
55 Photos and videos










Pinned Tweet
We present Compute Optimal Tokenization! 🔡
Common in LLM scaling works stick to one tokenizer, sweeping data/model size.
But what happens when we control the tokenizer’s compression rate (bytes/token)?
Here we sweep tokenizers, params, and data across compute budgets: [1/N]
21
95
620
104,465
Tomasz Limisiewicz retweeted

Jun 11
Blog post about my recent optimal tokenizer exploration blog.aqnichol.com/2026/06/10…
4
5
46
3,861
Tomasz Limisiewicz retweeted

COLM 2026 will host 16(!) workshops:
colmweb.org/workshops.html
CFPs are all online, and deadlines are coming up, so check the CFP of your workshops of interest

21
74
16,999

May 26
Happy to share that the unprocessed results and code for fitting scaling laws and plotting are now available at:
github.com/facebookresearch/…

We present Compute Optimal Tokenization! 🔡
Common in LLM scaling works stick to one tokenizer, sweeping data/model size.
But what happens when we control the tokenizer’s compression rate (bytes/token)?
Here we sweep tokenizers, params, and data across compute budgets: [1/N]
6
24
1,825
Tomasz Limisiewicz retweeted

Announcing First Call for Papers: Second Tokenization Workshop 🔡 📣
▶️ Non-archival submissions of two types: Research papers (up to 9 pages)
▶️ Extended abstracts (up to 2 pages)
Submission deadline June 23, 2026 (AoE)
Acceptance notification on July 24, 2026 (AoE)

1
12
16
4,104
Tomasz Limisiewicz retweeted

May 18
MoEs are everywhere, but the design space is confusing: total vs active experts? expert size? shared experts? routing? token dropping?
We train >2000 MoE LMs 🫠 to investigate and bring you:
📄🔪🍰 Slicing and Dicing MoEs
Tl;dr: it's all about expert size and count
[1/9]

15
56
377
36,582
Tomasz Limisiewicz retweeted

May 14
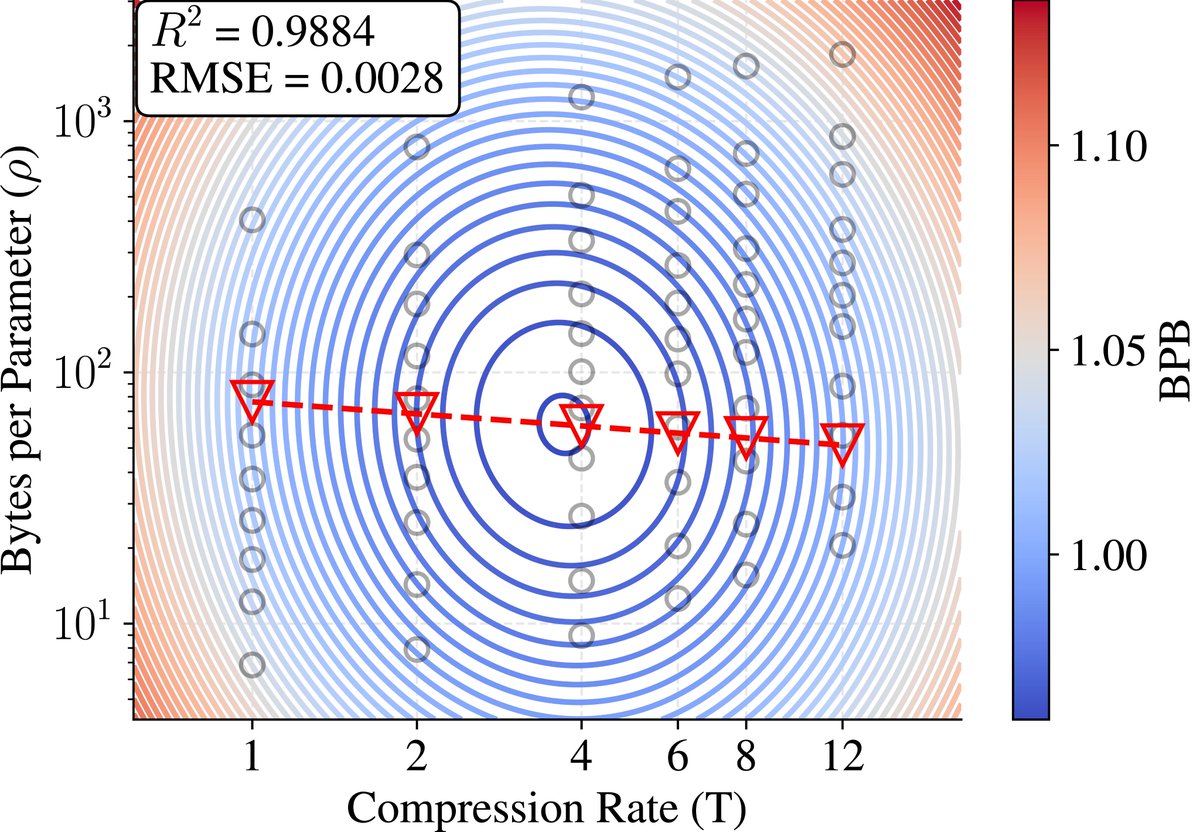
In SuperBPE we found: as tokenizer compression increases, the compute-optimal ratio of train tokens to model params decreases — and remarkably, corresponds to the same underlying ratio of train *bytes* / param! Our new work makes it official: scaling laws depend on compression.

We present Compute Optimal Tokenization! 🔡
Common in LLM scaling works stick to one tokenizer, sweeping data/model size.
But what happens when we control the tokenizer’s compression rate (bytes/token)?
Here we sweep tokenizers, params, and data across compute budgets: [1/N]
3
23
198
25,730
May 14
See you there! 🌉🔠

TokShop will be at #COLM2026!
🗓️ October 9th, 2026
📍 San Francisco, USA
More details and a call for papers coming soon.

10
353
Tomasz Limisiewicz retweeted

May 12
1/
The "20 tokens per parameter" Chinchilla scaling law is flawed. It is an artifact of your tokenizer. Scaling shouldn't be measured in tokens at all. It should be measured in bytes. 🧵

6
46
344
19,482
May 11
There is life beyond BPE!
🔠🌱🥪
Don’t miss this amazing work from @JulieKallini tackling one of the key challenges of byte-level LLMs: generation speed.
Diffusion and speculative decoding come to the rescue, enabling much faster generation with BLT with similar performance.
May 11

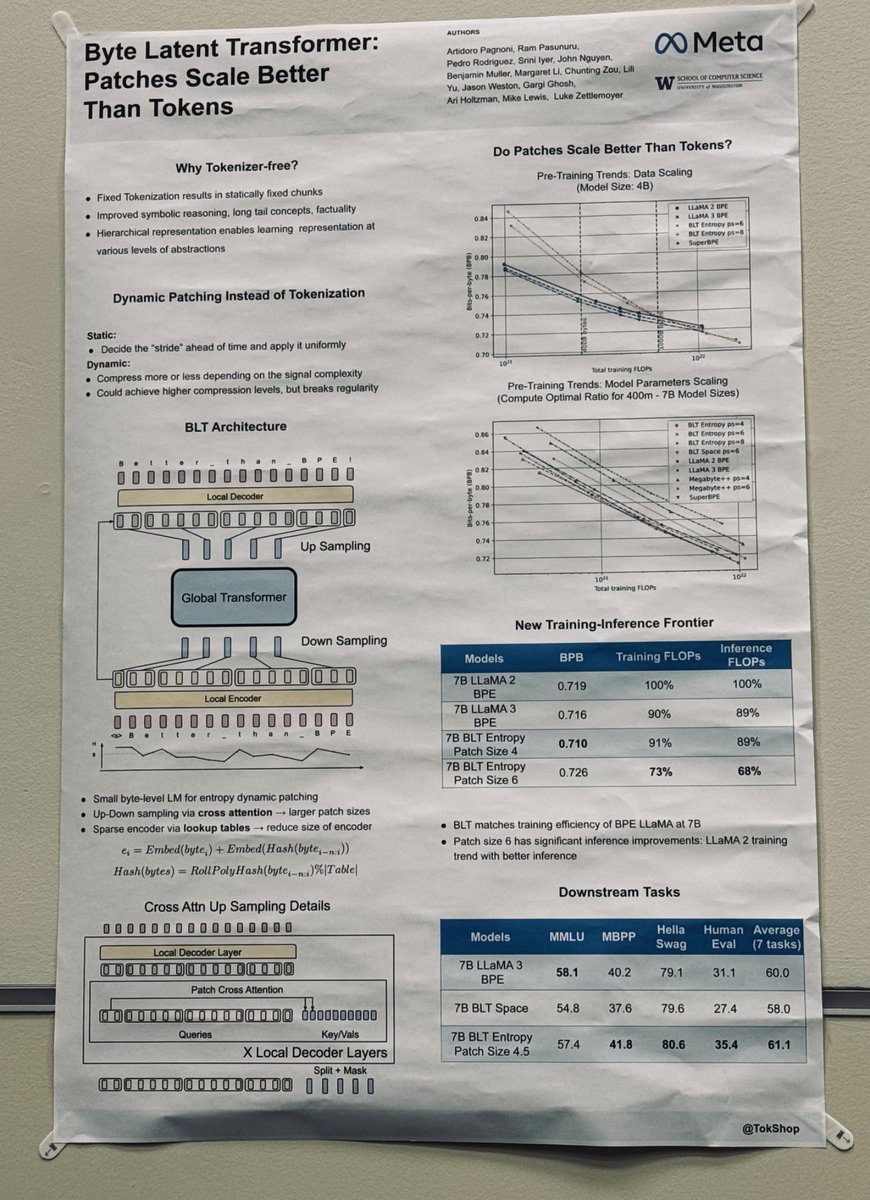
Fast Byte Latent Transformer is accepted to ICML 2026! ⚡🥪
Byte-level LMs promise to free us from subword tokenizers, but decoding one byte at a time is super slow.
We make BLT generation more efficient with BLT-D: text diffusion for parallel byte decoding. 1/
1
3
25
3,104
Tomasz Limisiewicz retweeted

Tokens are not a universal unit of data.
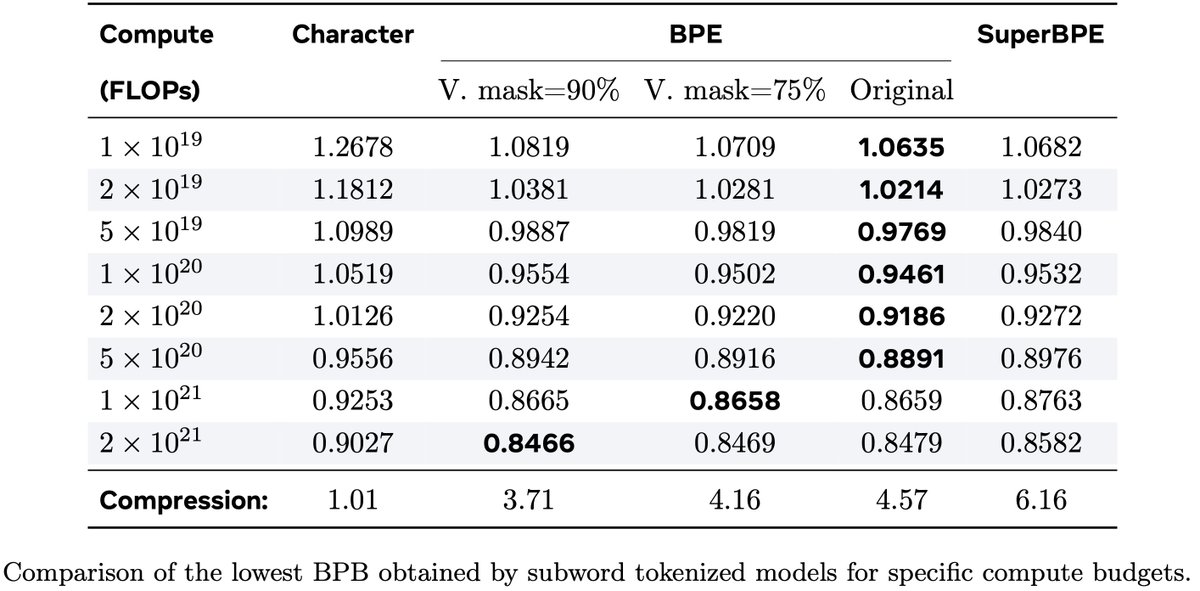
In our new work on Compute Optimal Tokenization, we show that when adapting scaling recipes across tokenizers, bytes are the more stable unit. And the compute-optimal compression rate is not necessarily what today’s BPE tokenizers use.
We present Compute Optimal Tokenization! 🔡
Common in LLM scaling works stick to one tokenizer, sweeping data/model size.
But what happens when we control the tokenizer’s compression rate (bytes/token)?
Here we sweep tokenizers, params, and data across compute budgets: [1/N]
3
6
69
8,327
Tomasz Limisiewicz retweeted

May 4
Extremely excited about our work on Compute Optimal Tokenization! This paper categorically nails down the role that compression plays in compute optimality and recommends how to scale models keeping compression in mind. Cool results on multiple languages too!
We present Compute Optimal Tokenization! 🔡
Common in LLM scaling works stick to one tokenizer, sweeping data/model size.
But what happens when we control the tokenizer’s compression rate (bytes/token)?
Here we sweep tokenizers, params, and data across compute budgets: [1/N]
4
7
1,405
Tomasz Limisiewicz retweeted

May 5
larger compute prefer smaller vocabulary, interesting.
2 follow-up questions:
1. can we decouple in/out tokenization? to isolate the effect of more-input-tokens vs. finer-prediction-granularity.
(see also arxiv.org/abs/2504.14992)
2. can we combine it with n-gram embed?
These findings hold both for latent tokenizers (BLT) and subword tokenizers (BPE variants).
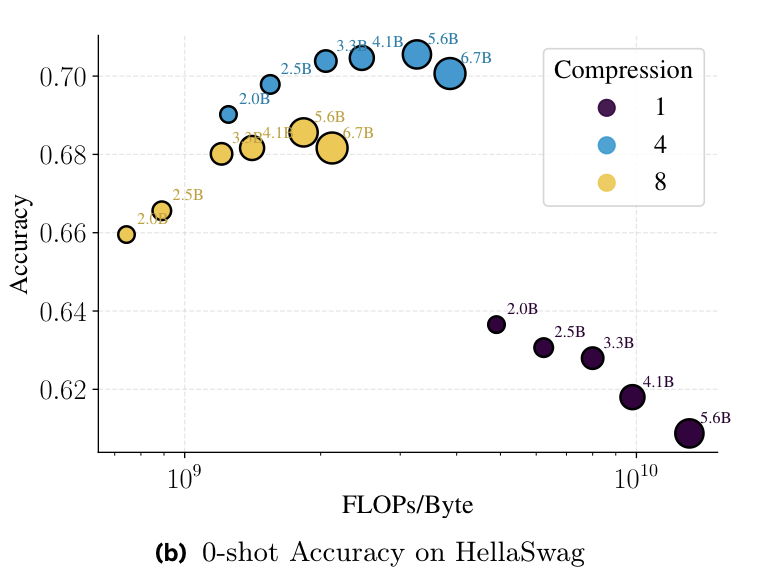
Interestingly, with BPE we observe that at large scale decreasing compression by choosing smaller vocabulary improves performance. [4/N]
1
5
32
3,929
We present Compute Optimal Tokenization! 🔡
Common in LLM scaling works stick to one tokenizer, sweeping data/model size.
But what happens when we control the tokenizer’s compression rate (bytes/token)?
Here we sweep tokenizers, params, and data across compute budgets: [1/N]
21
95
620
104,465
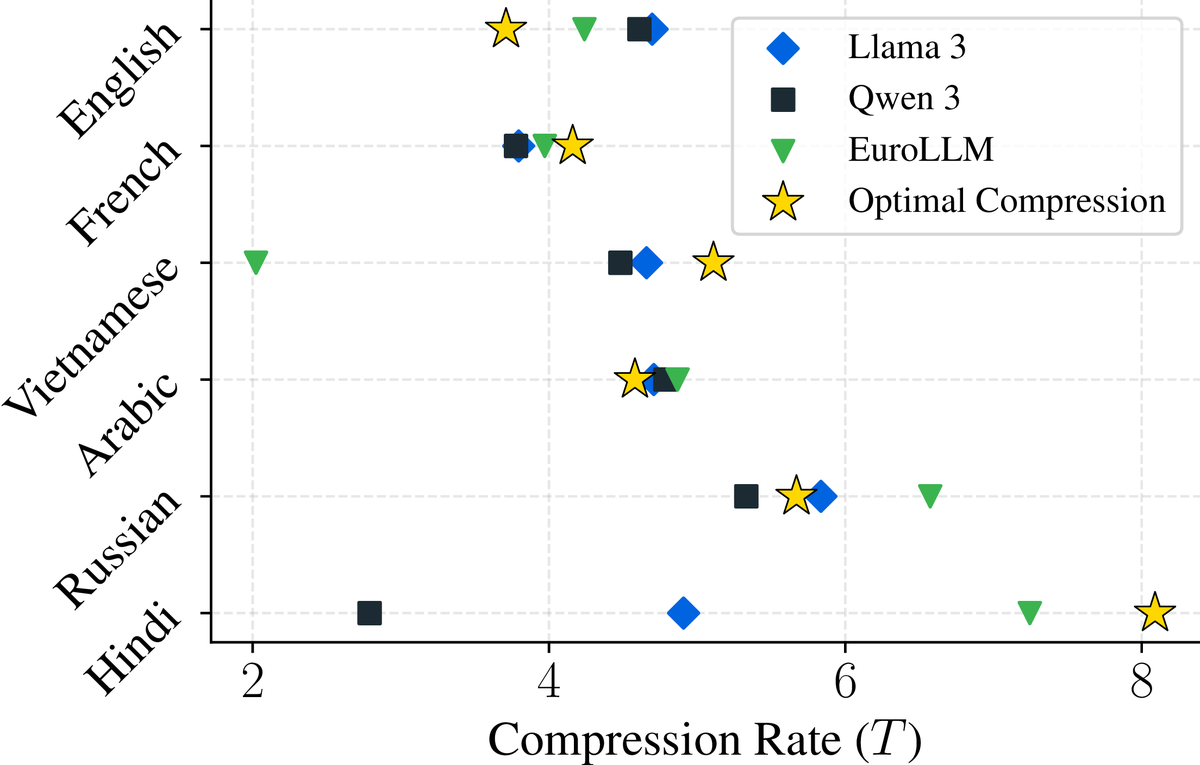
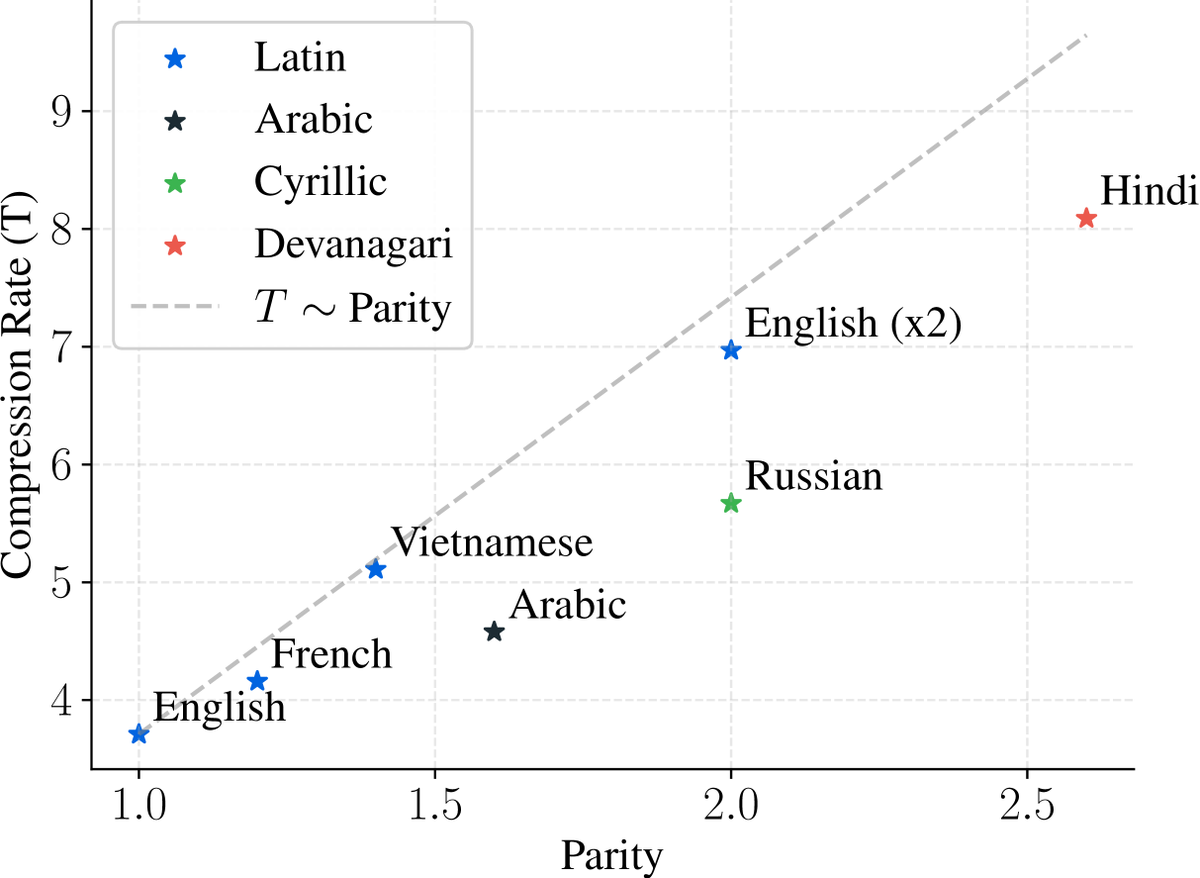
At the same time, the optimal compression rate varies across languages and can differ substantially from the compression rate of popular BPE tokenizers. [7/N]
1
2
21
2,367
Find more in the blogpost: co-tok.github.io/
And the paper: co-tok.github.io/paper.pdf
Huge thanks to my amazing co-authors at @AIatMeta : @ArtidoroPagnoni @sriniiyer88 @ml_perception @sacmehtauw @gargighosh @LukeZettlemoyer
and @uwnlp: @margs_li @alisawuffles
[8/N]
1
1
33
2,229