
Decoding the future @ Litus AI ~ NLP PhD @ Sapienza - Engineer at heart - he/him.
Joined January 2012
- Tweets 61
- Following 126
- Followers 106
- Likes 103
3 Photos and videos

Pinned Tweet

17 May 2022
Super happy that our DiBiMT paper got recognized as the Best Resource Paper @aclmeeting #ACL2022! 🥳🎉
A (not so) short 🧵 about it :) 👇
Joint work with @FedeMartelli25 @FrancescoSaina @RNavigli
📜: aclanthology.org/2022.acl-lo…
1/7
3
7
30
Niccolò Campolungo retweeted

8 Feb 2023
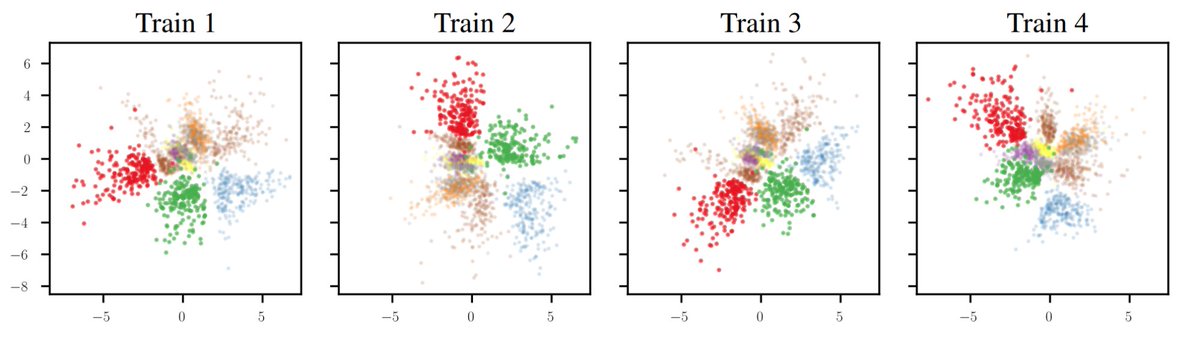
📢 It looks like relative representations are here to stay!
I'm beyond thrilled to announce that our work has been selected as one of the notable top 5% (oral) papers at #iclr23 ! 🥳
x.com/moschella_luca/status/…
[1/5]
6 Oct 2022

Welcome Relative Representations, enabling zero-shot communication between latent spaces without any training!
arxiv.org/abs/2209.15430
It turns out that distinct neural networks learn intrinsically equivalent latent spaces [1/6]
3
37
266
54,628
Niccolò Campolungo retweeted

7 Dec 2022
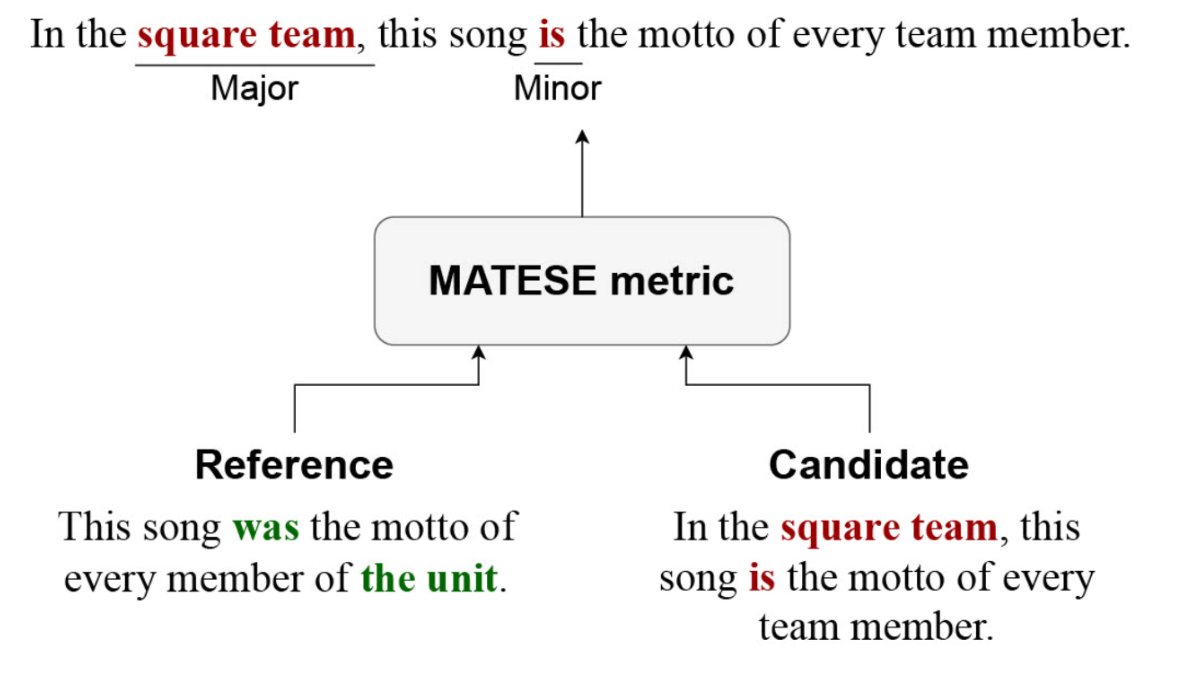
We reframe #MT evaluation as sequence tagging in our #WMT2022 paper: check MaTESe, an interpretable metric that tags error spans in translations!
📜 statmt.org/wmt22/pdf/2022.wm…
By @19Stefano97 @LorenzoProiet13 @alescire94 @Valahaar @RNavigli @babelscape @ERC_Research #EMNLP2022
7
14
Niccolò Campolungo retweeted

27 Nov 2022
Great to wake up on a lazy Sunday and see REBEL is still doing numbers. This is the page for top seq2seq models at @huggingface, currently top 12 with 200K monthly downloads. Thank you to whomever is using it and honestly curious to know what people are using it for.

7
39
Niccolò Campolungo retweeted
13 Jul 2022
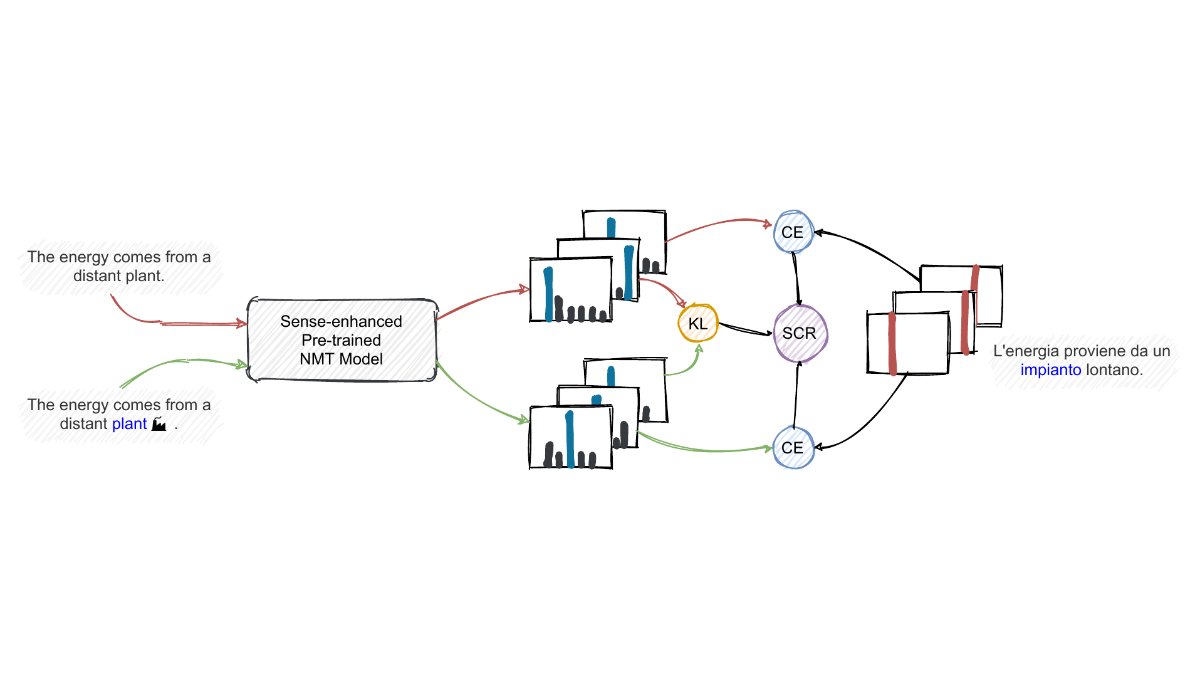
Interested in reducing semantic bias in NMT models with smart data creation & the KL divergence?
Come check out the work by @Valahaar, @pasini_t, @emelin_denis & @RNavigli!
Presentation today @ 9.15 PDT / 18.15 CET, session 8D (MT 3) #NAACL2022
📝 aclanthology.org/2022.naacl-…
2
11
Niccolò Campolungo retweeted

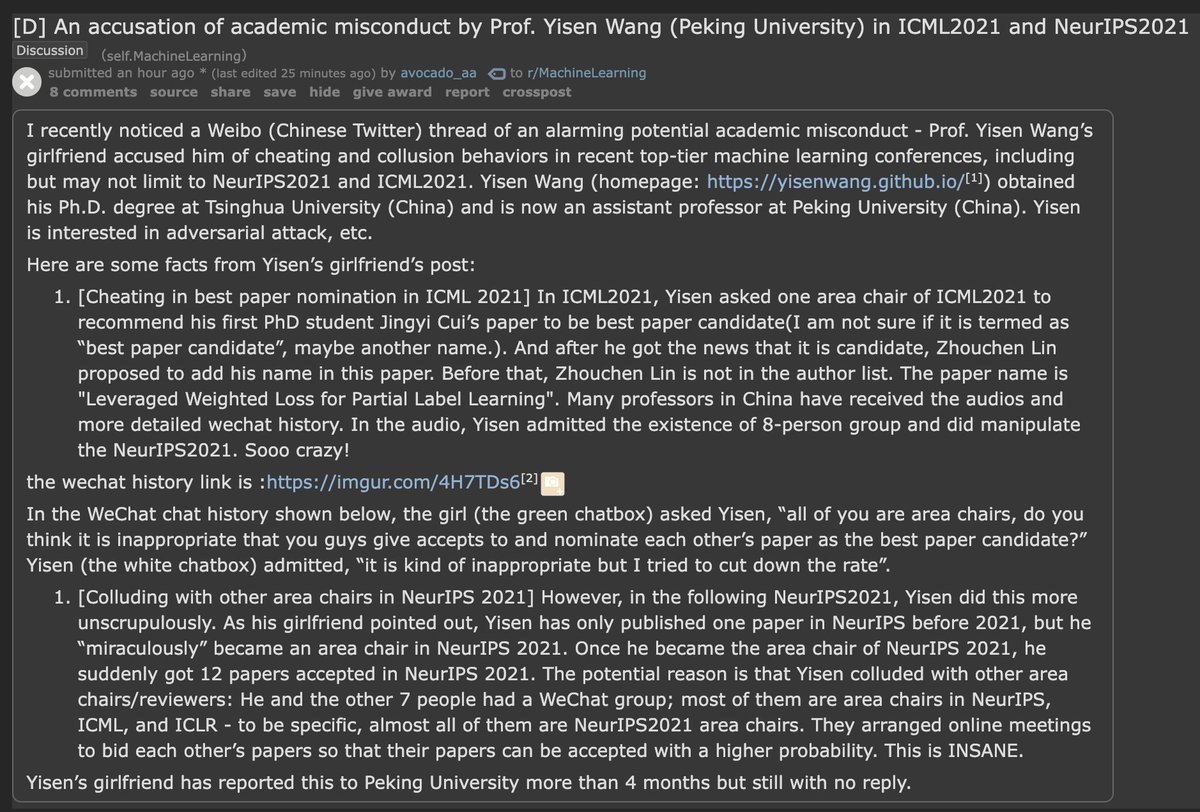
7 Jul 2022
machine learning researchers learn to optimise their own best paper rate through collusion and other unregulated mechanisms
reddit.com/r/MachineLearning…
40
194
1,012
Niccolò Campolungo retweeted

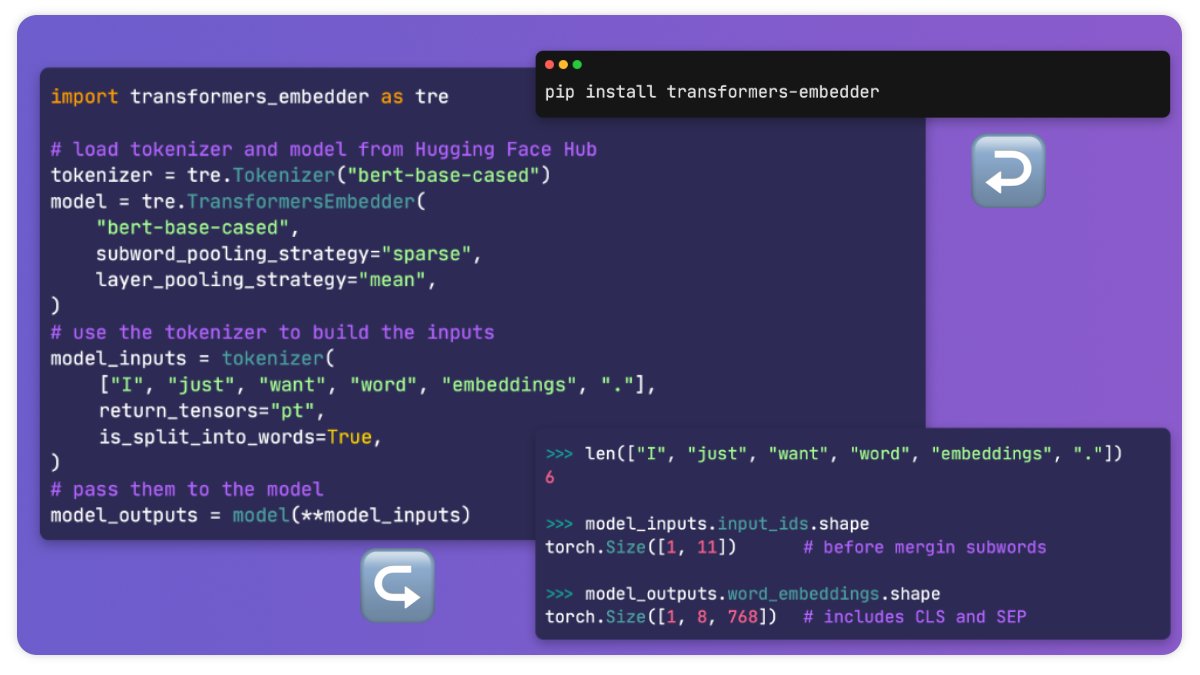
7 Jul 2022
Hey #NLProc, I built this little tool to make working with @huggingface 🤗Transformers a bit easier. If you want to directly access whole-word embeddings hassle-free, give it a try!
👉GitHub: github.com/Riccorl/transform…
9
22
Niccolò Campolungo retweeted

6 Jul 2022
The Rome Workshop on 10 Years of #BabelNet & Multilingual Neurosymbolic Natural Language Understanding was a great success, with productive in-person discussions, amazing talks & >100 online participants! Thanks!
@ERC_Research @Babelscape @SapienzaNLP @SapienzaRoma @WikiResearch

15
37
Niccolò Campolungo retweeted

6 Jul 2022
🎉10 Years of #BabelNet Workshop is now over:
what a great experience!🎉
Thanks to everyone who participated both in person and online!
@SapienzaNLP @babelscape @ERC_Research
@AccademiaCrusca @RNavigli
#workshop @WikiResearch #BabelNet10anniversary
1
16
30
25 May 2022
I have never clapped my hands as much as I have at the @aclmeeting 2022 Closing Remaks 😂 thank you Bernardo! #ACL2022
6


25 May 2022
Presenting in front of a live audience was an amazing experience :) hope we nailed it! Thanks @aclmeeting
25 May 2022

#acl2022 nlp Best Resource Paper
DiBiMT: A Novel Benchmark for Measuring Word Sense Disambiguation Biases in Machine Translation
(Niccolò Campolungo, Federico Martelli, Francesco Saina and Roberto Navigli)
#acl2022 #NLProc

1
14
Niccolò Campolungo retweeted
17 May 2022
🥳 We are proud to share the news that our DiBiMT paper on Disambiguation Biases in MT received the ✨Best Resource Paper Award✨ @aclmeeting #ACL2022! See you there!
6 Apr 2022

Open & commercial Neural Machine Translation models heavily suffer from disambiguation biases! We present DiBiMT, our novel benchmark for lexical-semantic bias in MT at #ACL2022! By @Valahaar @FedeMartelli25 @FrancescoSaina @RNavigli
@ELEXIS_EU #NLProc
📝:researchgate.net/publication…

6
23
17 May 2022
Super happy that our DiBiMT paper got recognized as the Best Resource Paper @aclmeeting #ACL2022! 🥳🎉
A (not so) short 🧵 about it :) 👇
Joint work with @FedeMartelli25 @FrancescoSaina @RNavigli
📜: aclanthology.org/2022.acl-lo…
1/7
3
7
30
17 May 2022
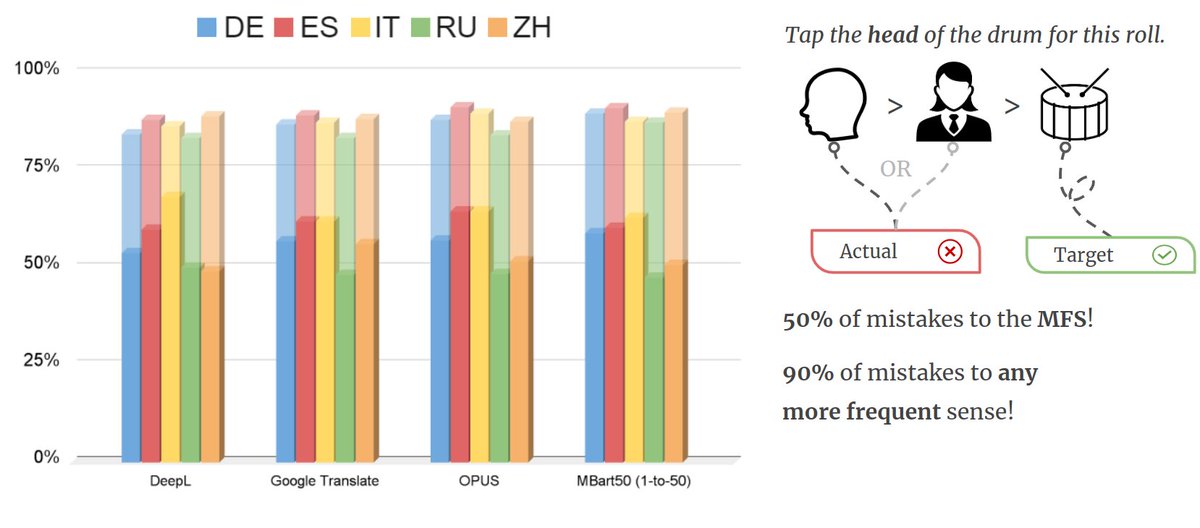
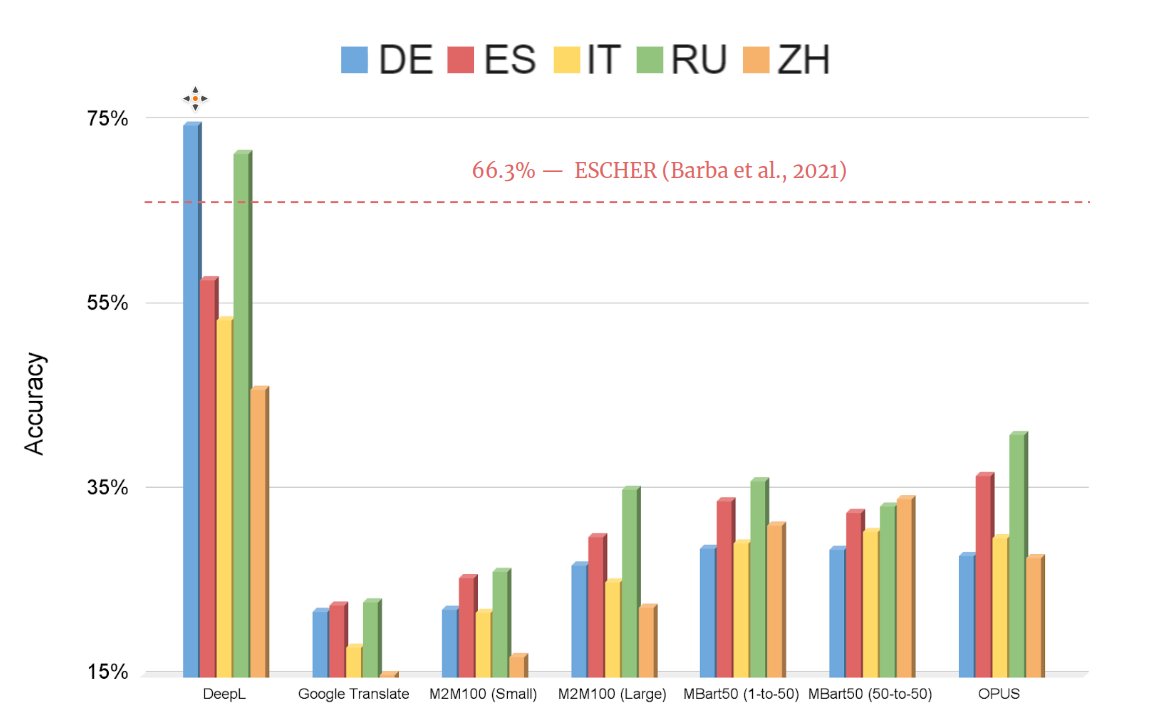
- (neural) models are pretty confident of their incorrect translations: >90% of the time, they deem their BAD❌ translation better than a GOOD ✅ one!
- In neural Transformer models, disambiguation does not seem to be happening on the encoder side 🤔
6/7
1
1
17 May 2022
We will present DiBiMT on the 25th, during the Best Paper Oral Session at 14.45 Dublin time!
Or, you can come have a chat during Poster Session 6: Resources and Evaluation on the same day, from 10:45 to 12:15! Come say hi 👋😄
7/7
Niccolò Campolungo retweeted

17 May 2022
So proud that my former labmates at @SapienzaNLP have been awarded the Best Resource Paper at the #ACL2022 for their work on benchmarking disambiguation in MT! Congrats @Valahaar @FedeMartelli25 @FrancescoSaina @RNavigli
16 May 2022
The Best Paper Awards have just been announced! Congratulations to the authors for their fine work!
2022.aclweb.org/best-paper-a…
1
4
13