
comp bio
Joined April 2025
- Tweets 3,482
- Following 751
- Followers 2,561
- Likes 25,111
431 Photos and videos









Pinned Tweet

Jun 10
The future of biotech looks kinda grim if big labs with unlimited resources keep closing off their model weights like AlphaFold 3, and if LLMs keep cutting you off the moment you ask anything related to biology.
AlphaFold 2 was open, and it changed everything. Everyone could build on it. ESM and OF3 still open source, thankfully, and really close to AF3 after years of work.
And now general LLMS are getting so jumpy, they won't even answer basic biochem questions, just look at Fabel 5. Then there's GPT-Rosalind, OpenAI's model for biology and drug discovery, looks powerful but again locked behind trusted access and enterprise customers. So, unless you're a big pharma or have the right contacts, you are in the permanent underclass. We need much better bio safety guardrails, refusing to answer doesn't make it automatically safer.
5
9
119
7,017
i'm definitely still in a writer's block after that thesis draft
1
2
127
wild to think whales invented the concept of a graveyard millions of years before humans even existed

In 2023, researchers in a deep-sea submersible west of Australia came across several whale skeletons 2400 meters deeper than had ever been described.
As the expedition continued, the scientists found an unprecedented abundance of skeletons—the biggest, deepest, and oldest collection ever seen on the sea floor.
Learn more: scim.ag/4vAI2WV
8
541
a lot of people i've talked to are in comp bio because they were really inspired by alphafold
this is what a good scientific breakthrough does, it makes an entire field feel like the place to be, and pulls in people from physics, math, cs who never thought about biology before
2
1
27
1,700
Stuck with the giants
Jun 13

i made a map of everyone on twitter!
yes you're on there too ^w^
every account is placed next to the people they talk to, so you can find out where you are, which cluster claimed you, and exactly who you're stuck next to
atlas.tiago.zip?ref=launch_t…
2
408
nabbo (bio/acc) retweeted

Jun 13
Meet the members of Proxima:
Anindyadeep (@anindyadeeps) is building Litefold. LiteFold combines physics-based simulation and AI to accelerate the design and validation of drug candidates in silico.
Their leading product is Rosalind: An AI Co-Scientist for Life Sciences.


4
8
52
5,122
nabbo (bio/acc) retweeted

Jun 13
To train a GPT class 1T model from scratch - including failed runs, data acq clean rlhf, post-training, team/people will likely req $250M of compute on an aggressive 3-4mo schedule (i.e. more reserved GPUs), $500-600M all-in IF you do a dense one. MoE fp8 will cut costs by 1/10th depending on how many active params you have. If you want SOTA however, the budgets go significantly higher on test-time compute, post-training RL, and data/synthetic generations..and v. high on talent. Maybe $2-4B all-in. After that comes serving the model. The talent is key to get to SOTA/beat it - and then you have to ensure this is useful enough to have inference vol over time - for which the capital will come if there is usage / TAM. So this is not as much about raising $50-60B, or raising it all at once as the OP says - we are investors in mistral, sarvam, reflection and anthropic - and they all scaled capital over time as models got adoption, but the early bottleneck is more on talent GPUs at that scale where you can do interesting things.
Jun 13

Stop making loose comments. A foundational model needs 50/60b $ Huge hyper cloud capacity with hundreds of billion $
93
273
2,056
241,914

Jun 13
It was Amazon all along lol

🚨US government’s action to shut down Anthropic’s top AI models was actually triggered by an unnamed rival company claiming it could break Mythos’s security, not by China


6
347
Jun 13
when the US finds out i'm using fabel 5
Jun 13

As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
7
1,198
Jun 13
been following spacex even before i knew who elon was, it's just a beautiful feeling how far they have come
3
107
Jun 12
my mind is absolutely blown away, crazy good sensors from precigenetics
Jun 12

@yacineMTB cancer drugs dying as we dose our drugs...
the pink is cytochrome c. as you can see it collects in the mitochondria. then it spreads all over and the cells die!
17
3,471
nabbo (bio/acc) retweeted

Jun 11
Do single-cell foundation models obey scaling laws?
A somewhat thought-provoking new Nature Methods study by the Crawford lab suggests that, for current single-cell foundation models, the answer may be “not really.” Across a broad range of architectures and downstream tasks, increasing pretraining data from hundreds of thousands to tens of millions of cells yielded surprisingly limited gains, with performance often saturating much earlier than expected.
This is interesting and provides exactly the kind of rigorous benchmarking our field needs. As Felix Fischer and I commented in the accompanying Research Briefing, such studies help move the discussion beyond model size and computational budgets toward actual scientific utility.
At the same time, I am not convinced the key conclusion is that scaling does not work in biology. Rather, it may be that current objectives are not extracting enough information from additional data.
Interestingly, in our recent scConcept work, we observe a markedly different scaling behavior, with continued gains as training data grows toward hundreds of millions of cells. The key difference may be the training objective itself: instead of reconstruction-based masked modeling, scConcept uses a contrastive objective that directly optimizes biologically meaningful cell representations.
biorxiv.org/content/10.1101/…
This raises an interesting question for the field: Have we reached the limits of data scaling, or only the limits of current objectives?
-> My guess is that the next generation of biological foundation models will depend less on simply collecting more cells and more on finding the right representation learning principles for biology.
Nature Methods paper:
nature.com/articles/s41592-0…
Research Briefing:
nature.com/articles/s41592-0…
#SingleCell #FoundationModels #AIforBiology

10
52
226
27,950
nabbo (bio/acc) retweeted

Jun 11
Together with UC Berkeley we are announcing the laser phase plate - a breakthrough in atomic resolution imaging. This is the brightest continuous wave laser in the world, 100 million times the intensity of the surface of the sun.
Phase contrast plays an important role in microscopy, but it was thought close to impossible for electron microscopy, where it would require interfering with an electron beam. Holger Mueller and Robert Glaeser proposed exactly this using a standing wave laser. It has taken over 15 years to make this a reality. Biohub partnered with UC Berkeley and Mueller to support this work and to engineer and build the technology.
Contrast has been the critical barrier to achieving atomic resolution imaging of the cell. In cryo-electron tomography, a cellular imaging technology that uses electron microscopy, the low contrast makes it impossible to resolve anything but the largest proteins within their cellular context. The laser phase plate removes that barrier.
With advances in AI this breakthrough in contrast will start to open up a new frontier in structural biology, that will allow us to see the molecular machines of the cell, and how they assemble into far more complex and dynamic systems, and understand how they work.
85
530
3,710
578,991
nabbo (bio/acc) retweeted

Jun 11
@mihirbafna14 and I are excited to introduce Promera, a co-folding and design model with
• best-in-class binder filtering
• nanobody design with in-silico success rates matching hallucination
• case studies on hantavirus epitope targeting and GPCR agonism (1/8)
7
59
279
42,361
Jun 11
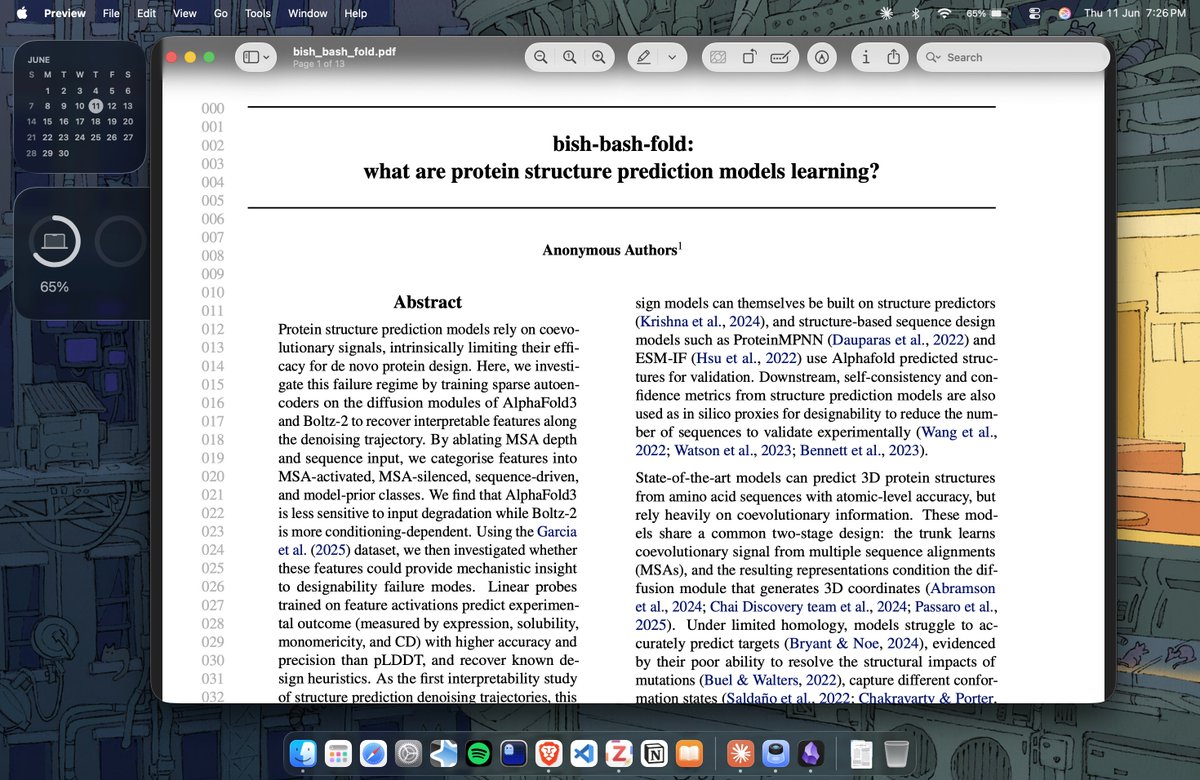
Came across an interesting paper today which trains sparse autoencoders on AF3 vs Boltz-2 denoising trajectory.
AF3 builds bottom-up from local physicochemical features residue identity, charge, hydrophobicity early, then global stuff like coiled-coils and tertiary packing etc. whereas Boltz-2 commits to protein-identity and domain features early (pattern matching).
Also, the model's internal features read via the sparse autoencoders predict designability (expression, solubility, etc.) works more accurately than pLDDT
2
12
84
4,966
Jun 11
still a no for biology if you are wondering, it's a shame

NEW: Anthropic is walking back Claude Fable 5's policy to covertly degrade performance for competing AI researchers, after facing fierce backlash.
“We’re changing Fable 5’s safeguards for frontier LLM development to make them visible,” Anthropic tells WIRED. “We made the wrong tradeoff and we apologize for not getting the balance right.”

6
1
28
1,600