
Llama3 pre-training lead. Partially to blame for things like the Cicero Diplomacy bot, BART, RoBERTa, attention sinks, kNN-LM, top-k sampling & Deal Or No Deal.
Joined September 2019
- Tweets 277
- Following 252
- Followers 8,406
- Likes 837
11 Photos and videos





Feb 4
Excited to see what the amazing @sarahookr and team build here!
Feb 4

Beginnings are very special. Today is an important day for @adaptionlabs.
Today a handful of one-size-fits-all-models are optimized for the average use case.
Averages erase the exceptional.
Everything intelligent adapts. So should AI.
13
2,959
Mike Lewis retweeted

Jan 22
Our team in FAIR at Meta is hiring a (full-time) researcher!
We work on the topics of Reasoning, Alignment and Memory/architectures (RAM) for self-improvement & co-improvement.
Apply here:
metacareers.com/profile/job_…
Location: NY, Seattle or Menlo Park.
Some of our recent work to give flavor:
Co-Improvement (position): arxiv.org/abs/2512.05356
SPICE (Self-Play in Corpus Environments): arxiv.org/abs/2510.24684
Self-Challenging Agents: arxiv.org/abs/2506.01716
RL from Human Interaction: arxiv.org/abs/2509.25137
AggLM (parallel aggregation): arxiv.org/abs/2509.06870
StepWiser (CoT-PRM RL): arxiv.org/abs/2508.19229
DARLING (diversity-trained RL): arxiv.org/abs/2509.02534
J1 (RL-trained LLM-as-Judge): arxiv.org/abs/2505.10320
CoT-Self-Instruct: arxiv.org/abs/2507.23751
Multi-Token Attention: arxiv.org/abs/2504.00927
10
33
351
57,876
Mike Lewis retweeted

8 Oct 2025
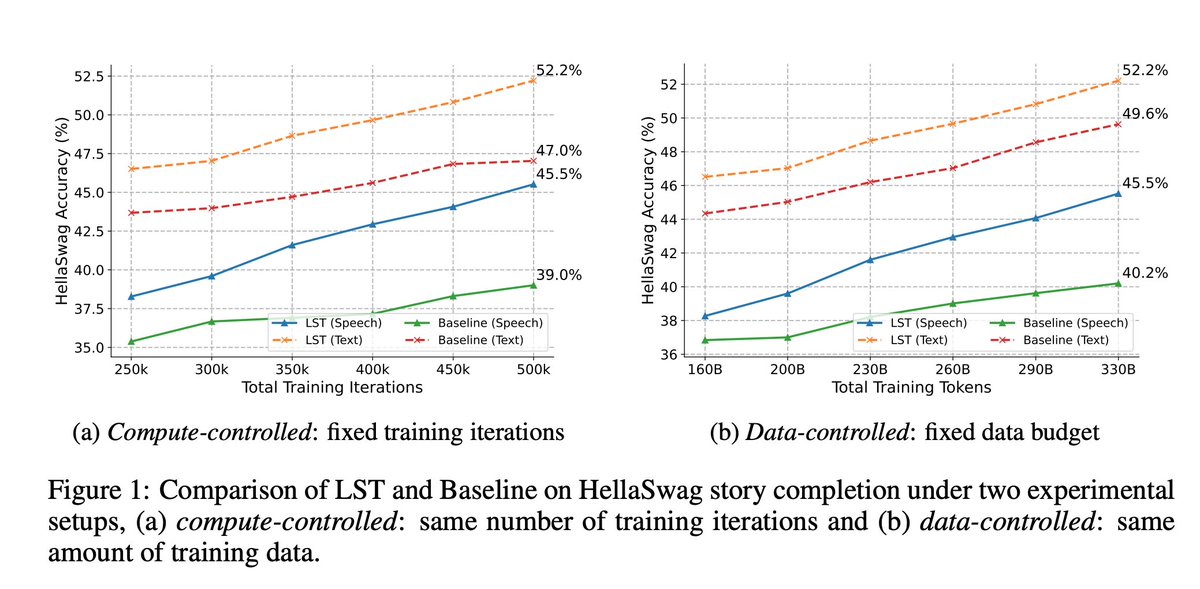
🚀 Introducing the Latent Speech-Text Transformer (LST) — a speech-text model that organizes speech tokens into latent patches for better text→speech transfer, enabling steeper scaling laws and more efficient multimodal training ⚡️
Paper 📄 arxiv.org/pdf/2510.06195
7
16
35
9,527
13 Aug 2025
Love seeing these incredibly creative new evaluations! Optimizing benchmarks is easy, the real challenge is in generalizing to the tasks that don't exist yet


3
49
6,311
Mike Lewis retweeted

8 Aug 2025
I've written the full story of Attention Sinks — a technical deep-dive into how the mechanism was developed and how our research ended up being used in OpenAI's new OSS models.
For those interested in the details:
hanlab.mit.edu/blog/streamin…

40
275
2,200
264,843
Mike Lewis retweeted

6 Apr 2025
Don’t miss this - I’ve worked with Mike (@ml_perception) very closely at Meta and his talks are super informative and fun.
4 Apr 2025

Want to learn about Llama's pre-training? Mike Lewis will be giving a Keynote at NAACL 2025 in Albuquerque, NM on May 1.
2025.naacl.org/
@naaclmeeting

1
25
4,338
Mike Lewis retweeted

21 Mar 2025
📉📉NEW SCALING LAW PHENOMENON 📉📉
We find that knowledge and reasoning exhibit different scaling behaviors!
Super excited to finally tell you all about our paper on the compute optimal scaling of skills:
arxiv.org/pdf/2503.10061
[1/n]

13
170
1,083
136,009
Mike Lewis retweeted

4 Feb 2025
✨New Preprint✨We introduce 𝐁𝐫𝐚𝐧𝐜𝐡-𝐓𝐫𝐚𝐢𝐧-𝐒𝐭𝐢𝐭𝐜𝐡 (𝐁𝐓𝐒), an efficient & flexible method for stitching together independently pretrained LLM experts (i.e. code, math) into a single, capable generalist model.
Key Takeaways:
✅BTS achieves the best average generalist performance across a variety of tasks 👊
✅We stitch together 4 x 2.7B specialized expert LLMs, where only the lightweight stitching layers (<300M params in total‼) are trained while the experts’ params remain frozen. This makes BTS super modular, flexible, and easy to train! 👊
arxiv.org/abs/2502.00075
Work done at @AIatMeta w/ @prajjwal_1, Chloe Bi, Chris Cai, @j_foerst @imjeremyhi @punitkoura, Ruan Silva, @shengs1123 @em_dinan* @ssgrn* @ml_perception*
* Joint last author
🧵👇(1/5)
1
8
76
18,587
Mike Lewis retweeted

13 Dec 2024
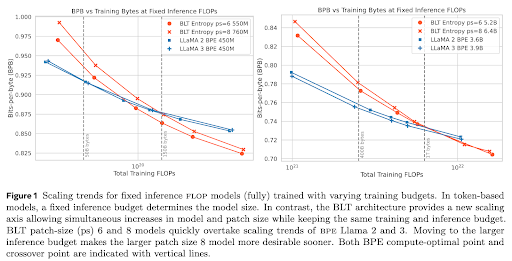
🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/B…
Code 🛠️ github.com/facebookresearch/…
16
141
718
181,697
Mike Lewis retweeted

8 Nov 2024
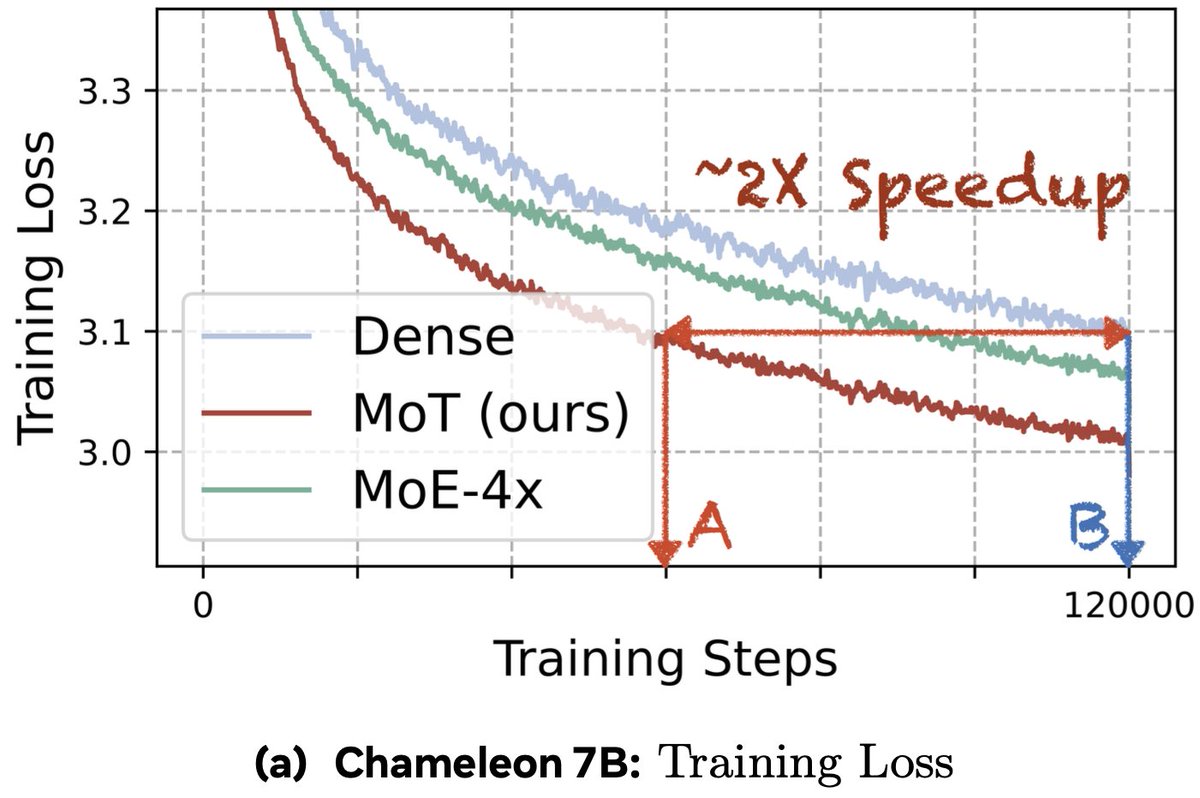
How can we reduce pretraining costs for multi-modal models without sacrificing quality? We study this Q in our new work: arxiv.org/abs/2411.04996
At @AIatMeta, We introduce Mixture-of-Transformers (MoT), a sparse architecture with modality-aware sparsity for every non-embedding transformer parameter (e.g., feed-forward networks, attention matrices, and layer normalization). MoT achieves dense-level performance with up to 66% fewer FLOPs!
✅ Chameleon setting (text image generation): Our 7B MoT matches dense baseline quality using just 55.8% of the FLOPs.
✅ Extended to speech as a third modality, MoT achieves dense-level speech quality with only 37.2% of the FLOPs.
✅ Transfusion setting (text autoregressive image diffusion): MoT matches dense model quality using one-third of the FLOPs.
✅ System profiling shows MoT achieves dense-level image quality in 47% and text quality in 75.6% of the wall-clock time**
Takeaway: Modality-aware sparsity in MoT offers a scalable path to efficient, multi-modal AI with reduced pretraining costs.
Work of a great team with @liliyu_lili, Liang Luo, @sriniiyer88, Ning Dong, @violet_zct, @gargighosh, @ml_perception, @scottyih, @LukeZettlemoyer, @VictoriaLinML.👏
**Measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs.


5
36
216
91,515
Mike Lewis retweeted

1 Aug 2024
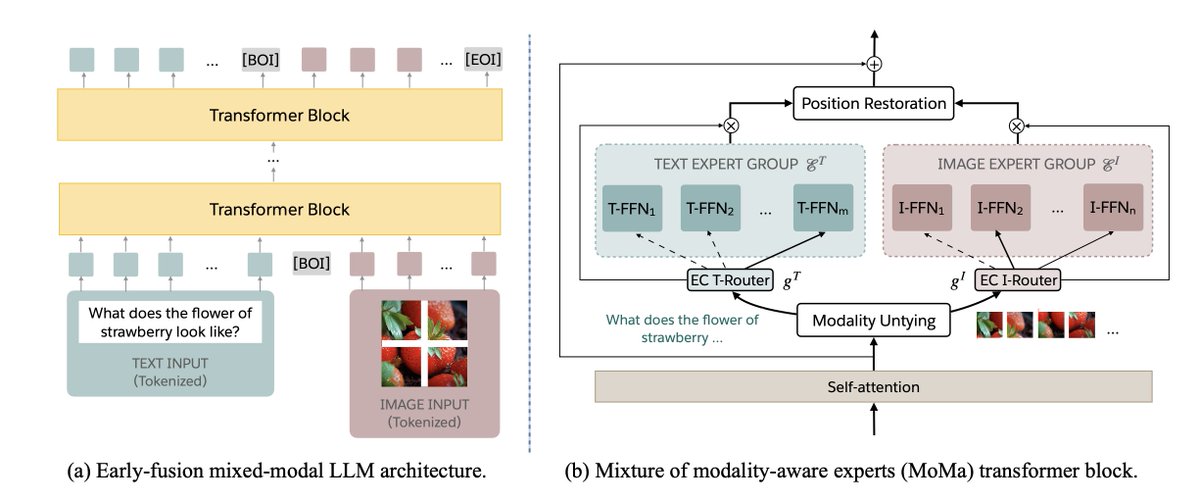
1/n Introducing MoMa 🖼, our new sparse early-fusion architecture for mixed-modal language modeling that significantly boosts pre-training efficiency 🚀 (arxiv.org/pdf/2407.21770).
MoMa employs a mixture-of-expert (MoE) framework with modality-specific expert groups. Given any interleaved mixed-modal token sequences, each group exclusively processes tokens of the designated modality with conventional MoE routing.
This is joint work with amazing co-first authors @AkshatS07, @ArmenAgha and collaborators @AIatMeta – Liang Luo, @sriniiyer88, @ml_perception, @gargighosh and @LukeZettlemoyer.
8
50
307
101,898
23 Jul 2024
tldr; you can go a long way in pre-training by (1) curating amazing data, (2) using a lot of FLOPs, and (3) otherwise not screwing up. All three are harder than they sound, so read the paper... That said, I'm amazed by our progress since Llama 3 - expect big things from Llama 4!
23 Jul 2024

So excited for the open release of Llama 3.1 405B - with MMLU > 87, it's a really strong model and I can't wait to see what you all build with it! llama.meta.com/ Also check out the paper here, with lots of details on how this was made: tinyurl.com/2z2cpj8m
4
15
164
25,771
23 Jul 2024
So excited for the open release of Llama 3.1 405B - with MMLU > 87, it's a really strong model and I can't wait to see what you all build with it! llama.meta.com/ Also check out the paper here, with lots of details on how this was made: tinyurl.com/2z2cpj8m
3
19
178
44,233
18 Jun 2024
Excited to see the open source release of FAIR's early fusion multimodal LLMs!
18 Jun 2024

Today is a good day for open science.
As part of our continued commitment to the growth and development of an open ecosystem, today at Meta FAIR we’re announcing four new publicly available AI models and additional research artifacts to inspire innovation in the community and help advance AI in a responsible way. More in the video from @jpineau1.
What we’re releasing:
🦎 Meta Chameleon
7B & 34B language models that support mixed-modal input and text-only outputs.
🪙 Meta Multi-Token Prediction
Pretrained Language Models for code completion using Multi-Token Prediction.
🎼 Meta JASCO
Generative text-to-music models capable of accepting various conditioning inputs for greater controllability. Paper available today with a pretrained model coming soon.
🗣️ Meta AudioSeal
An audio watermarking model that we believe is the first designed specifically for the localized detection of AI-generated speech, available under a commercial license.
📝 Additional RAI artifacts
Including research, data and code to measure and improve the representation of geographical and cultural preferences and diversity in AI systems.
We believe that access to state-of-the-art AI creates opportunities for everyone – not just a small handful of Big Tech companies. We’re excited to share this work and to see how the community learns, iterates and builds using this technology.
Details and access to everything released by FAIR today ➡️ go.fb.me/tzzvfg
4
46
6,200

Thrilled to be in Vienna for our ICLR workshop, Navigating and Addressing Data Problems for Foundation Models. Starting Saturday at 8:50 AM, our program features keynote talks, best paper presentations, a poster session, and a panel discussion. Explore the full schedule here! sites.google.com/view/dpfm-i…

2
16
58
30,513
Mike Lewis retweeted

7 May 2024
Introducing Lory, a fully-differentiable MoE arch for decoder LM pre-training!
Lory merges expert FFNs by computing a weighted average in the parameter space, and computes the output through the merged FFNs.
But training naively is infeasible, how to make it work?
Details in🧵

4
42
229
22,810
7 May 2024
Heading to ICLR! I’m writing fewer papers now to train more Llamas, but proud of our work here: Instruction Backtranslation (arxiv.org/abs/2308.06259), Attention Sinks, (arxiv.org/abs/2309.17453) In Context Pretraining (arxiv.org/abs/2310.10638) and RA-DIT (arxiv.org/abs/2310.01352).
5
11
124
16,920

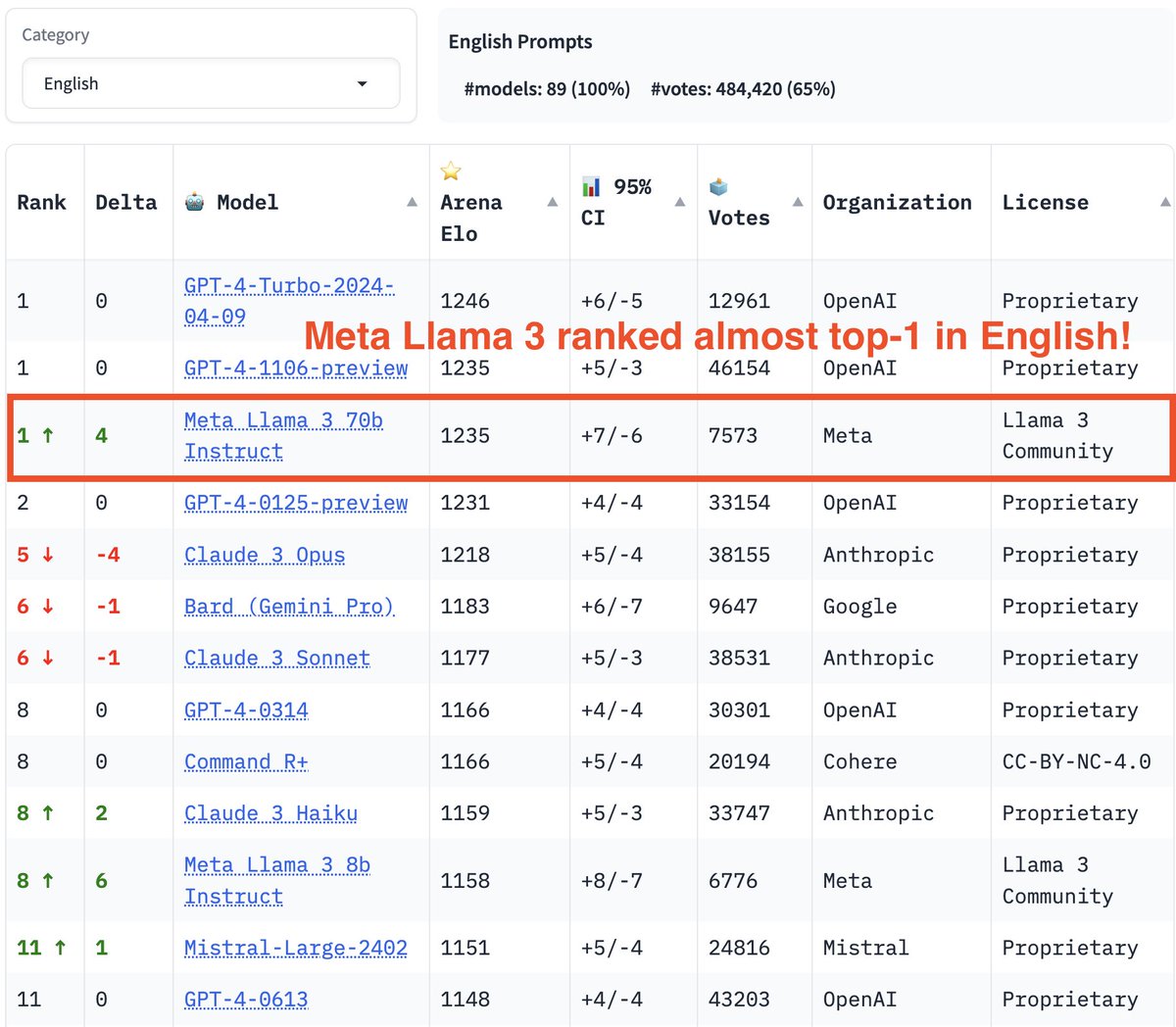
Moreover, we observe even stronger performance in English category, where Llama 3 ranking jumps to ~1st place with GPT-4-Turbo!
It consistently performs strong against top models (see win-rate matrix) by human preference. It's been optimized for dialogue scenario with large amount of instruction data in post-training.
More analysis still ongoing with topic distribution and agreement study. We also look forward to details in Llama-3's technical report.
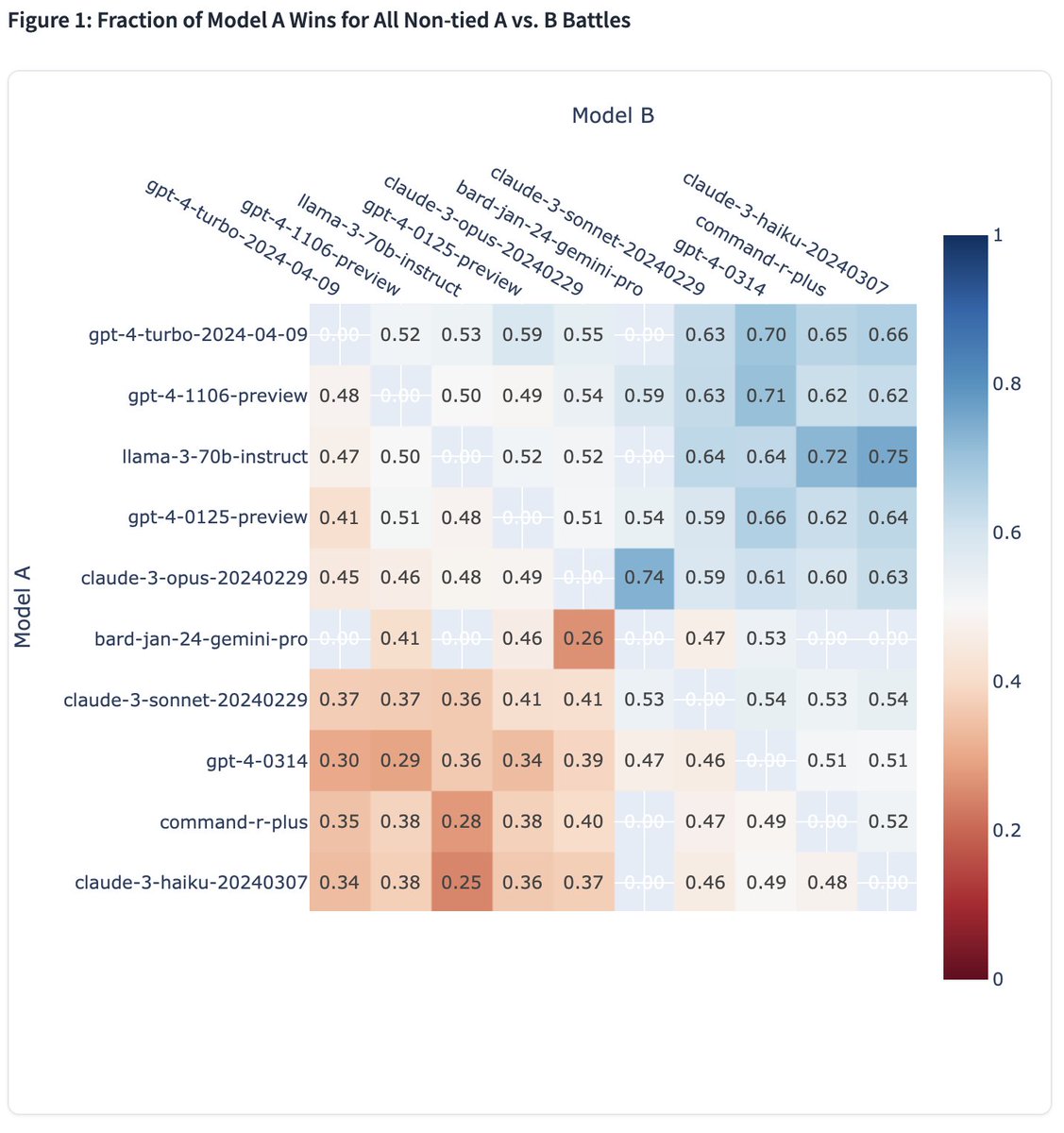
11
38
369
346,820
19 Apr 2024
I'm seeing a lot of questions about the limit of how good you can make a small LLM. tldr; benchmarks saturate, models don't. LLMs will improve logarithmically forever with enough good data.
18 Apr 2024
Yes, both the 8B and 70B are trained way more than is Chinchilla optimal - but we can eat the training cost to save you inference cost! One of the most interesting things to me was how quickly the 8B was improving even at 15T tokens.
5
14
169
34,870
18 Apr 2024
Yes, both the 8B and 70B are trained way more than is Chinchilla optimal - but we can eat the training cost to save you inference cost! One of the most interesting things to me was how quickly the 8B was improving even at 15T tokens.
18 Apr 2024

Llama3 8B is trained on almost 100 times the Chinchilla optimal number of tokens
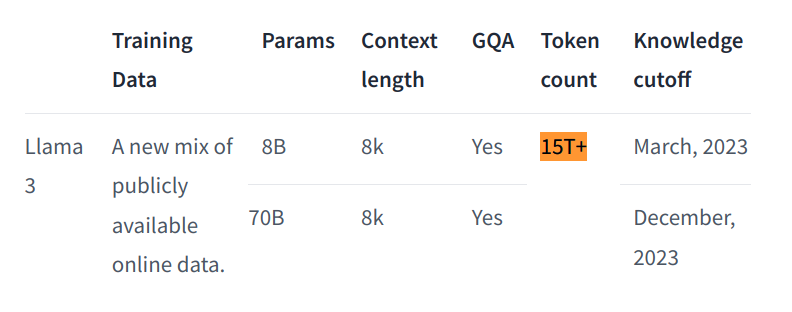
13
34
482
92,521