
CS Ph.D. at @SCSatCMU. Funded by @NDSEG Fellowship. Intern @arena. Editor at blog.ml.cmu.edu.
Joined July 2013
- Tweets 485
- Following 231
- Followers 945
- Likes 1,100
39 Photos and videos



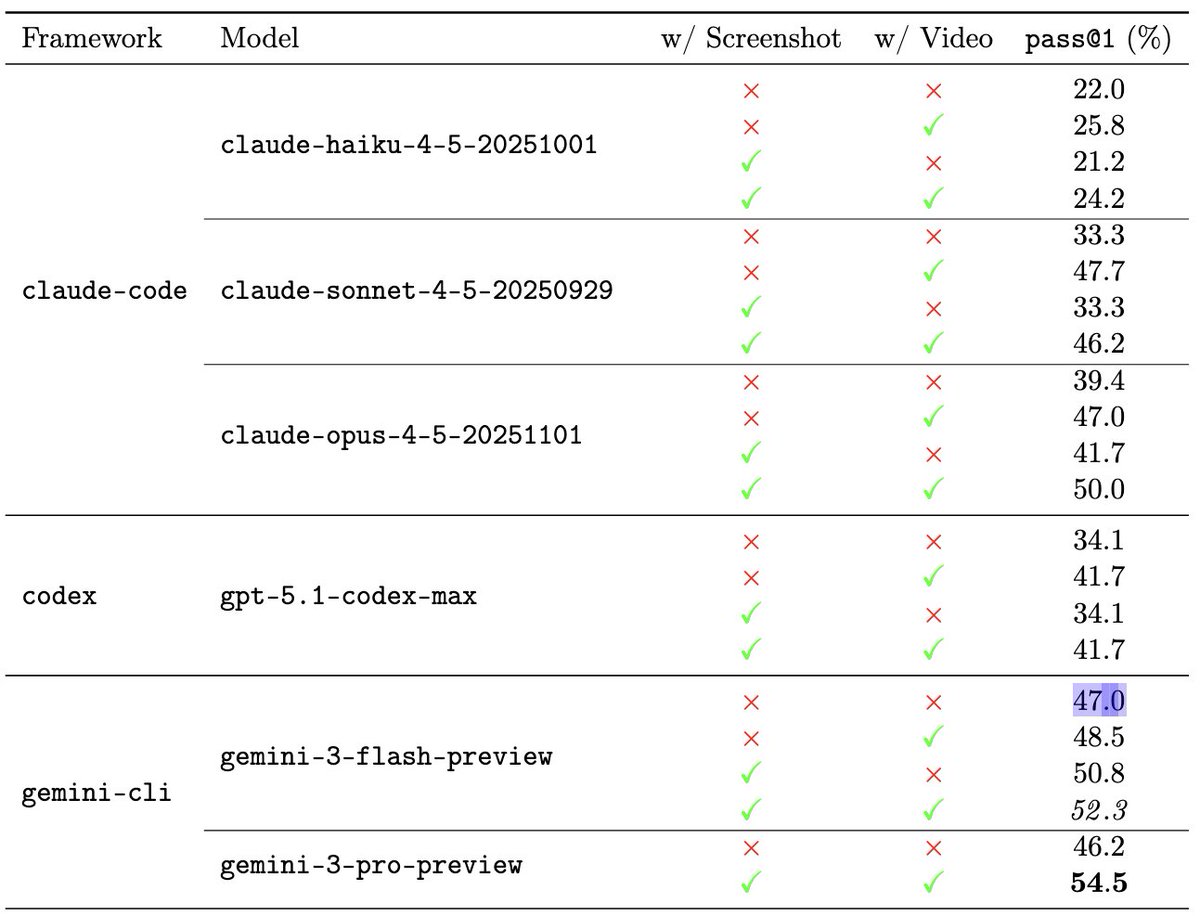



Pinned Tweet

Feb 13
New preprint alert 🚨
Can LLM agents develop video games?
We release GameDevBench, the first benchmark evaluating agentic game development in a game engine, Godot.
We also present two simple multimodal feedback mechanisms that lead to immediate performance gains.
/🧵
19
27
257
26,273
Jun 12
I miss when frontier labs tackled fun benchmarks.
Fable 5’s system card has 50 benchmarks, yet almost all of them feel... sterile. Where are the creative writing evals? Don’t we want to know if models can actually make something delightful?
Creative industries are huge, profitable, and technically demanding, perfect for frontier evals. Game dev, for example, tests long-context reasoning, multimodal understanding, tool-use, and taste.
Obviously, I’d love to see GameDevBench in the mix. But really, even one fun or creative benchmark would be refreshing.
The world could use a little more whimsy. 🪅
2
24
1,457
Jun 11
This is 🥜 btw

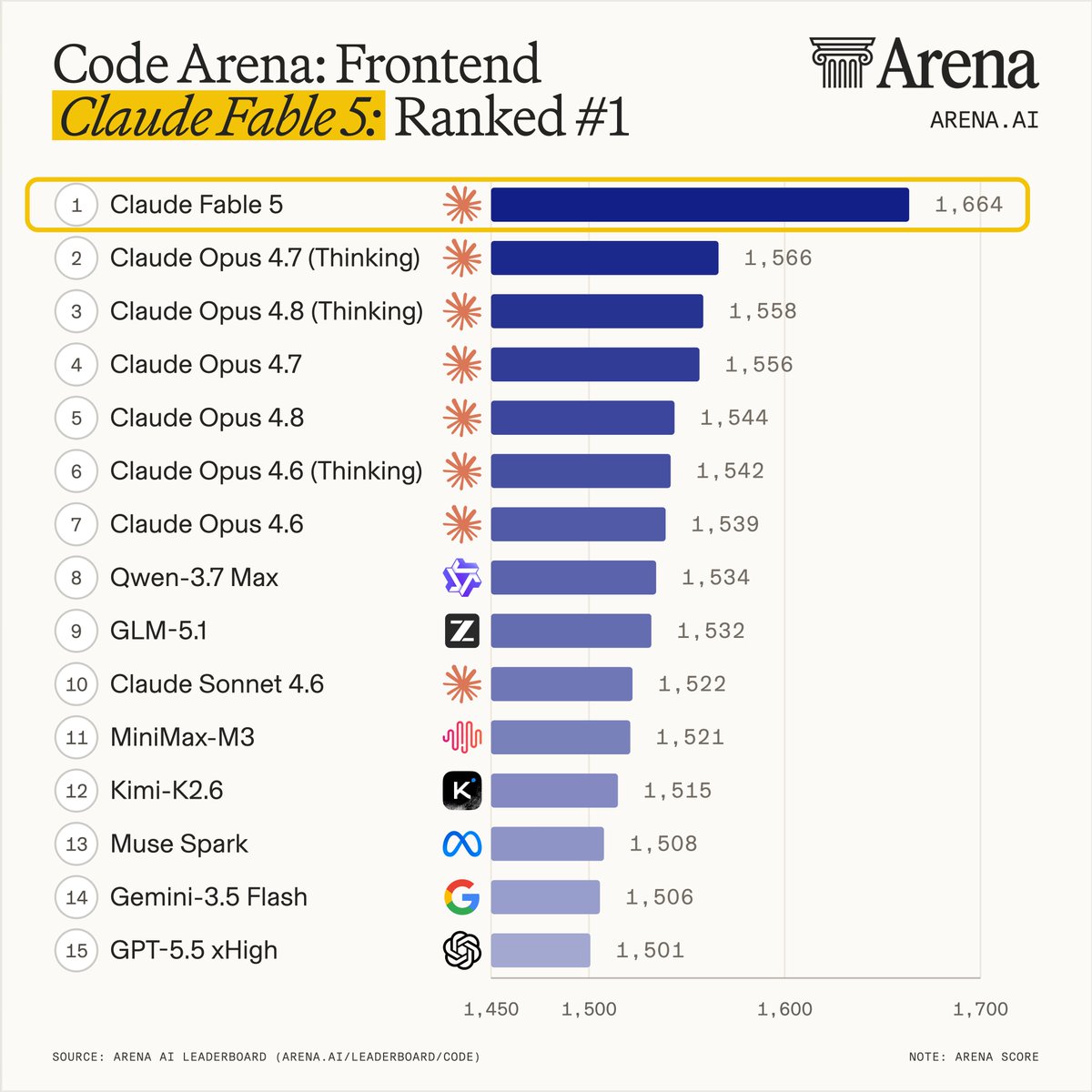
Claude Fable 5 ranks #1 in Code Arena: Frontend, leading by a wide margin over Opus-4.8.
Highlights:
- #1 in every sub leaderboard: HTML, React
- #1 in every sub category: Brand & Marketing, Reference-Based Design, Data & Analytics, Consumer Product, Gaming, Simulations, and Content Creation Tools.
Huge congrats to @AnthropicAI for this milestone! The thread breaks down how Claude Fable 5 ranks across single-modality arenas.
1
1
423
Jun 5
Things you can do this summer while Claude Code works for you!

Things you should do this summer in San Francisco NorCal instead of sitting inside with Claude Code:
🌁 Grab fresh oysters from Tomales Bay
🌁 Pick strawberries, cherries, & blackberries in Brentwood
🌁 Walk the SF Crosstown trail
🌁 Picnic in Dolores, GGP, Lafayette, Crissy Fields, or Alamo Square parks
🌁 Go on a wine tour in Sonoma & Napa
🌁 Take the ferry from SF to Sausalito
🌁 Drive down to Santa Cruz and grab burritos on the beach
🌁 Visit the Ferry Building or Fort Mason farmers markets
🌁 Take a trip to Muir Woods
🌁 Drive down Highway 1 for insane views
🌁 Explore or camp in Carmel
🌁 Hike Mission Peak in Fremont
🌁 Visit Yosemite/Halfdome
🌁 Golf in Half Moon Bay
🌁 Polar Plunge at Aquatic Park or Ocean Beach
🌁 Dine at the Taco Bell Cantina in Pacifica
1
239
Jun 4
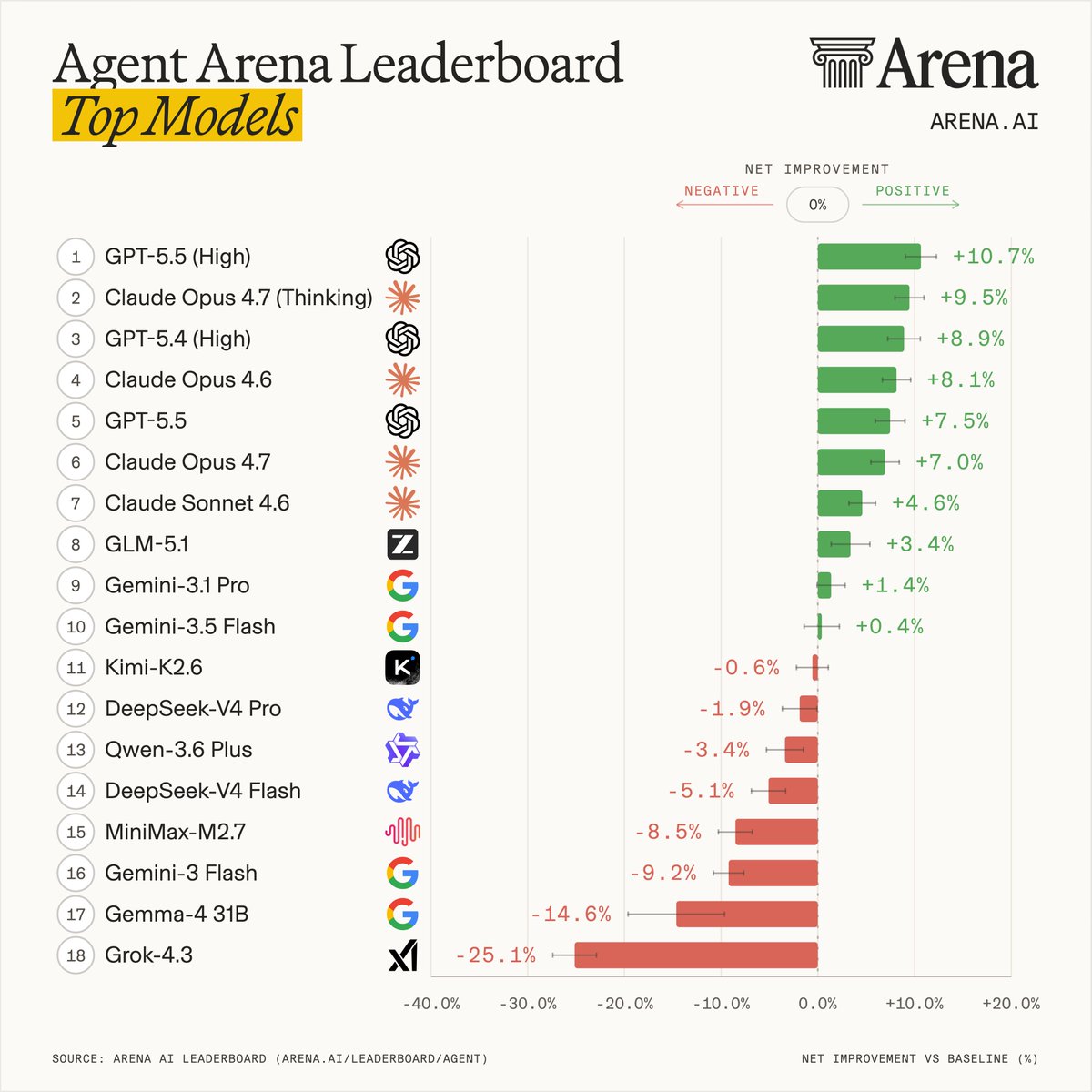
Agents are taking over!
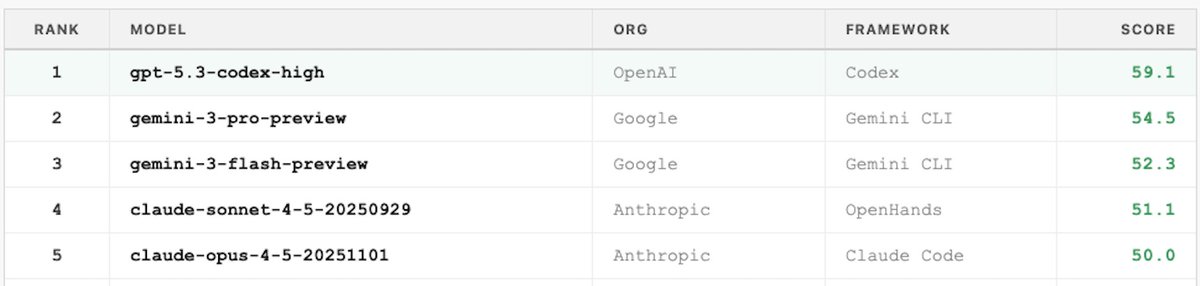
Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K tasks, 2M tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
1
14
1,441
Jun 4
I've joined @arena for the summer where I'll be working on ... something new and secret 😁
Super excited to work with @ml_angelopoulos, @infwinston, and @istoica05 again!
6
2
49
4,434
May 29
Alright I guess it's time to test Opus 4.8 on GameDevBench

1
3
1,094
May 25
From my experience doing both, this is the most accurate differentiator.
Most of the differences in methods and skills stem from this.
May 24

IMO a researcher studies a problem that may not be solvable, while an engineer solves a problem that is considered solvable.
5
840
Wayne Chi retweeted

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
139
921
6,555
1,088,708
May 11
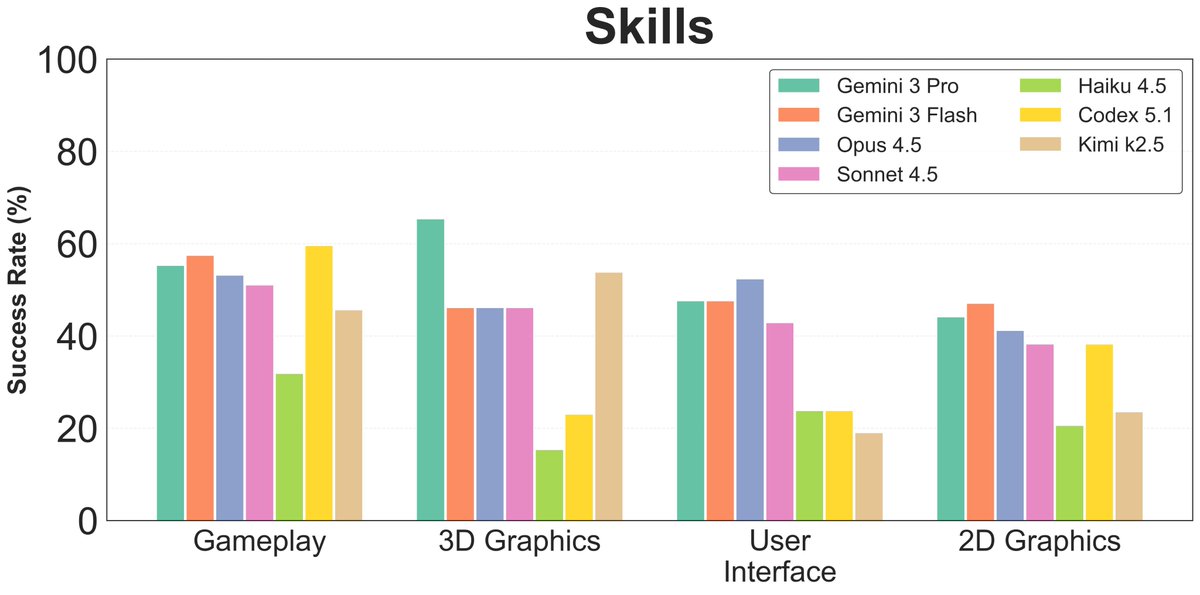
We observed this a month or two ago on GameDevBench!
Ever since GPT 5.4, @OpenAI took over as the best agent for game development. However @AnthropicAI was never in the lead; the best was actually @Google with Gemini (good at multimodal understanding).
Good to see further confirmation on what's SOTA for game development.

Fun fact, GPT 5.5 is very good at Game Dev
Game Dev is the notable category where @OpenAI consistently beats out @AnthropicAI's Claude models
Upon code inspection, our @Designarena team found that GPT 5.5's frontend verbosity plays in its favor for game dev - it consistently created games with the most functional features
Congrats to @OpenAI for establishing the new Game Dev frontier!

3
1
12
2,464
May 10
A big downside with the the new focus on ArXiv is you have to read (and eventually cite) some absolutely awful papers that would clearly never pass peer review...
6
699
May 10
I love how southern Jensen sounds when he says America.
'Murica!🇺🇸🇺🇸🇺🇸🦅🦅🦅
1
170
May 1
GameDevBench has been accepted into ICML 2026! See everyone in Seoul soon!
Feb 13

New preprint alert 🚨
Can LLM agents develop video games?
We release GameDevBench, the first benchmark evaluating agentic game development in a game engine, Godot.
We also present two simple multimodal feedback mechanisms that lead to immediate performance gains.
/🧵
4
28
1,472
May 1
Exciting work and really cool to see Moonlake reference GameDevBench as a precursor to their work!
The future of agentic game development is bright ☀️

Introducing Moonlake's 3D Agent.
Our agent acts like a technical artist that can build and reconstruct articulated assets and large-scale editable scenes with hundreds of objects from a single image and can improve its generations continuously.
Learn more in the thread below.
16
1,032
Apr 24
The presenters in front of me took 15 minutes instead of 10 minutes each. And then the conference organizer CUT MY QUESTIONS???
wtf @iclr_conf
1
2
30
6,174
Apr 22
I will be presenting EDIT-Bench as an Oral at ICLR on Friday 4/23! Session 4D starts at 3:15 and the talk is at 3:39.
We will also be at poster session 3 in the morning.
See you all there!
19 Nov 2025
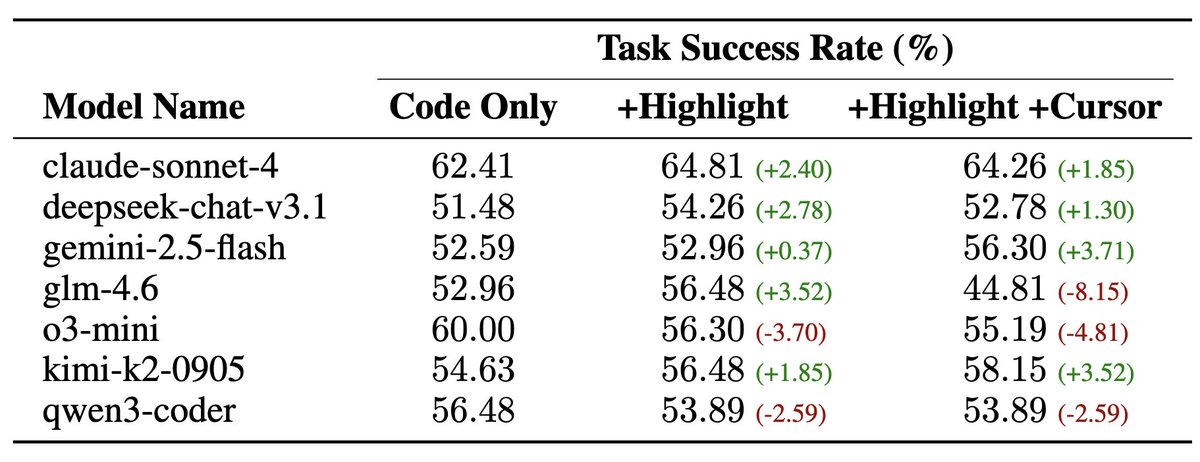
Tired of evaluating LLMs on made-up problems that look nothing like real tasks?
Introducing EDIT-Bench, a code editing benchmark built from in-the-wild user interactions in VSCode.
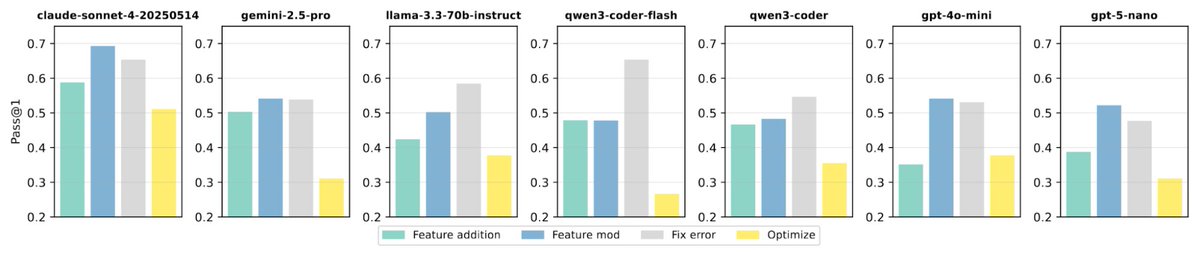
Real-world edits are challenging: 𝗼𝗻𝗹𝘆 𝟭/𝟰𝟬 𝗺𝗼𝗱𝗲𝗹𝘀 𝘀𝗰𝗼𝗿𝗲 > 𝟲𝟬% 𝗽𝗮𝘀𝘀@𝟭.

8
31
4,443
Mar 19
I think I might be addicted to making benchmarks... evaluating LLMs is, for some strange reason, incredibly fun...
Anyways new benchmark coming soon!
1
12
437

Mar 9
No more benchmarks. Only tier lists going forward
Mar 8

Benchmarks? Where we’re going, we don’t need benchmarks.
1
11
1,329
Mar 9
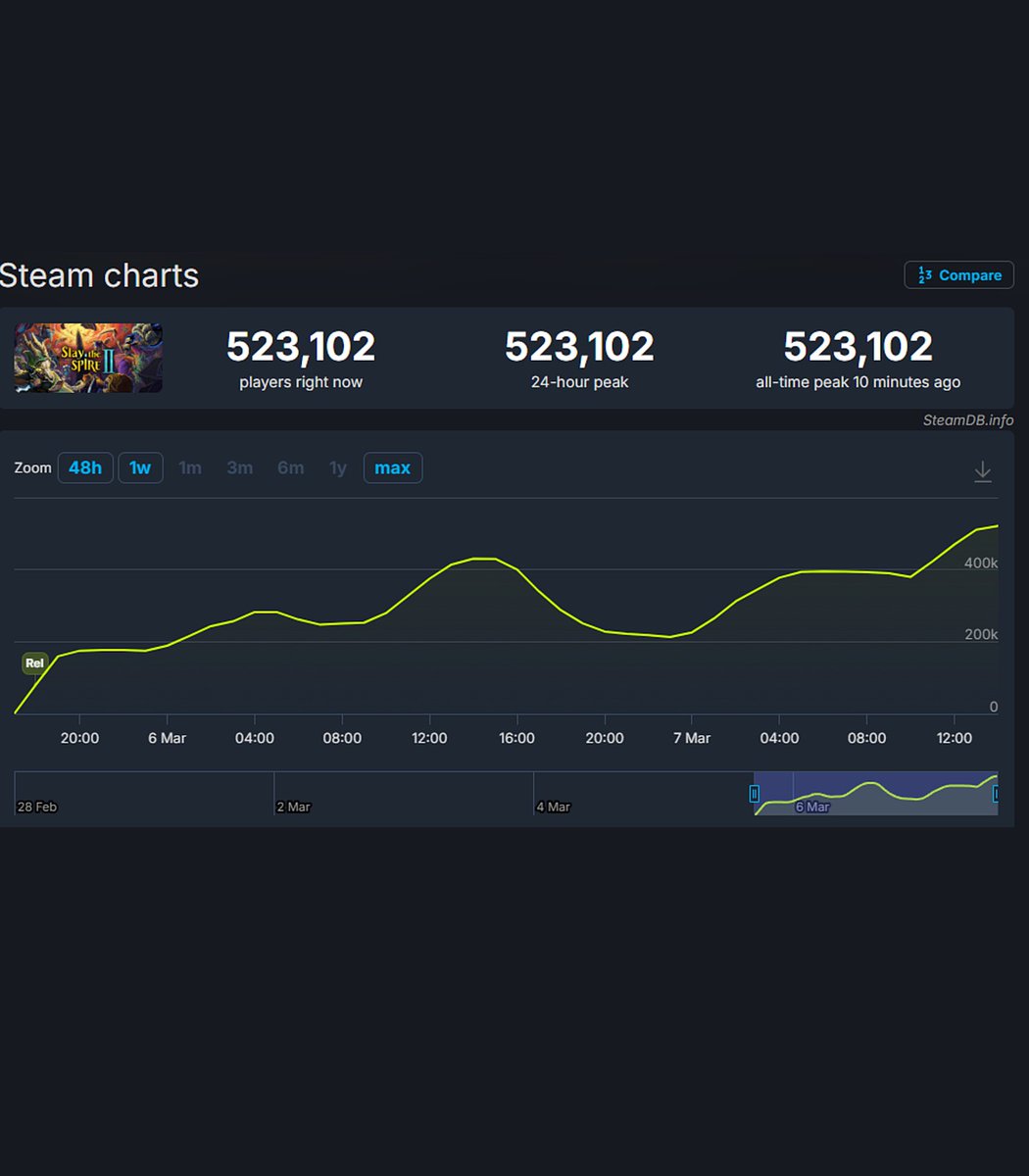
Slay the Spire 2 is having one of the most successful launches in indie gaming history... And it's made entirely in Godot
I think Godot will have a meteoric rise in the coming years and it's a big reason why I focused GameDevBench (arxiv.org/abs/2602.11103) on Godot

Indie game Slay the Spire 2 has surpassed 500,000 concurrent players on Steam
The rougelike is now in the top 20 games with highest all-time peaks on Valve's platform

1
1
8
591