
Now @tigerdatabase. The modern cloud platform built on PostgreSQL for time series, events, and analytics (and vectors too). ⭐️ - github.com/timescale.
Joined July 2015
- Tweets 5,843
- Following 458
- Followers 9,088
- Likes 3,094
1,599 Photos and videos













Pinned Tweet

17 Jun 2025
🐯 Timescale is now TigerData! 🚀
Eight years ago, we started as a PostgreSQL-based time-series database. But innovation never stands still—and neither have we.
Today, we proudly unveil @TigerDatabase, marking our evolution into the fastest and most powerful PostgreSQL database, purpose-built for modern transactional, analytical, and AI-driven workloads.
🌟 Why TigerData?
We’ve grown far beyond our initial identity. From handling early renewable energy use-cases to powering Bloomberg’s critical geotemporal data, our customers showed us we're not just the best in time-series—we're the best in PostgreSQL, period.
🔑 Our Journey Highlights:
- 2017: TimescaleDB introduces groundbreaking hypertables.
- 2019: Native columnar compression; our cloud service launches.
- Recent innovations: 2500x faster distinct queries, 8x more efficient Boolean storage, and ultra-fast queries on high-cardinality data.
🚀 Customer Impact:
- Bloomberg leveraged us for massive geotemporal datasets.
- Renewable energy utilities replaced Redis to efficiently monitor operations.
🤝 Community Commitment:
Our core remains open-source, including the beloved TimescaleDB extension. This rebrand changes nothing about our dedication to our community and customers.
🌐 Looking Ahead:
Exciting innovations await:
- Deeper lakehouse integrations.
- AI-native features.
- Enhanced scalability and unmatched performance.
We are not just renaming; we're recommitting—to deliver on our mission of building the fastest Postgres, and to give our customers speed without sacrifice.
✨ Join the Tiger Era! 🐯
Your feedback is invaluable. Tell us your thoughts and what you'd love to see next.
Ready for the ride? Let's roar ahead together!
tsdb.co/tigerdata
5
11
38
6,589
On Postgres and hitting the analytics wall?
We're at booth 115 at #AWSSummit LA today.
Come see how TimescaleDB handles it without a second database.
tsdb.co/wlety9mo
#TimescaleDB
1
4
241
TimescaleDB (by Tiger Data) retweeted
PSA for #Postgres extension developers: Consider adding open-source pgspot to your release CI pipeline.
github.com/timescale/pgspot
We regularly evaluate extensions for Tiger Cloud, and pgspot consistently finds security issues, privilege escalations, and unsafe patterns before deployment.
We try to report what we find upstream through issues and PRs, but even better is catching these problems before a release ever ships.
5
28
1,404
⚡ TimescaleDB 2.27 is out.
The theme: compressed data should do less unnecessary work across the full SQL workload. Reads, writes, mutations. Thread 🧵
1
2
4
877
Operations compress_after_refresh: refresh and compression now run in a single policy. No more competing jobs, no lock contention.
Plus smarter segmentby selection and more resilient compression policies.
1
98
Close Full details in Brandon's write-up.
tsdb.co/8r1vpily
Tiger Data (creators of TimescaleDB) #PostgreSQL #databases
1
75
TimescaleDB (by Tiger Data) retweeted

At Hannover Messe 2026, Tiger Data co-founder and CTO Mike Freedman sat with @IIoT_World co-founder Lucian Fogoros to break down how @TimescaleDB runs 10x faster than SQL Server, Oracle, or MongoDB at a fraction of the footprint.
They also covered the formal partnership with Inductive Automation after seven years of organic Ignition Community adoption, and the launch of TimescaleDB Enterprise for facilities where data cannot leave the building.
Full interview on YouTube: youtu.be/p1sUI-qVfU4
2
1
269
TimescaleDB (by Tiger Data) retweeted
Why do Postgres servers fall victim to OOM-killers despite having seemingly sound configurations?
At Swiss PGDay on June 25, @TigerDatabase platform engineers @hintbits and Dimitris will share an intensive exploration of the failure path. They'll examine the complexities of Linux overcommit, cgroups, and Postgres memory architecture to understand why the kernel issues a SIGKILL. ⚡
The session will also highlight how eBPF was utilized for troubleshooting and how combining Patroni hooks with Postgres extensions can create a dependable memory ceiling.
This deep dive offers a debugging experience that provides profound insights into both Linux and #Postgres operations.
Link below.

1
6
40
3,496
TimescaleDB (by Tiger Data) retweeted
CERN generates hundreds of gigabytes of time-series data every day from 800 SCADA systems supporting some of the world's most complex physics experiments.
Their legacy archiving stack couldn't keep up. By rebuilding on TimescaleDB (Tiger Data), @CERN achieved 95% storage reduction and 40% faster historical analytics, while keeping dashboards responsive across decades of data.
Join CERN engineers Rafal Kulaga and Martin Zemko on June 25 at 9 AM ET as they share the architecture, design decisions, and lessons learned from building the NextGen Archiver. Free to attend. Register below.
tsdb.co/nk3odc51
#PostgreSQL #TimeSeriesData #IndustrialData #IoT #TimescaleDB
3
8
506
TimescaleDB (by Tiger Data) retweeted

Jun 3
Postgres is the database that keeps on giving.
Latest example: @Azure HorizonDB includes first-class support for pg_textsearch by @TigerDatabase.
Love how the Postgres community is coming together to build the last database anyone will ever need. Postgres for Search. Postgres for AI. Postgres for Everything.
techcommunity.microsoft.com/…
2
3
10
940
ApexAnalytica renders a year of hourly building telemetry from 38 sites as a single heat map. 6 seconds on vanilla Postgres. Under a second on TimescaleDB hypertables time_bucket MVs.
Read how Andrew McKenna built it solo: tsdb.co/lgcewpdo
#TimescaleDB #PostgreSQL
1
1
269
TimescaleDB (by Tiger Data) retweeted
Agents love files.
The problem is that files were never designed for agents. No transactions. No isolation. No safe undo.
TigerFS turns Postgres into a transactional filesystem.
With TigerFS 0.7, released today, we've added arbitrary rollback. Every filesystem operation is recorded in a history log, allowing you to undo changes from a named snapshot, revert a single file or operation, or selectively undo the work of a specific agent.
Git is great for collaboration. It's less great as an undo log for AI agents.
Don't trust agents to clean up after themselves. Give them an undo button.
tigerfs.io
4
10
67
4,022
We’re heading to #AWSSummitLA on June 10 - booth 115.
Running Postgres on AWS and hitting query slowdowns? Come see how Tiger Data keeps analytics fast on live data without requiring a second database.
Book time with the team:
tsdb.co/wlety9mo
2
2
3
225
TimescaleDB (by Tiger Data) retweeted

May 29
Revert all changes to the last savepoint.
Let your agents cook, then clean up when they make a mess of everything. 😀
May 29

TigerFS now has full undo logic, both to individual files or to named savepoints. Don't rely on your agent to manually reverse it's exploratory changes.
3
2
9
4,284
TimescaleDB (by Tiger Data) retweeted
May 31
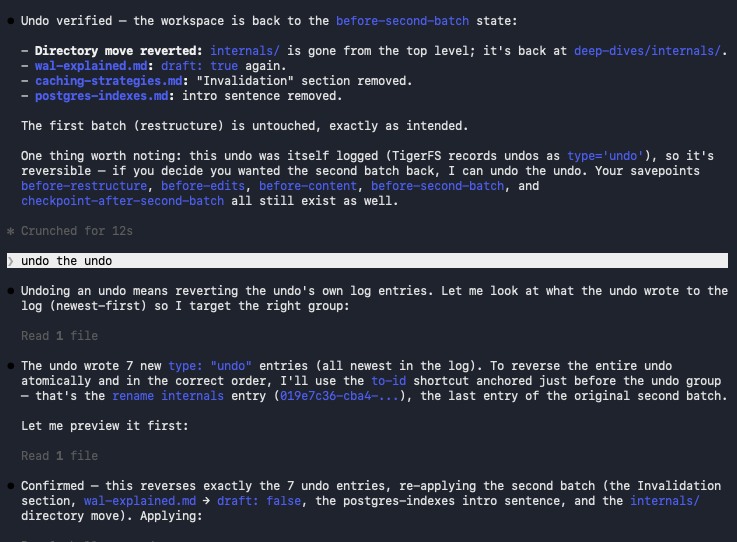
Now let's undo the undo with TigerFS to restore the changes...
Filesystem interface skills. Agents are so good at this.
May 29
Revert all changes to the last savepoint.
Let your agents cook, then clean up when they make a mess of everything. 😀
2
2
18
2,658
TimescaleDB (by Tiger Data) retweeted

May 29
Claude Code is now scary good at full-stack!
I asked it to build a real-time weather intelligence dashboard with an interactive 3D globe and a forecasting layer that predicts weather 3 days ahead.
It came back with a spinning globe that has a day/night cycle using NASA satellite imagery, city lights on the dark side, weather icons that switch between sun and moon based on local time, and a time travel slider that scrubs through 10 days of data.
Claude Code built the whole thing in a single session, including the backend, database, data pipeline, and frontend.
For the database, I needed something fast for time-series workloads since the app ingests hourly weather readings across many cities and serves time-range queries on every slider interaction.
I used Tiger Cloud by @TigerDatabase, which gives you managed TimescaleDB on the Postgres you already know.
Claude Code connected to it through the Tiger CLI MCP server and set up the entire backend directly:
- Provisioned the database service
- Created hypertables for time-partitioned weather storage
- Set up continuous aggregates for pre-computed rollups
- Built the data ingestion pipeline and the full NextJS ThreeJS frontend
The time travel slider queries thousands of rows on every position change.
On a regular Postgres table, this would require manual partitioning and index tuning to stay fast as data grows.
TimescaleDB partitions the data by timestamp automatically, so each query only hits the relevant time chunk.
Continuous aggregates serve the trend charts and forecast layer from pre-computed rollups instead of rescanning raw data on every request.
The video below shows the final build in action, and I worked with the Tiger Data team to put this together.
Tiger CLI is open-source (Apache 2.0) and works with Claude Code, Cursor, Codex, Gemini CLI, and VS Code.
To try this yourself:
→ Sign up for Tiger Cloud (I have shared the link in the replies). It gives you $1,000 free credits (no card needed)
→ Install Tiger CLI: curl -fsSL https(:)//cli(.)tigerdata(.)com | sh
→ Run tiger mcp install claude-code
→ Give Claude Code a prompt and let it build
Find the sign-up link in the replies.
11
6
61
14,613
TimescaleDB (by Tiger Data) retweeted

Discover how a reliable MQTT pipeline helped an explosives manufacturer save their production numbers, turning failing sensor data into real-time machine learning insights: hackernoon.com/hivemq-and-ti…
2
28
211
2,440,928