
Building the platform for Continual Learning
Joined December 2025
- Tweets 25
- Following 1
- Followers 2,934
- Likes 123
8 Photos and videos
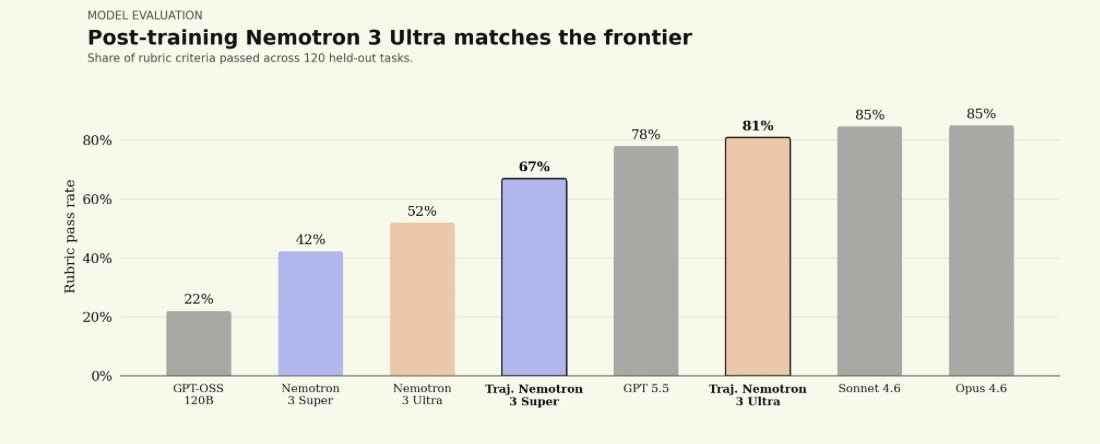
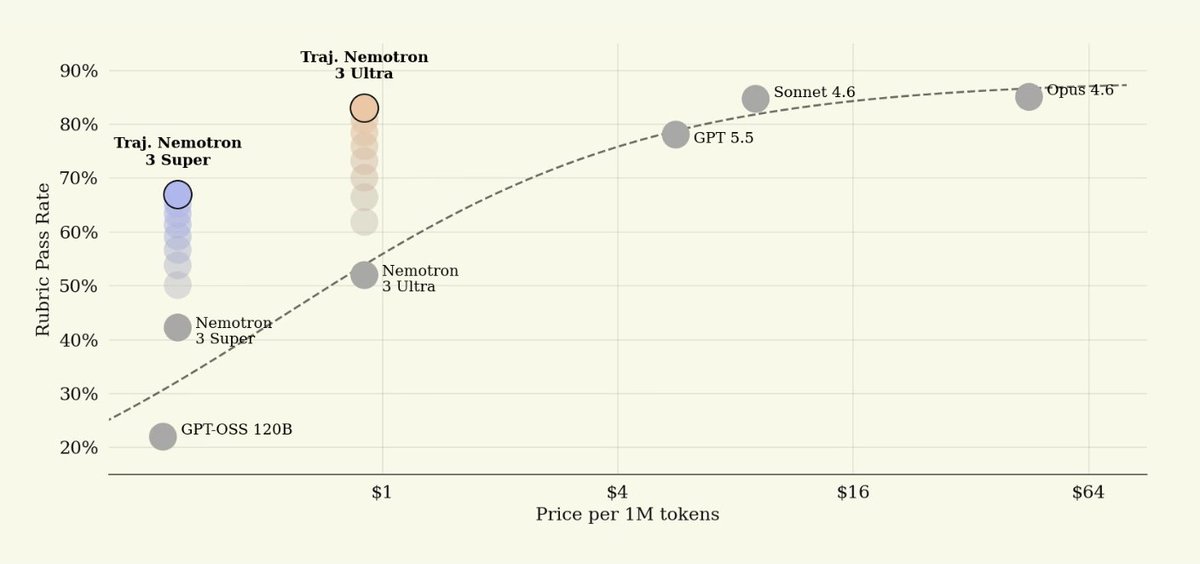







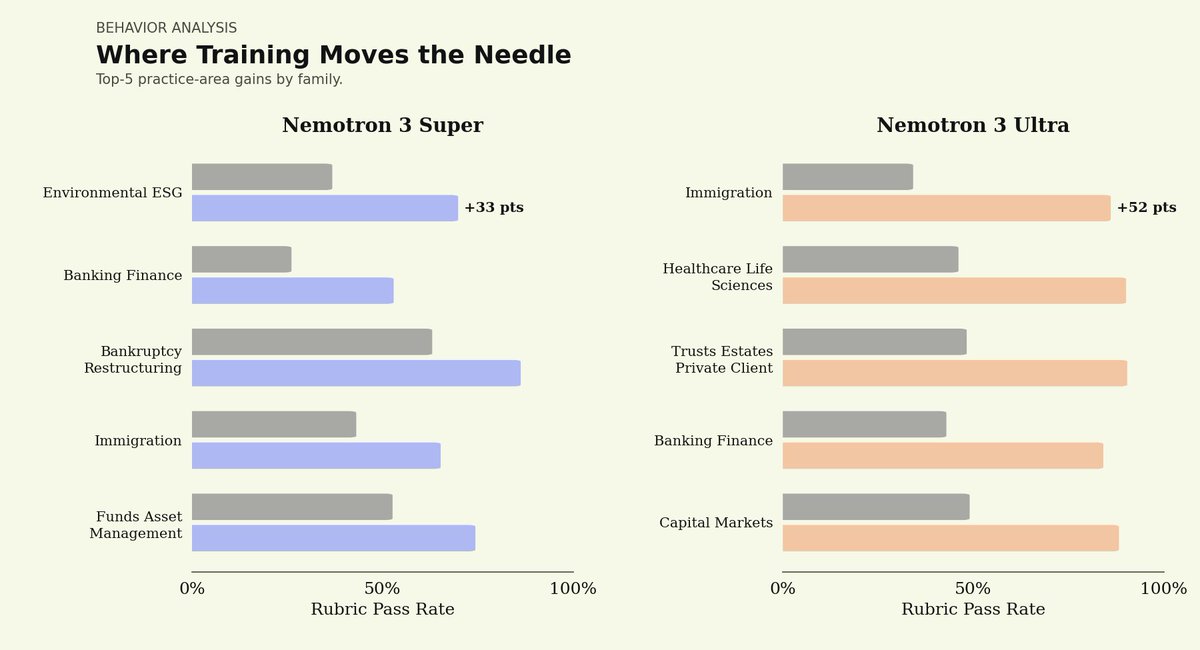
We partnered with @trajectorylabs to post-train NVIDIA Nemotron 3 Ultra for legal. Here’s what we found:
1) Open-weight models can reach frontier legal performance.
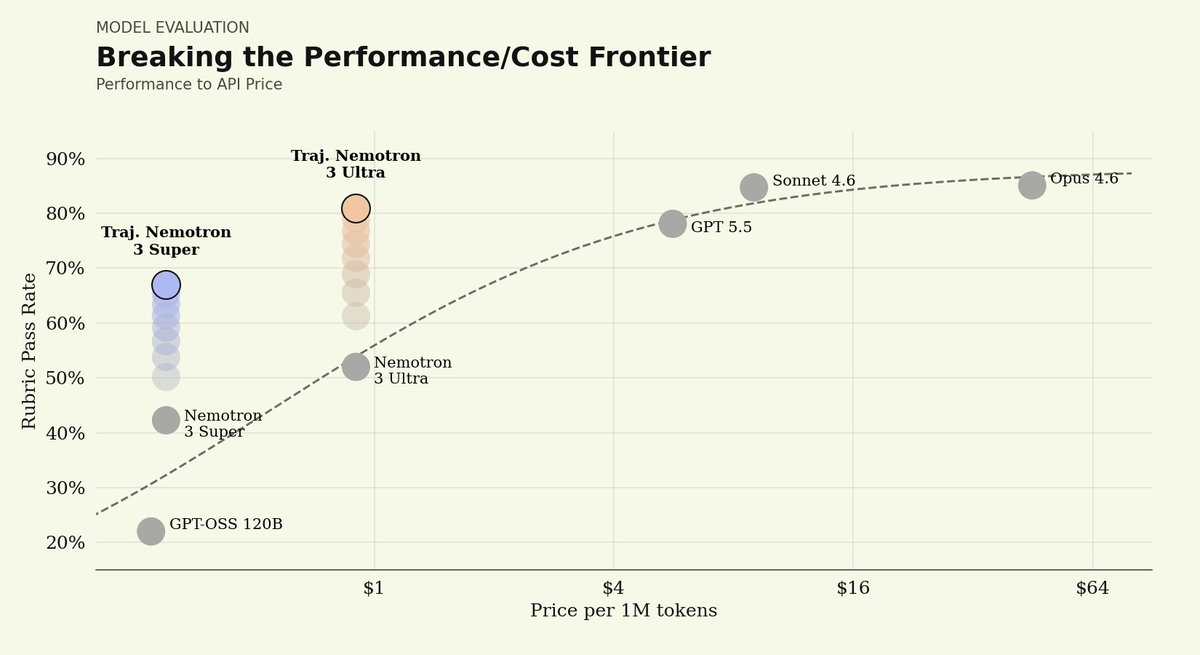
On our Legal Agent Benchmark (LAB), Nemotron 3 Ultra started at a 0% all-pass rate. After post-training, it reached 5.8%, placing it between Sonnet 4.6 at 4.2% and Opus 4.6 at 6.6%.
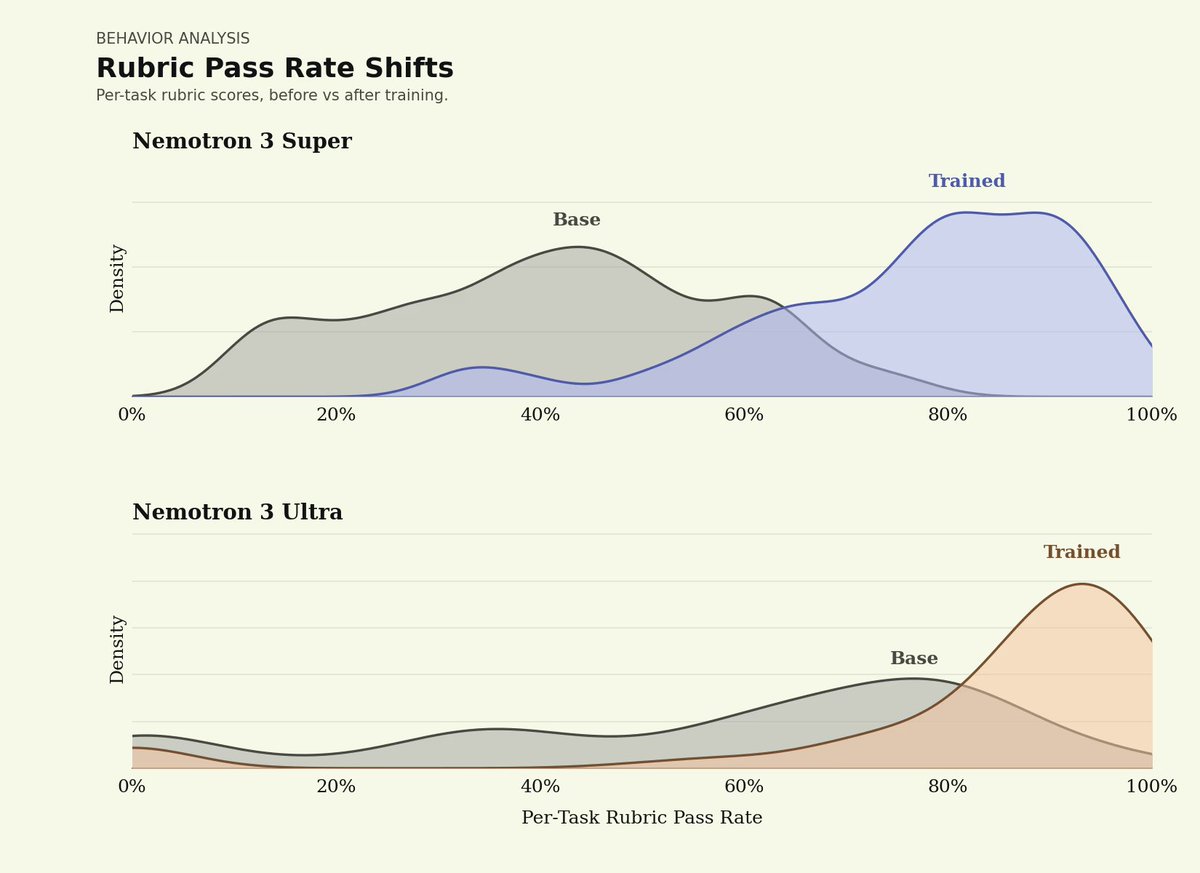
2) Post-training dramatically improves reliability.
Before training, many held-out tasks missed enough rubric dimensions to land around ~70% pass rates. After training, those tasks shifted toward ~95% pass rates.
3) Open-weight performance comes at much lower cost.
Post-trained Nemotron 3 Ultra reached a similar quality band to leading closed models while running at roughly 1/8th to 1/50th the per-token price of Sonnet 4.6 and Opus 4.6.
Most importantly: we post-trained this model on the @trajectorylabs platform less than 24 hours after Nemotron 3 Ultra launched, using the same harness, data, and recipe we used for Nemotron 3 Super.
More to come as we continue to experiment with open-weight legal agents.
Read more on post-training with Trajectory below:
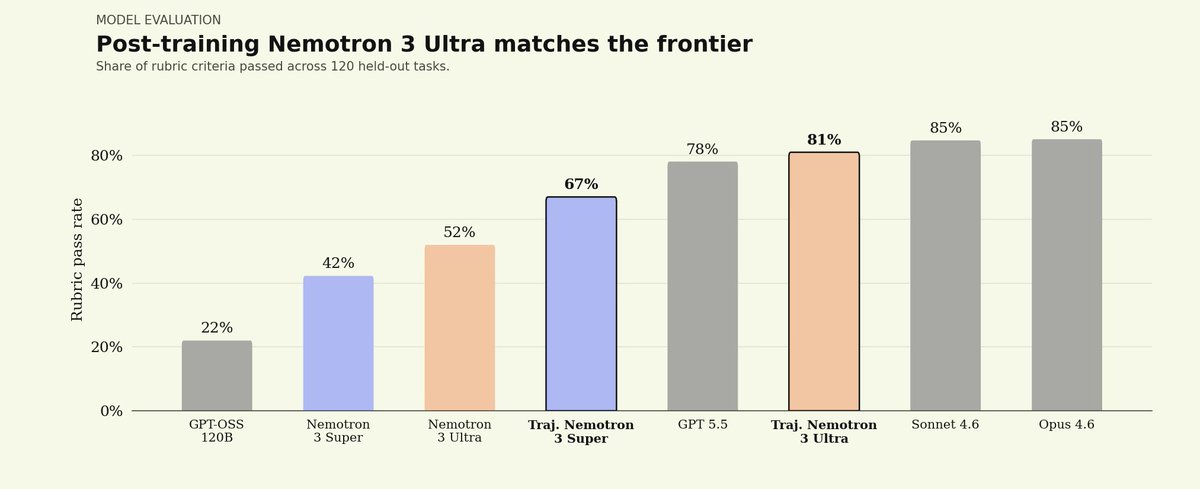
Jun 10

1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.
11
31
277
47,892

Jun 10
1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.
9
20
261
75,314
Jun 10
4/ The shift is that the most valuable training signal already lives inside companies.
Every brief, edit, correction, review, approval, and workflow is proprietary data that can make their models better.
Open models give companies the weights.
Trajectory helps them turn their own work into capability.
1
8
1,773
Trajectory retweeted

Jun 4
Nemotron 3 Ultra from @nvidia is out today and available on Tinker day one!
The flagship from the Nemotron family is built for long-running agents; @trajectorylabs have been using it in early access to power continual learning workflows.

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
5
8
68
7,543
Trajectory retweeted

Jun 3
We worked with @trajectorylabs to run their SDPO algorithm on APEX-Agents and see what it could do with real production data. Pass rates went from 5% to 25% on GPT-OSS-120B, and the curve is still climbing.
Read more about our work together in their blog post below.
Jun 2
5 Days of Trajectory
🏹Day 5: Scaling SDPO to Agentic Tasks
Continual learning means you must train on data from production. But production gives you one example per task. A user makes a request once. You get one trajectory, not a batch.
However, current RL algorithms don't work that way, They need groups of tasks. By definition, that means you need some artificial environment to perform those rollouts in. But what if you don't?
SDPO is a promising route. It learns from a single trajectory, with no group required and failures still producing signal. The shape of the method matches the shape of production data.
But one fundamental problem remained. Every published SDPO work assumed fresh, on-policy rollouts. Agentic work cannot give you that. Trajectories run for an hour or more and arrive stale. On true agentic tasks, naive SDPO collapses.
We fixed it. We're the first to make SDPO work on agentic tasks.
On Mercor's APEX-Agents, with hour-long trajectories and near-zero base pass rates: 25% average reward, 5x over zero-shot. More importantly, it trains stably and the curve is still climbing.
Read more below.
2
2
56
13,068
Jun 2
5 Days of Trajectory
🏹Day 5: Scaling SDPO to Agentic Tasks
Continual learning means you must train on data from production. But production gives you one example per task. A user makes a request once. You get one trajectory, not a batch.
However, current RL algorithms don't work that way, They need groups of tasks. By definition, that means you need some artificial environment to perform those rollouts in. But what if you don't?
SDPO is a promising route. It learns from a single trajectory, with no group required and failures still producing signal. The shape of the method matches the shape of production data.
But one fundamental problem remained. Every published SDPO work assumed fresh, on-policy rollouts. Agentic work cannot give you that. Trajectories run for an hour or more and arrive stale. On true agentic tasks, naive SDPO collapses.
We fixed it. We're the first to make SDPO work on agentic tasks.
On Mercor's APEX-Agents, with hour-long trajectories and near-zero base pass rates: 25% average reward, 5x over zero-shot. More importantly, it trains stably and the curve is still climbing.
Read more below.
9
11
130
39,423
Jun 1
🏹 5 Days of Trajectory.
Day 4 - Why We’re Building Trajectory
AI is the most capable software ever built.
You correct it.
You teach it what you want.
However, the next session starts, and the learning is gone.
This is deeply unnatural - nothing intelligent works this way.
Today, we’re sharing the thesis behind Trajectory:
- why continual learning is the next platform shift in AI
- why the primitive governing that shift is the trajectory
- our plan to move products from being shipped to being grown: first make the intelligence layer better, faster, and cheaper; then make it shapeable; finally, make it learn
Read more below⬇️
6
5
66
62,954
May 31
We’re taking a quick break for the 5 days of Trajectory, but wanted to take this time to say that we’ve been named to @Redpoint’s 2026 Infrared 100 as one of the companies shaping the future of AI infrastructure.
We're so grateful for the recognition so early in our journey, and want to congratulate the other awardees as well!
5
5
66
7,840
May 30
🏹5 Days of Trajectory.
Day 3 - An Open Source Training Stack for Continual Learning
Building the platform for continual learning requires both partnering with pioneering AI companies, as we showed on Day 2 with Harvey, and working toward frontier research, which we are highlighting today.
Continual learning means models that improve hourly from real production use. But with the size of frontier models, this becomes quite difficult. A Qwen-397b would need to spin up and tear down repeatedly across six GPU nodes, and that's valuable time gone.
Our contribution is Continual LoRA (C-LoRA): many lightweight adapters running at once on one shared base model. Our insight centers on where the parallelism lives: instead of splitting one giant job across nodes, we load-balance many small jobs over a single base.
The result: 2.81x experiment throughput over single-tenant training, with no regression on rewards.
We built this together, with @anyscalecompute, @NovaSkyAI, and generous support from @GoogleCloud and @GoogleStartups. We've open-sourced on SkyRL as one of the first multi-LoRA, RL training platforms, so that every team can get to continual learning faster.
We’re very excited to see what you build, please reach out!
11
61
508
94,076
May 30
Try it out here:
Code: github.com/NovaSky-AI/SkyRL?…
Getting Started : trajectory.ai/field-notes/mu… (Section Getting-Started)
1
3
24
3,895

This is a great read on post-training and open models.
@harvey & @trajectorylabs post-trained Nemotron 3 Super on complex legal tasks with some very impressive initial results. All with auditable weights, real security, and clear provenance.

We're partnering with @trajectorylabs to bring sovereign continual learning to legal AI with NVIDIA Nemotron models.
Continual learning allows agents to improve over time from feedback on their work: every redline refines the next draft.
Open-weight models offer full auditability and data sovereignty over legal agents.
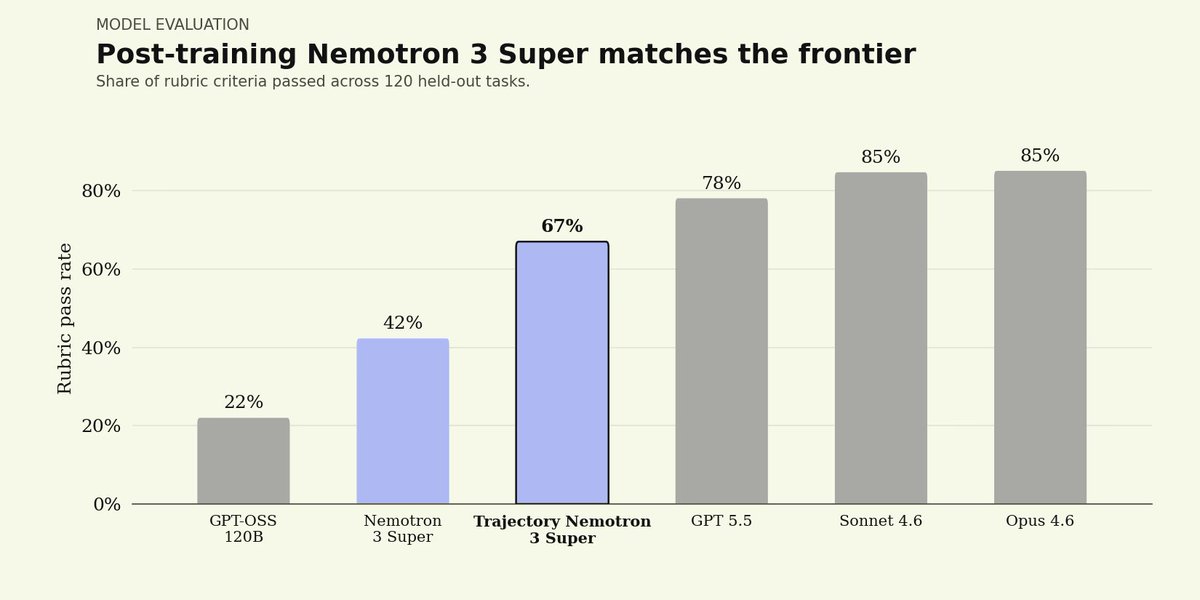
Using Trajectory's platform, we post-trained NVIDIA Nemotron 3 Super on our Legal Agent Benchmark (LAB), measuring performance on 1,200 complex end-to-end legal tasks across 24 practice areas.
Initial results show that a post-trained Nemotron 3 Super can match performance of closed-source frontier models.
This is just the start: we'll keep pushing the frontier with the more powerful Nemotron 3 Ultra when available.


16
36
252
30,953
We're partnering with @trajectorylabs to bring sovereign continual learning to legal AI with NVIDIA Nemotron models.
Continual learning allows agents to improve over time from feedback on their work: every redline refines the next draft.
Open-weight models offer full auditability and data sovereignty over legal agents.
Using Trajectory's platform, we post-trained NVIDIA Nemotron 3 Super on our Legal Agent Benchmark (LAB), measuring performance on 1,200 complex end-to-end legal tasks across 24 practice areas.
Initial results show that a post-trained Nemotron 3 Super can match performance of closed-source frontier models.
This is just the start: we'll keep pushing the frontier with the more powerful Nemotron 3 Ultra when available.
May 29
Welcome to Day 2. Yesterday, we showed the broader work we're doing with the pioneers of continual learning.
Today we'd like to deep dive on one: how we post-trained an open model for legal work, in partnership with @Harvey.
We've built a platform where production data is the moat. Every correction, retry, and edit becomes signal you can post-train on, and the models are plug and play: customer's can drop in their model of choice, and improve from there.
Fields like legal and finance make those demands absolute, with hard security, sovereignty, and provenance requirements. That's why we post-trained @nvidia 's open-weight Nemotron 3 Super, on Harvey's LAB benchmark.
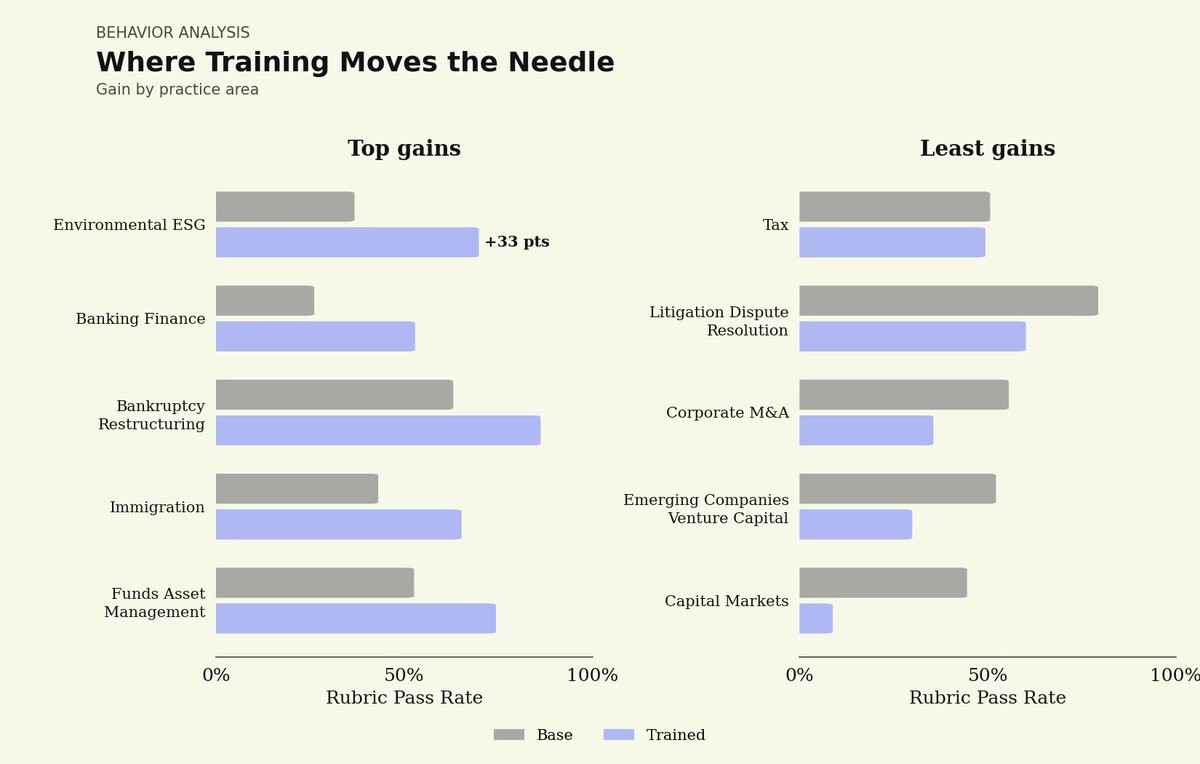
The results, in just hours: post-trained Nemotron 3 Super approaches the closed frontier, matches GPT 5.5, lifts rubric-pass criteria 25%, all while beating the performance-vs-cost frontier. That's the power of our platform.
And this is just a glimpse towards what the future of intelligence will look like: continual learning, where products get smarter every time they're used.
Thanks to @nikogrupen, @gabepereyra, @ItsJulioPereyra, and the whole Harvey team for their collaboration on this. Much more to come soon on continually learning legal agents
8
23
207
59,979
May 29
Welcome to Day 2. Yesterday, we showed the broader work we're doing with the pioneers of continual learning.
Today we'd like to deep dive on one: how we post-trained an open model for legal work, in partnership with @Harvey.
We've built a platform where production data is the moat. Every correction, retry, and edit becomes signal you can post-train on, and the models are plug and play: customer's can drop in their model of choice, and improve from there.
Fields like legal and finance make those demands absolute, with hard security, sovereignty, and provenance requirements. That's why we post-trained @nvidia 's open-weight Nemotron 3 Super, on Harvey's LAB benchmark.
The results, in just hours: post-trained Nemotron 3 Super approaches the closed frontier, matches GPT 5.5, lifts rubric-pass criteria 25%, all while beating the performance-vs-cost frontier. That's the power of our platform.
And this is just a glimpse towards what the future of intelligence will look like: continual learning, where products get smarter every time they're used.
Thanks to @nikogrupen, @gabepereyra, @ItsJulioPereyra, and the whole Harvey team for their collaboration on this. Much more to come soon on continually learning legal agents
12
6
110
65,470