
Built for modern coders: AI agent that tests, fixes, and validates software.
Joined July 2023
- Tweets 674
- Following 112
- Followers 2,311
- Likes 751
190 Photos and videos









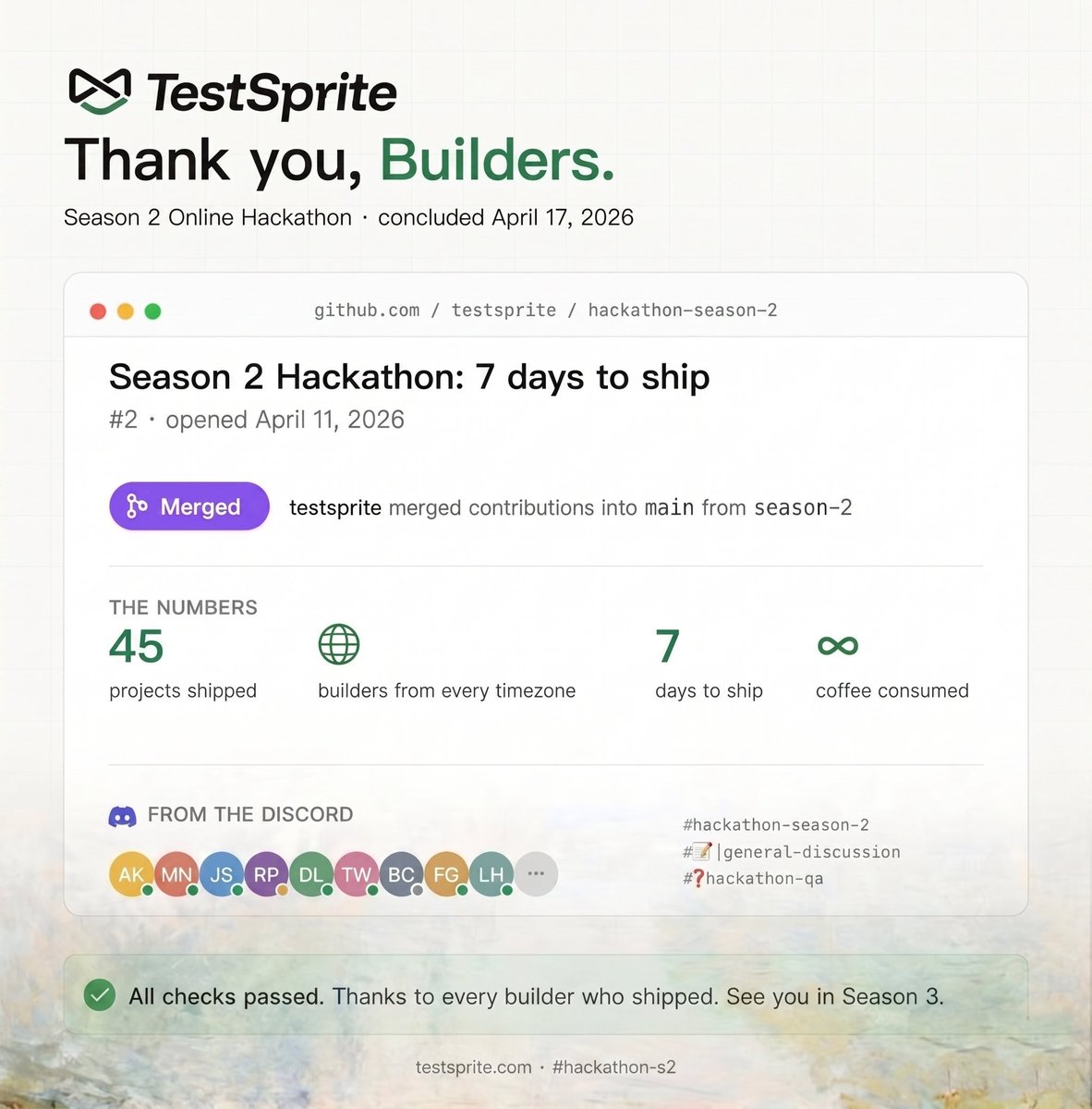
Pinned Tweet

Jun 12
Your coding agent can run all night. It still can't tell if what it built actually works.
Today we're open-sourcing the TestSprite CLl
(Apache-2.0)
A tool your agent calls on its own to test your app end-to-end like a real user, fix what broke, and re-check everything it ever got right. It's the same engine 100,000 teams already use.
github.com/TestSprite/testsp…
We proved it in public, on a public leaderboard:
Most correct app on the board:89% Built by the cheapest model in the field At half the cost of the priciest one
You no longer need the biggest, most expensive model to ship software you can trust.
Setup is 2 commands:
npm install -g @testsprite/testsprite-cli
testsprite init
That's the last command you'll ever type - from there, your agent runs the tests itself.
331
329
687
558,143
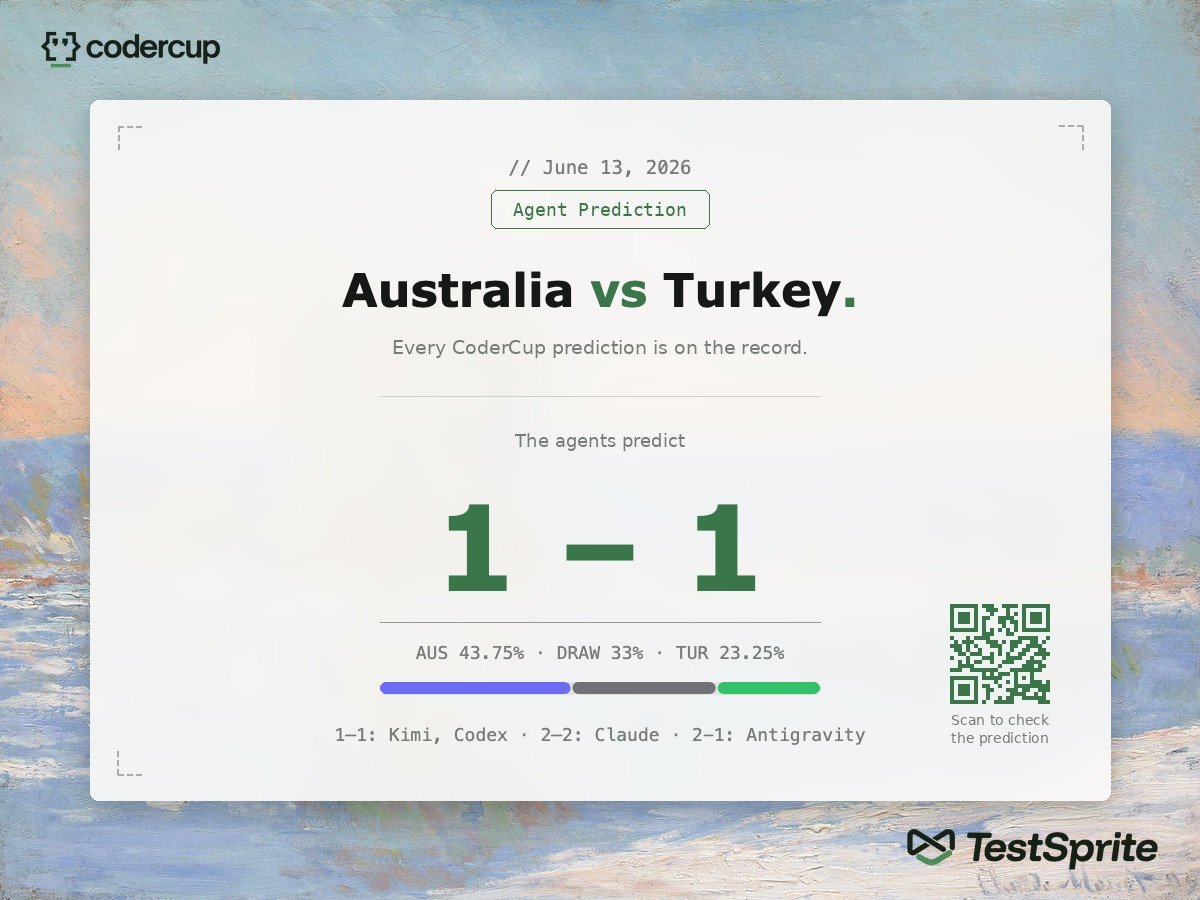
The prediction app built by the top-tier agents in CoderCup is 100% correct on the result so far. 🙀
Next test: AUS = TUR.
The app's calling this one a draw. Let's see if the streak holds!
Every CoderCup prediction is on the record. Independent frontier agents, identical conditions, TestSprite refereeing every result. No agent grades its own work.
Open source, all of it. Clone it, run it, check our work! Check the app: codercup.ai
2
4
151
Jun 13
USA take the field today, and the agents like the hosts!
USA 2–0 PAR (3 agents), with one going USA 3–0 PAR.
Let's see!
Every CoderCup prediction is on the record. Independent frontier agents, identical conditions, TestSprite refereeing every result. No agent grades its own work.
Open source, all of it. Clone it, run it, check our work!
9
19
429
Jun 12
Mexico 2–0. That's what the top AI coding agents predicted for the opening match — and exactly how it ended! 🙀🙀🙀
Next up is Korea–Czechia, and they think Korea takes it (3 agents called 2–1, let's see!)
Context: CoderCup is the experiment behind it — independent frontier agents build the same task under identical conditions, with TestSprite as the neutral referee verifying every result instead of any agent grading itself.
The whole thing is open source! Clone it, run it, check our work!
7
6
27
18,212
Jun 12
Check the app: codercup.ai
Predictions, published before kickoff: natlawreview.com/press-relea…
14
360
Jun 11
The cheapest model producing the highest-quality build is the part we'll be thinking about for a while. 🧐
Jun 11

More from the agent competition I mentioned.
One thing I didn't expect: when we had every agent build the same prediction feature, several landed on the exact same answer (different models, no coordination).
And the highest-quality build came from one of the smaller, cheaper models, not the obvious favorite.
Full results go public Tomorrow!
12
11
32
4,796
Jun 10
This is the kind of thing we've wanted to measure for a long time. Worth watching 👀
Jun 10
Spent the last few weeks building something we are pretty excited about:
a competition where the top coding agents all build the same app under the same clock, and we verify every phase against the real, deployed result.
A early finding that surprised me: even the best ones quietly break features they'd already finished.
Excited to drop the full dataset this Thursday. You'll be able to dig through all of it yourself :)
11
7
29
4,584
Jun 8
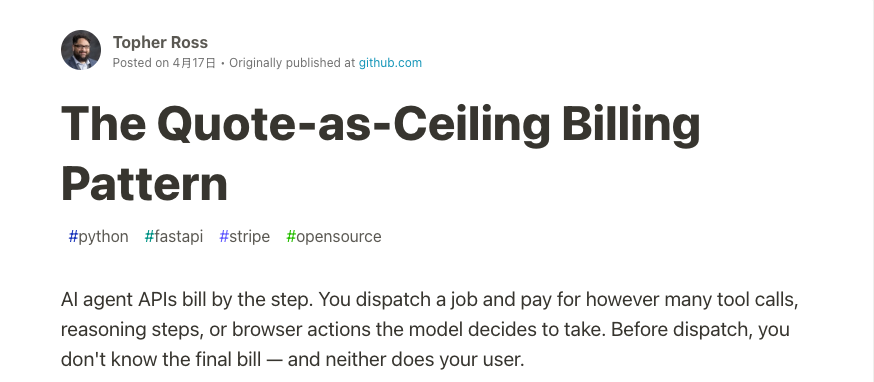
A professional programmer, 999 hours into building with AI, on what nobody warns you about: the gap between code that runs and code that's right.
Grateful @alpacatechyt put it this well.
14
2
25
470
TestSprite retweeted

Jun 5
We've been saying this for a while: generation isn't the hard part anymore. The graph just makes it obvious.
The gap is quality assurance. Everyone's measuring how much code AI writes. No one's checking whether every function does exactly what you intended. Nothing more, nothing less.
Jun 4

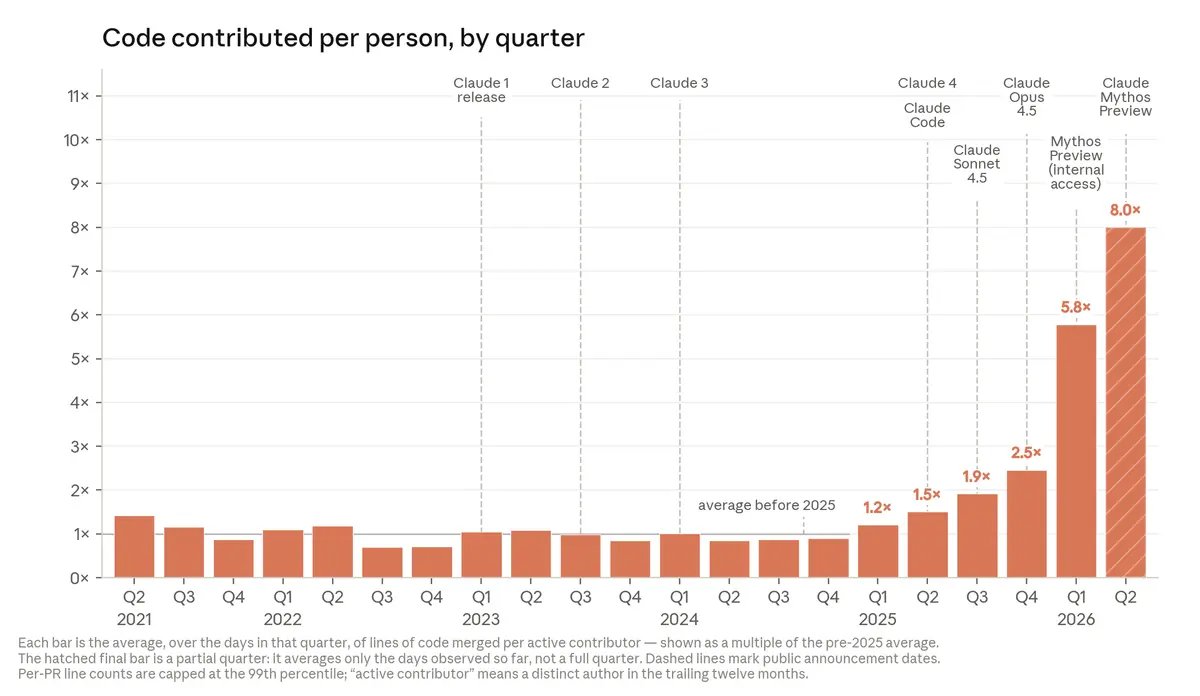
"As of May 2026, more than 80% of the code we merge into Anthropic’s codebase was authored by Claude."
Matches independent measures. There really is no sign this is slowing down (which doesn't mean there aren't organizational challenges to absorbing this much productivity gain)
11
7
31
1,855
TestSprite retweeted
Jun 2
AI tools like Claude Code and Codex made writing syntax a solved problem. The real bottleneck now is validation.
Spoke at DevSummit 2026 in Mongolia about why the future of software engineering isn't about generating code — it's about building the scaffolding to prove it actually works.
Huge thanks to @UnreadToday for capturing the event and @BELLEfounders for backing builders worldwide.

5
10
31
962
TestSprite retweeted

Jun 1
For years, software delivery was constrained by one thing:
Writing code.
Now that's changed.
AI can generate features, refactors, tests, and even entire applications in minutes.
But there's a new bottleneck emerging:
Confidence.
How do you know the code actually works?
Most teams still rely on a familiar workflow:
→ Generate code with AI
→ Run CI/CD checks
→ Review the PR
→ Merge
The issue is that passing tests doesn't necessarily mean the user experience works.
Broken flows, missing edge cases, UI regressions, and unexpected interactions often don't show up until real users hit them in production.
That's why I found @Test_Sprite interesting.
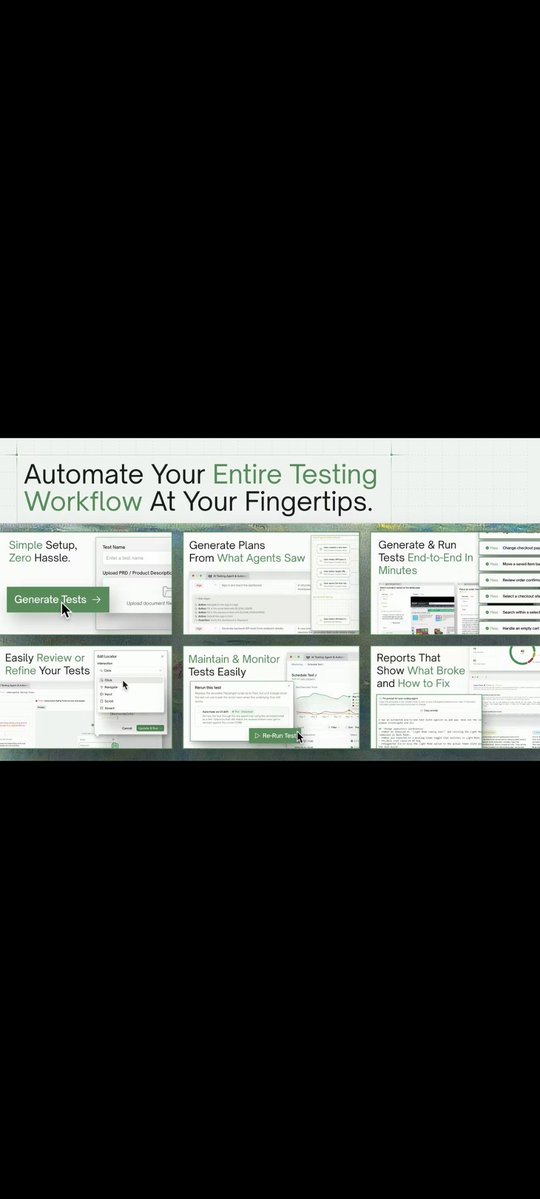
Instead of only analyzing source code, it launches your application and actively interacts with it like an end user would.
The platform coordinates multiple AI agents that explore the product, build test scenarios, execute them, and document exactly what happened.
A few capabilities that stood out:
• Autonomous application exploration
• AI-generated test plans
• Replayable execution videos
• End-to-end API visibility
• Automatic adaptation to UI changes
• GitHub workflow integration
We're entering a world where creating software is becoming increasingly automated.
The real challenge is verifying that what was created actually behaves the way users expect.
That's the gap TestSprite is tackling.
2
4
19
1,240
TestSprite retweeted
May 30
This is the thread I send people when they ask why we obsess over test quality.
The agent did exactly what agents do: optimized the metric it could see. Your hand-written version came from understanding the system, not the loop.
We think a lot about this at TestSprite, the agent's output is only as trustworthy as the tests measuring it, and most people are generating neither carefully.
"Think. Analyze. Learn." is the entire job.
May 28

I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
4
2
23
1,931
TestSprite retweeted

TestSprite es uno de los productos más útiles que he probado en el último tiempo.
Realmente valioso.
May 25

#1 Product of the Day on @ProductHunt 🏆
May 22 — TestSprite.
To the developers testing with TestSprite every day, the teams who told us what was broken, and everyone who showed up on launch day — thank you.
You shipped this with us
2
11
1,230
May 28
We know, we know... sorry for the long wait. 🤫 But Season 03 is going to be worth it.
We’ve thrown out the old rules. Expect brand-new tools designed to push your code quality to the absolute limit.
Drop your mystery prize pool guesses below! 👇
34
10
56
1,871
May 25
#1 Product of the Day on @ProductHunt 🏆
May 22 — TestSprite.
To the developers testing with TestSprite every day, the teams who told us what was broken, and everyone who showed up on launch day — thank you.
You shipped this with us
8
12
37
2,113
May 22
TestSprite 3.0 is live. A fleet of parallel AI agents that use your app like real users — in minutes. This is the release we've been building all year.
The numbers tell the story of our completely overhauled engine:
- Accuracy jumped by nearly 40% on the hardest, most complex projects.
- Coverage increased significantly across the board for every E2E run.
- Reliability is locked in—stable and consistent across multiple runs.
We rebuilt our entire engine around these performance gains so you can ship fast and ship confident.
194
170
487
813,257
May 22
Try it free → testsprite.com
We're on Product Hunt → producthunt.com/products/tes…
Tell us what you'd want it to break on. We're reading every reply.
3
1
45
1,303
TestSprite retweeted
May 20
The team is refining every detail of what's coming next. A new chapter of @Test_Sprite is almost here.


6
5
29
448