
Uber is committed to enabling collaboration for everyone, everywhere through open source.
Joined December 2017
- Tweets 308
- Following 68
- Followers 2,133
- Likes 352
15 Photos and videos













Uber Open Source retweeted

25 Jan 2022
Check out our new blog! Learn about how the Uber Big Data Format team improved cost efficiency with innovations in Apache Parquet and ZSTD, saved millions of dollars for storage cost, and reduced vCores consumption significantly.
read more: eng.uber.com/cost-efficiency…
3
7
37
Uber Open Source retweeted
9 Nov 2021
Come join us for our Workflow Systems: Now and the Future Cadence Open Source Meetup on Friday, November 19th at 11 AM PST! #opensource #cadence
meetup.com/UberEvents/events…
2
7
17
Uber Open Source retweeted
21 Oct 2021
New on our blog today! Introducing uGroup, Uber’s universal Kafka consumer group state management & lag tracking service.
read more: eng.uber.com/introducing-ugr…
3
4
8

WE ARE THRILLED! 🥇 @prestodb is recognized as Best Open Source Software of 2021 in @InfoWorld's 2021 Bossie Awards! 🎉 More details 👉 infoworld.com/article/363703… h/t @linuxfoundation #OpenSource #Presto #SQL for #Datalakes
3
13
15

14 Oct 2021
We're excited to release the Uber design map marker components to the open-source @BaseWebReact library!
Two different categories of map markers (floating fixed) that come with all sorts of sizing, icon, color, and position customizations.
Learn more:
baseweb.design/blog/introduc…
1
5
23
28 Sep 2021
Congrats to the Gitpod team for launching Open VSCode Server! Uber's at the forefront of remote development, and this project will help keep our developer experience modern and fast.
gitpod.io/blog/openvscode-se…
3
4
Uber Open Source retweeted

4 Aug 2021
On Tuesday we're excited to have @KDharak and @cnaer from @UberEng join @JackieXiaotian for @ApachePinot Features: Lookup Join & Subquery! Register to join our meetup here! hubs.la/H0TtWh00
2
6
Uber Open Source retweeted
29 Jul 2021
New on our blog today! Our Uber Engineers & Apache Pinot community discuss how they build a 7x24 data ingestion pipeline in the article Pinot Real-Time Ingestion with Cloud Segment Storage. @UberOpenSource @LinkedInEng
read more: eng.uber.com/pinot-real-time…
8
19
Uber Open Source retweeted
22 Jul 2021
New on our blog today! Members of Uber's Data team discuss the journey of containerizing Apache Hadoop infrastructure with Docker. @uberopensource
read more: eng.uber.com/hadoop-containe…
3
9
Uber Open Source retweeted
19 Jul 2021
Tomorrow morning Yupeng Fu from @UberEng will be speaking on geospatial support in @ApachePinot including the geospatial data model, functions, and indexing for better query performance. Join us LIVE at 9AM PDT! hubs.la/H0SC9ZD0
3
11
Uber Open Source retweeted
13 Jul 2021
Join us for a Meetup on July 29th, Introducing Orbit, An Open Source Package for Time Series Inference and Forecasting @UberOpenSource
RSVP here: meetup.com/UberEvents/events…
5
19
Uber Open Source retweeted

12 Jul 2021
Thanks, @Uber @UberOpenSource @SFbrigade & everyone involved on this great track for our @devmissionorg Pre Apprenticeship Graduates to become full-stack developers.
12 Jul 2021

New Blog! Read about our Uber Fellowship Program. In partnership with @Uber and @SFbrigade. How we are trying to eliminate barriers to the tech industry. Thanks to Uber and Code For San Francisco for their ongoing support in making this possible.
devmission.org/uber-fellowsh…

2
3
Uber Open Source retweeted
7 Jul 2021
New on our blog today! Members of our engineering team describe how they co-developed Distributed XGBoost on Ray with the Ray team @raydistributed to tackle various production challenges of doing distributed machine learning at scale.
read more: eng.uber.com/elastic-xgboost…
1
10
30
Uber Open Source retweeted

1 Jun 2021
Check out this blog post by @kennybastani & Yupeng Fu (@UberEng) that introduces you to real-time geospatial queries in #ApachePinot 0.7.1 medium.com/apache-pinot-deve…
9
24
Uber Open Source retweeted
14 May 2021
New on our blog today! Members of our data science team introducing Orbit, An Open Source Package for Time Series Inference and Forecasting. Orbit is a general interface for Bayesian time series modeling. @UberOpenSource
read more: eng.uber.com/orbit/
9
17
Uber Open Source retweeted
6 May 2021
New on our blog today! Members of our engineering team introducing Optimal Feature Discovery: Better, Leaner Machine Learning Models Through Information Theory.
read more: eng.uber.com/optimal-feature…
3
4
8
30 Mar 2021
Please join us for a virtual Apache Hudi Meetup with @ubereng, @RobinhoodApp and @logicalclocks. Apache Hudi is a data platform technology that helps to build reliable and scalable data lakes. @apachehudi
RSVP here: meetup.com/UberEvents/events…
7
17
Uber Open Source retweeted

30 Mar 2021
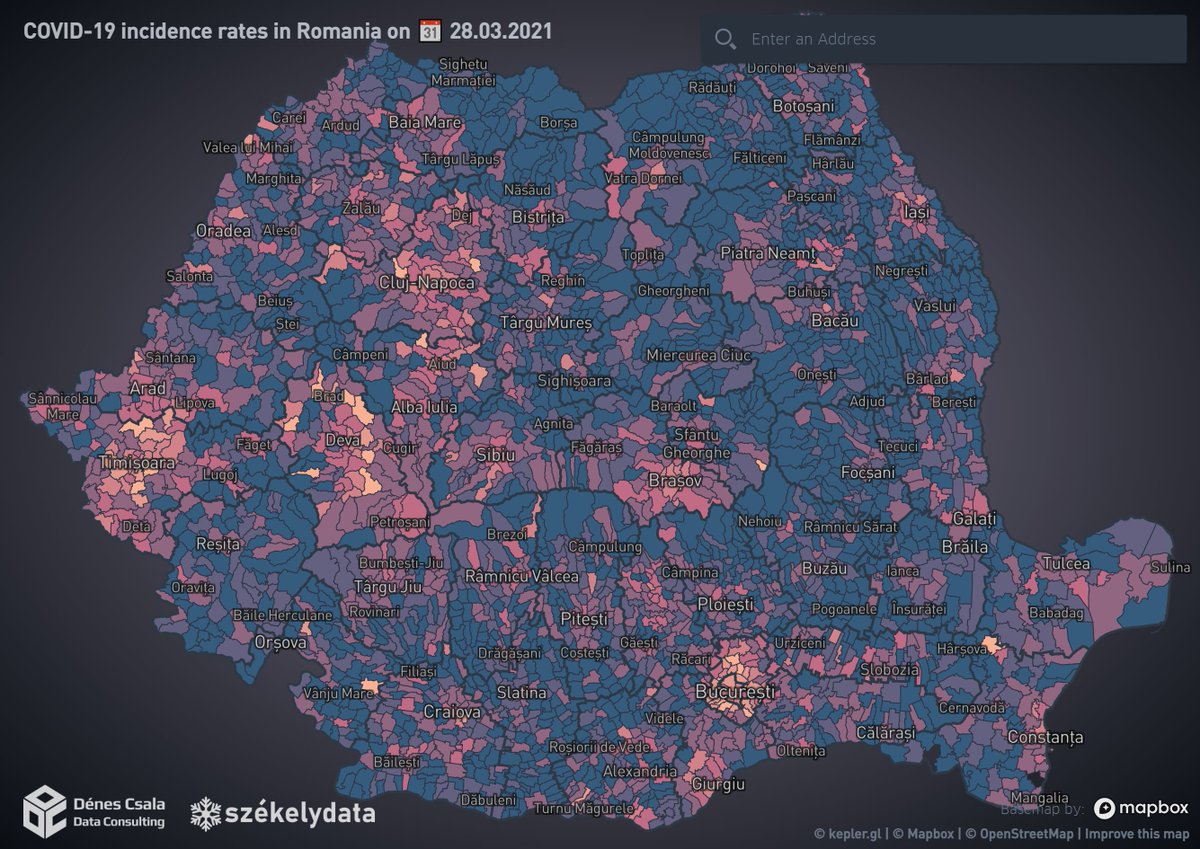
Fiddling around with @UberOpenSource #KeplerGL 👉 the result: a 🌄 #choropleth map of locality-level COVID-19 incidence rates in #Romania
#GIS #dataviz #szekelydata @DataDenes szekelydata.csaladen.es/inci…
1
1
9

Asian people have the right to move without fear. #StopAsianHate
386
46
165
22 Mar 2021
Join the #Presto community this week on Wed March 24th for PrestoCon. Speakers from different companies big & small will present @fbOpenSource, @UberEng, @TwitterOSS, @AhanaIO, @upsolver, @intel & more!
Free Registration: events.linuxfoundation.org/p…
3