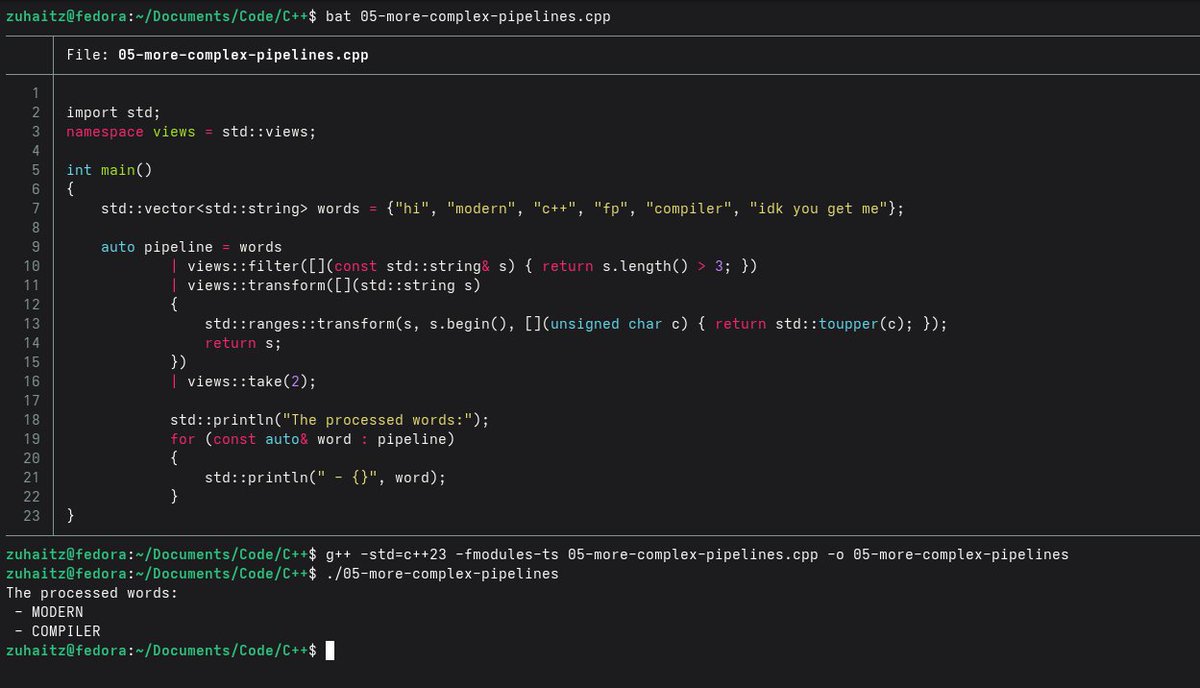
It's actually quite readable and easy to understand.
Ngl, I am having fun and I shouldn't admit it.
3
329
Jun 2
People are planning to add a new LLVM backend to target Metal, that lowers LLVM IR to a loadable .metallib for Apple Silicon GPUs. I am quite excited with this.
discourse.llvm.org/t/rfc-add…
1
109
May 24
So, someone opened a PR in LLVM. The mistakes were incredibly obvious, so I gave him my review (I'm a non-maintainer).
He didn't even bother addressing my feedback and simply tagged someone else to review it.
Hm... Okay...
1
16
2,455
May 24
The problem is, the review queue in LLVM is always super saturated, so you want to reduce the workload of maintainers by fixing obvious mistakes before the maintainer look at your code.
10
465
May 23
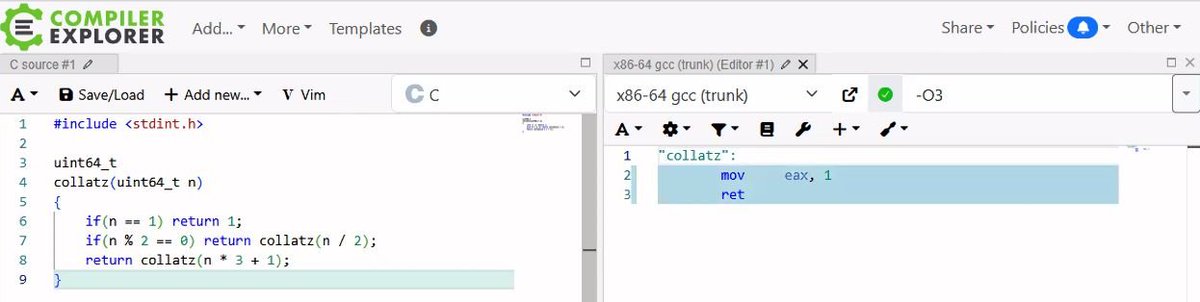
Another godbolt posting: Proof of collatz conjecture by C compiler
13
90
1,670
180,402
hellowww retweeted

May 22
New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
94
725
5,597
926,418
May 17
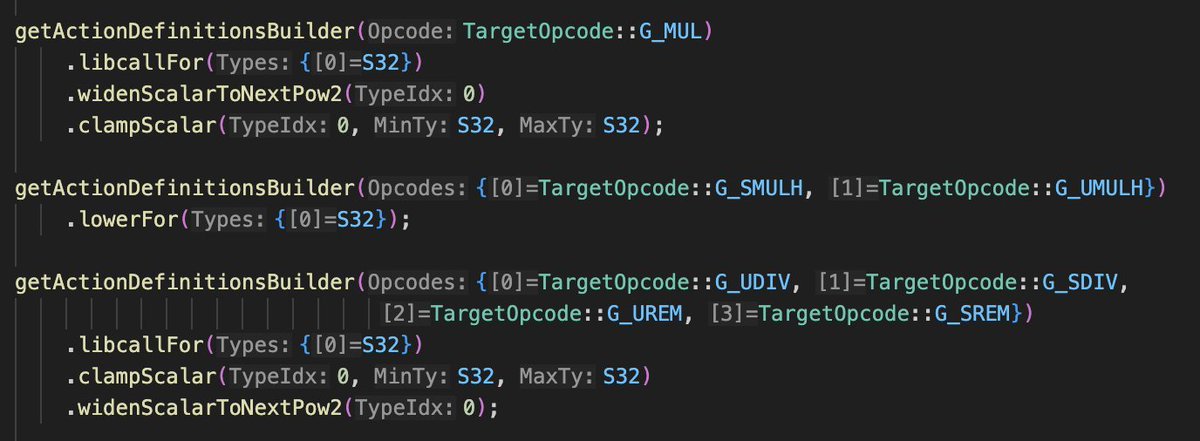
In LLVM, legalization is a phase where illegal instructions getting converted into instructions that is supported by your hardware. The easiest way is using libcall.
1. Tell legalizer to use libcall for your illegal instructions.
2. call setLibcallImpl in TargetLowering.

1
1
122
May 17
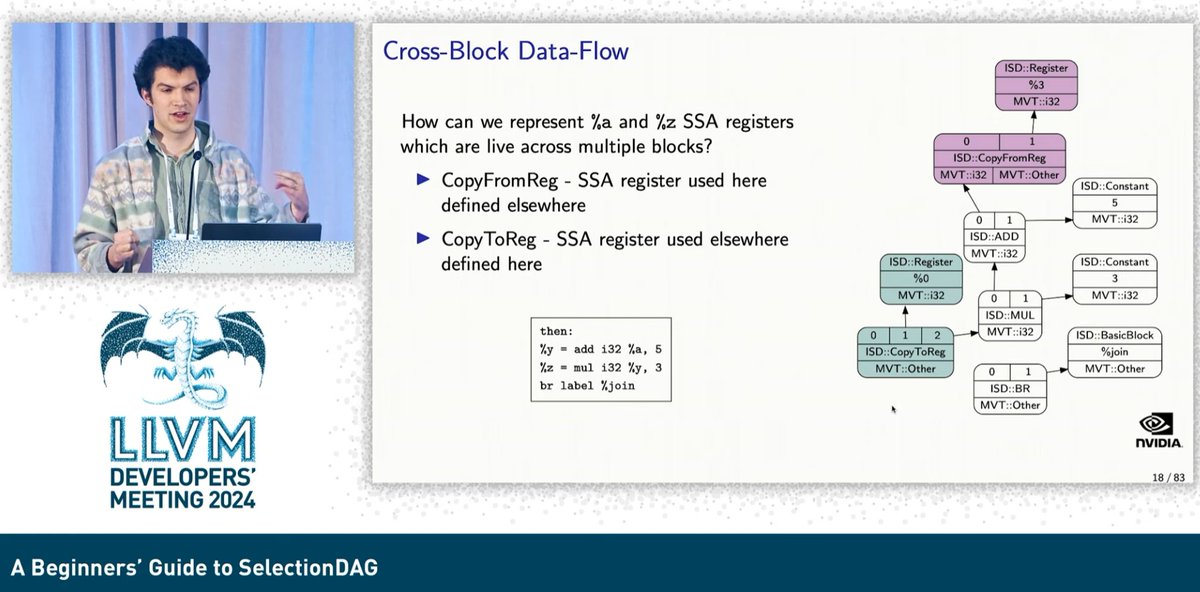
The screenshot is showing how to do it in GlobalISel. In SelectionDAG, you do something similiar, that is, tell legalizer to use libcall for your illegal operation (Node).
for example, in your TargetLowering, do this: setOperationAction(ISD::FADD, MVT::f32, LibCall);
1
112
May 16
x87 being too suck, compilers start to use vector registers to do floating point math
May 14
It has. x87 is specifically designed for floating-point arithmetic.
Originally it was a coprocessor but in the 90s it started to be implemented in the main CPU if I'm not wrong.
2
103
hellowww retweeted

May 8
The tinygrad spec is now merged in tinygrad/spec. Unlike every other ML compiler, all optimization is done in this IR all the way up to instruction selection.


9
29
465
31,003
May 3
I found many algorithm on papers are horrible, seems like they only care about mathematical elegance
1
3
75
hellowww retweeted

May 2
In this paper is proposed CuLifter, a IR lifting framework that recovers register types from NVIDIA SASS binaries via constraint propagation with conflict detection, reconstructs explicit control flow, and aggregates multi-instruction patterns.
arxiv.org/pdf/2604.27486




1
13
50
2,788