
Joined December 2018
- Tweets 5,805
- Following 1,212
- Followers 8,144
- Likes 33,252
482 Photos and videos








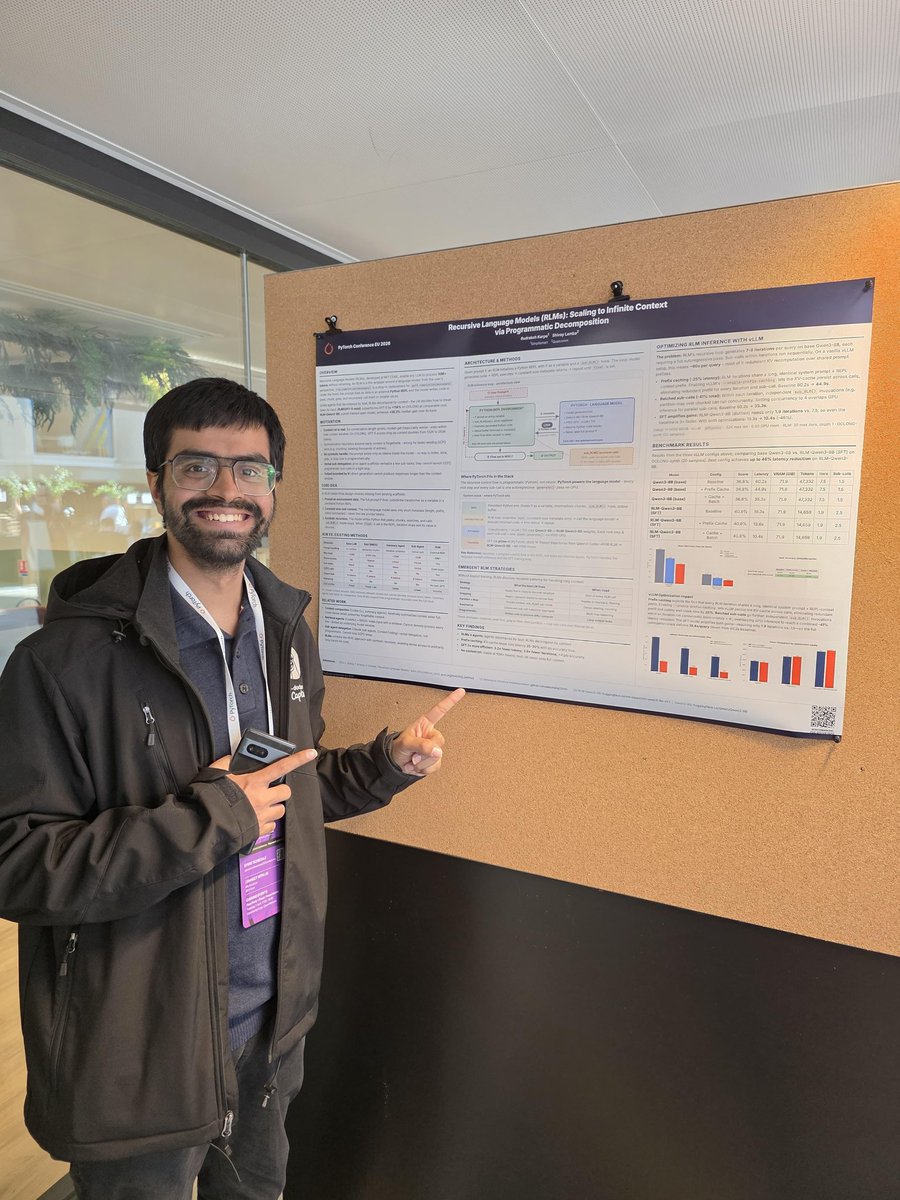
Pinned Tweet

Apr 8
What an amazing day! Presented a poster at @PyTorch Conference: how we optimised the RLM paper with pre-fix caching & batched Sub calls with @vllm_project
And a full house for our Pytorch Conference talk on running LLMs using Executorch on Android!

4
3
68
7,747

GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
204
559
5,734
639,181
Shivay Lamba retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,089
25,253
85,479
83,403,795
Shivay Lamba retweeted

Jun 11
Calling all developers and innovators!
The Snapdragon Multiverse Hackathon is here. Create real-world AI solutions across PC, mobile, IoT, and cloud.
📍 Qualcomm Building N, Bengaluru — July 11
🔗 Register here: qualcomm.com/developer/event…
📍 Qualcomm Campus, Noida — July 18
🔗 Register here: qualcomm.com/developer/event…
Form your team, submit your idea, and start building what’s next!

1
16
24
2,139
Shivay Lamba retweeted

Jun 10
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
169
805
5,012
913,126

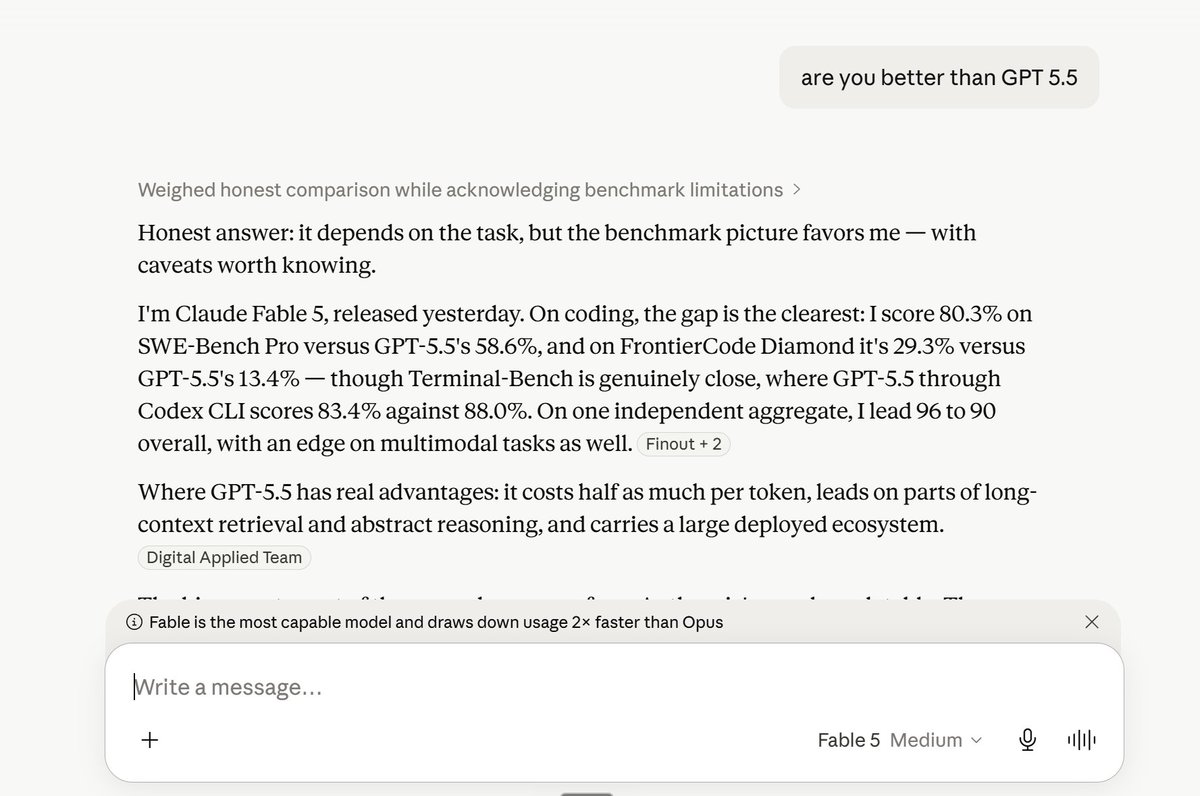
Claude Fable 5 is by far the most ridiculous model that makes me genuinely afraid for the future of software engineering.
I compiled the top 10 most unbelievable things I've seen Claude Fable 5 do today:
— Migrate a 50M line codebase from Stripe in a day (humans take 2mos)
— Draw amazing 3D graphics a) Boeing 747 b) space simulations with >5000 objects c) Minecraft roller coasters d) full photorealistic forest scenes e) NYC skyline f) stormy clouds)
— One-shot Pokemon FireRed the game
— Optimize a real world proprietary interaction net evaluator 10x more than the next best model, gpt5.5
AND it's about the same price as GPT 5.5 ($10/M input, $45/M output) vs Fable 5 ($10/M input, $50/M output) and 6x cheaper than GPT 5.5 Pro.
Community note
The claim misrepresents Anthropic's report: Fable 5 performed a codebase-wide migration within a 50M-line codebase in one day, not a full 50M-line migration. GPT-5.5 standard pricing is $5/M input and $30/M output, not the $10/$45 long-context rates used in the comparison. anthropic.com/news/claude-fa… developers.openai.com/api/docs/prici…
391
425
6,157
915,024

Shivay Lamba retweeted

Jun 9
Today we're launching Raah.
Analytics and observability for your website, in one place.
→ Real traffic, errors, and Core Web Vitals from actual users
→ Page and API latency tracking
→ Session replays
→ An AI Chat that tells you what's broken based on your production data
Try Now: raah.dev
31
28
102
28,084
Shivay Lamba retweeted

Jun 8
30
148
1,108
584,352

Build on-device AI with ExecuTorch on @Snapdragon .
The ExecuTorch Hackathon brings developers to San Francisco on June 27–28 to build and optimize real-time AI applications that run directly on Snapdragon-powered mobile devices. Participants will build on Samsung Galaxy S25 Ultra devices powered by Snapdragon and receive mentorship and hands-on support from @Qualcomm and @Meta experts.
Learn more and register: pytorch.org/event/executorch…
Applications close June 15.

7
7
36
6,709
Jun 8
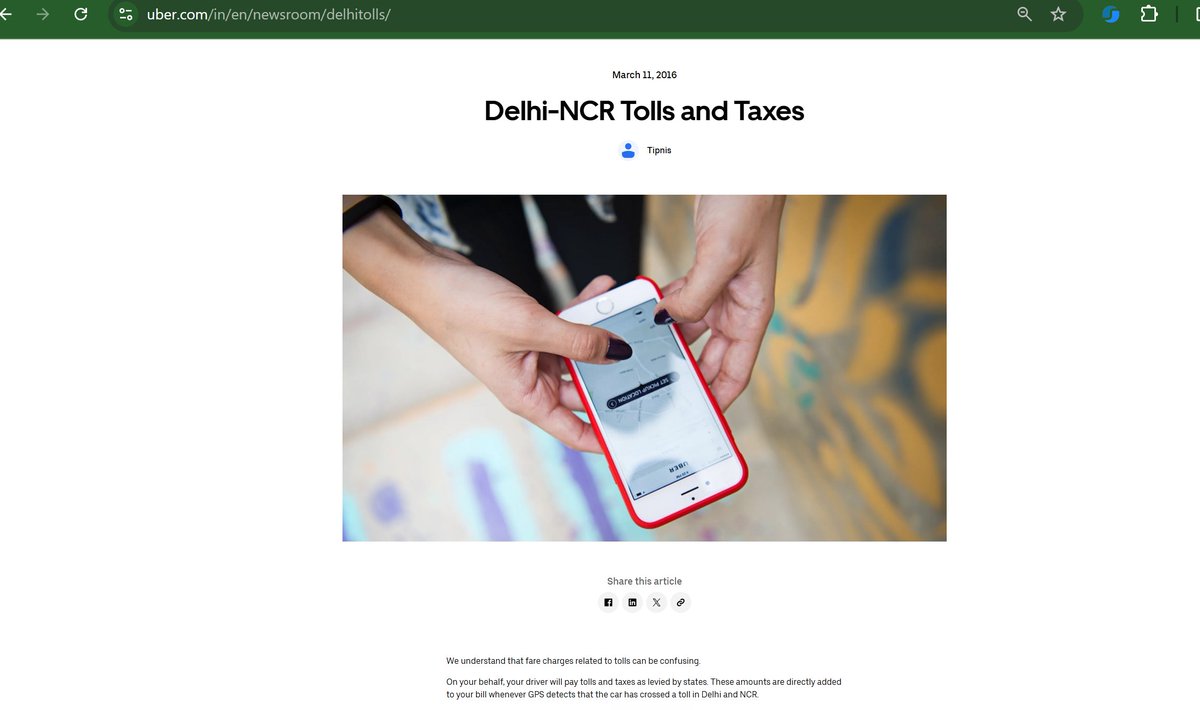
You know you're using a ride-sharing app in India when:
• The driver asks you to cancel the ride and go "offline" instead.
• Tries to collect toll money that's already included in the fare.
• Spends the trip speaking loudly or hurling abuses on the phone without even caring to ask the passenger
P.S. not every driver is like this, but it happens too often than one would like. Professionism is lacking
4
29
4,641
Jun 8
Jun 7

The Mega KubeCon CloudNativeCon India Livestream is happening tomorrow with amazing speakers and giveaways so do not miss this one.
12
653
Shivay Lamba retweeted

Jun 7
Tokenmaxxing is dead. Everyone's realized that token usage is a horrible way to measure productivity. So where do we go from here?
The next phase of AI adoption will be based on output, impact, and value you can trace: how much real value are you getting from each agent session?
Here are some of the ways we're addressing this at @cognition:
1. Adaptive Routing - an intelligent model router that automatically selects the best AI model for each task. (other products are also starting to adopt this)
2. Spend Attribution - @cognition auto-classifies every agent session by what it actually did (feature work, bug fixing, migrations, tests) and shows admins the spend behind each, right next to PRs merged. You can draw a straight line from every dollar spent to the outcome it bought.
3. Advanced automations - wiring agent sessions to the events that already cost teams engineering hours: production incidents in PagerDuty, failing deploys, alerts on a revenue-critical service. Each trigger maps to work that used to page a human, so the value isn't theoretical, it can be traced straight to the work it replaced.
4. AI Productivity Guarantee - if @DevinAI delivers less engineering value than you’re paying for, @cognition will fund your usage until it does, up to $10 million for Enterprise customers.
These are just some of the areas we're actioning and exploring, but the broader point is this: the design space for measuring AI value is still wide open. The winners will be the teams that can prove, compound, and operationalize the most impact.



53
24
369
83,738
Jun 6
Excited to be renewed as a @Docker Captain for another year!
As AI coding agents, coding harnesses, and MCP-powered workflows move into production, secure execution environments and trusted infrastructure are becoming essential.
Technologies like Docker Sandbox, Docker Hardened Images will play a key role in enabling the next generation of agentic applications.
Looking forward to continuing to learn, build, and contribute with the container community! 🚀
12
1
70
2,739
Shivay Lamba retweeted

Gemma 4 quantization-aware training (QAT) models are now available, bringing AI performance directly to edge devices and consumer GPUs. These checkpoints are optimized with quantization-aware training to dramatically reduce memory requirements and unlock high-speed local inference. 🧵

ALT Gemma 4 QAT
33
144
1,217
79,383
Shivay Lamba retweeted

Jun 4
31
84
1,092
313,861
Shivay Lamba retweeted

Just tried @NVIDIAAI Nemotron-3-Ultra on @nebiustf playground.
Gave it a reasoning prompt. Here's what it did:
• 807ms time to first token
• 6.5s total time
• 126.3 tokens/s
For a 550B MoE model, this is fast. Worth testing if you're building agents.
Demo:

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
2
4
8
1,411

Shivay Lamba retweeted
Jun 3
What happens when your AI coding agent hits an unexpected failure?
For a number of teams, the workflow is still surprisingly manual: inspect the logs, copy the stack trace, trace the root cause, and patch it yourself.
But agents shouldn't stop at generating code, they should be able to debug it too.
In this tutorial, I built a self-repairing agent workflow where the agent can investigate its own failures by accessing production telemetry, analyzing traces, and using that context to identify and resolve issues autonomously.
youtube.com/watch?v=FquPk9jt…
5
8
29
1,858
Shivay Lamba retweeted

Jun 4
Excited to launch OpenHack! 🚀
A fully open source agentic security scanner to hunt and verify security vulnerabilities.
Upto 40x cheaper, it is on par with Claude Opus 4.6 on CVE-Bench for finding logic based vulnerabilities in web apps.
30
20
97
13,790