
Accelerate inference, model shaping, and pre-training on a research-optimized platform.
Joined November 2022
- Tweets 2,774
- Following 374
- Followers 56,209
- Likes 2,152
823 Photos and videos
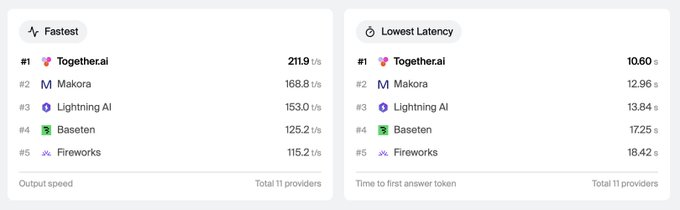













DeepSeek V4 Pro on Together AI is now #1 on Artificial Analysis for both output speed and latency.
Serving V4 well is an inference systems problem: KV cache, prefix reuse, kernels, and endpoint profiles.
We break down the systems work here:

4
1
19
2,245
Together AI retweeted
DeepSeek V4 Pro on @togethercompute becomes #1 on both latency and speed.

10
7
67
6,992
Kimi-K2.7-Code from @Kimi_Moonshot is now available on Together AI.
Built on Kimi K2.6, it’s a coding-focused agentic model for long-horizon software engineering workflows, now running on Together’s research-powered inference stack for tool-heavy coding agents.
6
6
45
4,124
Highlights:
👉 Stronger real-world coding performance over Kimi K2.6
👉 ~30% lower thinking-token usage for better token efficiency
👉 256K context for larger repos and longer coding sessions
👉 Interleaved thinking and multi-step tool calling for coding agents
2
3
1,225
Try it now: together.ai/models/kimi-k27-…
1
1,026

Jun 13
MiniMax-M3 from @MiniMax_AI is now available on Together AI.
It’s an open-weight native multimodal model with 1M context, MiniMax Sparse Attention, and thinking / non-thinking modes.
Together AI is MiniMax’s preferred cloud partner, with inference optimizations delivering up to 125% higher throughput across concurrency levels.
2
3
26
12,369
Jun 13
Highlights:
👉 Native multimodality across text, image, and video
👉 1M context with MiniMax Sparse Attention for long-context workloads
👉 9x prefill and 15x decode speedups vs M2 at 1M context
👉 Thinking mode for complex reasoning, non-thinking mode for latency-sensitive chat and code completion
2
5
2,644
Jun 12
The case for Blackwell in production agent infrastructure just got cleaner.
@ArtificialAnlys AgentPerf gives the hardware picture.
Together's coding agent benchmarks give the inference picture: 31% more TPS than the next-fastest OSS engine on the same hardware, through custom kernels built for Blackwell's Tensor Core instructions.
Cursor runs their real-time coding agents on this stack. Learn more about how we built it in the 🧵

The first agentic AI infrastructure benchmark is here.
An AI agent chains dozens to hundreds of AI model calls together, using tools, gathering context, and iterating until the task is done. Existing benchmarks weren't designed for that.
AgentPerf from @ArtificialAnlys gives developers, enterprises and infrastructure providers a clear way to compare accelerated computing systems for agentic AI.
First round of results highlight that NVIDIA Blackwell delivers 20x more agents per megawatt than NVIDIA Hopper.

3
1
15
3,646
Jun 12
When deploying voice agents, users notice latency above 500ms. Above one second, they hang up. @rish_bhargava walks through the full pipeline at that level of specificity, including why 75ms of network latency adds 30% overhead and how colocating everything drops it to 5ms. youtu.be/N7b1PJc7SFc?si=dMFM…
1
3
11
2,469
Jun 12
@realDanFu guest lectured in @percyliang's CS336 at Stanford, check out what he covered:
→ The life of a token: KV cache, prefill/decode disaggregation, and what inference looks like at scale
→ Megakernels: fusing GPU ops to hit near speed-of-light LLM decode
→ Parcae: why loop transformers blow up, how to fix it, and some new scaling laws that suggest we've been leaving intelligence on the table
Catch the recording and a deep dive on Parcae below!
1
21
2,607
Jun 12
Watch the session: youtube.com/watch?v=9EEm4iMA…
Read about Parcae: together.ai/blog/parcae
3
705
Jun 11
Training a Llama 3B model with a 3M token context on a single 8xH100 node fails because model parameters alone exhaust GPU memory. @m_ryabinin explains how Untied Ulysses, his team's latest research, pushes past that wall, training at 8B and 32B scale with 25% longer sequences than prior implementations.
youtube.com/watch?v=TUnPNY4E…
7
4
42
4,124
Jun 11
Frontier model performance on an open model, post-trained in under 24 hours. @trajectorylabs is showing what's possible when great open models meet the right training infrastructure. Proud to power the compute behind this work alongside @nvidia .
Jun 10

1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.

4
5
21
5,834
Jun 11
M3’s architecture makes long-context inference more efficient. Serving it at production scale required systems work.
Together’s kernel and inference teams built KV-block-major sparse attention, integrated MSA with paged KV cache, optimized decode index scoring, and moved multimodal preprocessing into a Rust gateway before requests reach GPU workers.
4
3
40
6,163

Jun 10
Learn how @cursor_ai partnered with Together AI to deliver real-time inference for AI-powered coding in this article from @ce_zhang and @realDanFu.
Cursor's in-editor agents generate code while developers actively edit — requiring responses inside the editor's feedback loop. Together AI built the infrastructure to meet those strict latency targets at scale.
3
1
22
5,235
Together AI retweeted

Jun 10
As vertically integrated platforms start to dominate they lock out third party access to the most valuable portions of the platform.
Of course, Anthropic is has the right to implement whatever policy they want. But this is why open-weights are critical for human progress.
Jun 9

BREAKING NEWS: Anthropic's latest model will NOT help you if it thinks your ML research/ML engineering is interesting, and/or will secretly degrade its IQ so that the average engineer won't notice. We are already seeing Anthropic's latest model's moderation filters our GPU inference research and programming 😭

3
6
44
3,798