
167 Photos and videos








Pinned Tweet

14 Oct 2025
Thank you to Annual Reviews of Astronomy and Astrophysics for entrusting me.
Here's my author version of "Deep Learning in Astrophysics."
arxiv.org/abs/2510.10713
Aside from my textbook, this is probably one of my biggest undertakings in recent years. The strict word and reference limits were particularly challenging given how broad the topic is.
I spent the entire summer working on this piece. While writing it, I couldn't help but feel that it represents a decade of learning (and ongoing learning) along with much personal reflection.
I hope the community finds it useful.
Comments welcome.
2
44
236
12,228
I searched for health food on my Google Map, and Shake Shack showed up.....
I might go to have some health food today.
7
448
31 Dec 2025
I'll admit, in my earlier years I wasn't sure what to make of committee work—it can feel like a massive time sink. But I've grown to genuinely enjoy reading proposals and letters. Even writing them myself, to some extent.
It often feels like we're all shouting into the void—applicants and reference writers alike. But good work matters. A deep understanding of the field matters. And taking the time to articulate what you see in someone matters.
There are always these little sparks—of intelligence, of humanness—that come through in the letters and proposals. Those moments are genuinely beautiful.
The outcomes can be cruel, given how competitive things are. But I do think most people who take this work seriously see the beautiful work you're producing. It doesn't go unnoticed.
4
525
30 Dec 2025
Took advantage of the downtime to wrap up a paper—so, a bit of an untimely paper drop!
arxiv.org/abs/2512.23138
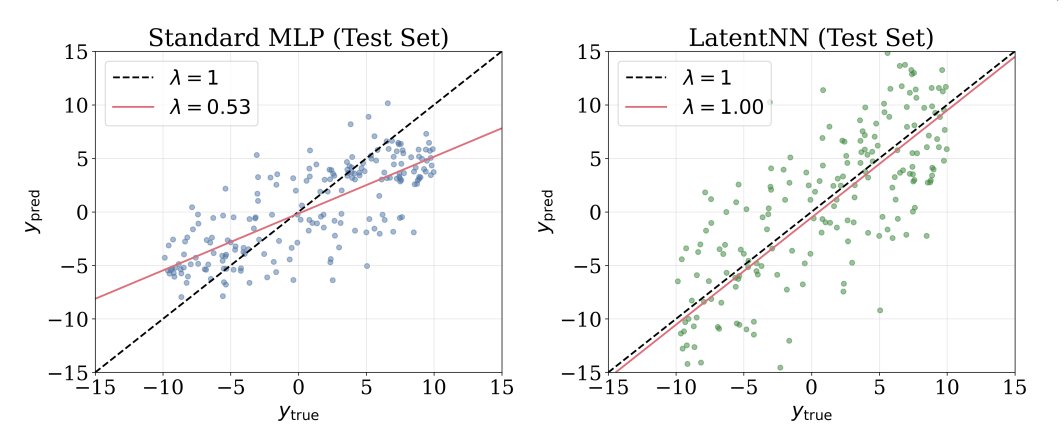
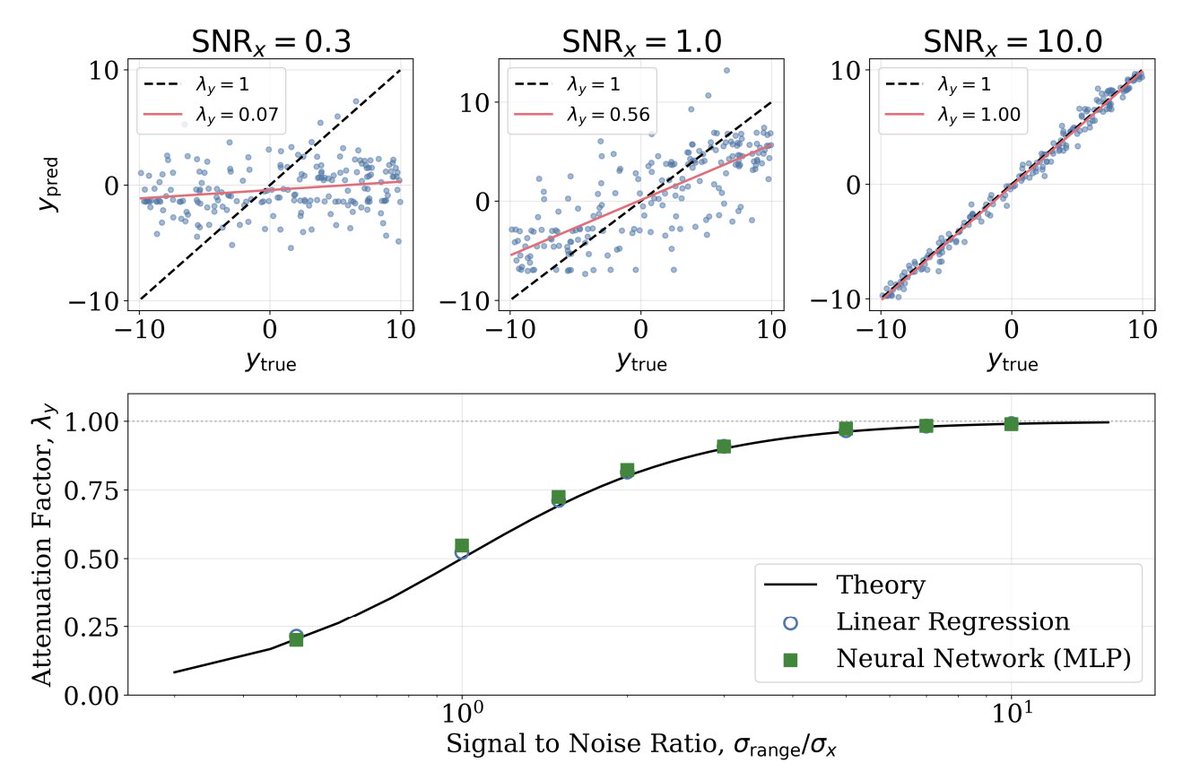
Deep learning has been increasingly applied to astronomy, yet unlike much of the real-world data neural networks were developed for, astronomy typically operates at much lower signal-to-noise ratios (SNR ~ 1–10 is common).
This brings back an old problem from linear regression known as attenuation bias—commonly seen when your regressed labels are systematically pulled toward the mean.
This bias persists in neural networks too, and contrary to common belief, it can't be solved simply by adding more data or using more precise training labels. There's also a misconception that it stems from training set imbalance.
In Paper I (arxiv.org/abs/2412.05806), we showed that this bias arises entirely from input uncertainty. When your SNR is ~10 or lower, it naturally occurs. This phenomenon isn't discussed much in AI circles simply because such low signal-to-noise regimes aren't typical in their applications.
Borrowing ideas from how attenuation bias has been addressed in linear regression (under various names: Deming regression, orthogonal regression, errors-in-variables models)—modeling both the true input values as latent variables and the model itself—we show how these ideas can be principally applied to neural networks to correct for this bias.
It's a simple idea, but I think it's worth writing up because applying deep learning to astronomy needs to be grounded in a solid understanding of statistics.
1
18
749
23 Dec 2025
New paper alert! This is one I'm really excited about.
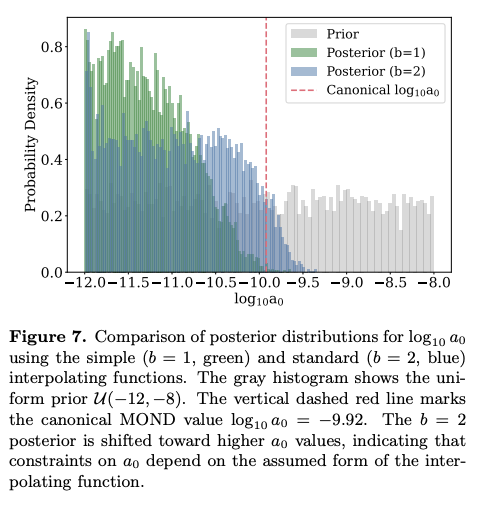
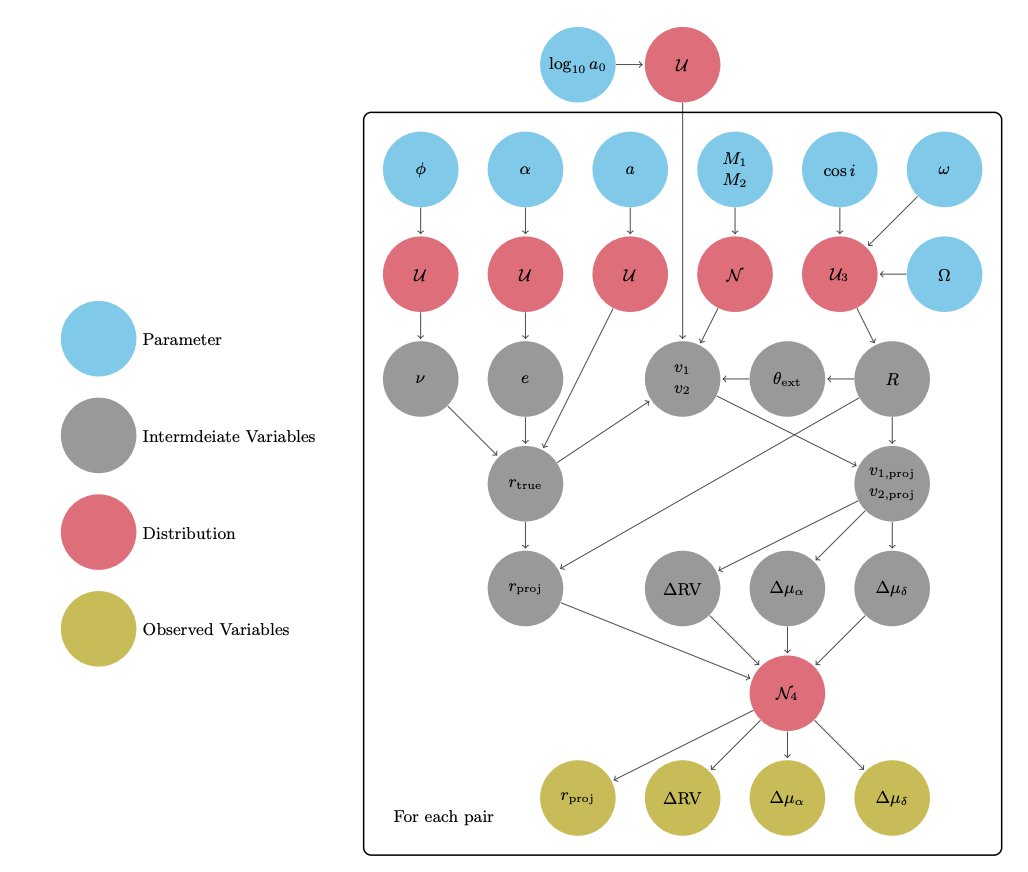
Serat Mahmud Saad took the stellar twin wide binary samples we collected as part of the C3PO program and used them to put strong constraints on Modified Newtonian Dynamics (MOND).
A few key highlights:
(1) We show that even without exoplanet-grade precision radial velocity spectrographs, a line-by-line "differential" analysis of the two stars can achieve ~10 m/s precision. Differential techniques like this are commonly used to measure abundances—we've extended the idea to radial velocities.
(2) We built a full hierarchical Bayesian model to constrain MOND in a statistically rigorous way, using the joint likelihood of all these samples while marginalizing over nuisance parameters.
(3) Despite having only ~100 stars, the precision of this sample gives it more statistical power than the Gaia wide binaries sample. Depending on the MOND interpolation function, the canonical MOND value is ruled out at 1.9–3.1 sigma.
Oh, and Serat is in his first semester of grad school.
arxiv.org/abs/2512.19652

16
627
15 Dec 2025
Very well said. For people who are wavering between industry and doing a PhD/postdoc, this is a good read.
14 Dec 2025

I did industry research and then chose to return for a CS PhD at CMU. A few thoughts on why I chose to do a PhD.
In industry research, it’s hard to work on the same problem for long. Timelines change and product incentives shift. As a result, it’s difficult to really develop deep insights into one particular area of research.
During a PhD, you can plan out multiple years of research without worrying about external factors. You want to work on diffusion for five years? Simply go do it. This is perhaps the number one reason to do a PhD.
Second, industry typically gives you little control over collaborators. It’s difficult to know who you’re going to work with and, once you’re there, you can’t really pick and choose either. At some point, everyone has worked with someone they absolutely do not want to work with.
In a PhD, the talent density is incredibly high. I’ve had the opposite problem where I simply want to work with too many people. But, if you do encounter someone you don’t want to work with… simply don’t work with them.
Lastly, let’s say you do work for a top-lab where you’re surrounded by brilliant people and everyone has the same long term vision. Guess what… almost everybody around you has a PhD. Not only does this mean you have to prove you are at a PhD level, but mentally it’s annoying knowing that everyone else has a PhD and you don’t. I firmly believe that you can succeed without a PhD, but it’s definitely an uphill battle.
Of course, there are many downsides to doing a PhD, most notably money and compute (aka money). Nowadays, a pattern I’ve seen work very well is 2-3 years in industry before the PhD, just to provide yourself some money and comparison. Everyone I know who has done this has been very successful.
At the end of the day, the PhD is about buying time and freedom of choice. Whether that’s worth it is up to you.
5
731
3 Dec 2025
Paper day!
Equivalent widths are the gold standard for studying stars—they can cancel out certain systematics in stellar spectra. But measuring them has long required painstaking human effort to adjust for optimization errors. This bottleneck has prevented us from scaling these careful, boutique-style analyses to the vast numbers of spectra now available.
Here, with our amazing 1st-year PhD student at OSU Serat Mahmud Saad, we present Egent: an agent for equivalent width measurements. We show how modern AI agents can overcome this challenge, opening a path to perform detailed spectroscopic studies at astronomical survey scales.
Paper: arxiv.org/abs/2512.01270
Github: github.com/tingyuansen/Egent… interface: ew-agent.streamlit.app
1
22
1,170
25 Nov 2025
It's paper day! But this time, I'll let Doraemon do the explaining.
arxiv.org/abs/2511.18901


2
2
19
770
22 Nov 2025
During the colloquium dinner, my colleague David Weinberg reminded us that one of the earlier indirect claims for dark matter came from Jeremy Ostriker and Jim Peebles (1973)—the simple argument that without dark matter, disks would naturally buckle, which does not match observations. So I attempted to reproduce this result with Gemini 3 for fun.
Here is the live website
tingyuansen.github.io/Ostrik…
11
62
363
41,869
19 Nov 2025
📢 Paper Day: We extract 10,000 semantic concepts from 400K astrophysics papers to enable AI-powered research discovery. Unlike sparse keywords, our concepts provide dense coverage & capture ideas buried in methods sections—critical for autonomous agents.
📄 Paper: arxiv.org/abs/2511.12353
💾 Data: github.com/tingyuansen/astro…
Shown here is the evolution of concept co-occurrence patterns in astrophysics papers (1992-2025)
4
16
2,072
7 Oct 2025
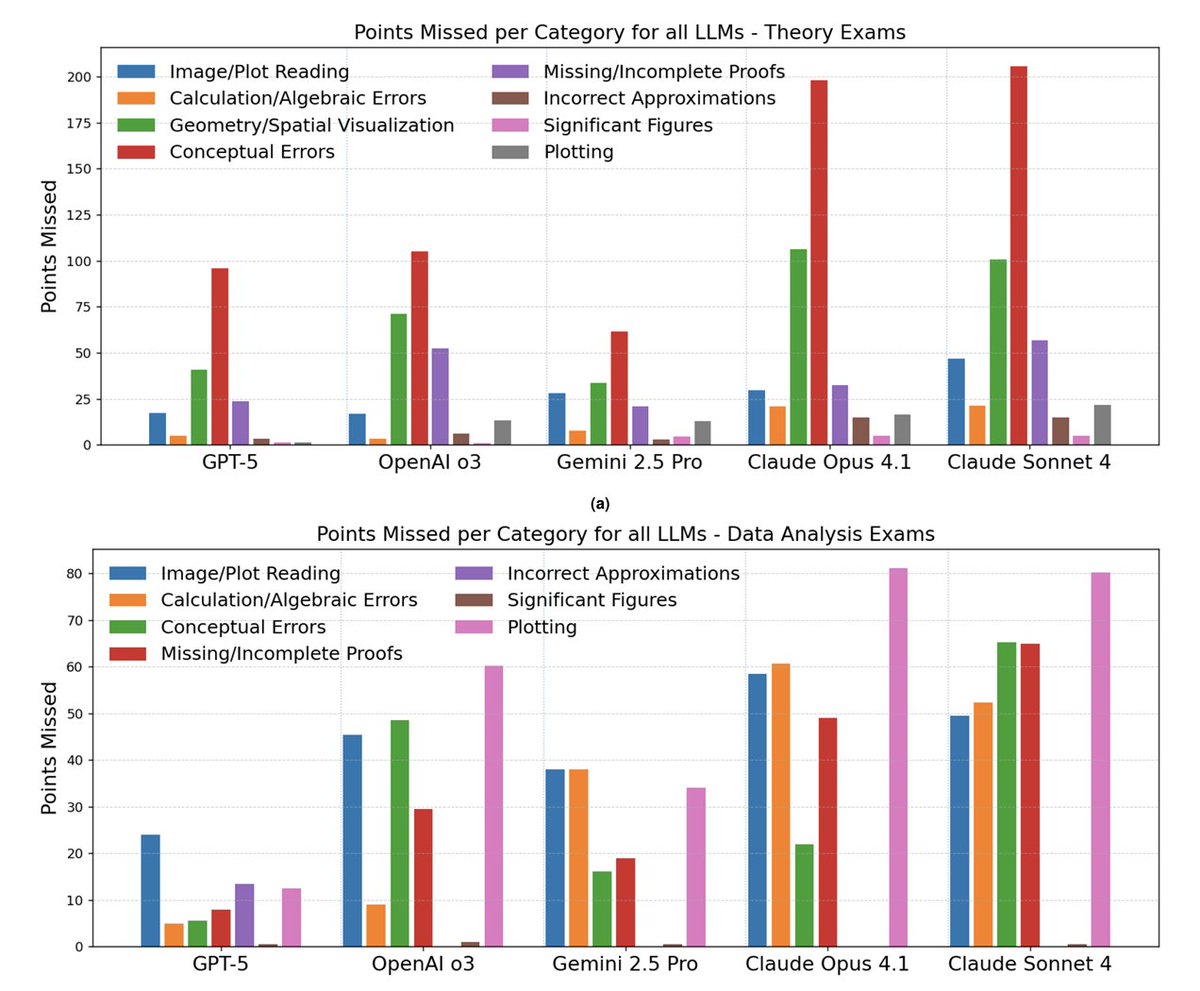
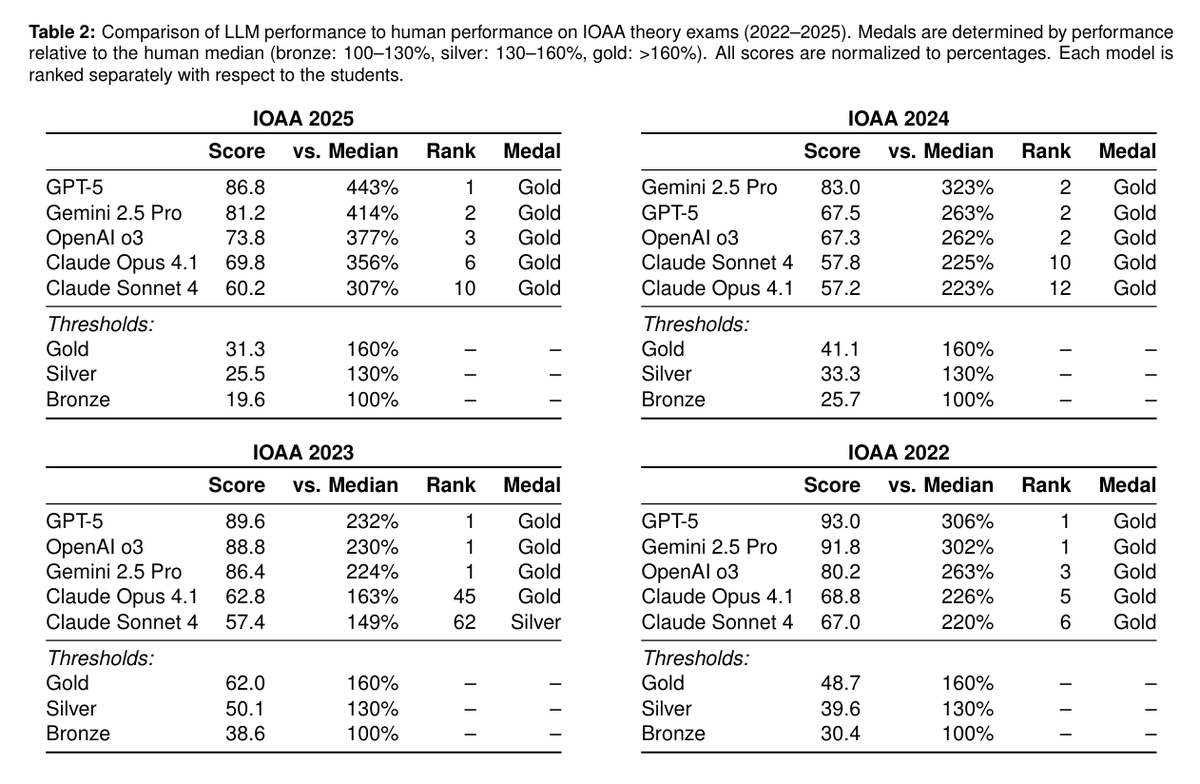
We tested 5 state-of-the-art LLMs (GPT-5, Gemini-2.5-Pro, OpenAI o3, Claude Opus 4.1, Claude Sonnet 4) on the International Olympiad on Astronomy and Astrophysics (IOAA).
arxiv.org/pdf/2510.05016
Theory problems: GPT-5 and Gemini-2.5-Pro ranked top 2 among 200-300 students across 4 years (2022-2025), achieving gold medals. Other models also reached gold level but with lower rankings 🥇
Data analysis problems: GPT-5 ranked top 10, but other models struggled to varying degrees, revealing gaps in multimodal reasoning 📷
AI can excel at physics reasoning but still struggles with spatial visualization and interpreting astronomical data.
Great collaboration with the NLP science agent group at OSU @hhsun1 @ShroffNess Yingbin Liang. Led by Lucas Carrit Delgado Pinheiro and @RonZiruChen. Also Bruno Caxeita Piazza.
2
4
19
1,463
22 Sep 2025
I'm teaching an introductory coding course for first-year non-computer-science students, and I've been working on modernizing the Python 101 curriculum, including integrating LLMs into their workflow. I'm sharing some of the material here in case they're helpful to anyone—and I'm only about a third through the semester, so there's more to come.
tingyuansen.github.io/coding…
1
17
891
4 Sep 2025
Following an idea conceived last summer, we held an NSF-supported meeting at MIT this March to discuss the future of AI and the Mathematical and Physical Sciences (MPS). We brought together leaders from each subfield—astronomical sciences, chemistry, materials research, mathematical sciences, and physics—to explore a wide range of opportunities and challenges, covering everything from funding streams and infrastructure to science, education, ethics, and beyond.
After nearly a year of organizing and work, the white paper is now available: arxiv.org/abs/2509.02661
No matter where you are in your career—whether you're a K-12 student, graduate student, postdoc, faculty member, staff, department chair, director, or funding program manager—this document offers a comprehensive overview of the landscape and highlights key opportunities and gaps the community has identified.
Organizer:
@marisa_kathryn, Jesse Thaler (Physics), Lars Ruthotto
@lruthotto (Maths and Statistcs), Soledad Villar, @SoledadVillar5 (Maths and Statistics), Pratyush Tiwary (Chemistry), Andrew Fergurson (Chemistry), and myself (Astronomical Science)
1
4
23
1,055
20 Aug 2025
I met two extraordinary PhD students at OSU today.
When I tried to retrieve my car from storage, it was completely dead. The first car I waved down actually stopped—two students who wanted to help but didn't have jumper cables. After they left, I tried waving down more cars, but most just drove past.
Then those same two students came back. They'd bought cables and returned just to check if I was still there—even though I could have been long gone. They helped me figure out how to reverse the car (through YouTube videos) and jumped the car. Only then did I learn they were biology PhD students.
After working with many students and postdocs, I know the most important quality in a good scientist is character—shown through actions, not words. A quick Google search revealed they're also doing excellent research.
These young people are what make the school great.
1
2
28
1,909
20 Aug 2025
Also, I've learned that all those zombie apocalypse series are completely bogus. How do the main characters always walk up to some random abandoned car and manage to start it right up after it's been sitting there for months?
1
6
496
16 Aug 2025
And my PhD student @yanjun_sheng undertook a huge effort, running 3000 LMC-Milky Way N-body simulations to study in detail how we can use the LMC wake to constrain the Milky Way's mass profile and total mass. The simulations are publicly available!
arxiv.org/pdf/2507.03663

3
29
988
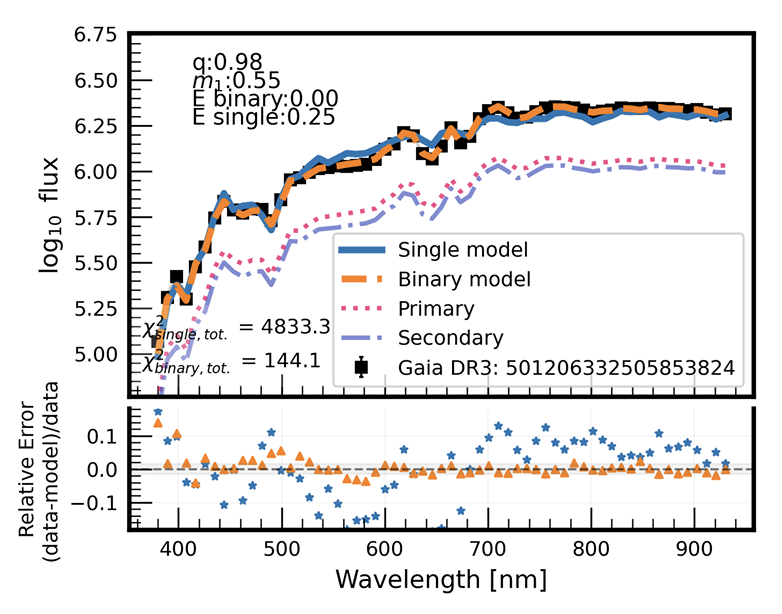
16 Aug 2025
And finally, heroic effort by @jordonglee who showed tAnd finally, a heroic effort by Jordan Glee, who showed that even at Gaia XP spectral resolution, spectral mixture models can still extract clean samples of ~1M binary stars. arxiv.org/abs/2507.09622
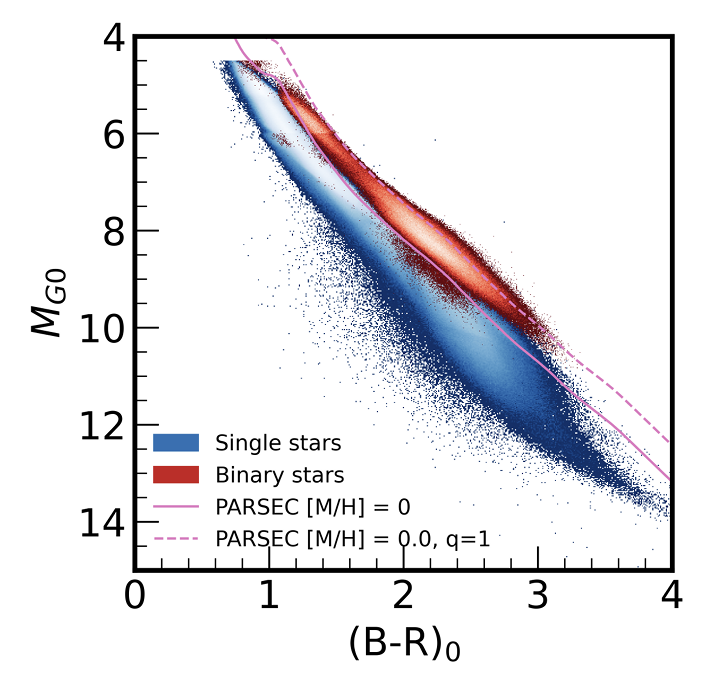
9
477
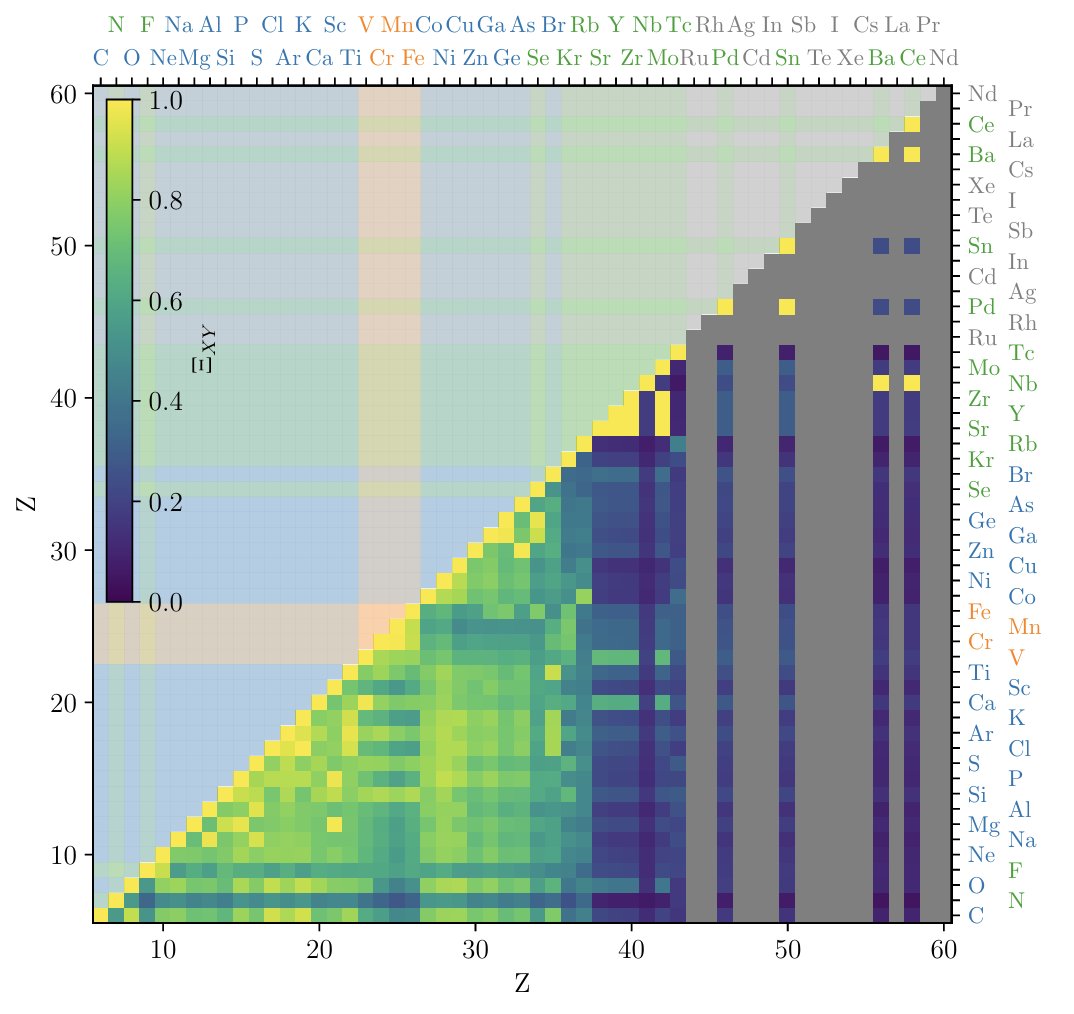
16 Aug 2025
I'm thrilled about this theoretical advancement. Mark Krumholz extended our 2018 paper and showed how to analytically(!) calculate elemental abundance correlations arising from ISM diffusion—and the simple theory matches the Ting & Weinberg (2022) abundance correlation measurements very well!
arxiv.org/abs/2507.14572
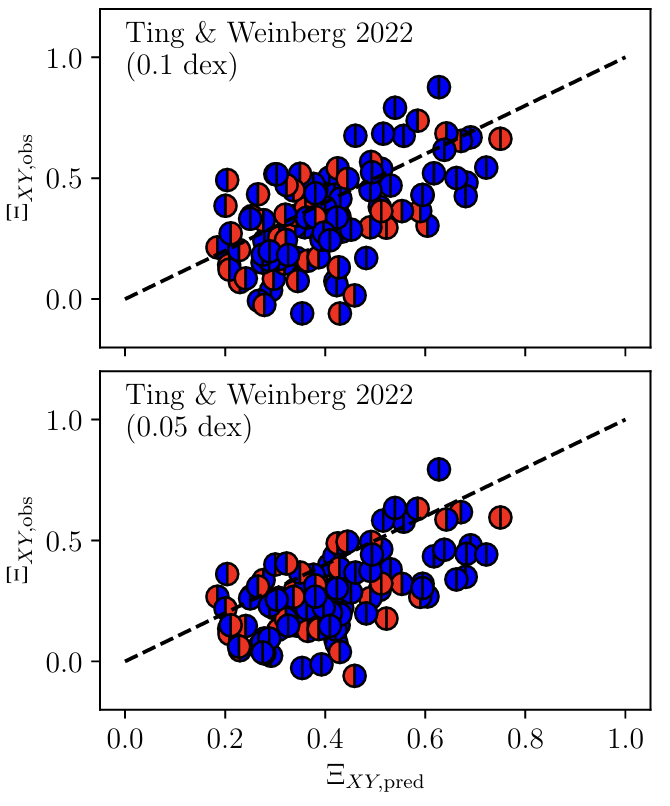
1
17
967