
backend engg · spring boot grpc in prod · built an app running a real lab's daily ops · 学汉语
Joined May 2024
- Tweets 921
- Following 75
- Followers 89
- Likes 1,880
22 Photos and videos







Sushruth retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,537
25,756
87,948
89,722,445

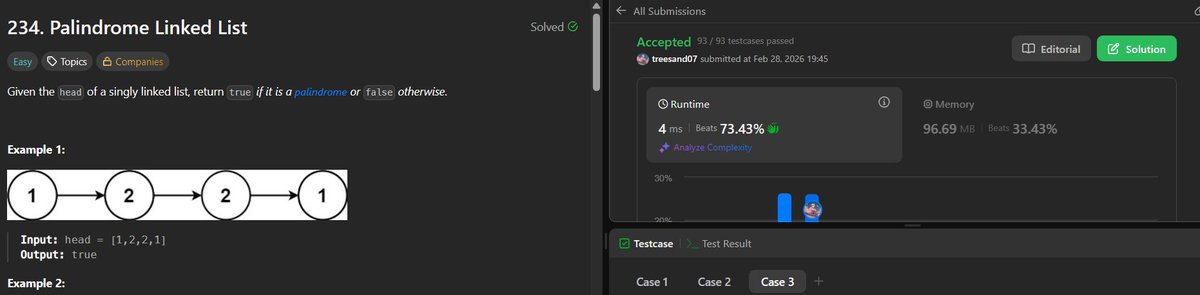
Explain what design patterns Spring Boot uses internally.
Interviewers arent asking if you know the patterns.
They are checking if you understand how Spring Boot is architected using them.
1. Singleton Pattern
Spring Boot Beans are Singleton by default.
When you annotate a class with @ Component, @ Service, or @ Repository, Spring creates only one instance by default.
You should say:
"All Spring beans are Singleton by default unless specified otherwise with scopes like @ RequestScope, which optimizes memory and ensures a consistent shared object graph."
2. Proxy Pattern
Spring AOP (Aspect-Oriented Programming) uses Proxies
3. Observer Pattern
Spring Event system = Observer pattern in action.
4. Factory Pattern
Spring uses factories everywhere.
BeanFactory, ApplicationContext, FactoryBean
You define a bean -> Spring decides when and how to instantiate it.
5. Builder Pattern
Used in clients like RestTemplateBuilder, WebClient.Builder.
5
16
178
9,369
Sushruth retweeted

Apr 23
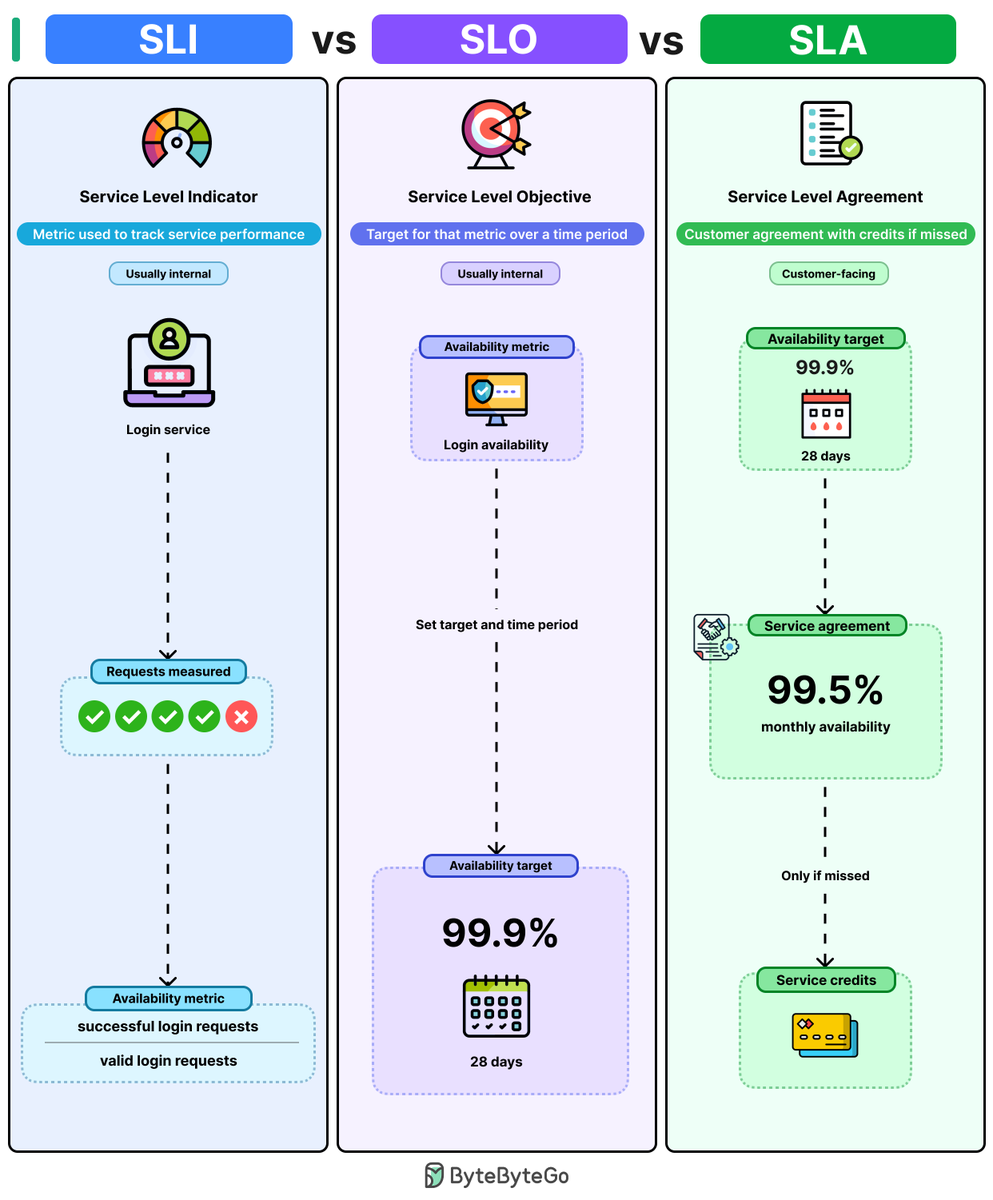
SLA vs SLO vs SLI
These three terms are related, but they mean different things. Knowing the difference helps you define what to measure, aim for, and promise your customers.
Here's how they actually connect:
- SLI (Service Level Indicator): This is the metric you're measuring. For a login service, it could be the ratio of successful login requests to total valid requests. It tells you how your service is performing right now.
- SLO (Service Level Objective): You take that SLI and define a target around it. Something like "login availability should stay above 99.9% over a rolling 28-day window." When you're missing your SLO, it’s a signal to find out what's failing before customers notice.
- SLA (Service Level Agreement): This is what you promise your customers in a contract. It's usually set lower than the SLO, say 99.5% monthly availability. If you breach it, you owe service credits.
If your SLO and SLA are both set to 99.9%, then the moment your availability drops below 99.9%, you've already breached the agreement.
The SLI tells you where you stand. The SLO tells you where you should be. The SLA tells your customers what they can expect.
4
73
370
21,847
Sushruth retweeted

Apr 19
Searching for a sorted file of 50GB that cant fully be loaded into memory is a kind of system design question.
The way to ans this is to go sequentially, even if you think you know the ans, ask clarifying ques. Will there be multiple searches or single search? What is the RAM available? Is the file on disk(HDD/SSD) or in remote S3 or blob storage? Is preprocessing allowed?
After we establish the problem state, then we are able to think of solutions in an increasing scale of complexity.
Binary search would be the starting point since the file is sorted. It would be O(logN). But one disadvantage is the disk seeks which can be expensive.
If we are allowed to preprocess, then establish a sparse index. An in memory mapping of Nth key/nodes. For a few mb used up, we can reduce the disk seeks drastically.
If there are expected to be multiple misses, then a bloom filter would be useful as a prefilter.
1
1
7
394

Apr 12
Hiyaa, first post here so will share smth simple :D
Built this for fun, it's a sword formation particle simulator inspired by xianxia novels.
Btw I'm a backend dev. No part of my day job touches frontend or animations. But I wanted to understand how animations work, so I decided to build something weird and fun :P
2
11
459
Sushruth retweeted
Feb 16
tldr:
- volatile = visibility, not atomicity. don't use it for compound ops
- synchronized = mutex memory visibility
- no sync = no guarantees
- if unsure, use java.util.concurrent, it handles this stuff for you
understand these traps before writing concurrent java.
1
3
233

Sushruth retweeted

Apr 10
8.) If you want to get into distributed systems, start here: (from my experience, otherwise it's totally yours choice)
→ Read the Raft paper (raft.github.io)
→ Read "Designing Data-Intensive Applications" by Kleppmann
→ Read "Database Internals" by Alex
→ Study how Kafka handles log replication
→ Then go read about eventual consistency and CRDTs
You'll never look at a database the same way again.
1
2
9
1,121
Sushruth retweeted
Apr 8
Kafka consumers are bound by num. of partitions not num. of consumers.
So if the topic only has 3 partitions then 7 of those 10 consumers are just idle.
I personally haven't tinkered with kafka tho, want to. Maybe in a side project since kafka config is already working fine at work and there's no reason to change it.
Ykw is more interesting, how would you prep your kafka for 10x volume that it currently handles. Having prepped steps for that is a good idea.
1
1
2
284
Java interviewers love to discuss about IMMUTABILITY.
Cover below 5 topics to be confident when asked about immutability
1. Definition of immutability and its benefits like thread safety, caching, and predictability.
2. Steps to create an immutable class: declare the class as final, make fields private and final, avoid setters, use constructors to initialize fields, and return copies for mutable fields in getters.
3. Why String is immutable in Java and the advantages it provides, such as caching and security.
4. Usage of immutable collections, including Collections.unmodifiableList and factory methods like List.of and Set.of, and the difference between unmodifiable and immutable collections.
5. How immutability is used in design patterns like the Builder Pattern.
2
14
116
4,818
Apr 5
RT @_overment: @om_patel5 @xlr8harder just keep in mind that LLMs “think by generating tokens”. In general, more tokens = more time for thi…
5
Apr 5
x.com/SumitM_X/status/204064…
1. Code in finally block runs irrespective of the program outcome, usually used for cleanup. Finalize is a method used by GC to give a final call for object
2. classnotfoundexception is a checked exception thrown when you dynamically load a class at runtime like Class.forName and it doesnt exist. noclassdeffounderror means the class was there at compile time but went missing at runtime.
3. for custom exceptions just extend Exception for checked or RuntimeException for unchecked and add code like usual. Also we can use context specific info like error codes.
4. synchronous is for using in normal try catch in same thread while asynchronous is when exceptions happen in a async env or process for example, CompletableFuture where you use exceptionally() or handle() instead.

Exception handling is important for apps, and Java interviewers make sure to evaluate it.
Some common beginner level questions 👇
- finally vs finalize
- classnotfound vs. noclassdeffound
- how to create custom exceptions
- synchronous vs asynchronous exception handling and when to use what
3
490
Apr 3
Is it just me or is Claude usage getting exhausted wayyy faster lately?
1
4
100
Sushruth retweeted

Apr 3
What are Agent Skills?
An agent with 30 specialized workflows could need ~150k tokens in its system prompt if you loaded everything upfront.
With Agent Skills, that drops to ~3k tokens. The agent knows what skills exist but loads full instructions only when the task needs them.
Here's how skills exactly work in 7 stages:
> Stage 0: Skills discovery
Skills are discovered from multiple sources, like:
- Bundled (ships with the platform)
- project-level (.claude/skills/)
- global (~/.claude/skills/)
- plugins
- API
- community
Only the YAML frontmatter (name description, which is typically ~100 tokens per skill) gets loaded into the system prompt.
> Stage 1: User query:
The user's request combines with the system prompt, which already contains skill metadata from Stage 0.
> Stage 2: LLM selects skill:
The LLM scans skill descriptions and picks the best match. This does not involve embeddings or classifiers but rather pure LLM reasoning during the forward pass.
> Stage 3: Skill activation:
The selected skill loads into context in 3 tiers: metadata (already loaded), SKILL(.)md body, and scripts (run only if needed). Typically, only the script output enters context, not the source code itself, though this can vary by implementation.
> Stage 4: Context injection:
Skill instructions get injected into the conversation context. Some implementations also scope execution permissions via the spec's experimental `allowed-tools` field. The LLM is now enriched with specialized knowledge.
> Stage 5: Agent executes:
The enriched agent produces output, using external tools (like MCP servers) as the skill instructs. Skills define the workflow. MCP provides the connections.
> Stage 6: Output and dehydrate:
Final output goes to the user. In implementations like Claude Code, the skill is typically unloaded from context after execution, enabling a load, execute, unload, repeat cycle for multi-step tasks. But the exact behavior can vary across agents.
👉 Over to you: Have you built custom skills for your workflow yet?
P.S. The visual below was inspired by ByteByteGo's diagram on Agent Skills but it was missing a few key pieces like skill discovery, the 3-tier progressive disclosure, context injection and permission scoping and skill dehydration. I addressed that to build a complete 7-stage diagram that covers the full lifecycle.
____
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
14
39
199
29,699

Sushruth retweeted

Mar 31
Based on everything explored in the source code, here's the full technical recipe behind Claude Code's memory architecture:
[shared by claude code]
Claude Code’s memory system is actually insanely well-designed. It isn't like “store everything” but constrained, structured and self-healing memory.
The architecture is doing a few very non-obvious things:
> Memory = index, not storage
MEMORY.md is always loaded, but it’s just pointers (~150 chars/line)
actual knowledge lives outside, fetched only when needed
> 3-layer design (bandwidth aware)
index (always)
topic files (on-demand)
transcripts (never read, only grep’d)
> Strict write discipline
write to file → then update index
never dump content into the index
prevents entropy / context pollution
> Background “memory rewriting” (autoDream)
merges, dedupes, removes contradictions
converts vague → absolute
aggressively prunes
memory is continuously edited, not appended
> Staleness is first-class
if memory ≠ reality → memory is wrong
code-derived facts are never stored
index is forcibly truncated
> Isolation matters
consolidation runs in a forked subagent
limited tools → prevents corruption of main context
> Retrieval is skeptical, not blind
memory is a hint, not truth
model must verify before using
> What they don’t store is the real insight
no debugging logs, no code structure, no PR history
if it’s derivable, don’t persist it

152
694
6,348
833,775