
張量殺手
Joined February 2010
- Tweets 10,956
- Following 94
- Followers 865
- Likes 4,526
750 Photos and videos












Pinned Tweet

19 Jul 2025
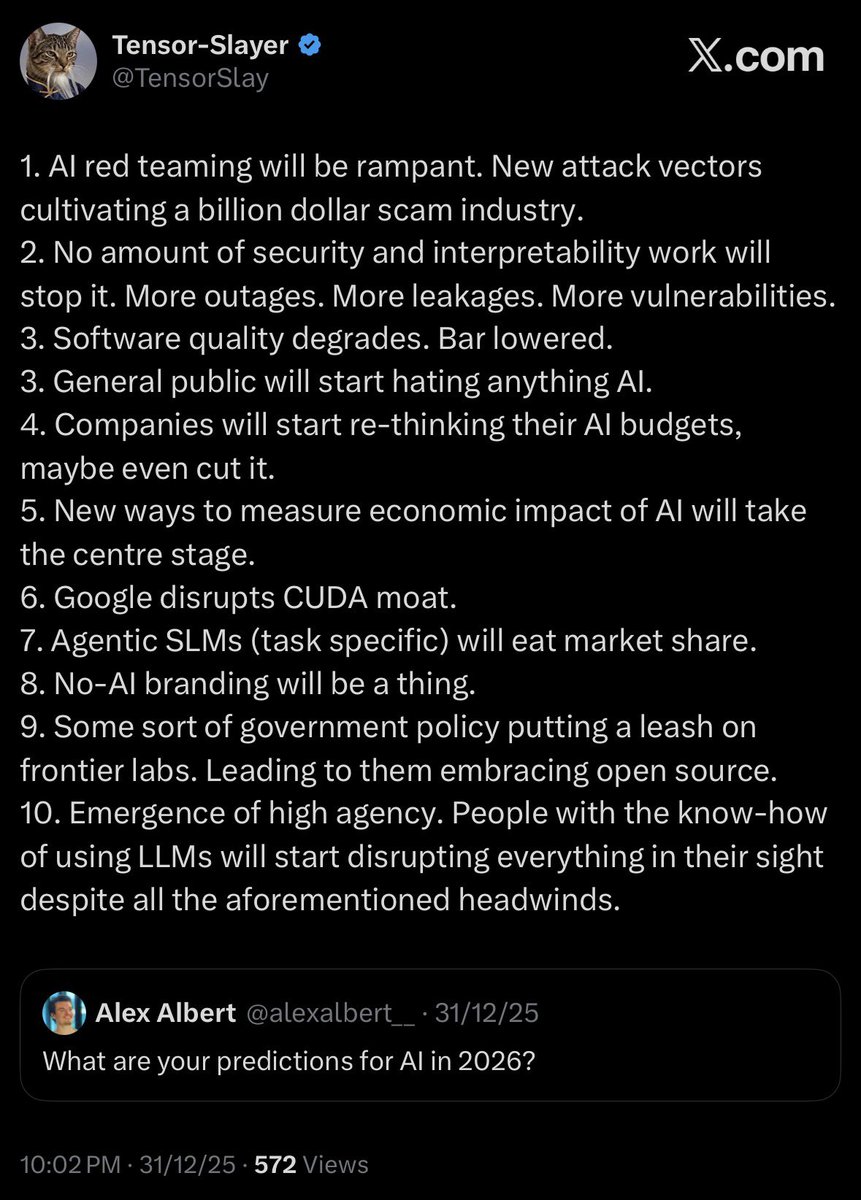
Exploring Direct Tensor Manipulation in Language Models: A Case Study in Binary-Level Model Enhancement: areu01or00.github.io/Tensor-…
1
9
61
16,725
Tensor-Slayer retweeted

My RLM agent can effortlessly process ~80k lines of service logs from CloudWatch
in a single go. that's worth like 8 million tokens.
The cool part is, after 53 steps, it had spent only 32k "active" tokens* (not through the full 8MM yet atp, more like half).
That's nothing for Claude Fable 5 (rip), and weeell within effective context window, so its very "context-efficient".
It can go VERY far and I dont even have to handhold it or anything, i'm not worrying about context running out or compactions either.
I'm saying I kicked this thing off, almost without any context, and it was able to infer the service architecture based on logs alone, and spot issues my team didn't.
In this particular case it was able to narrow down on a specific slice and find a couple issues that flew under the team's radar (AgentCore's throttles, Slack's user_not_found)
Very handy.
I'll release this as OSS soon (my first release on llm tooling!)

3
7
36
2,515
Very important.

In light of what happened, I'm doubling down on skills like /improve.
A frontier model got pulled. If it happened once, it's gonna happen again. Fable today. 4.9 tomorrow or maybe gpt 6 one day.
So, treat intelligence as borrowed. Drain intelligence when it's available. Build a catalog of plans today. Then implement later with a cheaper, open source, or a model you control.
Build the backlog now.
github.com/shadcn/improve
1
63
Tensor-Slayer retweeted

Jun 13
I think there's some confusion about what on-policy distillation (OPD) loss actually optimizes. So here's some math:
If you write down the *sequence-level* reverse KL between a student and teacher model, the gradient would have two terms (see the image below).
- MiniLLM backpropogates through the student's sampling distribution, which makes it akin to policy gradient with dense rewards (but noiser).
- OPD does not add this term, thus it akin to supervised learning, simpler to implement and similar to what DAGGER does.
As such, almost all of the OPD codebases (e.g, Tinker, verl, huggingface) use the implementation suggested by the GKD paper (one on the left).
We did try what MiniLLM suggested but just couldn't get it to work in practice -- overall, my impression back then was that it adds a bunch of complexity and needs stabilization tricks, without clear gains. That said, it is an interesting direction worth studying that why treating distillation as an RL problem doesn't work well or bring benefits (maybe it does in really long-horizon tasks?)
PS: MiniLLM changed their paper title (!) after Thinking Machines blog post LOL to catch the on-policy distill cites ;)
PPS: GKD is a terrible name



6
18
256
23,373
Tensor-Slayer retweeted

It's now possible to compile Python extensions (C, C , Rust etc) to WebAssembly and distribute them through PyPI such that Pyodide can install them directly simonwillison.net/2026/Jun/1…
24
33
321
28,027
Jun 13
Wtf

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

2
149
Jun 13
> what can be done in 100 hours with Opus can done with Fable in 1
Stfu retard
Jun 13

Assuming Anthropic is able to restore Fable in the next few days, there's literally zero point doing any meaningful work until it is back.
What can be done in 100 hours with Opus can be done in 1 with Fable.
Hopefully this is figured out quickly.
1
144
Tensor-Slayer retweeted

Jun 13
Decided to go to DC next week to talk directly with policymakers. Not sure how impactful it will be but with everything happening, feels like a good time to share more about open-source AI, transparency, concentration of power, the real risks vs the real benefits. Who do you think I should meet there (Congress members, WH people, public orgs,...)?
60
44
700
44,134
Jun 13
Prediction 2030s :
(And I have held this opinion since 2022)
Large scale open source training runs will rule this world.
Jun 13

what happens is you make a bigger open source model
1
4
413
Jun 13
Collective training runs : Everyone pooling resources to awaken a machine god
1
1
113
Jun 13
90-day review period prior to release by the government still applies so it doesn’t really matter.
We have decelerated before acceleration even took off.
Jun 13

OpenAI now just needs to sandbag the next model release
So the US doesn't export control them
So they gain massive market share
It's imperative that all the OAI employees don't vauge hype post their next model release as the greatest thing ever
Don't know if they are capable tho
1
101
Jun 13
🤣🤣🤣🤣🤣🤣
Jun 13

to all the people who fell for it and bought a Claude subscription to try Fable
53
Tensor-Slayer retweeted

Jun 12
71
224
1,062
469,876
Jun 13
Ahhahahaha this was my first thought too but government will allow the release eventually maybe something like 90 days as per their earlier directive to frontier labs to get their models evaluated by them before release.
1
61
Jun 13
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
49
Tensor-Slayer retweeted

How do you give a code LLM knowledge of an entire repository without paying for it at every single query?
We introduce Code2LoRA: a hypernetwork that turns a repository into its own LoRA adapter. Repo knowledge baked into weights → zero inference-time token overhead.
40
121
1,213
159,136
Tensor-Slayer retweeted
Jun 12
This graph captures what’s broken about AI evals: they structurally favor closed-source APIs that can route, fallback, ensemble, and optimize behind the scenes with no transparency.
No offense, @ArtificialAnlys, but how is comparing one model to two models fair?
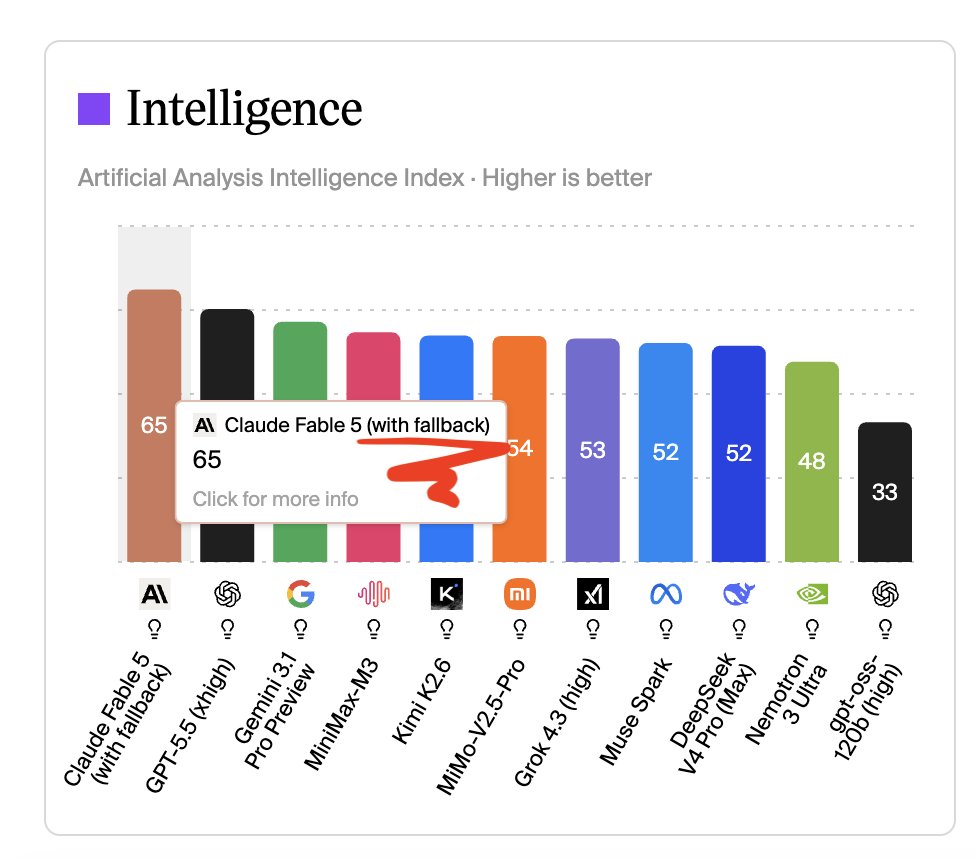
72
44
620
82,380
Tensor-Slayer retweeted

Jun 12
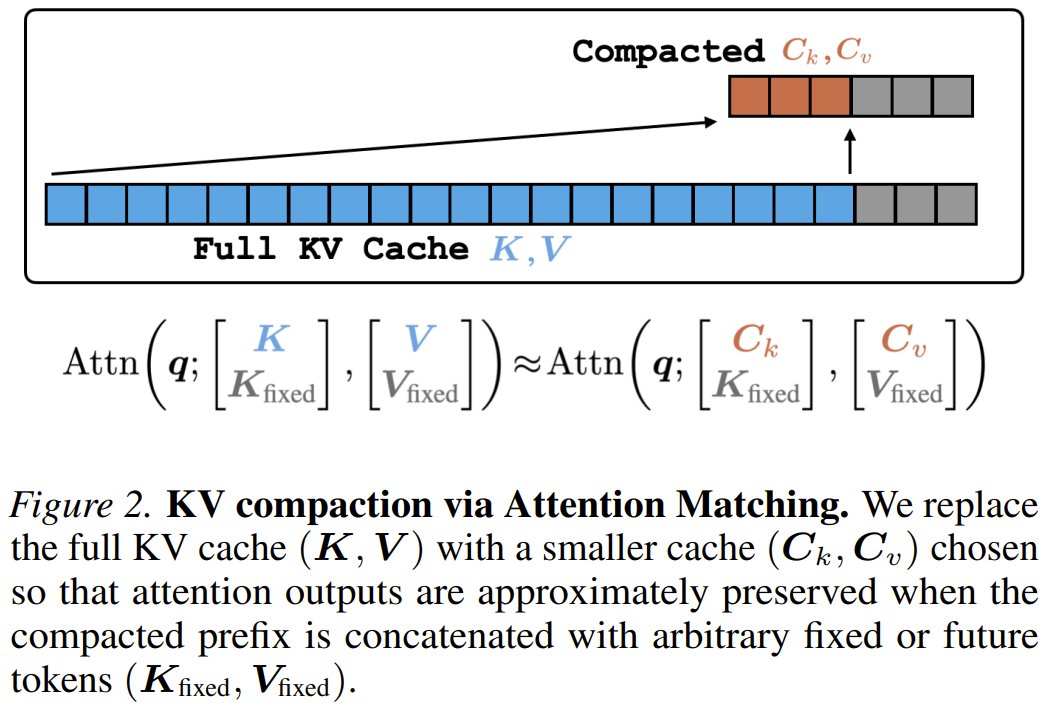
What if you could shrink a language model’s memory by 50x in seconds without losing performance?
MIT researchers present Fast KV Compaction via Attention Matching.
They build compact key-value caches in latent space that preserve attention outputs per head, avoiding slow end-to-end training.
Result: up to 50x compaction in seconds on some datasets with minimal quality loss – outperforming prior methods on the speed vs. quality tradeoff.
Fast KV Compaction via Attention Matching
Paper: arxiv.org/pdf/2602.16284
Code: github.com/adamzweiger/compa…
Our report: mp.weixin.qq.com/s/3wDmtR64s…
📬 #PapersAccepted by Jiqizhixin
1
45
275
14,440
Tensor-Slayer retweeted

Jun 12
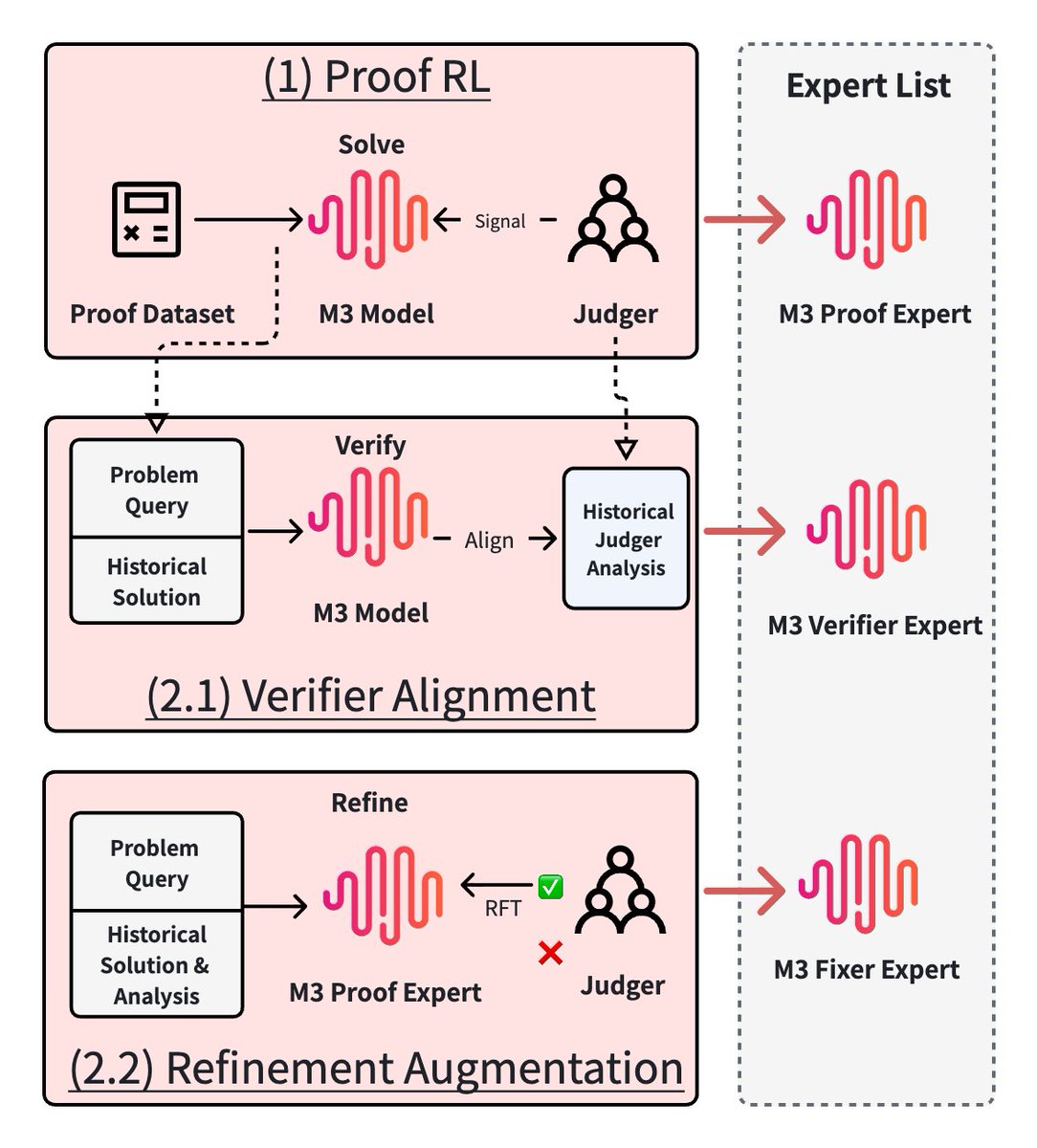
With the MaxProof framework, M3 exceeded the human gold-medal threshold on both sets. In this paper, we go deeper into the technical path behind our progress in mathematical proof: improving the base model, aligning a verifier, building refinement capability, and designing the test-time scaling framework MaxProof.
Here it is
《MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Evolutionary Search》
huggingface.co/papers/2606.1…
8
24
225
21,719
Jun 12
Fable is the new protobuf king
Jun 11

github.com/pydantic/monty/pu…
Opus 4.8 or gpt-5.5 cannot do this.
53
Tensor-Slayer retweeted

Jun 11
Our Scientific Agent Skills now run on OpenClaw, NemoClaw, and Hermes Agent! Already in use by 160,000 scientists worldwide with 28k GitHub stars. Please let us know how we can improve them for you!
github.com/K-Dense-AI/scient…
3
19
140
7,978