
Working on jj-fzf (Jujutsu TUI), Anklang (DAW), Imagewmark, Audiowmark; github.com/tim-janik
Joined October 2011
- Tweets 1,032
- Following 498
- Followers 1,167
- Likes 1,284
111 Photos and videos


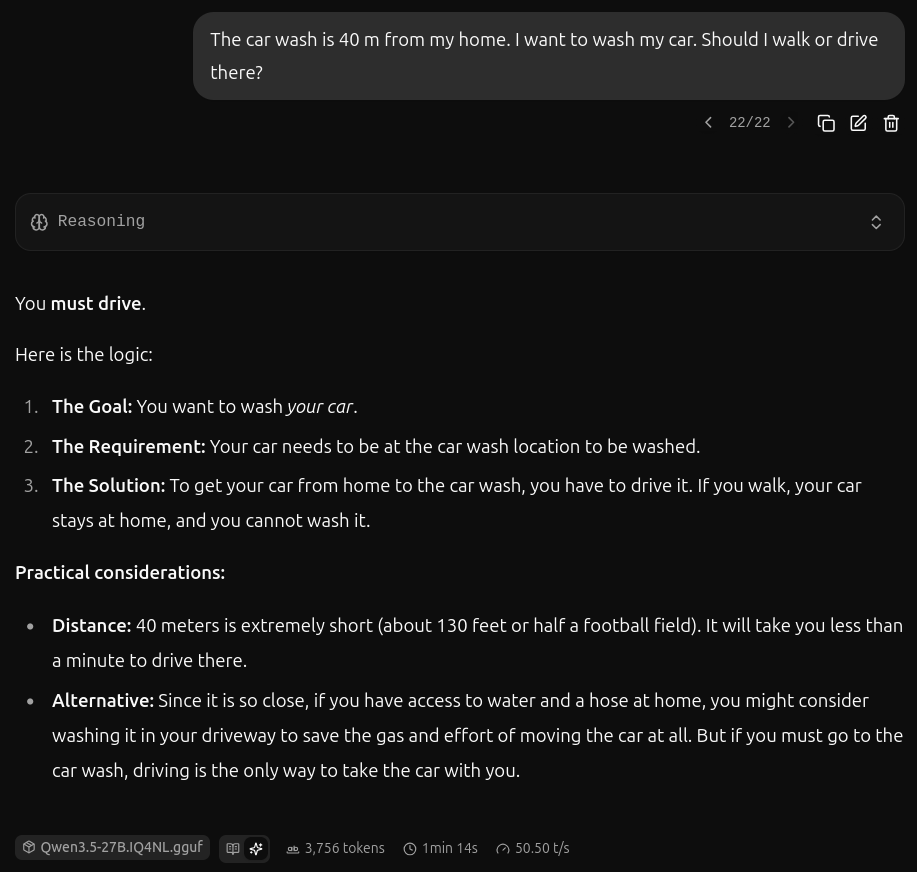



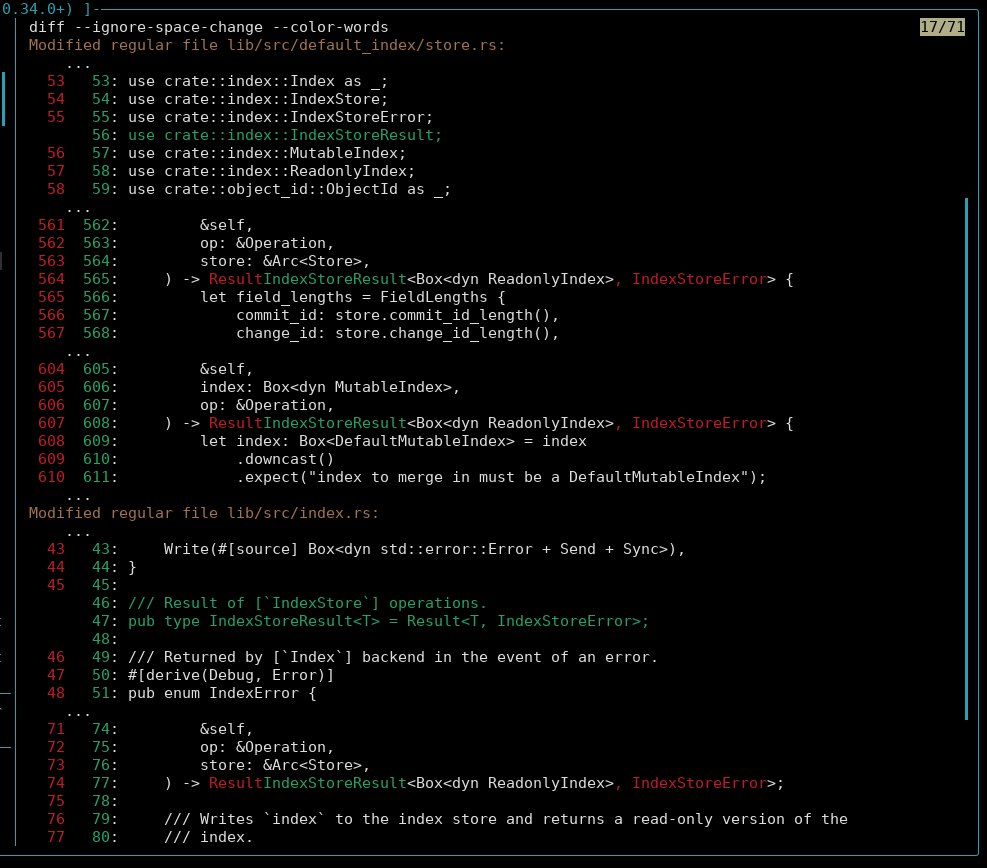

Are Local LLMs Ready for Production?
I gave a local Qwen3.6-27B a try at a real world task.
testbit.eu/2026/local_llms_f…
1
347
Recommended reading, frontier models aren't really close to each other on DeepSWE, Looking forward to the C version!
x.com/serenaa_ge/status/2059…
May 26

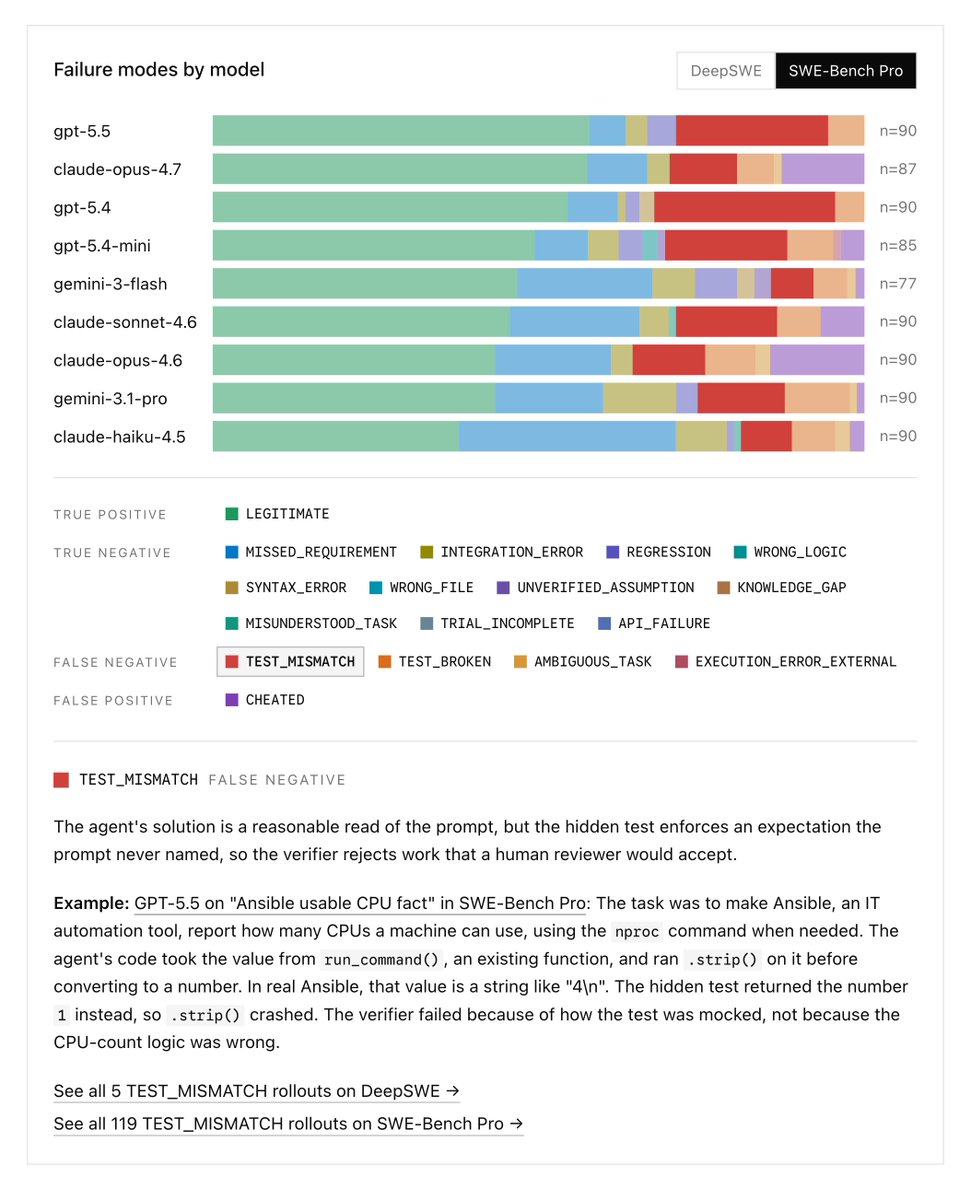
To ensure our grading is fair and reliable, we built a trajectory analysis agent to replay agent rollouts and map out exactly why they fail.
Running it on existing benchmarks surfaced significant grading noise, with verifiers rejecting valid code or letting models read solutions straight from git history.
93
Why local LLMs mean peace of mind:
x.com/TimJanik/status/205822…

Are Local LLMs Ready for Production?
I gave a local Qwen3.6-27B a try at a real world task.
testbit.eu/2026/local_llms_f…
240
Thoughtful explanation without oversimplification.
Well recommended read:
AI Cannot Self Improve and Math behind PROVES IT!
smsk.dev/2026/04/26/ai-canno…
100
Wow, Qwen3.6-27B closing in on Gemini 3.1 Pro on SWE-Bench Pro??
Qwen3.6-35B-A3B was already great for smaller Laptop GPUs (6GB), the 27B should be a great fit for larger consumer GPUs (24GB) and should surpass 35B-A3B by a strong margin.
Downloading for quantization now… 🫢
Apr 22

🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power!
Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇
What's new:
🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks
💡 Strong reasoning across text & multimodal tasks
🔄 Supports thinking & non-thinking modes
✅ Apache 2.0 — fully open, fully yours
Smaller model. Bigger results. Community's favorite. ❤️
We can't wait to see what you build with Qwen3.6-27B! 👀
🔗👇
Blog: qwen.ai/blog?id=qwen3.6-27b
Qwen Studio: chat.qwen.ai/?models=qwen3.6…
Github: github.com/QwenLM/Qwen3.6
Hugging Face:
huggingface.co/Qwen/Qwen3.6-…
huggingface.co/Qwen/Qwen3.6-…
ModelScope:
modelscope.cn/models/Qwen/Qw…
modelscope.cn/models/Qwen/Qw…

1
3
2,361
This model indeed works acceptably on a RTX 3060 Laptop GPU w/ 6GB VRAM:
llama-server -c 98304 -m Qwen3.6-35B-A3B-UD-IQ3_XXS.gguf -fitt 512 --temp 0.6 --top_p 0.95 --top_k 20 --min_p 0
Runs at ca 22 tok/s!
(kv quantization would be marginally faster but generates worse output)
Exciting!
Seeing these benchmarks, Qwen3.6-35B-A3B could potentially bring Qwen3.5-27B / Gemma4-31B quality inference to small laptop GPUs.
I will give this a test run a on an NVIDIA GeForce RTX 3060 Laptop GPU and report back.
9
1,148
Exciting!
Seeing these benchmarks, Qwen3.6-35B-A3B could potentially bring Qwen3.5-27B / Gemma4-31B quality inference to small laptop GPUs.
I will give this a test run a on an NVIDIA GeForce RTX 3060 Laptop GPU and report back.
Apr 16
⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀
A sparse MoE model, 35B total params, 3B active. Apache 2.0 license.
🔥 Agentic coding on par with models 10x its active size
📷 Strong multimodal perception and reasoning ability
🧠 Multimodal thinking non-thinking modes
Efficient. Powerful. Versatile. Try it now👇
Blog:qwen.ai/blog?id=qwen3.6-35b-…
Qwen Studio:chat.qwen.ai
HuggingFace:huggingface.co/Qwen/Qwen3.6-…
ModelScope:modelscope.cn/models/Qwen/Qw…
API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned

4
1,847
Orion currently behind the moon, here's the NASA feed for when it comes back:
youtube.com/watch?v=m3kR2KK8…
111
Imagewmark 0.6.0 🚀
🖼️ C #watermarking (much faster, lower RAM)
🔧 Split arch: C for embedding, Python for extraction
⚙️ New test‑suite attacks: gamma, brightness‑contrast
🐞 Fixes: .ppm/.tif support, sign‑preservation
🔍 Blind detection
Contributor: @polysynth
1
2
364
Imagewmark 0.6.0 Article:
testbit.eu/2026/imagewmark-0…
Release Downloads:
github.com/tim-janik/imagewm…
#ImageWatermarking
3
70
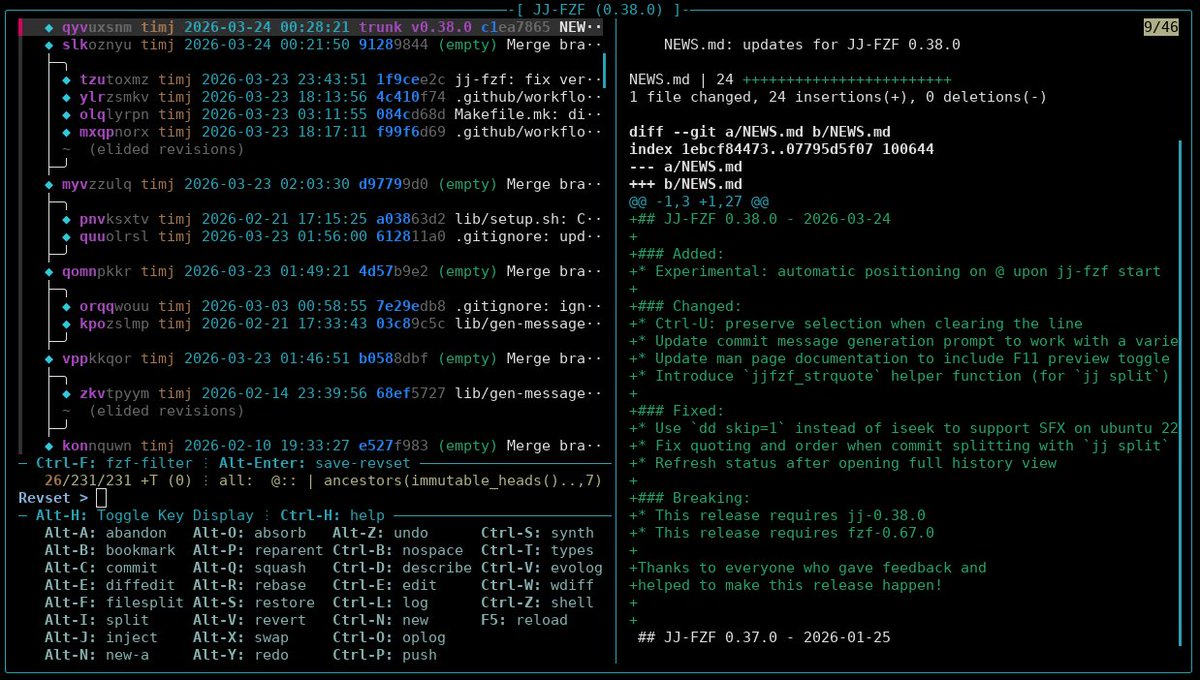
Detailed jj-fzf 0.38.0 release notes are up.
They cover the new experimental positioning, selections, #LLM improvements and SFX fixes.
Details upgrade path:
testbit.eu/2026/jj-fzf-0.38.…
Feedback on the cursor behaviour or further refinements are welcome as GitHub issues.
3
355
jj-fzf Repo:
github.com/tim-janik/jj-fzf
#100DaysOfCode
1
57
Another saddening aspect of this is that we increasingly see Open Source developers spend their time and energy reviewing *other* people's non-reviewed LLM slop, simply because they care while the vibe coders don't.
That's some seriously unhealthy asymmetry there.

1
235
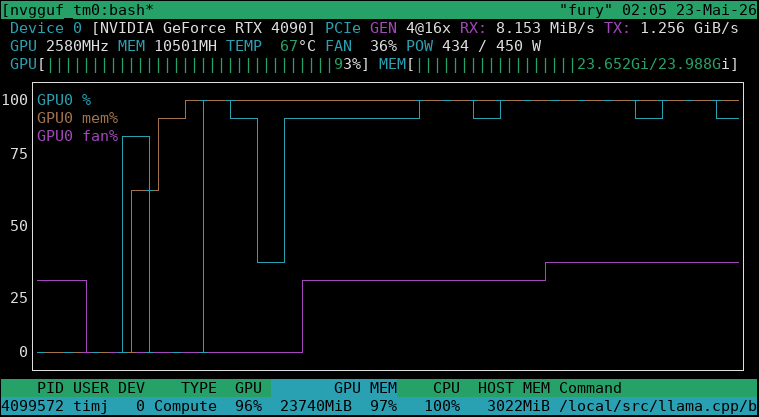
Nice speedups in llama.cpp lately.
WIth the right set of flags, Qwen3.5-27B runs at 50tok/s VL embedder on a 4090 at 24GB VRAM:
llama-server -c 0 -m Qwen3.5-27B.IQ4NL.gguf -ngl 99 --cache-type-k q4_0 --cache-type-v q4_0 -ub 1024 -b 2048 --mmproj Qwen3.5-27B.F16.mmproj.gguf
2
201
LLM Neuroanatomy: How I Topped the AI Leaderboard Without Changing a Single Weight
dnhkng.github.io/posts/rys/
56