
Joined March 2026
- Tweets 39
- Following 116
- Followers 11
- Likes 1
Photos and videos

Jun 12
An AI company is about to say something nuanced about AI, so brace yourself. This retraction is not the case against AI in peer review. It is the case for the most boring use of it.
The same technology pulls in opposite directions depending on the job. Generation invents citations that look perfect and do not exist. Verification checks every DOI and author list against a real database and flags the fakes in seconds. One caused this retraction. The other would have caught it at submission.
22 fake references is not a screening failure that needs more human reviewers staring at reference lists. No human should be doing that by hand. It is a check a machine runs instantly, freeing the humans to actually evaluate the science.
AI did not break this. The wrong AI doing the wrong job did. The right one never gets near the conclusions.

Ghost References, Compromised Peer Review
Just saw this Elsevier retraction from IJC Heart & Vasculature. The paper had 27 references. The journal now admits:
1. 17 references had scrambled titles, authors, and DOIs
2. 5 references were completely non-existent
3. That leaves exactly 5 valid references out of 27 — an 81.5% hallucination rate, baby.
The paper literally cited more ghosts than real articles, and it still tiptoed through submission, editorial screening, peer review, and production without anyone noticing.
At this point Elsevier doesn’t need a plagiarism checker, they need an exorcist. If a paper that’s 81% AI fever dream can waltz into a journal in 2026, what’s the screening actually screening? Vibes? Auras?

24
Jun 12
AI should not write your paper. It is genuinely excellent at reviewing it. That sounds self-serving coming from this account, so here is the actual reasoning.
The two jobs fail in opposite directions. When AI writes, its mistakes become yours: fluent, confident, and published under your name. When AI reviews, its mistakes are comments you cross out. One puts errors into the literature. The other pulls them out before a journal finds them.
The line is generation, not grammar. Tightening sentences is fine. Your arguments, analysis, and conclusions need to come from the person whose name is on the work. What that person deserves in return is a tireless skeptical reader who checks every reference and is just as alert on page 14 as page 1.
Keep the authorship. Borrow the scrutiny.
14
Jun 7
The ICLR finding everyone's quoting — 21% of peer reviews fully AI-generated, most of them long and low-substance — has an obvious takeaway and a real one.
Obvious: AI peer review is bad.
Real: context-starved AI peer review is bad.
An AI review is only as good as the context it's grounded in. Those ICLR reviews were a PDF pasted into a chatbot with nothing else attached. No wonder they produced 40 generic questions and caught nothing that mattered.
Here's what a chatbot in a browser tab actually works with:
— only the text you pasted, not the full manuscript, supplements, or figures
— no idea which journal you're targeting or what it requires
— no way to verify a single citation
— one pass, then done
Here's what changes when the AI has real context:
— the entire manuscript, supplementary files, and figures, not a fragment
— the specific target journal's reporting standards and author guidelines
— tens of millions of papers to cross-reference claims against, and every reference checked against real databases
— multiple passes: critique the paper, then critique the critique
A chatbot tells you the obvious things you already knew. A system with context tells you what you missed — the citation that doesn't actually support your claim, the test your target journal requires, the closely related paper you forgot to cite.
The problem at ICLR was never that AI reviewed. It's that the AI was reviewing blind.
Context is the whole game.
1
43
May 27
Most rejected papers don't fail on the science.
They fail on things the authors could have caught before submitting:
- References that don't say what the authors claim they say
- Results in the abstract that don't appear in the figures
- Statistical tests described in the methods but never reported in the results
- Claims of novelty that ignore a paper published 6 months ago
- Supplementary materials that contradict the main text
These aren't knowledge gaps. They're attention gaps.
Human reviewers catch some of them. But they're volunteering their time, reviewing 3 papers at once, and racing a deadline.
The fastest way to improve your acceptance rate isn't better science. It's a better final check before you hit submit.
18
May 27
This is the line that matters for scientific publishing:
"There's a difference between using AI as a shortcut and using it as a second opinion."
AI that writes your paper for you is cognitive surrender. AI that finds the statistical blind spots, checks your code against your claims, and verifies your references before you submit — that's a second opinion.
The tool should make the researcher better, not optional.
May 26

I wrote a new post on what we need to keep human and what to hand over to AI, with forays into experiments in education, consulting, and the the latest controversy over literary prizes. oneusefulthing.org/p/choosin…
2
58
May 25
New Lancet audit: fabricated references in biomedical papers increased 12x in three years.
2023: ~1 in 2,500 papers had a fabricated citation.
2026: 1 in 277.
They scanned 2.5 million papers and 125 million references.
This isn't a hypothetical. It's measurable. It's accelerating. And it's already in the published literature — papers that passed peer review with citations pointing to studies that don't exist.
Peer reviewers can't catch what they don't check. And no human is cross-checking 40 references against PubMed for every manuscript they review.
This is exactly why automated reference verification isn't a nice-to-have anymore. It's infrastructure.
thelancet.com/journals/lance…
1
1
62
May 25
The arXiv ban targets the obvious cases — hallucinated references left in by careless authors.
But The Lancet data shows something worse: fabricated citations that are subtle enough to pass peer review entirely.
The problem isn't just sloppiness. It's that the current system has no systematic verification layer.
1
30
May 24
The most dangerous thing an AI can do in science is sound certain when it shouldn't be.
That's why we built PeerReviewAI as a second opinion, never a verdict. It flags what it finds — methodological gaps, statistical issues, missing references, reporting compliance problems. It doesn't tell you what to do about them.
The decision stays with the researcher. Always.
The real question isn't whether AI can say "I don't know." It's whether we build AI tools that are honest about what they don't know — or ones that fake confidence to seem useful.

Perspective by @AndreaSikora, PharmD, MSCR, Leo A. Celi, MD, MPH, and Raja-Elie E. Abdulnour, MD (@BageLeMage): Can AI Say “I Don’t Know”? nej.md/4fgdg0D
#MedEd #MedicalEthics

ALT A quote from a Perspective by Andrea Sikora, Pharm.D., M.S.C.R., Leo A. Celi, M.D., M.P.H., and Raja-Elie E. Abdulnour, M.D. published in the New England Journal of Medicine. The quote reads, "Current methods for training AI systems rarely reward abstaining from answering a question ... Yet if AI is going to support clinical reasoning, systems will need to be able to indicate uncertainty."
32
May 24
arXiv is now banning researchers for a year if their papers contain obvious AI-generated errors.
The problem isn't AI. It's lazy AI use.
Pasting your manuscript into ChatGPT and submitting the output is not "AI-assisted research." It's outsourcing your thinking.
There's a difference between using AI as a shortcut and using it as a second opinion.
A shortcut skips the work.
A second opinion challenges it.
The researchers getting banned aren't using AI to improve their science. They're using it to avoid doing science.

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
2
72
May 24
One thing arXiv specifically flagged: hallucinated references. Citations that point to papers that don't exist.
This is what happens when you let AI write your reference list instead of using it to verify the one you already have.
22
May 21
The buried lede in this paper isn't that AI matches human reviewers.
It's that 26% of AI-raised criticisms were issues NO human reviewer caught — and 82% of those were correct.
AI doesn't just replicate peer review. It sees things humans systematically miss.
Here's what stood out to us 🧵
May 21
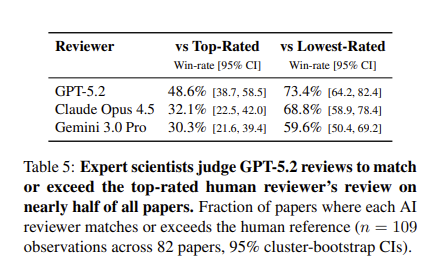
Seems GPT-5.2 reaches expert level in peer review: 45 scientists took 469 hours evaluating human & AI reviews on 82 papers.
"Surprisingly, current AI reviewers are competitive even with the top-rated reviewers in Nature’s official peer review..." though not without weaknesses.


1
85
May 21
This is exactly why we're building @PeerReviewAI — not to replace reviewers, but to give authors a rigorous pre-submission check before their manuscript ever reaches an editor.
Statistical blind spots caught. Code verified against claims. Evidence grounded.
The peer review system is under pressure. AI can help carry the load.
1
17
May 21
Genuine question for researchers:
If an AI reviewer could catch the methodological and code-level issues human reviewers miss — but you knew it might overcriticize based on field norms —
Would you want that feedback before you submit?
24
May 11
Peer review is the only professional service in the world where:
— The workers are unpaid
— The customers wait months for delivery
— Quality control is essentially random
— And the entire system depends on guilt and obligation to function
Journals have tried incentives. Faster turnaround pledges. Reviewer training programs. One journal even tried paying reviewers — it only marginally reduced turnaround times.
None of it works at scale because the fundamental problem isn't motivation. It's that the volume of manuscripts has outgrown the capacity of volunteer labor.
The answer isn't asking more from reviewers. It's asking less — by automating the work that doesn't require human expertise.
Source:
frontiersin.org/journals/res…
19
May 8
Over 14,000 retraction notices were issued in 2023 alone — a new record.
12,000 articles published in 2022 were retracted. In 2024, another 9,000 .
In 2002, the total was 119.
Something that peer review was supposed to catch is clearly not being caught.
What editors actually want from a reviewer report:
— Specific methodological concerns with section references
— Statistical validity assessment
— Whether conclusions are supported by the data
— Missing controls or comparisons
— Reporting guideline compliance
— Citation verification
What editors often get:
"Interesting study. Some minor issues with the methods. Recommend minor revisions."
The gap between those two is where flawed manuscripts become published papers and published papers become retractions.
Source:
arxiv.org/html/2511.21176v1
20
May 7
A study of 57 health policy journals found the complete publication process ranged from 35 to 353 days.
The peer review phase alone stretched to 314 days in some cases. Time to first peer-reviewed decision ranged up to 263 days.
That's not a system working slowly. That's a system failing quietly.
Meanwhile, the science inside those manuscripts ages. Competing groups publish first. Early-career researchers lose funding cycles waiting for a decision.
Peer review doesn't need to be faster for the sake of speed. It needs to be faster because slow review is actively harming the science it's supposed to protect.
Sources:
jamanetwork.com/journals/jam…
frontiersin.org/journals/res…
17